3_Cortex-M3和M4 架构
文章目录
- Cortex-M3和M4 架构
-
- 简介
- 编程模型
-
- 操作模式和状态
- 寄存器
- 特殊寄存器
-
- 程序状态寄存器
- PRIMASK、FAULTMASK 和 BASEPRI 寄存器
-
- PRIMASK
- FAULTMASK
- BASEPRI
- CONTROL寄存器
- 浮点寄存器
-
- 浮点状态和控制寄存器(FPSCR)
- 经过存储器映射的浮点单元控制寄存器
- 应用程序状态寄存器APSR
-
- 整数状态标志
- Q状态标志
- GE位
- 存储器系统
-
- 存储器系统特性
- 存储器映射
- 栈存储
- 存储器保护单元
- 异常和中断
-
- 异常概述
- 嵌套向量中断控制器NVIC
-
- 灵活的中断和异常管理
- 嵌套向量/中断支持
- 向量化的异常/中断入口
- 中断屏蔽
- 向量表
- 错误处理
- 系统控制块SCB
- 复位和复位流程
Cortex-M3和M4 架构
简介
Cortex-M3和M4都基于ARMv7-M架构,在一般的应用中使用Cortex-M3和M4微控制器,无需了解架构的详细内容,只需要对编程模型、异常处理、存储器映射、外设使用及软件驱动库文件使用等方面做个了解即可。
编程模型
操作模式和状态
Cortex-M3和M4处理器有两种操作状态和两个模式,另外还可以区分特权和非特权访问等级。如下图所示。
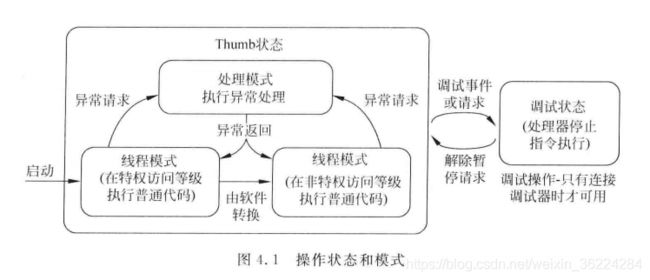
特权访问等级可以访问处理器中的所有资源,而非特权访问等级则意味着有些存储器区域时不能访问的,有些操作也时无法使用的,非特权访问等级还可被称作用户状态。
操作状态分为:
调试状态:当处理器被暂停(如通过调试器触发断点)后,就会进入调试状态,并停止指令执行。Thumb状态:当处理器在执行程序代码,就处于Thumb状态。由于Cortex-M处理器不支持ARM指令集,因此ARM状态并不存在。
操作模式分为:
处理模式:执行中断服务程序(ISR)等异常处理,在处理模式下,处理器总是具有特权访问等级。线程模式:在执行普通的应用程序代码时,粗粝其可以处于特权访问等级,也可以处于非特权访问等级,实际的访问等级由特殊寄存器CONTROL控制。
软件可以将处理器从特权模式切换到非特权模式,但是无法将自身从非特权模式切换到特权模式,这种操作需要借助于系统异常机制。
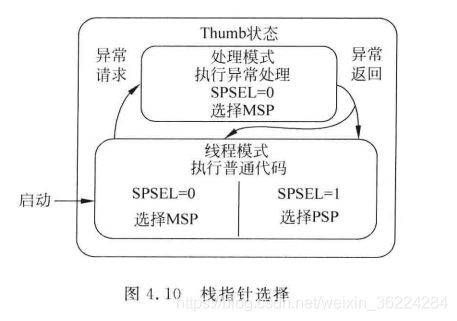
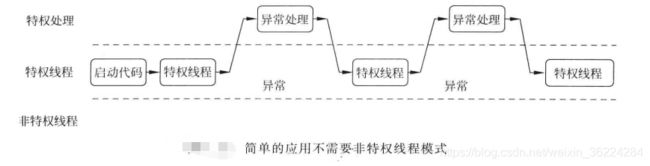
Cortex-M处理器在启动后默认处于特权线程模式以及Thumb状态。对于简单的应用,非特权线程模式和影子SP可能不会用到,如下图所示。Cortex-M处理器不支持非特权线程模式,不过在Cortex-M0+上是可选的。
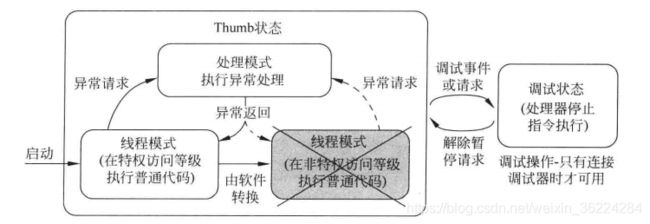
调试状态仅用于调试操作,可以通过两种方式进入调试状态:
- 调试器发起暂停请求
- 处理器中的调试部件产生调试事件
在此状态下,调试器可以访问或修改处理器寄存器的数值,无论在Thumb状态还是调试状态,调试器都可以访问处理器内外的外设等系统存储器。
寄存器
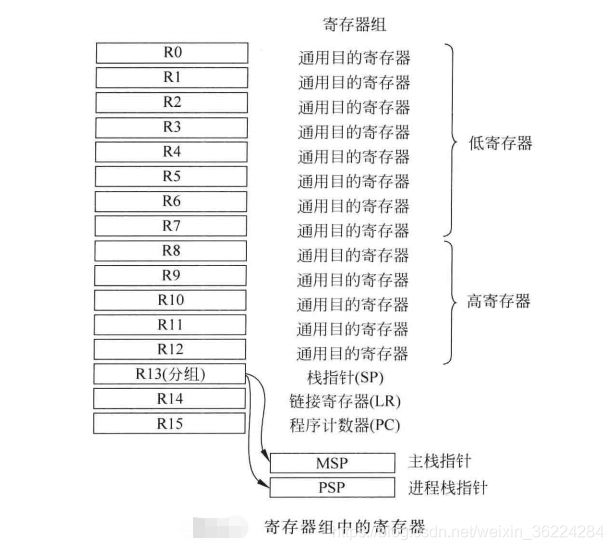
Cortex-M3和M4处理器在内核中由多个执行数据处理和控制的寄存器,这些寄存器大都以寄存器组的方式进行了分组。每个数据处理指令都指定了所需的操作和源寄存器,若需要,还有目的寄存器。对于ARM架构,若处理的是存储器中的数据,需要将其从存储器加载到寄存器组中的寄存器里,在处理器内处理完成后,若由必要,还要写回存储器中,这种方式称为 加载-存储架构。由于寄存器组中由丰富的寄存器,这种设计使用起来非常方便,而且可以用C编译器生成高效的程序代码。
Cortex-M3和M4处理器的寄存器组中有16个寄存器,其中13个为32位通用寄存器,其他3个为特殊用途。
如下图所示:
寄存器具体的使用说明参考文章:《ARM-THUMB子程序调用规则-ATPCS》
特殊寄存器
除了寄存器组中的寄存器外,处理器中还存在多个特殊寄存器,这些寄存器用于表示处理器状态、定义了操作状态和中断异常屏蔽,如下图所示:
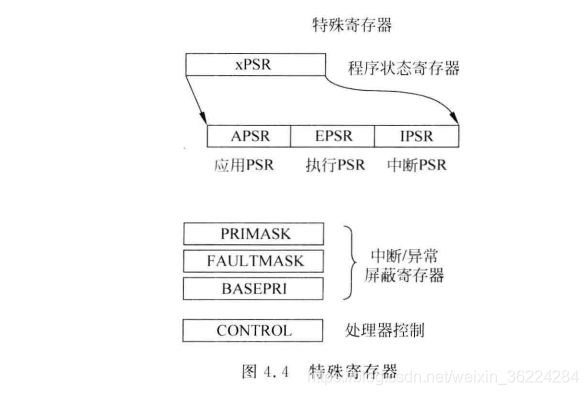
在使用C语言编程开发简单的应用时,一般不会去访问这些寄存器,在开发嵌入式OS或者需要高级的中断屏蔽特性(如进入临界区等)时,需要访问它们。
特殊寄存器未经过存储器映射,可以使用MSR和MRS等特殊寄存器访问指令来进行访问。
CMSIS-Core也提供了几个用于访问特殊寄存器的C函数,记得不要把特殊寄存器和其他控制器架构的特殊功能寄存器(SFR)搞混乱了,这个一般指的是用于I/O控制的寄存器。
程序状态寄存器
程序状态寄存器包括下面三个状态寄存器:
应用PSR (APSR)执行PSR (EPSR)中断PSR (IPSR)
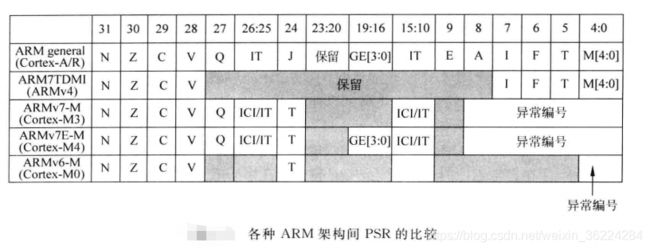
这三个寄存器可以通过一个组合寄存器访问,叫做xPSR。ARMv7-M架构中各个PSR的定义,如下图所示:


ARM其他架构的PSR定义如下:
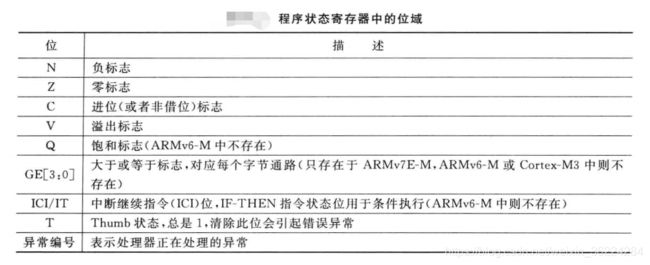
程序状态寄存器的位域定义如下:
对于ARM汇编器,在访问xPSR时,使用PSR,如下代码所示:
MRS r0,PSR ;读组合的程序状态字
MSR PSR,r0 ;写组合的程序状态字
也可以单独访问单个PSR,如下所示:
MRS r0,APSR ;读APSR(标志状态)到r0
MRS r0,IPSR ;读IPSR(异常/中断状态)到r0
MSR APSR,r0 ;写APSR(标志状态)
注意:
- 软件代码
无法直接使用MSR或MRS来直接访问EPSR。 - IPSR为只读的,可以从
PSR(xPSR)中读出
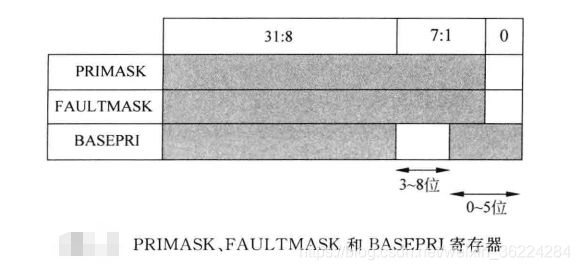
PRIMASK、FAULTMASK 和 BASEPRI 寄存器
PRIMASK、FAULTMASK 和 BASEPRI 寄存器都用于异常或中断屏蔽,每个异常或中断都具有一个优先级,数值小的优先级高,数值大的优先级低。这些寄存器可以基于优先等级屏蔽异常,只有在特权访问等级才可以对它们进行操作,非特权状态下,写操作会被忽略,读操作会返回0。默认值全部为0,也就是中断屏蔽不起作用,寄存器的编程模型如下图:
PRIMASK
PRIMASK寄存器为1位宽的中断屏蔽寄存器,在置位时,它会阻止不可屏蔽中断和HardFault异常之外的所有异常及中断。实际上,它是将当前异常优先级提升为0,也就是最高优先级。常见用途为在时间要求严格的进程中禁止所有中断,在进程完成后,将PRIMASK清除重新使能中断。
FAULTMASK
FAULTMASK 和 PRIMASK的用途相似,不过它还能屏蔽HardFault异常,也就是说它将异常的优先级提高到了-1。异常处理代码可以使用FAULTMASK以免在Fault处理期间引发其他的Fault。与PRIMASK不同之处在于,FAULTMASK在异常返回时被自动清除。
BASEPRI
ARMv7-M架构还支持BASEPRI,使得中断屏蔽更灵活,这个寄存器可以根据优先级屏蔽异常或中断。BASEPRI的宽度一般位3或者4位,这样就有8或16个编程的异常优先级。BASEPRI为0时,不起作用,为非0值时,它会屏蔽具有相同优先级或者更低优先级的异常及中断,而更高优先级的还可以被处理器接受。常见的应用为OS的临界区。
CMSIS-Core提供了多个C函数用于访问PRIMASK、FAULTMASK 和 BASEPRI寄存器,注意,这些寄存器只能在特权等级下访问:
x = _get_BASEPRI(); //读 BASEPRI 寄存器
x = _get_PRIMASK(); //读 PRIMASK 寄存器
x = _get_FAULTMASK(); //读 FAULTMASK 寄存器
_set_BASEPRI(x); //写 BASEPRI 寄存器
_set_PRIMASK(x); //写 PRIMASK 寄存器
_set_FAULTMASK(x); //写 FAULTMASK 寄存器
_disable_irq(); //设置 PRIMASK 寄存器,禁止IRQ
_enable_irq(); //清除 PRIMASK 寄存器,使能IRQ
还可以使用汇编代码访问这些寄存器:
MRS R0,BASEPRI
MRS R0,PRIMASK
MRS R0,FAULTMASK
MSR BASEPRI,R0
MSR PRIMASK,R0
MSR FAULTMASK,R0
也可以使用修改处理器状态指令,快速地设置或清除PRIMASK和FAULTMASK的值:
CPSIE i //清除 PRIMASK 寄存器,使能IRQ
CPSID i //设置 PRIMASK 寄存器,禁止IRQ
CPSIE f //清除 FAULTMASK 寄存器,使能IRQ
CPSID f //设置 FAULTMASK 寄存器,禁止IRQ
CONTROL寄存器
CONTROL寄存器结构如下图所示,定义了:
- 栈指针的选择(MSP/PSP)
- 线程模式的访问等级(特权/非特权)
- 对于具有浮点单元的Cortex-M4处理器,CONTROL还有一位表示当前上下文是否使用浮点单元。
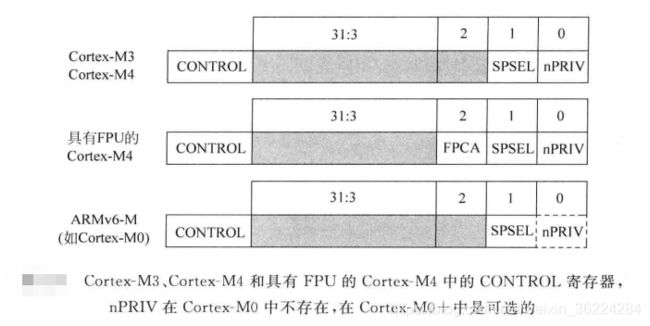

复位后,CONTROL寄存器默认为0,这意味着处理器此时处于线程模式,具有特权访问权限以及使用主堆栈指针MSP。通过写CONTROL寄存器,特权线程模式的程序可以切换栈指针的选择或进入非特权访问等级,不过nPRIV置位后,运行在线程模式的程序就不能访问CONTROL寄存器了。如下图所示:
运行在非特权等级的程序无法切回特权访问等级,如果要切换,需要使用异常机制,在异常处理期间,处理程序可以清除nPRIV位,在返回线程模式后,处理器就会进入特权访问等级,如下图所示:
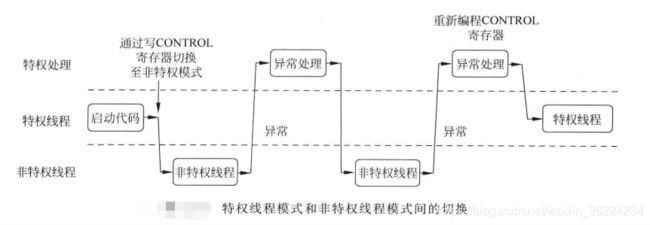
如果使用嵌入式OS,在每次上下文切换的时候,都可以重新编程CONTROL寄存器,以满足不同的应用间不同的特权访问等级需要。
nPRIV和SPESEL的设置共有4中组合方式,其中3中比较常见,如下图:
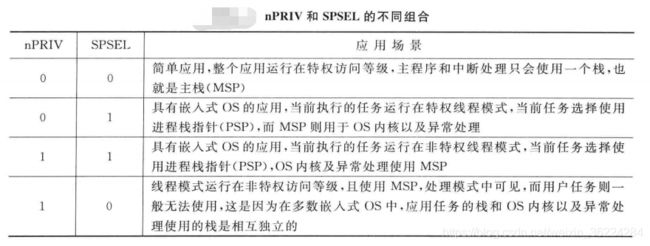
对于未使用嵌入式OS的多数简单应用,不需要修改CONTROL寄存器的数值,整个应用可以运行在特权访问等级并且只使用MSP,如下图:
使用C语言访问CONTROL寄存器,可以使用CMSIS的设备驱动库提供的下面函数:
x = _get_CONTROL(); //读取CONTROL寄存器的值
_set_CONTROL(x); //设置CONTROL的寄存器为x
使用汇编访问CONTROL寄存器,可以使用MRS和MSR指令:
MRS R0,CONTROL ;将CONTROL寄存器读入R0
MSR CONTROL,R0 ;将RO写入CONTROL寄存器
可以通过检查CONTROL和IPSR的值来判断当前是否是特权等级:
bool in_privileged(void)
{
if(_get_IPSR()!=0)
return true;
else
{
if((_get_CONTROL()&0x01)==0)
return true;
else
return false;
}
}
在修改CONTROL寄存器的值时需要注意:
- 对于具有FPU的Cortex-M4的处理器来说,由于PFU的存在,FPCA会自动置位,如果FPCA位被意外清除,而且接下来产生一个中断,那么程序可能会无法继续正确的处理。
- 修改了CONTROL寄存器后,应使用同步屏障指令(ISB),在CMSIS驱动库中为ISB()函数,以确保本次修改对接下来的代码能起到作用。
浮点寄存器
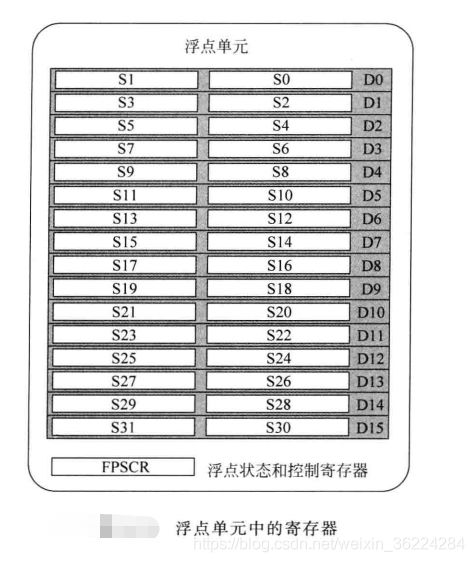
Cortex-M4具有可选的浮点单元,提供了浮点数据处理用的一些寄存器以及浮点状态和控制寄存器(FPSCR),如下图所示:S0~S31 为32位寄存器,每个都可以通过浮点指令访问,或者利用符号 D0~D15成对访问。
浮点状态和控制寄存器(FPSCR)
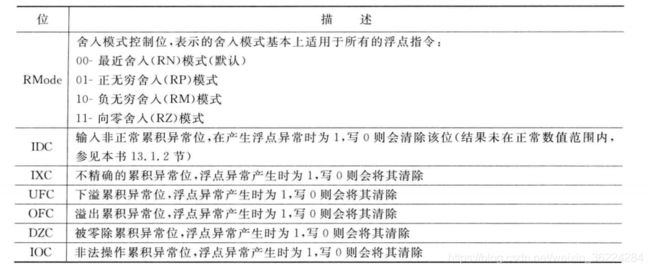
由于下面几个原因,FPSCR中包含多个位域,见下图:
- 定义一些浮点运算动作。
- 提供浮点运算结果的状态信息。

浮点控制默认被配置为符合IEEE754单精度运算,下表列出了FPSCR的位域描述:

经过存储器映射的浮点单元控制寄存器
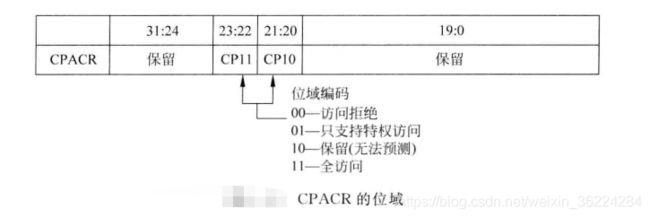
除了浮点单元寄存器组和FPSCR,浮点单元还向系统引入了一些经过存储器映射的寄存器,如用于使能和禁止浮点单元的协处理器访问控制寄存器CPACR,浮点单元默认被禁止以降低功耗,在使用浮点指令前,必须通过CPACR寄存器来使能浮点单元。
在使用CMSIS的设备驱动的C编程环境中:
SCB->CPACR |= 0xF <<20; //使能对FPU的全访问
在汇编环境中,可以使用下面代码:
LDR R0, =0xE000ED88 ;R0设置为CPACR地址
LDR R1, =0x00F00000 ;R1设置为 0xF<<20
LDR R2,[R0] ;读取CPACR的值
ORRS R2,R2,R1 ;用或的方式置位
STR R2,[R0] ;将修改后的数值写入CPACR
应用程序状态寄存器APSR
APSR中包含下面几组状态标志:
- 整数运算的状态标志(N-Z-C-V位)
- 饱和运算的状态标志(Q位)
- SIMD运算的状态标志(GE位)
整数状态标志
整数状态标志和其他架构中的ALU状态标志类似,受普通数据处理指令的影响,在控制条件跳转和条件执行时很有用。另外,APSR标志之一,也就是C(进位)位,也可用于加法和减法运算中。
Cortex-M处理器中共4个整数标志,如下图所示:

对于ARMv7-M和ARMv7E-M架构,多数的16位指令会影响这4个标志,对于32位指令,指令编码中的一个位定义了是否更新APSR标志,注意,部分指令不会更新V和C标志,如乘法指令MULS只会更新N和Z标志。
除了条件跳转或条件执行,APSR的进位标志也可以用于将加法和减法运算扩大为超过32,如将两个64位的整数相加时,可以将低32位加法运算的进位标志作为高32位加法的一个输入,ARM处理器都具有N-Z-C-V标志。
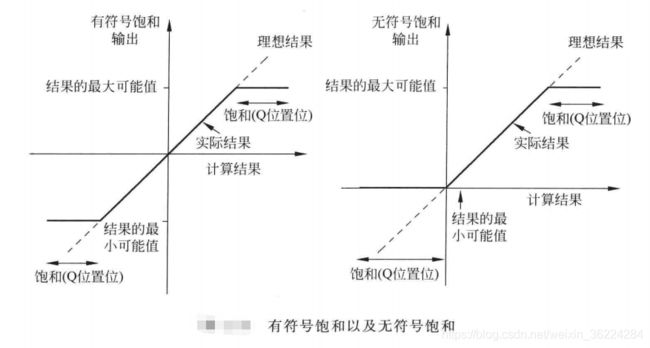
Q状态标志
Q表示饱和算术运算或饱和调整运算过程中产生了饱和,存在于ARMv7-M中,在ARMv6-M,如Cortex-M0中不可用。在该位被设置后,以及软件写APSR清除Q位之前,会一直保持置位状态,饱和算术/调整运算不会清除该位,因此在饱和算术/调整运算流程结束时,利用该位确定是否产生了饱和,而无需在每一步都检查饱和状态。
饱和算术运算对于数据信号处理非常有用,有些情况下,保存计算结果的目的寄存器的位宽可能会不够,导致上溢或下溢。如果使用一般的数据运算指令,结果的MSB会丢失,从而导致结果产生畸变。饱和算术运算并非直接将MSB去掉,而是将结果强制置为最大值或最小值,以降低信号畸变的影响。
触发饱和的最大值和最小值取决于所使用的指令,多数情况下,饱和算术运算的指令的助记符前都导游Q,如QADD16,如果产生了饱和,Q就会置位,否则Q位的数值不变。如下图所示:
GE位
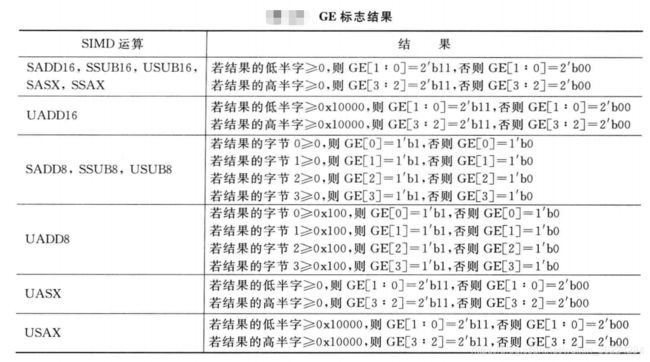
在Cortex-M4中,大于等于(GE)位域在APSR中占4位,在Cortex-M3中不存在,许多SIMD指令会更新这个标志,多数情况下,每个位表示SIMD运算的每个字节为正或者溢出,对于16位数据的SIMD指令,第0和1位由低半字的结果控制,第2和3位由高半字的结果控制。如下图所示:
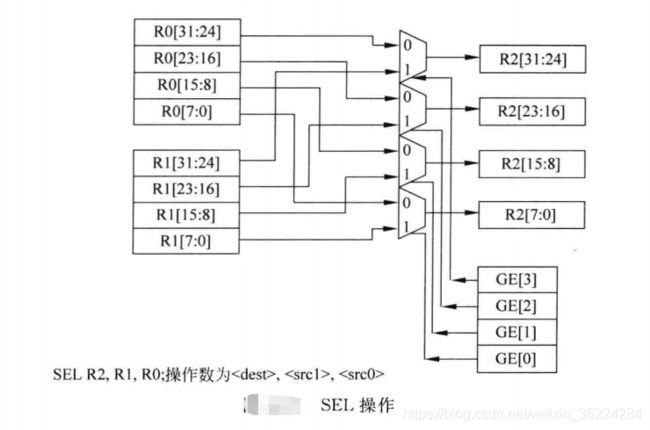
SEL指令会使用GE标志,基于每个GE位复用两个源寄存器的字节数值,在组合使用SIMD指令和SEL指令时,可以在SIMD中建立简单的条件数据选择,以提高性能。
存储器系统
存储器系统特性
Cortex-M3和M4处理器具有一下存储器系统特性:
- 4GB线性地址空间,通过32位寻址。Cortex-M3和M4处理器用AHB LITE总线协议提供32位总线。
- 架构定义的存储器映射,4GB的存储空间被划分为多个区域,用于预定义的存储器和外设,以优化处理器设计的性能。例如Cortex-M3和M4处理器具有多个总线接口,允许对程序代码用的CODE区域的访问和对SRAM或外设区域的数据操作同时进行。
- 支持小端和大端的存储器系统。
- 位段访问(可选),当包含位段特性时,存储器映射中的两个1MB区域可以通过两个位段区域进行位寻址,这样可以对SRAM或外设地址空间中单独的位进行原子操作。
- 写缓冲。如对可缓冲的存储器区域的写传输需要花费多个周期,处理器内的写缓冲可以将本次传输缓存起来,处理器继续处理下一条指令,这样可以提高程序的执行速度。
- 存储器保护单元MPU,MPU定义了个存储器区域的访问权限,并且可以进行编程。Cortex-M3和M4处理器的MPU支持8个可编程区域。
- 非对齐传输支持。ARMv7-M架构的所有处理器都支持非对齐传输。
Cortex-M处理器的总线接口为通用总线接口,可通过不同的存储器控制器被连接到不同类型和大小的存储器。微控制器存储器系统一般为两种或多种:
- 程序代码用的Flash存储器。
- 数据用的静态RAM(SRAM)。
- 有时还有电可擦出的只读存储器EEPROM。
大多数情况下,这些存储器位域芯片内部,软件开发人员只需要了解程序存储器和SRAM的地址和大小即可。
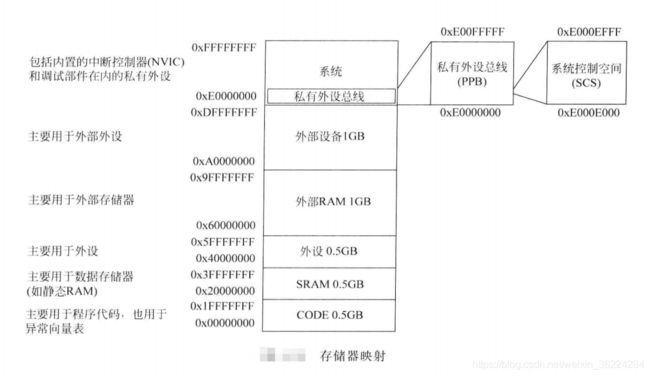
存储器映射
Cortex-M处理器的4GB地址空间被分为多个存储器区域,区域根据各自的典型用法进行划分,主要用于:
- 程序代码访问,如CODE区域
- 数据访问,如SRAM区域
- 外设,如外设区域
- 处理器的内部控制和调试部件,如私有外设总线
所有的Cortex-M处理器的存储器映射处理都是一样的,这可以提高不同Cortex-M的设备间软件可移植性及代码可重用性,区域分布如下图所示:
栈存储
Cortex-M处理器在运行时需要栈存储和栈指针R13,在栈中,存储器的一部分作为后进先出的数据存储缓冲。ARM处理器将系统主存储器用于栈空间操作,使用PUSH指令往栈中存储数据,以及POP指令从栈中提取数据,每次PUSH和POP操作后,栈指针都会自动调整。
栈可用于:
- 当正在执行的函数需要使用寄存器进行数据处理时,临时存储数据的初始值。这些数据在函数结束时可以被恢复出来,以免调用函数的程序丢失数据。
- 往函数或者子函数中的信息传递。
- 存储局部变量。
- 在中断等异常产生时保存处理器状态和寄存器数值。
Cortex-M处理器使用的栈模型为满递减,处理器启动后,SP也就是R13被设置为栈存储空间最后的位置,对于每次PUSH操作,处理器首先减小SP的值,然后将数据存储在SP指向的存储器位置。对于POP操作,SP指向的存储器位置的数据先被读出,然后SP的数值自动增大,如下图所示:
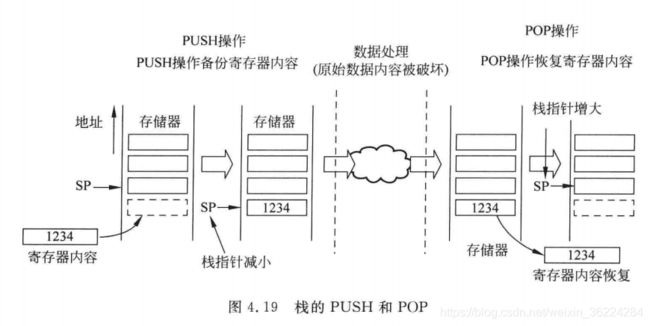
PUSH和POP指令最常见用法为,在执行函数或者子程序调用时,保存寄存器组中的内容。在函数调用开始时,有些寄存器的内容可以通过PUSH指令保存在栈中,然后在函数调用结束时,通过POP恢复为他们的初始值。
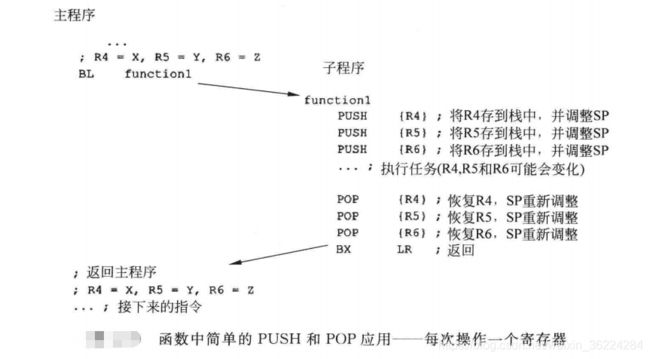
如下图,一个名为 function1的函数被主程序调用,由于function1在数据处理时需要使用并修改R4、R5和R6,而这些寄存器中的数值在后面还会被主程序用到,因此,他们会被PUSH保存到栈中,并在function1结束时被POP恢复,这样调用函数的程序代码不会丢失任何数据而且可以继续执行。注意,每一个PUSH操作,都有一个POP操作,并且地址是一致的。
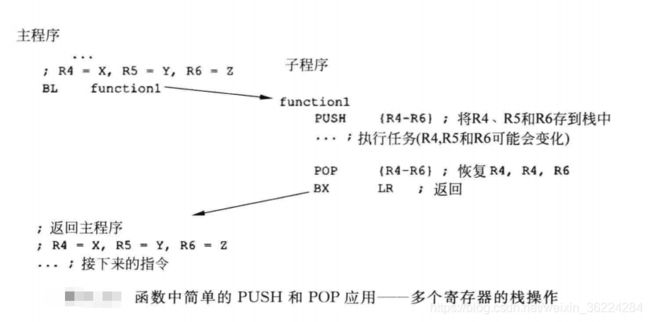
每个PUSH和POP指令都可以和栈空间传输多个数据,由于寄存器都是32位的,每个由栈PUSH和POP生成的存储器都会访问至少一个字的数据,而且地址总是对齐到4字节边界上,SP的最低两位地址总是0,如下图所示:
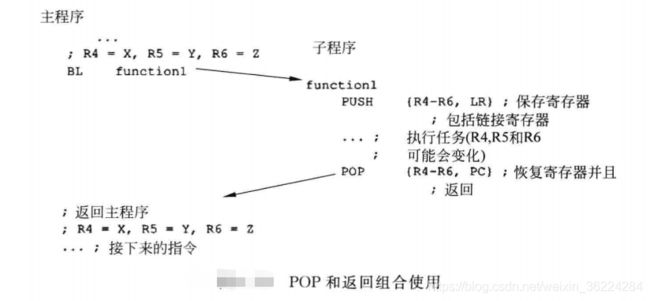
可以将POP和函数返回操作结合在一起,先将LR的值压入栈中,然后在子程序结束时,将其恢复到PC中,如下图所示:
Cortex-M处理器在物理上有两个栈指针:
- 主栈指针MSP,复位后默认使用的栈指针,用于所有的异常处理。
- 进程栈指针PSP,只用于线程模式的栈指针,通常用于运行嵌入式OS的嵌入式系统中的应用任务。
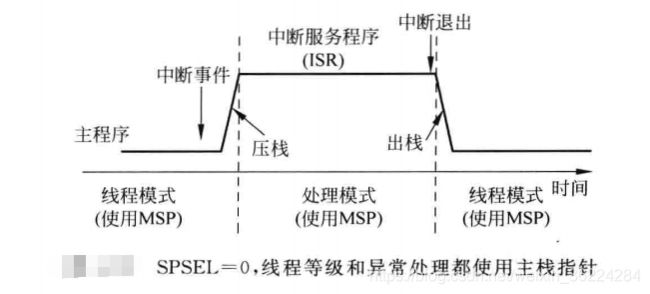
MSP和PSP的选择由CONTROL寄存器的第二位SPSEL的数值决定,如果为0,则线程模式在栈操作时使用MSP,否则使用PSP。另外,从处理模式到线程模式的异常返回期间,栈指针的选择可由EXC_RETURN数值巨鼎,这样处理器硬件会自动的更新SPSEL的值。
对于不具有OS的应用,线程模式和处理模式都可以使用MSP,在异常事件产生后,处理器进入中断服务程序前先将多个寄存器压入栈中,这种寄存器状态保存操作称为压栈,在ISR结束后,这些栈中的寄存器的值又会被恢复到寄存器中,这种操作叫做出栈,如下图所示:
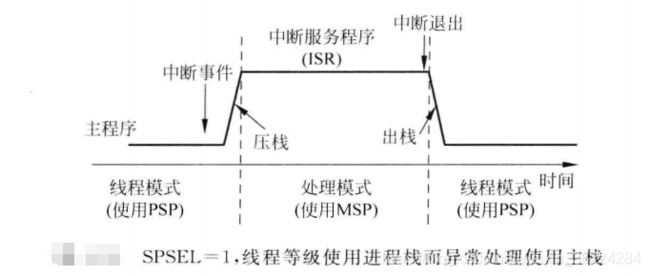
如果嵌入式系统中包含了嵌入式OS,则通常将应用任务和内核所用的栈空间分离开来,因此用到PSP,在异常入口和异常退出时发生SP切换,主动压栈和出栈阶段使用PSP,利用这种分离的栈结构,栈或者应用任务的错误不会影响OS使用的栈,同时也简化了OS的设计,提高了上下文切换的速度,如下图所示:
可以通过下面CMSIS函数或者汇编访问MSP和PSP,一般不建议使用C访问MSP和PSP,因为栈存储中的一部分可能被用于存储局部变量或其他数据,尽量使用汇编进行。
x = _get_MSP(); //读取MSP的数值
_set_MSP(); //设置MSP的数值
x = _get_PSP(); //读取PSP的数值
_set_PSP(); //设置PSP的数值
MRS R0,MSP ;将主栈指针读入R0
MSR MSP,R0 ;将R0写入主栈指针
MRS R0 PSP ;将进程栈指针读入R0
MSR PSP,R0 ;将R0写入进程栈指针
存储器保护单元
MPU在Cortex-M3和M4处理器中是可选的,因此并不是所有的Cortex-M3和M4微控制器都具有MPU特性,多数应用不会用到MPU,在需要高可靠性的嵌入式系统中,MPU可以通过定义特权和非特权访问权限,来保护存储器区域。
Cortex-M3和M4处理器中的MPU支持8个可编程区域,MPU由多种用法,可以由嵌入式OS控制或者配置为只保护某一特定存储器区域。
异常和中断
异常概述
异常是会改变程序流的事件,当其产生时,处理器会暂停当前正在执行的任务,转而执行一段被称作异常处理的程序。异常处理执行完后,处理器继续正常的程序执行。对于ARM架构,中断就是异常的一种,一般由外设或外部输入产生,有时也可以由软件触发,中断的异常处理程序也被称作中断服务程序ISR。
Cortex-M处理器由多个异常源,如下图:
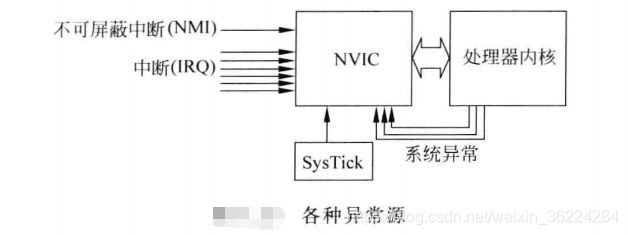
NVIC处理异常。NVIC可以处理多个中断请求IRQ和一个不可屏蔽中断NMI请求,IRQ一般由片上外设或外部中断输入通过IO端口产生,NMI可用于看门狗定时器或者掉电检测(在电压低到一定程度时给处理器产生警告)。处理器内部也有Systick的定时器,可以产生周期性的定时中断请求,可用于嵌入式OS计时或者没有OS的应用中的简单定时控制。
处理器自身也是一个异常事件源,其中包括表示系统错误状态的错误事件以及软件产生、支持嵌入式OS操作的异常,异常类型如下表:
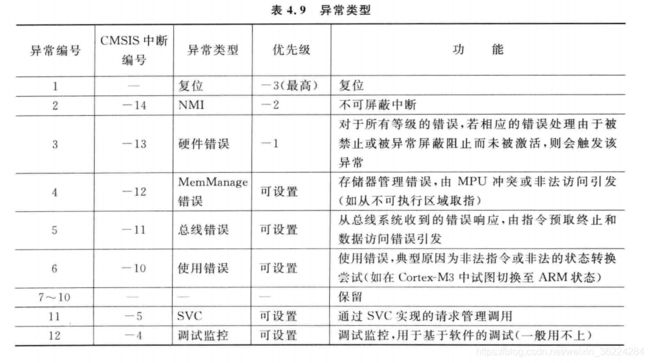
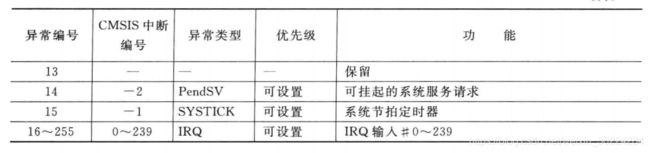
每个异常源都由一个异常编号,编号1~15为系统异常,16号及以后用于中断。Cortex-M3和M4处理器在设计上支持最多240个中断输入,不过为了减小硅片面积及节省功耗,一般只实现16-100左右。
异常编号在多个寄存器中都有所体现,包括用于确定异常向量地址的IPSR,异常向量存储在向量表中,在异常入口流程中,处理器会读取向量表来确定异常处理的起始地址。注意,异常编号的定义和CMSIS的驱动库的中断编号定义不同,CMSIS中中断编号从0开始,而系统异常编号为负值。
Cortex-M处理器没有快速中断FIQ,不过Cortex-M3和M4处理器的中断等待只有12个周期,时间非常短。
复位是特殊的异常,处理器从复位中退出时,会在线程模式而不是其他异常时的处理模式下执行复位处理,IPSR中的异常编号为0。
嵌套向量中断控制器NVIC
NVIC为Cortex-M处理器的一部分,为可编程的并且寄存器位域存储器映射的系统控制空间SCS,NVIC处理异常和中断配置、优先级以及中断屏蔽。NVIC具有以下特点:
- 灵活的异常和中断管理
- 支持嵌套异常/中断
- 向量化的异常/中断入口
- 中断屏蔽
灵活的中断和异常管理
每个中断,除了NMI,都可以被使能或者禁止,而且都有可由软件设置或清除的挂起状态,NVIC可以处理多种类型的中断源:
- 脉冲中断请求。中断请求至少持续一个时钟周期,当NVIC在某中断输入收到一个脉冲时,挂起状态就会置位并保持到中断得到处理。
- 电平触发中断请求。在中断得到处理前需要将中断源的请求保持为高。
NVIC输入信号为高有效,不过实际的微控制器的外部中断输入的设计可能会有所不同,会被片上系统逻辑转换为有效的高电平信号。
嵌套向量/中断支持
每个异常都有一个优先级,中断等一些异常具有可编程的优先级,其他的为固定优先级。当异常产生时,NVIC会将异常的优先级和当前等级比较,如果新的异常的优先级较高,则正在执行的任务暂停,寄存器进行压栈,处理器开始执行新异常的异常处理,这个过程叫做抢占。当高优先级的异常处理完成后,会被异常返回操作终止,处理器自动从栈中恢复寄存器内容,并继续执行之前的任务。
向量化的异常/中断入口
异常发生时,处理器需要 确定对应的异常处理入口位置。对于ARM7TDMI等ARM处理器,这一操作由软件实现,Cortex-M处理器则从存储器的向量表中自动定位异常处理的入口,这样可以降低从异常产生到异常处理执行间的延时。
中断屏蔽
Cortex-M3和M4处理器中的NVIC提供了多个中断屏蔽寄存器,如PRIMASK特殊寄存器。利用PRIMASK寄存器可以禁止除HardFault和NMI之外的所有异常。另外还可以使用BASEPRI寄存器来选择屏蔽低于指定优先级的异常或中断。
向量表
异常事件产生并被处理器内核接受后,响应的异常处理就会执行,要确定异常处理的起始地址,处理器里哟过了向量表机制。向量表为系统存储器内的字数据数组,每个元素都代表一个异常类型的起始地址,向量表是可以重定位的,重定位由NVIC中名为向量表便宜寄存器VTOR的可编程寄存器控制,复位后,VTOR默认为0,向量表位域地址0x0处,如下图所示:
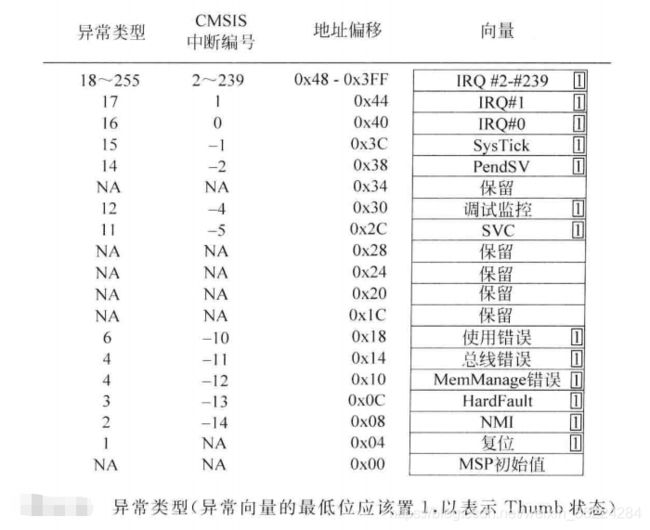
每个异常向量的最低位表示异常是否在Thumb状态下执行,由于Cortex-M只支持Thumb指令,因此所有的异常向量的最低位都应该为1。
错误处理
Cortex-M3和M4处理器有几个异常为错误处理异常。处理器检测到错误时,触发错误异常,检测到的错误包括执行未定义的指令以及总线错误、对存储器访问返回错误的响应等。错误异常机制使得错误可以被快速发现,软件因此可以执行相应的修复措施,如下图所示:
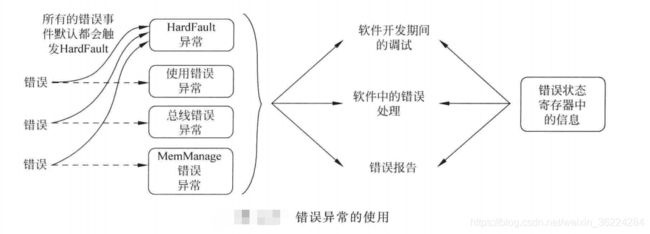
总线错误、使用错误以及存储器管理错误默认是禁止的,所有的错误事件都会触发HardFault异常。
错误异常可在软件调试中使用,当错误产生时,错误异常可以自动收集信息以及通知用户或其他系统错误已产生,并提供调试信息。Cortex-M3和M4处理器有多个可用的错误状态寄存器,提供错误源等信息。
系统控制块SCB
SCB为处理器的一部分,位于NVIC中,SCB包含寄存器,用于:
- 控制处理器配置,如低功耗模式。
- 提供错误状态信息,错误状态寄存器。
- 向量表重定位VTOR。
复位和复位流程
对于典型的Cortex-M微控制器,复位类型有三种:
- 上电复位。复位微控制器中的所有部分,包括处理器、调试支持部件和外设等。
- 系统复位。只复位处理器和外设,不包括处理器的调试及支持部件。
- 处理器复位。只复位处理器。
在系统调试或处理器复位操作过程中,Cortex-M3和M4处理器中的调试部件不会复位,这样可以保持调试主机(如运行在PC机上的调试软件)和微控制器间的链接。调试主机可以通过系统控制块SCB中的寄存器产生系统复位或处理器复位。
上电复位和系统复位的持续时间取决于实际的微控制器设计,某些情况下,由于复位控制器需要等待晶体振荡器等时钟源稳定下来,因此复位要持续若干毫秒。
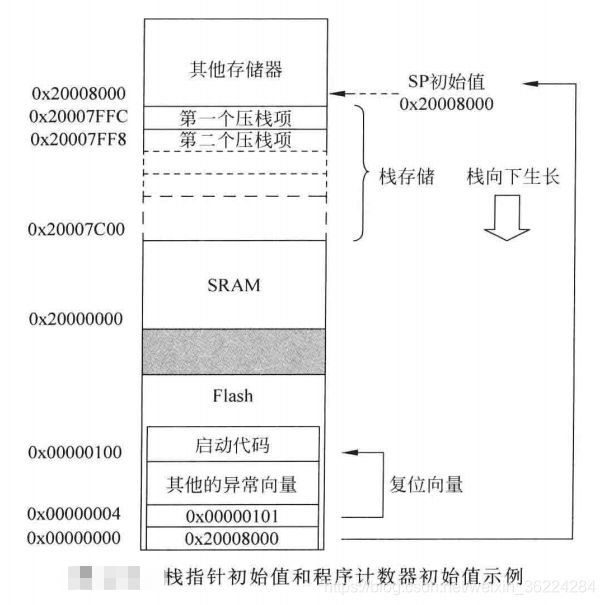
复位后及处理器开始执行程序前,Cortex-M处理器会从存储器中读出前两个字,向量表位于存储器的开头部分,它的头两个字为主栈指针MSP的初始值,以及代表复位处理起始地址的复位向量,处理器读出这两个字后,就会将这些数值赋给MSP和程序计数器PC, 如下图所示:
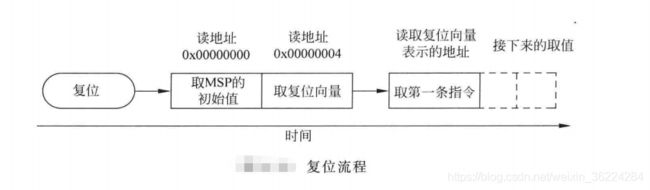
MSP的设置是很有必要的,因为在复位的短时间内有产生NMI或HardFault的可能,在异常处理前将处理器状态压栈时需要栈存储和MSP。
注意:对于多数C开发环境,C启动代码在进入主程序main前更新MSP的数值,通过两次对栈的设置,具有外部存储器的微控制器可以将外部存储器用作栈。例如启动时设置片上SRAM为栈,复位处理中初始化外部存储器后执行C启动代码,此时将栈设置为外部存储器。
由于Cortex-M3 和 M4的栈操作为满递减,SP的初始值应设置为栈区域顶部的第一个位置。例如,若栈区域为 0x20007C00~0x20007FFF,则初始栈指针应为0x20008000.如下图所示: