365天深度学习训练营-第J6周:ResNeXt-50实战解析
目录
一、前言
二、论文解读
研究背景
研究内容
研究结果
研究意义
三、关键解读
Aggregated Residual Transformations(AggResNet)
Random Erasing和Mixup
四、对比ResNet50V2、DenseNet
网络结构
精度和计算量
适用范围
五、论文复现
tensorflow
pytorch
一、前言
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊|接辅导、项目定制
● 难度:夯实基础⭐⭐
● 语言:Python3、Pytorch3
● 时间:3月19日-3月23日
要求:
阅读ResNeXt论文,了解作者的构建思路
对比我们之前介绍的ResNet50V2、DenseNet算法
使用ResNeXt-50算法完成猴痘病识别二、论文解读
论文:Aggregated Residual Transformations for Deep Neural Networks
研究背景
在深度神经网络的发展过程中,ResNet(Residual Network)架构由于其出色的性能和易于训练的特点而成为了许多视觉任务的基础模型。ResNet通过添加残差块来构建深度模型,解决了深度模型容易出现梯度消失和梯度爆炸问题的难题。但是,ResNet的性能在一定程度上受到了残差块数量的限制,因为随着深度的增加,每个残差块的参数量也会增加。
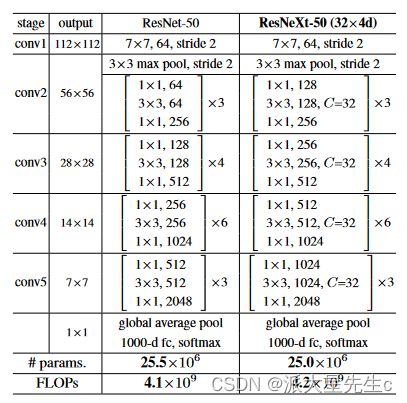
研究内容
为了解决ResNet的性能瓶颈,本文提出了一种新的深度神经网络结构Aggregated Residual Transformations(AggResNet),该结构在保持ResNet残差块的优点的同时,进一步减少了参数量和计算量。具体来说,AggResNet结构由两个模块组成:Aggregation模块和Residual模块。Aggregation模块通过1x1卷积和全局平均池化来减少通道数和空间尺寸,从而大大减少了Residual模块的计算量。Residual模块包含若干个残差块,每个残差块由两个卷积层和一个shortcut组成,shortcut连接上一层的输出和当前层的输入。整个AggResNet结构的层数可以非常深,并且具有很好的可扩展性和可适应性。
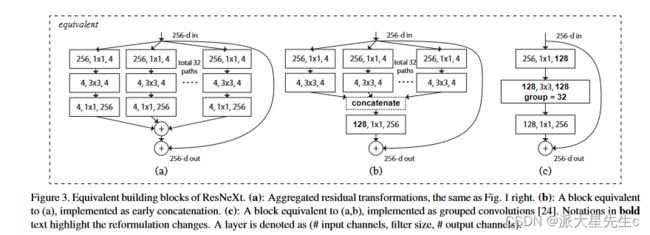
除了AggResNet结构,本文还提出了两种新的训练策略,分别是Random Erasing和Mixup。Random Erasing是一种数据增强技术,随机删除图像中的一些像素,并用随机值填充,从而增强模型的泛化性能。Mixup则是一种数据增强和正则化技术,将两张图像的像素按比例混合,生成一张新的图像作为输入,从而提高模型的鲁棒性和泛化性能。
研究结果
本文在CIFAR-10、CIFAR-100、ImageNet等多个视觉任务上对AggResNet进行了评测,并与其他经典的深度神经网络结构进行了比较。实验结果表明,AggResNet在各项指标上均取得了优异的性能,特别是在较深的网络结构上表现更加突出。此外,本文还证明了Random Erasing和Mixup对模型性能的提升具有显著的效果。
研究意义
本文提出的Aggregated Residual Transformations结构在保持了ResNet优点的同时,进一步减少了计算量和参数量,并且具有很好的可扩展性和可适应性,为深度神经网络的发展提供了一种新的方向。此外,本文提出的Random Erasing和Mixup技术也对深度学习领域的数据增强和正则化技术研究具有一定的启发意义。
总体来说,"Aggregated Residual Transformations for Deep Neural Networks"是一篇非常重要的深度学习论文,提出了一种新的深度神经网络结构和两种新的训练策略,在多个视觉任务上取得了优异的性能,并为深度学习领域的研究提供了重要的启发和参考。
三、关键解读
Aggregated Residual Transformations(AggResNet)
AggResNet结构是由两个模块组成的:Aggregation模块和Residual模块。Aggregation模块通过1x1卷积和全局平均池化来减少通道数和空间尺寸,从而大大减少了Residual模块的计算量。Residual模块包含若干个残差块,每个残差块由两个卷积层和一个shortcut组成,shortcut连接上一层的输出和当前层的输入。整个AggResNet结构的层数可以非常深,并且具有很好的可扩展性和可适应性。
值得注意的是,AggResNet使用了一种分组卷积的方法,可以将不同的通道分组处理,这在某些情况下可以提高计算效率。此外,AggResNet还使用了一种深度可分离卷积的方法,可以将卷积操作分解成深度卷积和逐点卷积两个步骤,从而进一步减少计算量。
Random Erasing和Mixup
Random Erasing是一种数据增强技术,随机删除图像中的一些像素,并用随机值填充,从而增强模型的泛化性能。该技术可以防止模型过分关注图像中的一些细节和特定的区域,从而更好地适应新的数据。此外,Random Erasing还可以增加数据集的多样性,从而降低过拟合的风险。
Mixup则是一种数据增强和正则化技术,将两张图像的像素按比例混合,生成一张新的图像作为输入,从而提高模型的鲁棒性和泛化性能。Mixup的基本思想是在训练过程中使用凸组合的方法,将输入的不同样本进行线性组合,从而生成一些新的数据样本。这种方法可以有效地增加数据集的多样性,从而提高模型的泛化性能。此外,Mixup还可以作为一种正则化技术,可以降低模型的过拟合风险。
四、对比ResNet50V2、DenseNet
ResNet-50v2和DenseNet是两个经典的深度神经网络结构,下面我们来简单比较一下它们和AggResNet的异同点。
网络结构
ResNet-50v2是ResNet系列中的一个经典模型,由50层卷积层、批量归一化、激活函数和池化层构成。它引入了一种全新的残差块结构,即bottleneck结构,使得网络参数量大幅度降低,同时精度也有所提升。
DenseNet是一种全新的网络结构,其特点是不同于传统的网络结构,DenseNet中每一层的输出不仅和前一层的输出有关,还和之前所有层的输出有关,这种密集连接的结构可以有效地缓解梯度消失和参数稀疏问题,提高了模型的泛化能力和精度。
AggResNet则是基于ResNet结构改进而来的新型深度神经网络结构,其特点是采用了聚合残差结构和局部连接结构,同时引入了Random Erasing和Mixup等数据增强和正则化方法,可以进一步提高网络的精度和鲁棒性。
精度和计算量
在ImageNet数据集上,ResNet-50v2和DenseNet在Top-1和Top-5指标上都取得了优异的性能。与之相比,AggResNet在相同的深度下具有更高的精度,并且在参数量和计算量上都显著降低。同时,在较深的网络结构下,AggResNet的优势更加明显,可以达到更高的精度,而ResNet-50v2和DenseNet则难以继续提高精度。
适用范围
ResNet-50v2适用于各种图像分类任务,但在一些特定的视觉任务,如目标检测、语义分割等方面的表现可能不如其他模型。DenseNet则在各种任务中都具有优异的性能,尤其在目标检测和语义分割等像素级别的任务中表现突出。
AggResNet则不仅适用于图像分类任务,同时也可以应用于目标检测、语义分割和行人重识别等视觉任务中,并且在这些任务中具有优异的性能。
总之,ResNet-50v2、DenseNet和AggResNet都是非常优秀的深度神经网络结构,它们在不同的任务和场景中都具有不同的优势和适用性。
五、论文复现
tensorflow
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import (Dense, ZeroPadding2D, Conv2D, MaxPool2D,
GlobalAvgPool2D, Input, BatchNormalization,
Activation, Add, Lambda, concatenate)
from tensorflow.keras.models import Model
from plot_model import plot_model
# ----------------------- #
# groups代表多少组
# g_channels代表每组的特征图数量
# ----------------------- #
def group_conv2_block(x_0, strides, groups, g_channels):
g_list = []
for i in range(groups):
x = Lambda(lambda x: x[:, :, :, i*g_channels: (i+1)*g_channels])(x_0)
x = Conv2D(filters=g_channels, kernel_size=3, strides=strides, padding='same', use_bias=False)(x)
g_list.append(x)
x = concatenate(g_list, axis=3)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Activation('relu')(x)
return x
# 结构快
def block(x, filters, strides=1, groups=32, conv_short=True):
if conv_short:
short_cut = Conv2D(filters=filters*2, kernel_size=1, strides=strides, padding='same')(x)
short_cut = BatchNormalization(epsilon=1.001e-5)(short_cut)
else:
short_cut = x
# 三层卷积
x = Conv2D(filters=filters, kernel_size=1, strides=1, padding='same')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Activation('relu')(x)
g_channels = int(filters/groups)
x = group_conv2_block(x, strides=strides, groups=groups, g_channels=g_channels)
x = Conv2D(filters=filters*2, kernel_size=1, strides=1, padding='same')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Add()([x, short_cut])
x = Activation('relu')(x)
return x
def Resnext(inputs, classes):
x = ZeroPadding2D((3, 3))(inputs)
x = Conv2D(filters=64, kernel_size=7, strides=2, padding='valid')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Activation('relu')(x)
x = ZeroPadding2D((1, 1))(x)
x = MaxPool2D(pool_size=3, strides=2, padding='valid')(x)
x = block(x, filters=128, strides=1, conv_short=True)
x = block(x, filters=128, conv_short=False)
x = block(x, filters=128, conv_short=False)
x = block(x, filters=256, strides=2, conv_short=True)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=512, strides=2, conv_short=True)
x = block(x, filters=512, conv_short=False)
x = block(x, filters=512, conv_short=False)
x = block(x, filters=512, conv_short=False)
x = block(x, filters=512, conv_short=False)
x = block(x, filters=512, conv_short=False)
x = block(x, filters=1024, strides=2, conv_short=True)
x = block(x, filters=1024, conv_short=False)
x = block(x, filters=1024, conv_short=False)
x = GlobalAvgPool2D()(x)
x = Dense(classes, activation='softmax')(x)
return x
pytorch
import torch.nn as nn
import math
__all__ = ['ResNeXt', 'resnext18', 'resnext34', 'resnext50', 'resnext101',
'resnext152']
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, num_group=32):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes*2, stride)
self.bn1 = nn.BatchNorm2d(planes*2)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes*2, planes*2, groups=num_group)
self.bn2 = nn.BatchNorm2d(planes*2)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, num_group=32):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes*2, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes*2)
self.conv2 = nn.Conv2d(planes*2, planes*2, kernel_size=3, stride=stride,
padding=1, bias=False, groups=num_group)
self.bn2 = nn.BatchNorm2d(planes*2)
self.conv3 = nn.Conv2d(planes*2, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNeXt(nn.Module):
def __init__(self, block, layers, num_classes=1000, num_group=32):
self.inplanes = 64
super(ResNeXt, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], num_group)
self.layer2 = self._make_layer(block, 128, layers[1], num_group, stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], num_group, stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], num_group, stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, num_group, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, num_group=num_group))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, num_group=num_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x