《从零开始学架构》读书笔记(上)
《从零开始学架构》读书笔记(上)
最近空闲时间比较多,花了几天时间读完这本书,整理下读书笔记。
思维导图
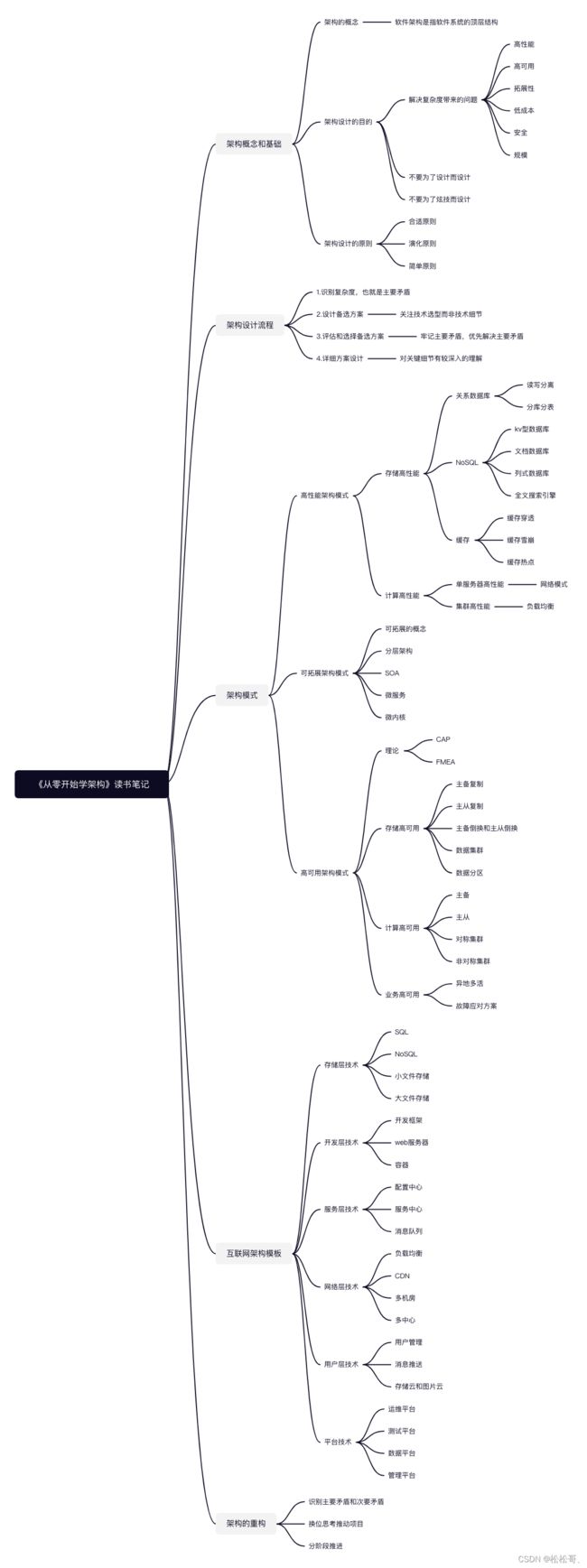
架构概念和基础
架构的概念
软件架构是指软件系统的顶层结构。
- 架构需要明确系统包含哪些“个体”
- 架构需要明确个体运作和协作的规则
架构设计的目的
架构设计的主要目的是为了解决复杂度带来的问题,也就是当前系统重存在非常尖锐的矛盾,为了解决这个矛盾而进行架构的设计。
那么,软件的复杂度主要来源有哪些呢?主要有:
- 高性能
- 高可用
- 可拓展性
- 低成本
- 安全
- 规模
常见的架构目的误区有:
- 为了设计而设计。也许当前业务比较简单,不需要进行设计。
- 为了体现自己技术能力进行设计
架构设计的原则
合适原则
合适优于业界领先
要认识当前业务的主要矛盾和业务特点,围绕解决主要矛盾进行架构的设计。
简单原则
简单优于复杂
越简单越容易理解,越简单越不容易出错,越简单后续维护成本越低。
演化原则
演化优于一步到位
识别主要矛盾和次要矛盾,优先解决主要矛盾,避免一口吃成大胖子。
架构设计流程
识别主要矛盾
架构设计的本质目的是为了解决软件系统与当前业务的矛盾。矛盾又分主要矛盾和次要矛盾,我们要分析业务特点,识别主要矛盾,优先解决主要矛盾。
设计备选方案
这里作者的意思就是靠平时对过去或者社区方案的积累,然后组合一下,稍作修改。
那怎么积累呢?作者在后续章节介绍了很多模式和常用架构,算是帮我们完成了初步的积累。
这里备选方案有几个点:
- 备选方案的数量以3-5个为最佳。少则狭隘,多则迷惑
- 备选方案的差异要比较明显
- 备选方案的技术不要只限于已经熟悉的技术,多看看新的技术
评估和选择备选方案
选择备选方案时,要围绕主要矛盾进行选择,并根据当前的业务发展情况、团队人员规模和技能、业务发展预测等因素进行综合评估。
详细方案设计
这一阶段主要就是完善技术细节,确定排期。
高性能架构模式
存储高性能
关系型数据库
关系型数据库业务中一般常用的是MySQL,是很多业务系统中关键和核心的存储系统。
一般一台单机MySQL服务器性能很有限,还要面对慢查询等问题,业务量稍微大一点就要考虑它的性能问题了。一般常见的改造方式有两种。
第一种是读写分离,其本质是将访问压力分散到多个节点,但是没有分散存储压力,还是一个节点存储着全部数据,另外节点间的数据复制是有延迟的,可能会引起数据一致性问题。
另一种就是分库分表,既可以分散访问压力,又可以分散存储压力。看似很美好,但是会带来很多问题,例如:
- join操作。一旦分库,就用不了join操作了,也许就要查两次进行与操作,复杂度上升
- 事务问题。一致性要求比较高的数据就无法通过事务来进行保障了。
- 成本问题
分库分表还需要面对的一个问题是怎么分?常见的有垂直分表和水平分表。
垂直分表适合讲表中不常用且占空间大的列拆分出去,主要造成的影响是表的数量要增加,而且会带来一定的字段冗余。
水平分表适合单表行数特别大的表,行数过多,查询就会越慢。所以要对其切分,拆成列字段相同的多个表。当行数过大时不得不进行拆分,但进行拆分又会带来很多问题,例如:
- 路由问题:拆分之后怎么路由,根据
范围路由还是hash路由还是单独维护一张路由表呢? - join操作:拆分之后基本和join操作说拜拜
- count计数操作:遇到技术需求一般只能遍历累加或者维护计数表等手段。对于内部统计需求可以采用前者,如果是访问量比较大的线上需求,则优先考虑后者实现。
- order by排序问题:这种问题都可以出一道算法题来面试。
NoSQL
上面的关系型数据虽然比较常用且功能强大,但是还是有很多问题不能解决,例如:
- 存储的都是行记录,不能存储数据结构,例如列表
- 列拓展不方便,MySQL加一个字段就要手动操作下,还可能长时间锁表
- io比较高,比较是放到磁盘的嘛
- 全文搜索能力比较弱
为了解决上述问题,诞生了很多NoSQL解决方案。常见的NoSQL方案有以下四类:
- K-V存储。解决关系数据库无法存储数据结构的问题,以Redis为代表
- 文档数据库。解决关系数据库schema强约束的问题,以MongoDB为代表
- 列式数据库。解决关系数据库大数据场景下io问题,以Hbase为代表
- 全文搜索引擎。解决关系数据库的全文搜索性能问题,以elasticsearch为代表
K-V存储
最场景的存储的就是Redis了,Redis大家都很熟悉,支持很多数据结构且性能有保证,但有一个缺点就是事务支持比较差,Redis的事务真是一言难尽,中间命令出错还是会继续执行,还不支持回滚。Redis官方说出错就是你自己的编程问题,回滚也不能避免你的编程问题。另外虽然Redis支持RDB和AOF两种持久化方式,但是宕机情况下还是会丢一部分数据。
文档数据库
MongoDB也都很熟悉,性能强大,没有字段的约束,很是好用。
但是,缺点是事务支持比较差(比Redis强)和无法join(Redis也不行)。所以这里面试常见的一个考点就是MongoDB和Redis的区别,这里列一下
- 性能方面,二者都很高,总体而言,TPS 方面 Redis 要大于 MongoDB;
- 可操作性上,MongoDB 支持丰富的数据表达、索引,最类似于关系数据库,支持 丰富的查询语言,操作比 Redis 更为便利;
- 内存及存储方面,MongoDB 适合 大数据量存储,依赖操作系统虚拟做内存管理,采用镜像文件存储,内存占有率比较高,Redis 2.0 后增加 虚拟内存特性,突破物理内存限制,数据可以设置时效性;
- 数据持久化和数据恢复,MongoDB 1.8 后,采用 binlog 方式(同 MySQL)支持持久化,增加了可靠性,而 Redis 依赖快照进行持久化、AOF 增强可靠性,但是增强可靠性的同时,也会影响访问性能;
- 数据分析上,MongoDB 内置 数据分析功能(mapreduce),而 Redis 不支持数据分析;
- 应用场景不同,MongoDB 适合海量数据,侧重于访问效率的提升,而 Redis 适合于较小数据量,侧重于性能。
列式数据库
列式数据库就是按照列来存储数据的数据库,MySQL以行来存储。主要应用场景是离线大数据分析。
全文搜索引擎
提到全文搜索就不能不提倒排索引,倒排索引基本原理是建立单词到文档的索引,一般实际应用场景中还是需要倒排索引+正排索引相结合的方式使用,毕竟你搜索出文档ID列表后还需要根据文档ID获取文档详情。
这方面比较常用的就是Elasticsearch了,es是分布式的文档存储方式,每个字段的所有数据都是默认被索引的,性能也非常强悍。
缓存
缓存一般用在读多写少的场景。存储一般采用Redis或者memcache。但是采用缓存必须要面对的就是数据一致性的问题,怎么更新数据?更新频率?都要根据业务特点来具体分析。
除了数据一致性,还会遇到缓存失效的问题,一般会有以下几个场景:
- 缓存穿透。数据既不在缓存也不在数据库中。常见的方案有三种:
非法请求的限制、缓存空值或者默认值、使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在; - 缓存雪崩。数据不在缓存中,导致大量请求访问了数据库。常见的解决方案有:
均匀设置过期时间、互斥锁、双 key 策略、后台更新缓存; - 缓存击穿。跟雪崩类似,但是场景是单key单点。解决方案类似。