神经网络原理讲解与过程梳理
神经网络原理讲解与过程梳理
-
- 一、神经网络原理讲解与过程梳理
-
- 1.数据输入层
- 2.卷积计算层
- 3.激励层
-
- 1.什么是激活函数
- 2.激活函数的用途?(或者说为什么我们需要激活函数)
- 4.池化层
- 5.全连接层
- 卷积神经网络之训练算法
- 卷积神经网络之优缺点
- 卷积神经网络之典型CNN
- 卷积神经网络之 fine-tuning
- 卷积神经网络的常用框架
- 总结
一、神经网络原理讲解与过程梳理
卷积神经网络是一种前馈型神经网络, 受生物自然视觉认知机制启发而来的. 现在, CNN 已经成为众多科学领域的研究热点之一, 特别是在模式分类领域, 由于该网络避免了对图像的复杂前期预处理, 可以直接输入原始图像, 因而得到了更为广泛的应用. 可应用于图像分类, 目标识别, 目标检测, 语义分割等等. 本文先介绍可用于图像分类的卷积神经网络的基本结构。
卷积神经网络的层级结构
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU激励层 / ReLU layer
- 池化层 /Pooling layer
- 全连接层 / FC layer

上图是一个简单的对输入图像进行卷积、激活函数处理、池化等操作卷积神经网络过程图。
上图是多次卷积、激活、池化。
1.数据输入层
在输入层注意需要做的工作是对输入的原始图像进行相关预处理,其中包括:
- 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
- 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
- PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化。
预处理用处讲解
去均值与归一化效果图:
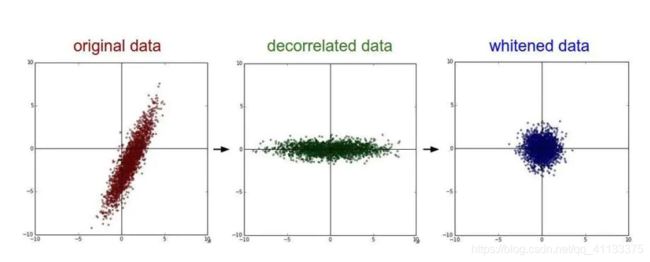
 去相关与白化效果图:
去相关与白化效果图:
2.卷积计算层
使用卷积层来进行特征的提取,如下图:
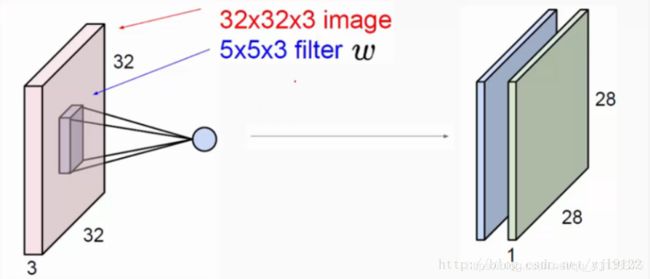
这里我们输入的图像是32323,这里的3是图片的深度(即R、G、B),使用的卷积核是一个553大小的。
注意: 卷积核的深度必须和输入图像的深度相同。
通过一个filter与输入图像的卷积可以得到一个28281的特征图,上图是用了两个filter得到了两个特征图。
下面看看单通道的图片进行卷积:

大家可以看看动图进行理解:

黄色的区域表示卷积核在输入矩阵中滑动, 每滑动到一个位置, 将对应数字相乘并求和, 得到一个特征图矩阵的元素. 注意到, 动图中卷积核每次滑动了一个单位, 实际上滑动的幅度可以根据需要进行调整. 如果滑动步幅大于 1, 则卷积核有可能无法恰好滑到边缘, 针对这种情况, 可在矩阵最外层补零, 补一层零后的矩阵如下图所示:
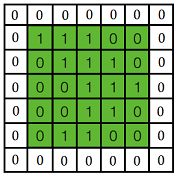
可根据需要设定补零的层数. 补零层称为 Zero Padding, 是一个可以设置的超参数, 但要根据卷积核的大小, 步幅, 输入矩阵的大小进行调整, 以使得卷积核恰好滑动到边缘。
一般情况下, 输入的图片矩阵以及后面的卷积核, 特征图矩阵都是方阵, 这里设输入矩阵大小为 w w w , 卷积核大小为 k k k, 步幅为 s s s, 补零层数为 p p p, 则卷积后产生的特征图大小计算公式为:

上图是对一个特征图采用一个卷积核卷积的过程, 为了提取更多的特征, 可以采用多个卷积核分别进行卷积, 这样便可以得到多个特征图. 有时, 对于一张三通道彩色图片, 或者如第三层特征图所示, 输入的是一组矩阵, 这时卷积核也不再是一层的, 而要变成相应的深度。
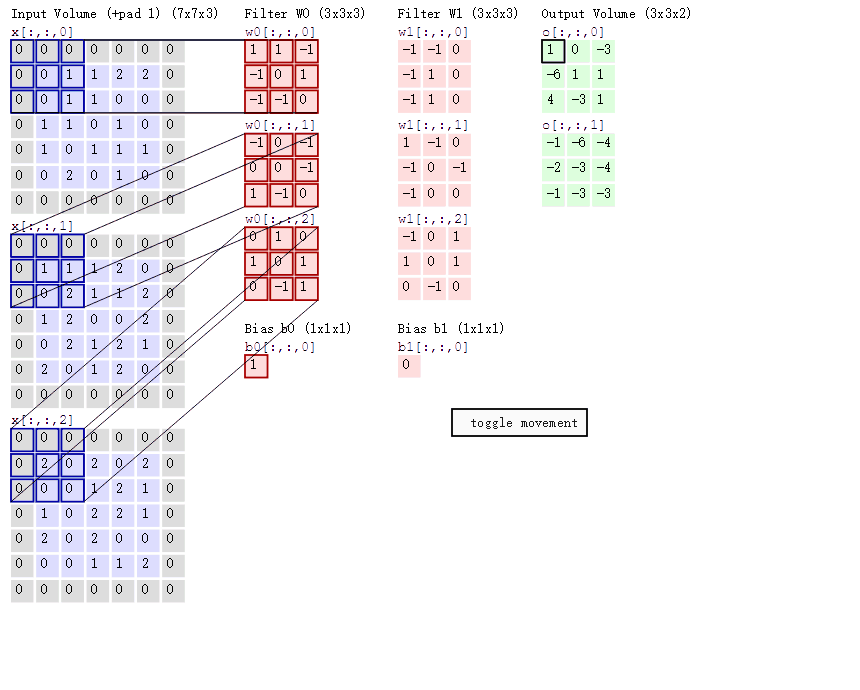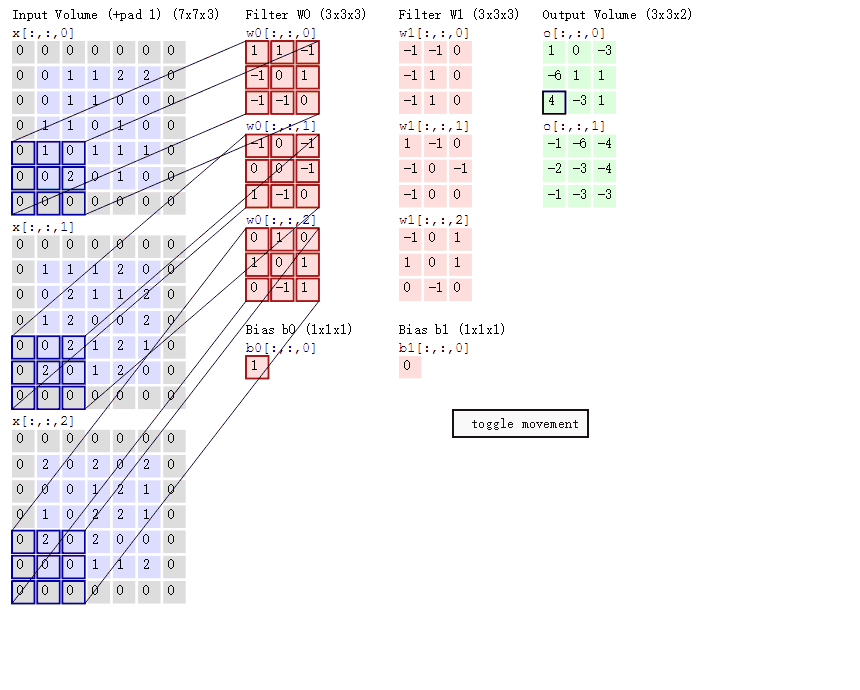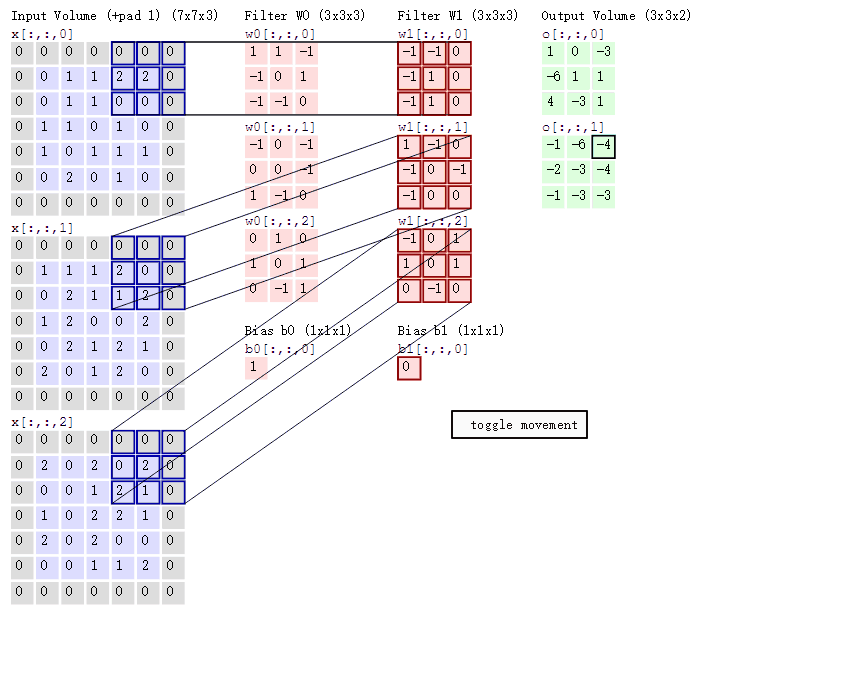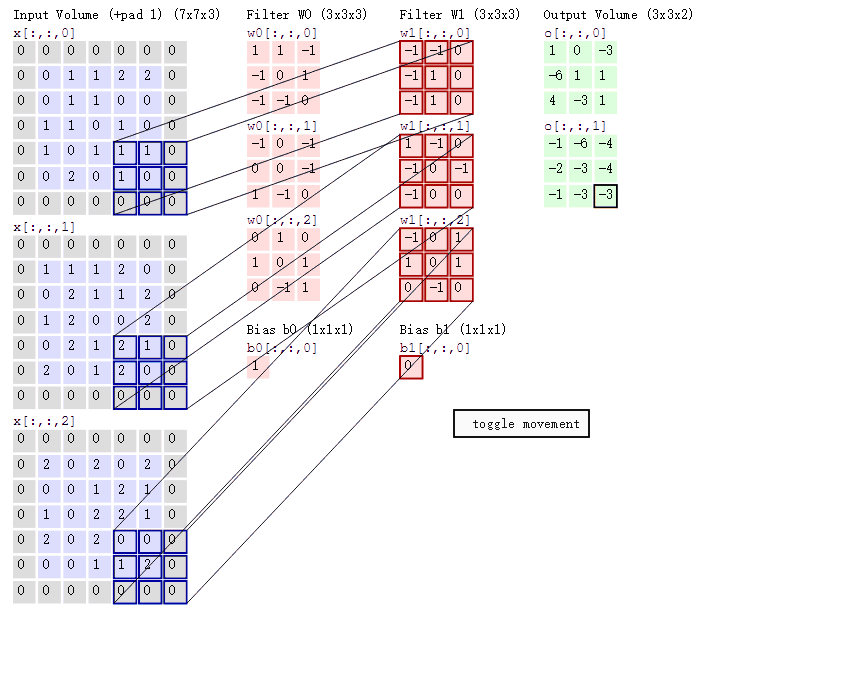
上图中, 最左边是输入的特征图矩阵, 深度为 3, 补零(Zero Padding)层数为 1, 每次滑动的步幅为 2。 中间两列粉色的矩阵分别是两组卷积核, 一组有三个, 三个矩阵分别对应着卷积左侧三个输入矩阵, 每一次滑动卷积会得到三个数, 这三个数的和作为卷积的输出. 最右侧两个绿色的矩阵分别是两组卷积核得到的特征图。
卷积层还有一个特性就是“权值共享”原则:
所谓的权值共享就是说,给一张输入图片,用一个filter去扫这张图,filter里面的数就叫权重,这张图每个位置就是被同样的filter扫的,所以权重是一样的,也就是共享。
3.激励层
把卷积层输出结果做非线性映射。
1.什么是激活函数
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
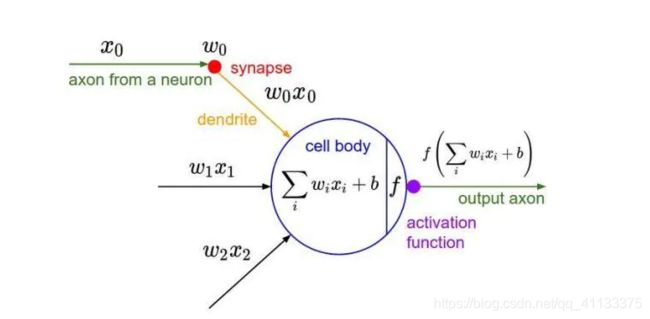
另外一张讲解图:

2.激活函数的用途?(或者说为什么我们需要激活函数)
首先数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数,是在神经网络中引入非线性,强化网络的学习能力。所以激活函数的最大特点就是非线性。
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。

激活函数包括:
- Sigmoid函数
- tanh函数
- Relu函数
- Leaky ReLU函数(PReLU), PReLU(Parametric Relu)(参数化修正线性单元), RReLU(Random ReLU)(随机纠正线性单元)
- ELU (Exponential Linear Units) 函数
- MaxOut函数
4.池化层
对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征,如下:

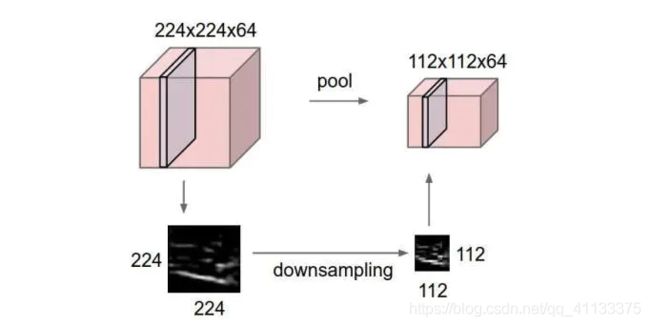
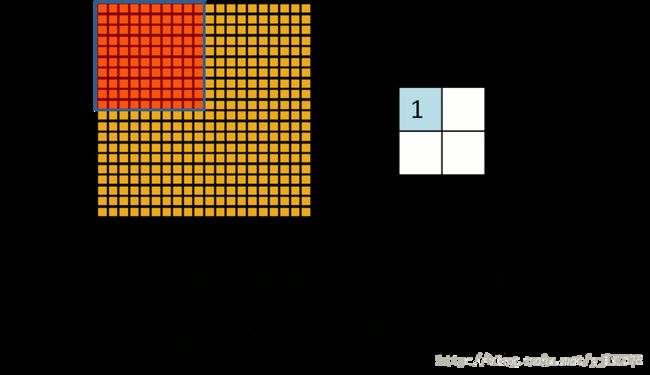
和卷积一样, 池化也有一个滑动的核, 可以称之为滑动窗口, 上图中滑动窗口的大小为 2 × 2 2 × 2 2×2, 步幅为 2 2 2 , 每滑动到一个区域, 则取最大值作为输出, 这样的操作称为 Max Pooling. 还可以采用输出均值的方式, 称为 Mean Pooling.
池化层具体作用:
- 特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
- 特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
- 在一定程度上防止过拟合,更方便优化。
注意:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补(这里的深度变为原来的2倍)。
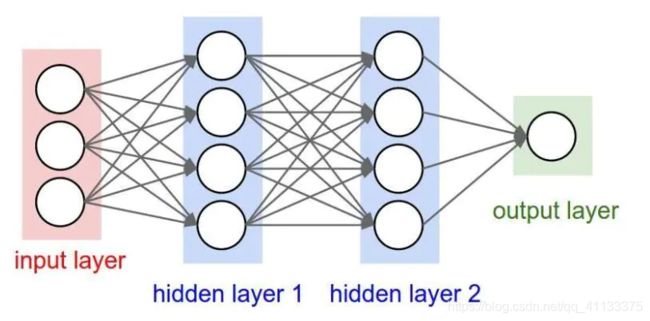
5.全连接层
经过若干层的卷积, 池化操作后, 将得到的特征图依次按行展开, 连接成向量, 输入全连接网络。
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:
卷积神经网络之训练算法
1.同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距。
2.找到最小化损失函数的W和b, CNN中用的算法是SGD(随机梯度下降)。
卷积神经网络之优缺点
优点
•共享卷积核,对高维数据处理无压力
•无需手动选取特征,训练好权重,即得特征分类效果好
缺点
•需要调参,需要大样本量,训练最好要GPU
•物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
卷积神经网络之典型CNN
- LeNet,这是最早用于数字识别的CNN
- AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比
- LeNet更深,用多层小卷积层叠加替换单大卷积层。
- ZF Net, 2013 ILSVRC比赛冠军
- GoogLeNet, 2014 ILSVRC比赛冠军
- VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
卷积神经网络之 fine-tuning
何谓fine-tuning?
fine-tuning就是使用已用于其他目标、预训练好模型的权重或者部分权重,作为初始值开始训练。
那为什么我们不用随机选取选几个数作为权重初始值?原因很简单,第一,自己从头训练卷积神经网络容易出现问题;第二,fine-tuning能很快收敛到一个较理想的状态,省时又省心。
那fine-tuning的具体做法是?
•复用相同层的权重,新定义层取随机权重初始值
•调大新定义层的的学习率,调小复用层学习率
卷积神经网络的常用框架
Caffe
•源于Berkeley的主流CV工具包,支持C++,python,matlab
•Model Zoo中有大量预训练好的模型供使用
Torch
•Facebook用的卷积神经网络工具包
•通过时域卷积的本地接口,使用非常直观
•定义新网络层简单
TensorFlow
•Google的深度学习框架
•TensorBoard可视化很方便
•数据和模型并行化好,速度快
总结
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
CNN一个非常重要的特点就是头重脚轻(越往输入权值越小,越往输出权值越多),呈现出一个倒三角的形态,这就很好地避免了BP神经网络中反向传播的时候梯度损失得太快。
卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
梯度下降和反向传播算法
与 BP神经网络一样, CNN 也是通过梯度下降和反向传播算法进行训练的。
cnn原理运行图:
https://poloclub.github.io/cnn-explainer/
过拟合、欠拟合、及如何防止过拟合:
https://zhuanlan.zhihu.com/p/72038532
神经网络分类图:
