变分系列 Deep Variational Instance Segmentation 论文阅读笔记
变分系列 Deep Variational Instance Segmentation 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
- 四、深度变分实例分割
-
- 4.1 Mumford-Shah 模型
-
- 从无监督到有监督的设置
- 4.2 深度变分实例分割
- 4.3 损失函数
-
- 二元损失
- 转置不变损失
- 归一化
- 五、实施细节
-
- 实例分割中的 FCN
- 训练
- 置换不变损失
- 离散化到实例分割
- 分类和验证
- 六、实验
-
- 6.1 数据集:
- 6.2 与 SOTA 的比较
-
- PASCAL VOC 和 SBD 数据集上的结果
- COCO 数据集上的结果
- 6.3 消融实验
-
- 推理成本
- 后处理中候选的数量
- 七、讨论与结论
- 变分实例分割的补充材料
-
- 1、DVIS 能够预测多少类的标签?
- 2、用于计算相对损失的窗口尺寸
- 3、归一化和量化
- 4、IoU 头的影响
- 5、在未知类别上的预测实例图
- 6、PASCAL VOC 上的定性结果
- 7、COCO 上的定性结果
写在前面
这是本周的第一篇博文,2023每周一篇博文,继续加油哇~
顺着上一篇博文(弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记)的参考文献找到这篇同样采用了能量函数进行实例分割的方法来读,加深理解。
- 论文地址:Deep Variational Instance Segmentation
- 代码地址:https://github.com/jia2lin3yuan1/2020-instanceSeg
- 收录于:NeurIPS 2020
- 欢迎关注,主页更多干货,持续输出中~
一、Abstract
实例分割的定义,之前的方法通常采用基于搜索的策略:先用一个规则的网格和每个网格块上生成的 proposal 划分图像,之后分类这些 proposal 并细化边界。本文采用一个全卷积网络来训练提出的变分实例分割,其作为一个最小优化函数来解决分段常数下的分割问题。具体来说,拓展了经典的 Mumford-Shah 变分分割算法来解决实例分割 GT 中的 permutation-invariant (置换/排列不变性?)问题。实验效果很好。
二、引言
介绍一下语义实例分割的概念,指出挑战性:1、同属一类的不同实例可能有着类似形状;2、实例的数量在预测时未知;3、实例的标签是 permutation-invariant 的,即随机置换训练 GT 中的实例标签而不会改变学习结果,如下图:
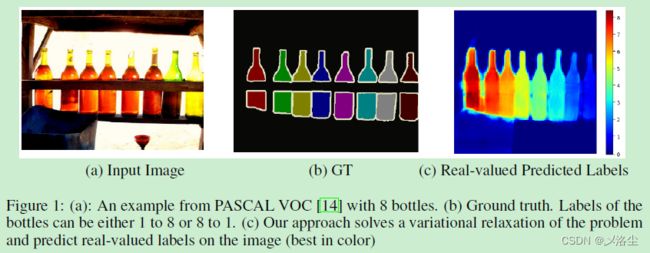
对于这类置换不变的实例标签,不能采用传统的目标函数,如 cross-entropy 损失来训练。常见的解决方式:将检测和分割结合融入到一个两阶段方法中,一个网络产生 proposal,另一个分类和细化每个 proposal,缺点是效率低。有一些改进的方法但是效率仍低。另外一些是无搜索的方法,并不直接产生目标 proposals。大多数方法学习预测每个实例标签中的像素代理,然后通过逐步的后处理来分割每个实例。
提及实例分割与 Mumford-Shah 模型。当时的难度在于从输入的图像中估计非线性函数,但这却可以应用到深度网络中,因为这一函数自然可微分。
这种变分方法和深度学习的结合能够解决深度学习问题,而这些是很难用传统的目标函数,如 cross-entropy 解决的。另一方面,用深度网络参数化变分方法能够建模复杂的图像函数。本文提出深度变分实例分割 deep variational instance segmentation (DVIS),本质是一个直接预测分段常数性质的实例标签的 FCN 网络,每一个常数子区域对应一个实例;提出一种变分目标函数来缓解实例分割中 GT 的置换不变性质。
三、相关工作
实例分割的定义。目前的方法大致分为基于搜索的(有 anchor)和无搜索(无 anchor)的方法。搜索的缺点:慢,无搜方法缺点:不能直接生成实例预测,因此需要后处理。
四、深度变分实例分割
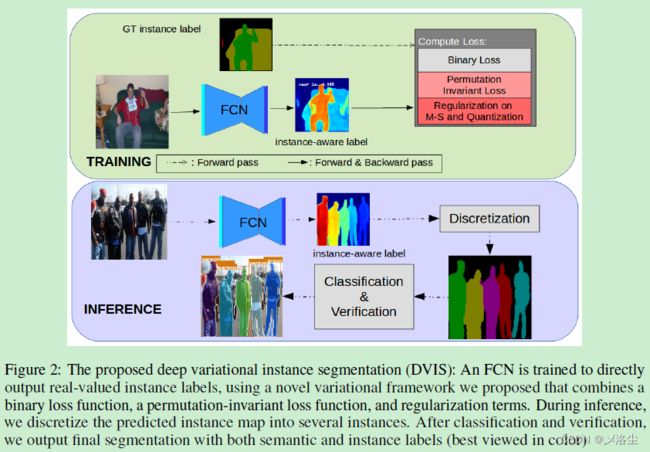
4.1 Mumford-Shah 模型
Mumford-Shah 模型通过计算给定图像中最优的分段光滑曲线,将实例分割任务视为一个连续能量函数最小化问题。图像定义为 I I I,边界域 Ω ∈ R 2 \Omega\in\mathcal{R}^{2} Ω∈R2 为被分割部分,定义一个估计的 I ^ \hat I I^ 和 C ∈ Ω C\in\Omega C∈Ω,此集合的边用边界划分为不同的目标。Mumford-Shah 函数定义为:
F ( I ^ , C ) = ∫ Ω ( I ^ ( x , y ) − I ( x , y ) ) 2 d x d y + μ ∫ Ω ∖ C ∣ ∇ I ^ ∣ 2 d x d y + ν ∣ C ∣ F(\hat{I},C)=\int_\Omega(\hat{I}(x,y)-I(x,y))^2dxdy+\mu\int_{\Omega\setminus C}|\nabla\hat{I}|^2dx dy+\nu|C| F(I^,C)=∫Ω(I^(x,y)−I(x,y))2dxdy+μ∫Ω∖C∣∇I^∣2dxdy+ν∣C∣其中 μ \mu μ、 ν \nu ν 为非负参数, Ω ∖ C \Omega\setminus C Ω∖C 为非边界像素, ∣ C ∣ |C| ∣C∣ 为 C C C 中像素数量。最小化上式本质上旨在优化一个分段的光滑函数(理想情况下在每个段内都是常数),而在边上或者边界上不光滑。第一项使得 I ^ \hat I I^ 更接近 I I I,第二项使得每个分割部分更加光滑,最后一项促使目标轮廓更短从而避免过大分割。
Mumford-Shah 函数被视为稳定的变分模型,能够近似的归一化目标边界的长度,同时能够建模同一图像内的多个目标。然而因其第一项通常强制 I ^ \hat I I^ 接近 I I I,因此传统上仅适用于超像素分割及主动轮廓检测。
从无监督到有监督的设置
无监督和有监督对于分段常函数的优化中,每个段都对应一个目标实例,此时分段的总数未知。每个段内所有的常量以及一个短边界长度同样是实例分割的理想先验。MS 模型中的第二项是一个公共的逐元素项,促进每个分段内都保持一个常数。之前的方法表明第二和第三项可以结合作为一个鲁棒损失。
拓展这一变分方法解决实例分割问题的主要难点在于,如何利用潜在的匹配项 ∫ ( I ^ ( x , y ) − I ( x , y ) ) 2 d x d y \int(\hat{I}(x,y)-I(x,y))^2dxdy ∫(I^(x,y)−I(x,y))2dxdy。一个简单的 MSE 或者 CE 损失由于 GT 标签转置不变的特点,而不能满足实例分割的要求。然而背景标签在整个数据集中都保持相同,因此需要一种新的变分函数。
4.2 深度变分实例分割
通常实例分割中的标签有两个确切的点:像素标签为 0 时,像素为背景;像素标签大于 0 时,标签为置换不变,即:可以将标签转移到不同的目标上而不影响实际意义。因此当定义一个实例分割变分函数时,需要考虑这点:
F ( f , C ) = ∫ Ω L b ( f ( x , y ) , I [ G T ( x , y ) = 0 ] ) d x d y ⏟ Binary Loss + μ ∫ Ω ∥ ∇ f ∥ 2 d x d y + ν ∣ C ∣ ⏟ Regularization + ∫ Ω ∣ f − Round ( f ) ∣ d x d y ⏟ Quantization + ∫ Ω ∫ Ω L p i ( ∣ f ( x 1 , y 1 ) − f ( x 2 , y 2 ) ∣ , I [ G T ( x 1 , y 1 ) ≠ G T ( x 2 , y 2 ) ] ) d x 1 d y 1 d x 2 d y 2 ⏟ Permutation Invariant Loss \begin{aligned} F(f, C)= & \underbrace{\int_{\Omega} \mathcal{L}_{b}\left(f(x, y), \mathbb{I}_{[G T(x, y)=0]}\right) d x d y}_{\text {Binary Loss }}+\underbrace{\mu \int_{\Omega}\|\nabla f\|^{2} d x d y+\nu|C|}_{\text {Regularization }}+\underbrace{\int_{\Omega}|f-\operatorname{Round}(f)| d x d y}_{\text {Quantization }} \\ & +\underbrace{\int_{\Omega} \int_{\Omega} \mathcal{L}_{p i}\left(\left|f\left(x_{1}, y_{1}\right)-f\left(x_{2}, y_{2}\right)\right|, \mathbb{I}_{\left[G T\left(x_{1}, y_{1}\right) \neq G T\left(x_{2}, y_{2}\right)\right]}\right) d x_{1} d y_{1} d x_{2} d y_{2}}_{\text {Permutation Invariant Loss }} \end{aligned} F(f,C)=Binary Loss ∫ΩLb(f(x,y),I[GT(x,y)=0])dxdy+Regularization μ∫Ω∥∇f∥2dxdy+ν∣C∣+Quantization ∫Ω∣f−Round(f)∣dxdy+Permutation Invariant Loss ∫Ω∫ΩLpi(∣f(x1,y1)−f(x2,y2)∣,I[GT(x1,y1)=GT(x2,y2)])dx1dy1dx2dy2其中 f f f 为网络预测的标签图, ω \omega ω 为网络的参数, R o u n d ( ⋅ ) Round(\cdot) Round(⋅) 为取整操作, L b \mathcal{L}_{b} Lb 为标签损失。 L p i \mathcal{L}_{pi} Lpi 为置换不变损失,用于比较两个像素标签的差异: ∣ f ( x 1 , y 1 ) − f ( x 2 , y 2 ) ∣ |f\left(x_{1}, y_{1}\right)-f\left(x_{2}, y_{2}\right)| ∣f(x1,y1)−f(x2,y2)∣ 和 I [ G T ( x 1 , y 1 ) ≠ G T ( x 2 , y 2 ) ] \mathbb{I}_{\left[G T\left(x_{1}, y_{1}\right) \neq G T\left(x_{2}, y_{2}\right)\right]} I[GT(x1,y1)=GT(x2,y2)],这表明了这些像素的 GT 标签是否不同。光滑程度与最小边长度和 Mumford-Shah 中一致。此外,整合一个量化机制,能够驱动输出的标签值更接近整形。
在置换不变损失 L p i \mathcal{L}_{pi} Lpi 中,原则上整合所有在图像内部的非边界上的所有像素点,而不是传统条件区域方法 conditional random field (CRF) 中的小的邻居点。原因在于实例分割是一个固有的非局部问题:由于遮挡,同一实例可以在 2D 中分成几个部分,这些部分可能彼此相距很远。因此,仅利用局部一致性可能不太够。实验结果也表明如果仅强调局部一致性,那么就会在预测的实例标签 f f f 上产生小的,光滑的改变,而这会导致相同实例下另一实例标签发生大的变化。
实际上在所有像素上离散化 L b \mathcal{L}_{b} Lb,在采样的像素对上离散化 L p i \mathcal{L}_{pi} Lpi,像素对上采用的是分层或随机采样。分层采样:在一个像素的 4 邻域内采样所有的中间邻居,并减少更远像素对的采样密度。随机采样:在整个图像上随机选择像素对来计算 L p i \mathcal{L}_{pi} Lpi。实验发现在小的分辨率下,分层采样有效,反之随机采样更有效。
在 CRFs 中,标签来源于分离的集合,然而在变分方法中,标签是连续的。对于CNN来说,很难模拟整个的 CRF 推导过程,而本文的 FCN 可以同时处理大量不确定目标的图像,因为它将标签作为一个连续的真实值。
4.3 损失函数
变分方法中输出的 f f f 值是连续的,因此损失函数要更接近于回归的损失函数。本文主要利用 Huber 损失函数的变体:当 v < θ v<\theta v<θ 时, L h ( v , θ ) = v 2 2 θ L_h(v,\theta)=\frac{v^2}{2\theta} Lh(v,θ)=2θv2,反之 v − θ 2 v-\frac{\theta}{2} v−2θ,这里设置 θ = 0.1 \theta=0.1 θ=0.1。
二元损失
第一项 L b \mathcal{L}_{b} Lb 旨在从 ‘‘stuff’’ 类别,如路、水、空气中分离出标签实例,而这些通常是背景。 L b \mathcal{L}_{b} Lb 使得分割是背景的像素为非正值,而前景目标为正值。设置 G T ( x , y ) = 0 GT(x,y)=0 GT(x,y)=0 在背景像素上而 G T ( x , y ) > 0 GT(x,y)>0 GT(x,y)>0 在前景像素上。于是二元损失计算如下:
L b ( f ( x , y ) , G T ( x , y ) ) = { L h ( R e L U ( f ( x , y ) ) ) if G T ( x , y ) = 0 L h ( R e L U ( m 1 − f ( x , y ) ) ) if G T ( x , y ) > 0 \mathcal{L}_b(f(x,y),GT(x,y))=\begin{cases}L_h(ReLU(f(x,y)))&\quad\text{if}~GT(x,y)=0\\ L_h(ReLU(m_1-f(x,y)))&\quad\text{if}~GT(x,y)>0\end{cases} Lb(f(x,y),GT(x,y))={Lh(ReLU(f(x,y)))Lh(ReLU(m1−f(x,y)))if GT(x,y)=0if GT(x,y)>0其中 R e L U ( x ) = max ( x , 0 ) ReLU(x)=\max(x,0) ReLU(x)=max(x,0) 为 ReLU 激活函数, m 1 m_1 m1 为损失函数的参数,用于从背景中分离出前景。在前景像素中,当 f ( x , y ) ≥ m 1 f(x,y)\geq m_1 f(x,y)≥m1 时,损失为 0,这会缓解有着不同 f ( x , y ) f(x,y) f(x,y) 值的前景目标。在背景像素中,一旦 f ( x , y ) ≤ 0 f(x,y)\leq0 f(x,y)≤0 时,损失为 0。实验中设置 m 1 = 2 m_1=2 m1=2。
本文将这一项设置为 Huber 回归损失,而不是 CE 二分类损失。原因在于:当标签值 ≥ m 1 \geq m_1 ≥m1 时,回归损失能够获得精确的 0 0 0,当标签值 ≤ 0 \leq0 ≤0 时为背景。而 CE 损失则会将预测值推向正负无穷。
转置不变损失
考虑到 GT 标签是转置不变的, L p i \mathcal{L}_{pi} Lpi 强制 GT 实例标签和预测标签的相似性。 p 1 p_1 p1 和 p 2 p_2 p2 为一个邻域中的两个像素,GT 分别为 G T p 1 GT_{p_1} GTp1、 G T p 2 GT_{p_2} GTp2,相应的损失为:
f d = ∣ ReLU ( f ( x 1 , y 1 ) ) − ReLU ( f ( x 2 , y 2 ) ) ∣ L p i ( f d , G T ( x 1 , y 1 ) , G T ( x 2 , y 2 ) ) ) = { L h ( f d ) , if G T ( x 1 , y 1 ) = G T ( x 2 , y 2 ) L h ( m 2 − f d ) , if G T ( x 1 , y 1 ) ≠ G T ( x 2 , y 2 ) \begin{array}{l} f_{d}=\left|\operatorname{ReLU}\left(f\left(x_{1}, y_{1}\right)\right)-\operatorname{ReLU}\left(f\left(x_{2}, y_{2}\right)\right)\right| \\ \left.\mathcal{L}_{p i}\left(f_{d}, G T\left(x_{1}, y_{1}\right), G T\left(x_{2}, y_{2}\right)\right)\right)=\left\{\begin{array}{ll} L_{h}\left(f_{d}\right), & \text { if } G T\left(x_{1}, y_{1}\right)=G T\left(x_{2}, y_{2}\right) \\ L_{h}\left(m_{2}-f_{d}\right), & \text { if } G T\left(x_{1}, y_{1}\right) \neq G T\left(x_{2}, y_{2}\right) \end{array}\right. \\ \end{array} fd=∣ReLU(f(x1,y1))−ReLU(f(x2,y2))∣Lpi(fd,GT(x1,y1),GT(x2,y2)))={Lh(fd),Lh(m2−fd), if GT(x1,y1)=GT(x2,y2) if GT(x1,y1)=GT(x2,y2)其中 m 2 m_2 m2 为调整预测标签和不同实例的裕量值,实验中设置 m 2 = 1 m_2=1 m2=1。当预测标签在两个像素上的差值大于 1 1 1 时,表明这两个像素属于不同的实例。另一方面,如果两个像素属于同一实例,当且仅当它们的预测标签相同时,损失为 0。
归一化
没有 Mumford-Shah 归一化时,后处理更加困难,于是将 Mumford-Shah 离散化为一个损失函数:
L M S ( f ( x , y ) ) = min ( μ ∥ ∇ f ( x , y ) ∥ 2 , ν ) L_{MS}(f(x,y))=\min(\mu\|\nabla f(x,y)\|^2,\nu) LMS(f(x,y))=min(μ∥∇f(x,y)∥2,ν)这等同于原始的 Mumford-Shah 公式,但并不需要优化项,于是使用一个简单的准凸损失函数作为柯西损失:
L M S ′ ( f ( x , y ) ) = log ( ( f ( x , y ) − f ( x , y + 1 ) ) 2 + ( f ( x , y ) − f ( x + 1 , y ) ) 2 + 1 ) L^\prime_{MS}(f(x,y))=\log\left((f(x,y)-f(x,y+1))^2+(f(x,y)−f(x+1,y))^2+1\right) LMS′(f(x,y))=log((f(x,y)−f(x,y+1))2+(f(x,y)−f(x+1,y))2+1)
最后,采用量化方法缩小输出的标签与最近整数的距离,这一项的梯度从第一个 f f f 中反向传播。由于取整操作 r o u n d ( ⋅ ) round(\cdot) round(⋅) 为分段常量,因此梯度为 0。量化操作能够在不同的标签值中建立充分的裕量,这使得后处理更加简单。
五、实施细节
实例分割中的 FCN
ResNet-50 和 ResNet-101 输出步长为 8,之后使用一个类似 FPN 的上采样 2 倍分支来产生高分辨率的输出。FCN 最后一层输出真实值标签来作为一个输出通道,用于计算变分损失和反向传播。增加一层 ReLU 来去除负标签输出,注意并未采用 FPN 中的多个输出头。
训练
输入图像尺寸:PASCAL VOC 513 × 513 513\times513 513×513;COCO 最小边长 700。
置换不变损失
输入单个 H × W H\times W H×W 的图像,FCN 下采样因子 d d d,输出尺寸 H d × W d × 1 \frac{H}{d}\times\frac{W}{d}\times1 dH×dW×1,于是像素数量 H W d 2 × H W d 2 \frac{HW}{d^2}\times\frac{HW}{d^2} d2HW×d2HW。在模型中,二元损失使得仅实例内的像素对得以考虑,因此减少了需要计算的像素量。之后分层采样这些像素对来计算置换不变损失。
给定一个像素 ( x , y ) (x,y) (x,y),窗口尺寸为 w w w,采样距离中心区域为 c c c( c < r c
离散化到实例分割
在获得真实实例标签值之后,应用平移分割算法在不同的带宽 0.9,0.4 上,离散化到两个不同的标签图。当 m 2 m_2 m2 固定为 1,带宽 0.9 能够使得模型分割出不同的目标。当模型不能充分地分割目标时,带宽 0.4 能够帮助分割目标。这两种带宽在实验中已经证实。
分类和验证
利用一个分类网络来验证分割:首先利用 ROIAlign 从 FCN 中每个预测的实例 bounding box 中提取 CNN 特征,与预测的实例二分类 mask 拼接。之后利用一个 7 层的小卷积网络来分类每个预测的实例到预定义的语义标签中。此外,利用一个 IoU 头尝试预测 Huber 回归损失中,预测实例与最佳匹配到的 GT 实例 IOU,最后通过阈值过滤掉虚假正样本。
六、实验
6.1 数据集:
- PASCAL VOC 2012
- PASCAL SBD
- COCO
6.2 与 SOTA 的比较
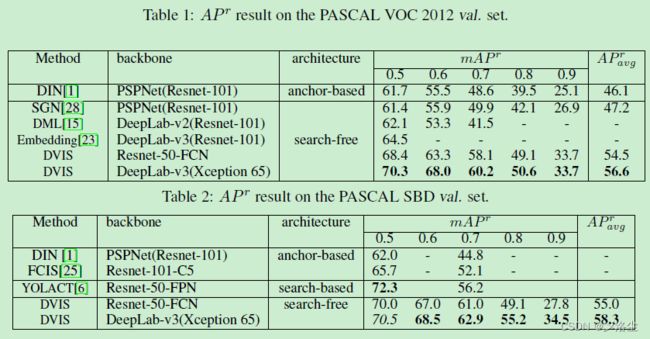
PASCAL VOC 和 SBD 数据集上的结果
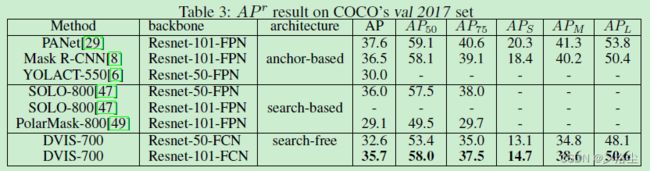
COCO 数据集上的结果

6.3 消融实验
推理成本
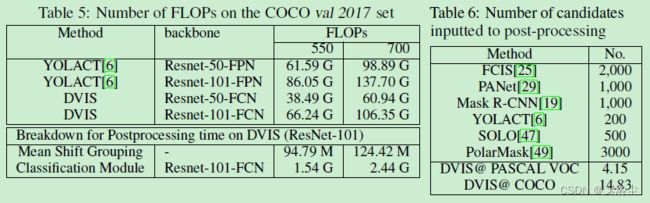
后处理中候选的数量
上表 6。
七、讨论与结论
本文提出深度变分实例分割,将实例分割放缩为变分问题,提出一种包含置换不变损失的变分目标函数,能够端到端的训练 FCN 网络,直接预测图像中真实的实例标签值。在推理阶段,分离预测的连续标签,然后利用小的 CNN 网络将他们划分到语义类别上。实验效果很好。
DVIS 不同于大多数基于搜索的方法在于:以单个的全局视角来处理整个图像。大多数基于搜索的方法查找每个位置区域来定位小的物体,而 DVIS 直接一次查找整个图像并提取目标信息,因此可能忽略了小的目标。但是这种方法能够应用在分割精度不高的快速分割场景中。
变分实例分割的补充材料
1、DVIS 能够预测多少类的标签?

2、用于计算相对损失的窗口尺寸

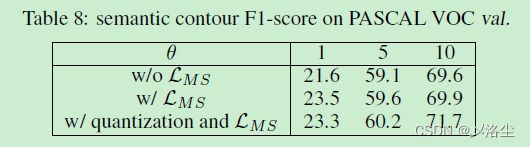
3、归一化和量化

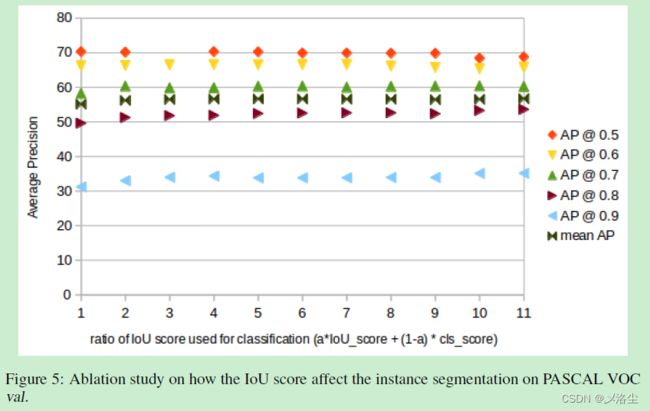
4、IoU 头的影响
5、在未知类别上的预测实例图

6、PASCAL VOC 上的定性结果

7、COCO 上的定性结果



写在后面
这一类数学性质的文章如果文章本身语言表达不行,读起来还是够呛,但工作量也是足够了,希望通过阅读代码得到进一步的收获~