计算机视觉(YOLO算法系类)—集合版本
前言:
✌ 作者简介:CC++Edge淇,大家可以叫我--斯淇。(CSDN优质博主建议加这一条!)
个人主页:CC++Edge淇主页
如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步
如果感觉博主的文章还不错的话,还请不吝关注、点赞、收藏三连支持一下博主哦
人生格言:这世界形形色色,做好自己才是真!-——从入门到现在不容易~
每日推荐书:《opencv基础教程》

一、前言(百度百科)
YOLO系列是one-stage且是基于深度学习的回归方法,而R-CNN、Fast-RCNN、Faster-RCNN等是two-stage且是基于深度学习的分类方法。
016年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实时运行。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once(也就是我们常说的YOLO的全称),并将该成果发表在了CVPR 2016上,从而引起了广泛地关注。
YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
深度学习经典检测方法:
- TWO-STAGE(两阶段):Faster-rcnn Mask-Rcnn系列
- ONE-stage(单阶段):YOLO系列
ONE-stage:
最核心的优势:速度非常快,适合做实时检测任务!
但是缺点也是有的,效果通常情况下不会太好!
个人理解:这个算法衡量的(两个指标)1.FPS的速度是快还是慢,2.mAP值的好坏!
TWO-STAGE:
- 速度通常比较慢(5FPS),但是效果通常还是不错的
- 非常实用的通用框架MaskRcnn,建议熟悉下!
指标分析
map指标:综合衡量检测效果;单看精度和recall不太行!

关于.YOLO系列指标分析:

TP的意思:true positives (TP正类判定位正类)
FP就是负类判定为正类“存伪”
FN:正类判断为负类“去真”,明明是小狗偏给判断为小猫!
TN:负类判定为负类!
检测任务中的精度和召回率分别代表

基于置信度阈值来计算,例如分别计算0.9;0.8;0.7
0.9时:TP+FP = 1,TP = 1 ;FN = 2;Precision=1/1;Recall=1/3;
YOLO-V1
把检测问题转化成回归问题,一个CNN就搞定了!
可以对视频进行实时检测,应用领域非常广!
YOLOv1采用的是“分开使用的”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。通过这种方式,我们就不需要再额外设计一个RPN网络,这正是YOLOv1作为单阶段网络的简单快捷之处!
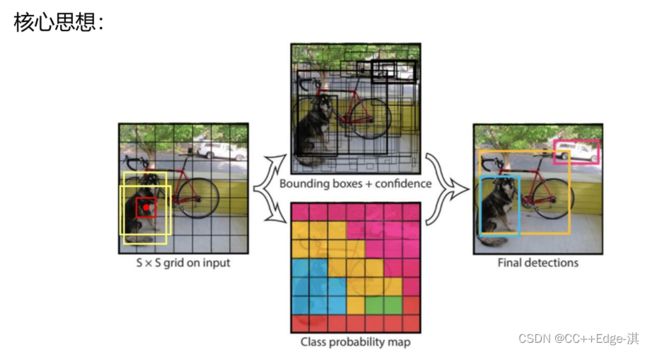
网络架构:
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
- YOLO在输入连接里面有一个全连接层,所以说这里必须做一个限制输入数据的大小(必须是448*448*3)
- 并且需要杂计算机里面设计一个损失函数,在损失函数里面(设置好损失的最小值)
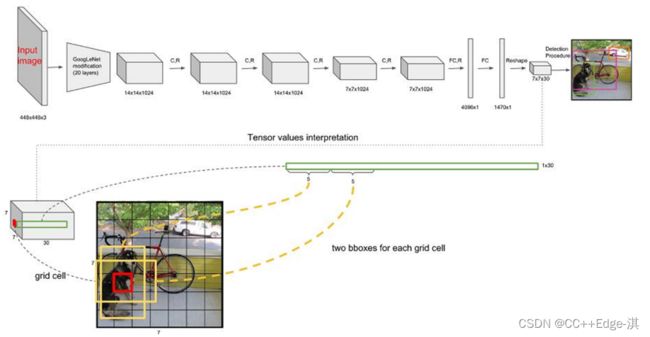
每个数字的含义:
1.10 =(X,Y,H,W,C)*B(2个)
2.当前数据集中有20个类别
3.7*7表示最终网格的大小
4.(S*S)*(B*5+C) 给出最终预测结果等于多少!
损失函数:
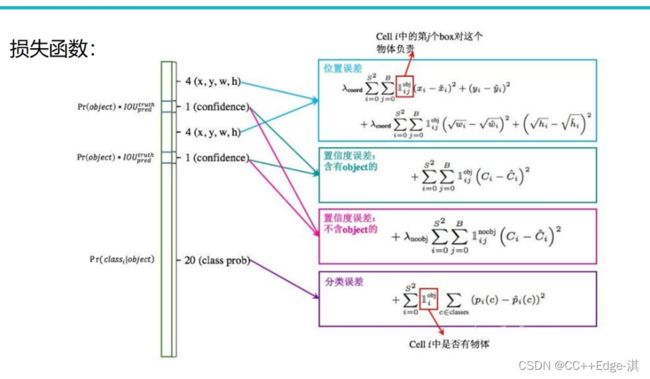
损失由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失
定位误差比分类误差更大,所以增加对定位误差的惩罚,使λ c o o r d = 5 λ。
YOLO-V1 (V1 内容介绍一遍)
优点:快速,简单!
问题1:每个Cell只预测一个类别,如果重叠无法解决
问题2:小物体检测效果一般,长宽比可选的但单一
具体说明一点优点:
- YOLO检测的速度其实非常快,拿标准版的YOLO来说每秒可以处理的图像为40-45秒每张图片!当然极速版的可以处理150帧的图像!!!!这也就是YOLO优于其他的方式!!
- YOLO的检测能力要比其他的监测系统快两倍!其迁移能力强,能过运用于多种的新的领域!
局限:
- YOLO对于小的群体的检测效果并不好,如果同时检测两个框,并且属于同一个类可能会出现错误!!
- 损失函数的问题也同样影响大,定位误差以及检测效果的偏移,和不同之间的角度问题上同样偏弱!
YOLO系列—V2
更快!更强!
YOLO-V2-Batch Normalization
V2版本舍弃Dropout,卷积后全部加入Batch Normalization(如果不加这个Batch Normalization,则数据似乎不可控制!)
网络的每一层的输入都做了归一化,收敛相对更容易
经过Batch Normalization处理后的网络会提升2%的mAP
从现在的角度来看,Batch Normalization已经成网络必备处理
网络结构层特点:
YOLO-V2-更大的分辨率
V1训练时用的是224*224,测试时使用448*448 (版本原因:测试时候使用了改进448*448
可能导致模型水土不服,V2训练时额外又进行了10次448*448 的微调
使用高分辨率分类器后,YOLOv2的mAP提升了约4%

YOLO-V2-网络结构
DarkNet,实际输入为416*416
没有FC层,5次降采样,(13*13)
1*1卷积节省了很多参数
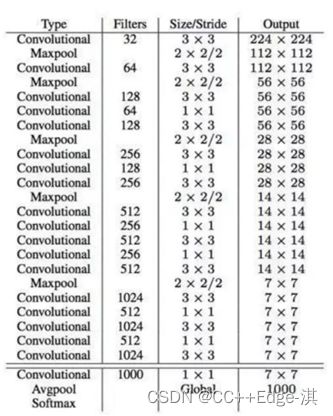
与第一代半版本相比足足大大了一倍的数据
引入 Anchor Box 机制:
在YOLOv1中,作者设计了端对端的网路,直接对边界框的位置(x, y, w, h)进行预测。这样做虽然简单,但是由于没有类似R-CNN系列的推荐区域,所以网络在前期训练时非常困难,很难收敛。于是,自YOLOv2开始,引入了 Anchors box 机制,希望通过提前筛选得到的具有代表性先验框Anchors,使得网络在训练时更容易收敛。
在 Faster R-CNN 算法中,是通过预测 bounding box 与 ground truth 的位置偏移值 t x , t y t_x
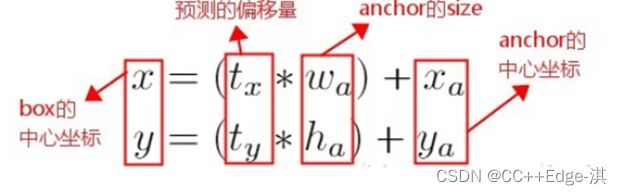
这个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性。
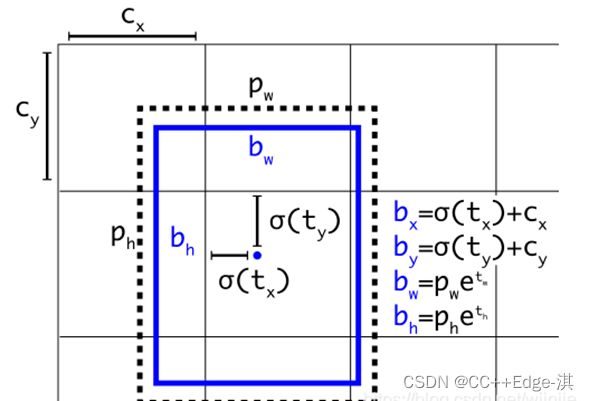
因此 YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标( C x , C y ) (C_x, C_y)的相对偏移量,同时为了将bounding box的中心点约束在当前网格中,使用 sigmoid 函数将tx,ty归一化处理,将值约束在0—1,这使得模型训练更加稳定
下图为 Anchor box 与 bounding box 转换示意图,其中蓝色的是要预测的bounding box,黑色虚线框是Anchor box。
YOLO-V2-聚类提取先验框:
faster-rcnn系列选择的先验比例都是常规的,但是不一定完全适合数据集
K-means聚类中的距离:
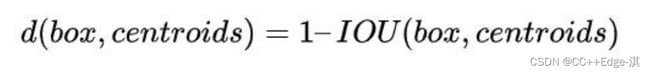 (距离的定义:是1-IOU来限制一下数值,不会误差太大)
(距离的定义:是1-IOU来限制一下数值,不会误差太大)
K=5刚好取到折中的数据!

YOLO-V2-Anchor Box
通过引入anchor boxes,使得预测的box数量更多(
13*13*n)
跟faster-rcnn系列不同的是先验框并不是直接按照长宽固定比给定

Recall(的值越高,检测出来的可能性就越大)
YOLO-V2-Directed Location Prediction
bbox:中心为(xp,yp);宽和高为(wp,hp),则: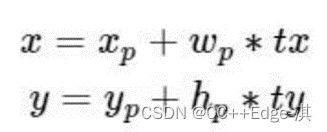
tx=1,则将bbox在x轴向右移动wp;tx=−1则将其向左移动wp
这样会导致收敛问题,模型不稳定,尤其是刚开始进行训练的时候
V2中并没有直接使用偏移量,而是选择相对grid cell的偏移量(不会飘逸)
计算公式为: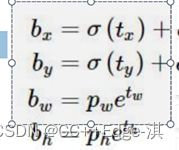

感受野的作用!!
概述来说就是特征图上的点能看到原始图像多大区域!
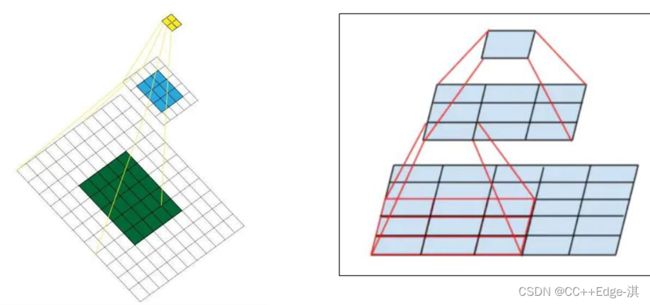
(越大的广视野外,看到的范围就越大)相当于原始区域的感受数据!!
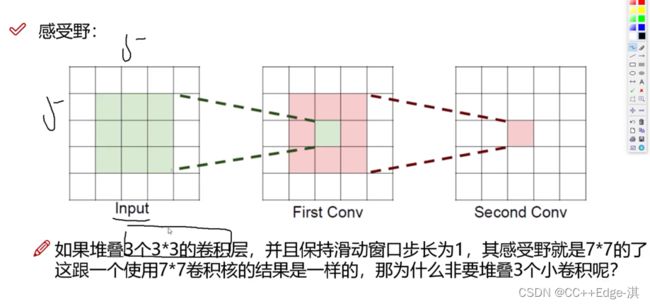
但是市面上却没有大的(卷积和),并没有太多小的卷积和!
假设输入大小都是h*w*c,并且都使用c个卷积核(得到c个特征图),可以来计算
一下其各自所需参数:

这一步看起来三个卷积和的参数更加省,更有效率!
4.很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取
也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,这就
是VGG网络的基本出发点,用小的卷积核来完成体特征提取操作。
- 最后一层时感受野太大了,小目标可能丢失了,需融合之前的特征
最后一层擅长找大物体!最好做到大小通吃!!!
YOLO-V2-Multi-Scale:
 都是卷积操作可没人能限制我了!一定iterations之后改变输入图片大小
都是卷积操作可没人能限制我了!一定iterations之后改变输入图片大小
YOLO-V3(简称巅峰之作)
2018年,作者 Redmon 又在 YOLOv2 的基础上做了一些改进。特征提取部分采用darknet-53网络结构代替原来的darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。
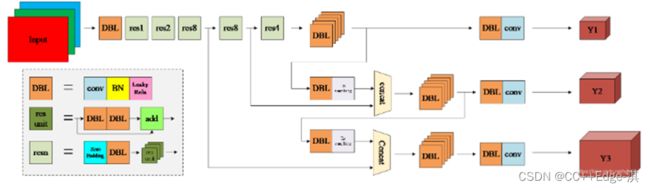
对此进行说明:
DBL: 一个卷积层、一个批量归一化层和一个Leaky ReLU组成的基本卷积单元。
- res unit: 输入通过两个DBL后,再与原输入进行add;这是一种常规的残差单元。残差单元的目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
- resn: 其中的n表示n个res unit;所以 resn = Zero Padding + DBL + n × res unit 。
- concat: 将darknet-53的中间层和后面的某一层的上采样进行张量拼接,达到多尺度特征融合的目的。这与残差层的add操作是不一样的,拼接会扩充张量的维度,而add直接相加不会导致张量维度的改变。
- Y1、Y2、Y3: 分别表示YOLOv3三种尺度的输出
终于到V3了!!!
(V2的缺点需要改进,所以来到了V3来做到了最大的改进!)
-
- 最大的改进就是网络结构,使其更适合小目标检测
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体
- 先验框更丰富了,3种scale,每种3个规格,一共9种
- softmax改进,预测多标签任务
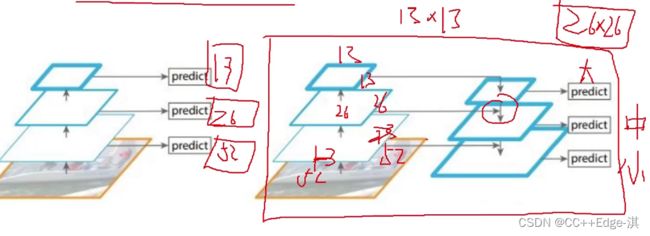
多scale类型,YOLO3为了检测不同大小的物体,设计3个scale
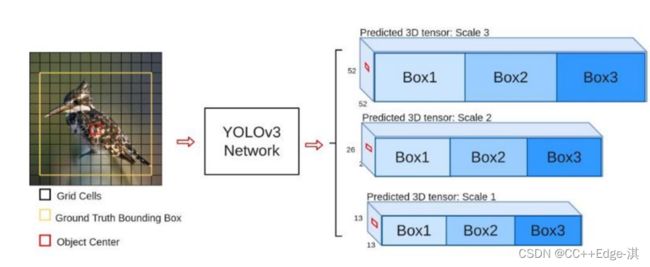
三种不同大小的特征图,可以检测的时候更好的使用!
分别13,26.,52
scale变换经典方法:
下列解释两个图片:金字塔,右图:单一的输入
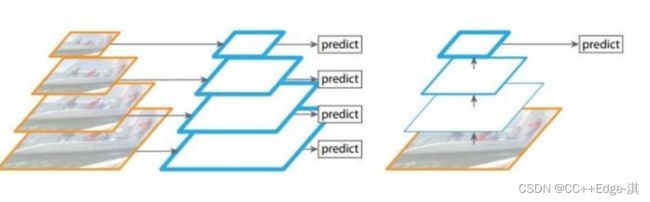
金字塔的数据依次输入,比较好控制图像的变换!(换到其他算法当中还行,因为他并不考虑其速度!,但是再scale算法当中确是不合适的!!!)
右图的单一输入:单一的输出结果!!
左图:对不同的特征图分别利用;右图:不同的特征图融合后进行预测;
右图做完上采样,实现一个大,中,小目标的实现!
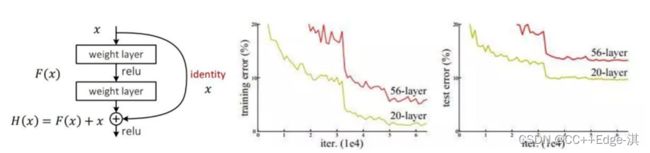
1.残差连接-为了更好的特征
2.从今天的角度来看,基本所有网络架构都用上了残差连接的方法
3.V3中也用了resnet的思想,堆叠更多的层来进行特征提取
(这里说白了就是一个思想的集合点,说白了yolo就是把当年一些最优秀的思想,例如resnet融合进来,做了一个整合!)
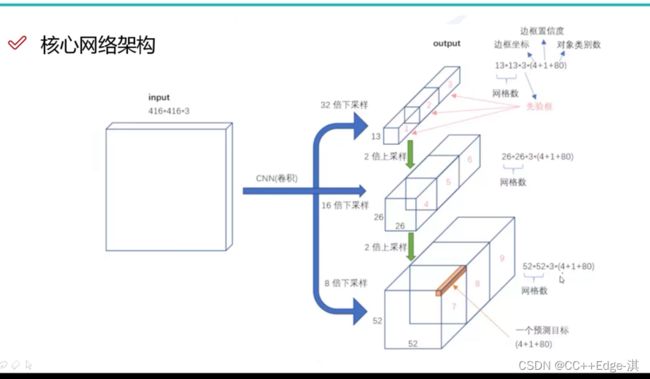
核心网络架构
1.没有池化和全连接层,全部卷积
2.下采样通过stride为2实现
3.3种scale,更多先验框
4.基本上当下经典做法全融入了

核心网络结构
先验框设计:
1.YOLO-V2中选了5个,这回更多了,一共有9种
2.13*13特征图上:(116x90),(156x198),(373x326)
3.26*26特征图上:(30x61),(62x45),(59x119)
4.52*52特征图上:(10x13),(16x30),(33x23)

以上的数据(术业有专攻,大的数据就交给大的处理特征图上)
YOLO-V2中选了5个,这回更多了,一共有9种

最后一点!!!
softmax层替代
1.物体检测任务中可能一个物体有多个标签
2.logistic激活函数来完成,这样就能预测每一个类别是/不是