App推荐系统
-
协同过滤
协同过滤(Collaborative Filtering)技术,是推荐系统中应用最为广泛的技术之一,协同过滤算法主要有两种,一种是基于用户的协同过滤算法(UserBaseCF),另一种是基于物品的协同过滤算法(ItemBaseCF)。
1.基于用户的协同过滤
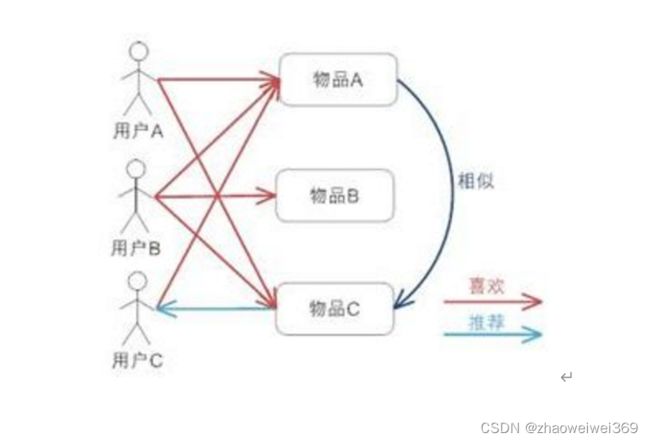
基于用户的协同过滤:跟你喜好相似的人喜欢的东西你也很有可能喜欢。如图假设用户A喜欢商品A,C。用户B喜欢商品B。用户C喜欢商品A,C,D。我们可以发现用户A和C的行为和偏好是比较类似的。用户C喜欢物品D,那么就可以将物品D推荐给用户A。
2.基于商品的协同过滤
基于商品的协同过滤:跟你喜欢的东西类似的东西你也可能喜欢。用户A喜欢商品A和C,用户B喜欢商品A,B,C。用户C喜欢物品A。从所有用户的历史喜好中假设商品A与商品C比较类似,也就是喜欢商品A的都喜欢商品C,那么基于这个结论我们可以将商品C推荐给用户C。 多数情况下基于商品的协同过滤经常使用。
-
App推荐系统
-
1.app推荐系统介绍
-
个性化商品营销和信息过载是推荐系统产生的根本原因。app推荐的最根本就是根据用户历史下载的App去找到与这个App相似的app,推荐给该用户。如何找到与此App相似的app?这就需要基于所有用户的下载历史计算挖掘出基于物品相似的矩阵。
-
app推荐系统是基于用户的隐式转换数据和基于商品的协同过滤来实现app个性化推荐。当用户登录应用商店时,根据之前用户的行为信息来推荐对应感兴趣的app。
思考:假设自己实现一个商品推荐系统需要什么样的数据?
商品的基本信息、用户商品购买记录、用户对购买商品的评价。
2.推荐的应用场景
推荐的应用场景有很多种,例如:商品信息推荐,新闻推荐、app推荐、好友推荐、音乐推荐、广告推荐等。以上场景都是推荐系统的应用场景。
推荐系统流程
-
推荐系统架构
推荐系统中一般都会分为两部分,一部分是离线训练模型,另一部分是在线使用模型推荐。离线训练模型需要经过数据采集、清洗、特征抽取等步骤,然后训练模型,这里训练模型一般是周期性训练模型,比如一天训练一次,或者一周训练一次,因为模型的数据不同,训练出来模型的效果不同,将模型训练好之后,可以将模型保存到HDFS中。在线使用模型时,从HDFS中加载模型,将对应的实时数据获取过来组织特征,然后带入模型使用,得到对应的推荐结果即可。
一般在做推荐系统时使用的架构如下图,左侧为推荐系统在线推荐部分,右侧为推荐系统模型离线训练部分,另外最下层是实时数据与离线数据结合部分。过程如下:
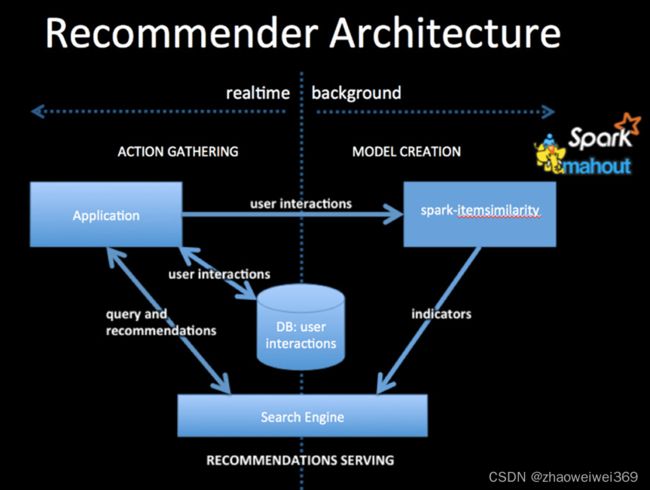
离线部分:当用户访问application时,将用户的行为数据收集起来放入Hbase或者Hive中,基于此数据构建训练集,离线训练推荐系统模型,将训练好的模型参数保存到Redis或者模型文件中,待使用
在线部分:当用户访问application时,根据用户的基本信息去数据库中拿到用户的最近行为数据,基于模型数据实时计算出用户的推荐列表。
2.App推荐系统架构
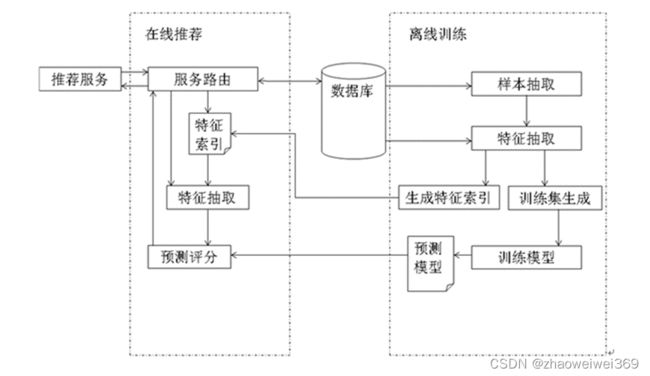
离线训练:
- 在准备训练集时,如果数据是放在HBase中,数据量太大,可以通过Hive映射,随机样本抽取一部分数据当做训练数据的源数据,只要抽取的数据能代表整体即可,这样即增大了构成的源数据集的时间跨度又可能使训练模型的时间会大大缩短。如果全量数据不多,也可以将所有数据直接当做源数据集。
- 如果Hive或者Hbase中的数据列太多,可以对数据进行特征抽取,构成训练模型的训练集。同时将所有的特征保存到特征文件中构成特征索引,供推荐系统在线推荐使用。
- 训练集准备好之后,对于训练集中的每条数据来说就是用户针对当前App的行为信息,结果上来看,要么下载了App,要么没有下载App,这就是二分类问题,可以使用逻辑回归结合训练集训练模型。
- 当模型训练好之后,就是一些特征参数,可以将模型保存到Redis或者文件中,供实时推荐部分调用。
- 在线推荐:
- 用户访问系统时,通过服务路由可以拿到用户的id,根据用户id首先去数据库中拿到当前用户的一些基础数据信息,将基础数据结合特征文件将有用的特征过滤出来,进行基础数据的格式化。
- 加载模型文件数据,将用户格式化后的特征数据带入模型文件得到推荐列表。
3.App推荐系统使用数据
App推荐系统使用的数据应该包括如下:
- 要推荐物品或内容的元数据,例如关键字,基本描述等。
- 用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。其实这些用户的偏好信息可以分为两类:
- 显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式的提供反馈信息,例如用户对物品的评分,或者对物品的评论。
- 隐式的用户反馈:这类是用户在使用网站时产生的数据,隐式的反应了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。
基于以上数据分析,App推荐系统使用的数据有:
App基本信息表、用户app历史下载表、用户浏览app信息表。
4.推荐系统详细流程
想要为用户推荐App,按照协同过滤的思想,要构建所有App的同现矩阵,还要知道每个用户对每个App的评分,这里无法获取用户对app的评分。我们根据逻辑回归模型使用app与app关联当做特征,基于用户浏览app信息表和用户历史下载表来基于所有用户数据构建出app之间的关联权重(特征的权重分值当做app与app关联的重要程度)。进而计算出每个App值得推荐的总分值,按照分值从大到小排序,将分值大的推荐给用户即可。
这里我们不可能拿到用户对所有App的评分。但是我们可以对用户下载或者浏览的每个App与该用户历史下载的每个App,构建不同App的同现情况,把同现情况当做特征维度,然后根据用户是否下载了该App(是或否),针对二分类问题,使用逻辑回归计算每两个App同现的权重,也就是每个特征维度的权重值。两个App同现的权重越大,说明两个App的关联性越强,比如:下载A应用的用户,都下载了B应用,而极少数用户下载B的同时还下载了C应用,那么AB同现的次数远远大于AC同现的次数,可以针对下载A的用户,推荐应用B。反映到逻辑回归中就是AB特征的权重大于AC特征的权重。
我们可以针对不同的用户将商家有的每个App与该用户下载历史App构建App同现特征,然后去训练好的模型中取对应维度的权重值累加,最终计算出每个App值得为该用户推荐的分值,进而得到推荐列表。
当一个新用户登录系统后,没有App的历史下载记录,那么就没有办法构建每个App与历史下载App的同现特征,就没有办法为用户计算出推荐列表,这就是推荐系统中的冷启动问题。
冷启动:当新用户登录系统后,没有办法生成对应的推荐列表。
如何解决冷启动问题?
在构建训练集时,不仅构建每个App与当前用户的下载历史App的同现特征,还要构建针对每个App各个维度的基本特征。这样训练出来的模型,当用户是新用户时,可以基于App本身的特征权重为用户推荐App列表,解决冷启动问题。
- 离线训练模型:
根据用户的下载或者浏览历史可以拿到用户对App的操作详细信息,比如:用户是否下载了该App、用户手机是否支付了该App、当前用户的手机型号、当前用户浏览或者下载的App的大小、版本号、设计者、评价星级、下载数量等信息。将这些信息当做App的基本特征。
根据用户下载和浏览每个App的历史,与该用户的历史下载App列表形成每个关联特征,作为App的关联特征。
综合上面基本特征和关联特征当做训练集的features,是否下载App作为训练集的Label,使用逻辑回归离线训练模型。
- 在线使用模型:
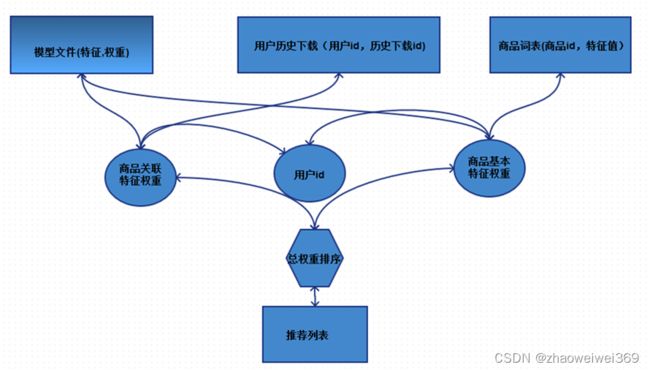
用户登录系统之后,根据用户ID,获取当前用户历史下载App列表,将商店中每个App与用户下载列表中的每个App构成关联特征,同时每个App还有基本特征,得到关联特征和基本特征之后可以去训练好的模型文件中拿到相应特征对应的权重值,将每个关联特征权重累加得到关联特征的总值(这就是根据用户偏好得到的当前App值得推荐给该用户的分值),将基本特征权重累加得到基本特征的总值,最后将关联特征总值和基本特征总值相加得到一个总分值,该分值就是该App值得推荐给该用户的推荐值。
商店中的每个App最终都会计算出一个值得为当前用户推荐的总分值,再按照分值取前N大,取出最值得推荐给该用户的App,构成推荐列表。
注意:在训练模型构建“商品基本特征”维度时,可能有“设计者”,“手机型号”等这种非数字化的可分类的文本特征属性(比如“性别”维度下有男女两类,“职业”类别下有老师、学生、工人等可分类的数据),由于模型只能使用数字化的数据来训练,可以对训练集含有这种可分类的文本特征属性自己定义一个特征变换规则:如果男用1表示,女用0表示。老师用0表示,学生用1表示,工人用2表示,那么使用模型时,相对应的将测试数据中当前维度的文本特征属性也要按照相对应的同一个特征变换规则来变换,对最终的结果没有影响。这里对文本特征属性设置不同的数字来表示不同的类别时,如果设置的值的跳度大(比如男用1表示,女用1000来表示),影响的是训练模型中按照梯度下降寻找最优解的迭代次数。