hive的常规操作
1、首先说说数仓与Hive
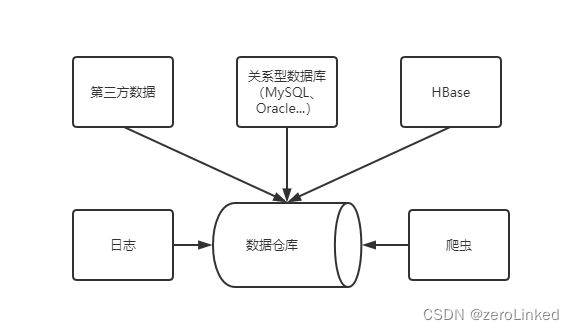
数据仓库,简单来说就是,企业利用其自身和行业本身的历史数据进行智能化统计分析,从中分析、挖掘出有价值的数据,为领导层提供科学的决策支持,作用是改善企业业务流程、运行成本、企业效益和提高用户体验。
数仓中的数据域有多种,为了分析,不择手段,只要有利于分析的数据,都可以集成到数仓中。
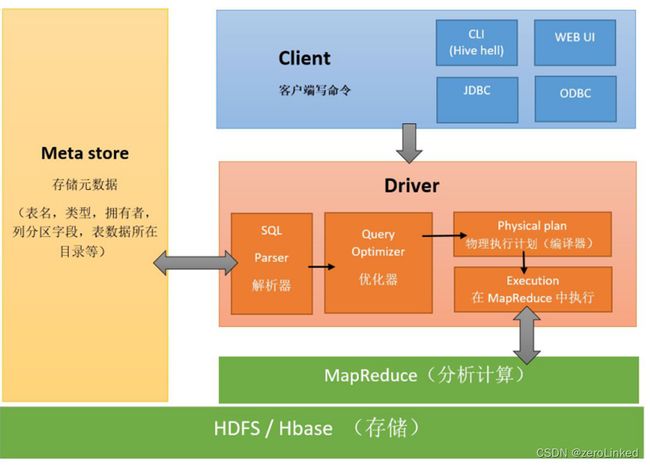
Hive,是一个数仓管理工具,可以将数仓存在HDFS上的文件变成表,同时提供HiveSQL进行表的分析处理,底层默认的计算框架是MapReduce,可以换成其他引擎(如Spark),编写HiveSQL时,会自动去匹配MapReduce模板,其架构如下:
Hive的大部分语法与MySQL类似,但这里记录一些不同的地方
2、内部表和外部表
2.1、内部表
- 内部表:私有表,一旦给表加载数据之后,内部表认为这份数据就是他独占的,表一旦删除,表数据文件会跟着全部删除,如果在应用中,数据是部门内部的,或者个人的,则表可以设置为内部表,不会对其他人造成影响。
举例:创建内部表,指定分隔符,加载数据。
2.1.1、数据准备
在linux中存放一个
student.txt文件
内容:
01 赵雷 1990-01-01 男
02 钱电 1990-12-21 男
03 孙风 1990-05-20 男
04 李云 1990-08-06 男
05 周梅 1991-12-01 女
06 吴兰 1992-03-01 女
07 郑竹 1989-07-01 女
08 王菊 1990-01-20 女
同时将该文件上传至HDFS中
2.1.2、创建表数据
根据表的结构,创建四个字段,同时指定表的分隔符为
\t
create database if not exists myhive;
use myhive;
create table student (id int, name string, birthday string, gender string)
row format delimited fields terminated by '\t';
2.1.3、从本地(linux)加载数据到表中
这里使用到
local关键字表示是在linux的路径下进行加载,overwrite关键字表示数据会进行覆盖,
操作完用查询语句查看数据是否存在。
load data local inpath '/hivedatas/student.txt' overwrite into table student;
操作完后,可以进去HDFS文件目录的/user/hive/warehouse/myhive.db/student中查看,你会发现,其实该操作是将一个txt文件复制过来,原来的数据还存在于linux系统中。
2.1.4、从hdfs文件加载数据到表中
该操作是一个剪切操作,将HDFS的
/input/hivedatas/student.txt路径下的文件移动到HDFS文件目录的/user/hive/warehouse/myhive.db/student中
load data inpath '/input/hivedatas/student.txt' overwrite into table student;
2.1.5、删除表
drop table student;
此时你再查询这张表,会显示表不存在,同时,去HDFS目录下,也不会存在这个表对应的文件夹。
2.2、外部表
- 外部表:公有表,一旦给表加载数据之后,外部表认为这份数据大家的,表一旦删除,表数据文件不会删除,只删除表和文件之间的映射关系,如果在应用中,数据是各部门共享,则可以设置为外部表,你的表只是对文件有访问权。
2.2.1、创建
创建同内部表类似,但是多了个关键字external,这里的SQL和数据参照上面内部表的例子
create external table student (id int, name string, birthday string, gender string)
row format delimited fields terminated by '\t';
2.2.2、加载数据
同内部表
load data local inpath '/export/data/hivedatas/student.txt' overwrite into table student;
2.2.3、删除表
删除语句也是类似,但不同的是,外部表的删除只删除元数据,即切断与源数据的联系。
drop table student;
执行完后,SQL中是查不到该表的,但数据依旧存在于HDFS中,当你再次创建这张表,再次进行查询的时候,该表又会有原来的数据。
3、分区表
所谓的分区表,指的就是将数据按照表中的某一个字段进行统一归类,并存储在表中的不同的位置,也就是说,一个分区就是一类,这一类的数据对应到hdfs存储上就是对应一个目录。当我们需要进行处理的时候,可以通过分区进行过滤,从而只取部分数据,而没必要取全部数据进行过滤,从而提升数据的处理效率。且分区表是可以分层级创建。
分区操作有静态分区和动态分区。
数据准备
准备两个文件
score1.txt
01 01 80
01 02 90
01 03 99
02 01 70
02 02 60
02 03 80
03 01 80
03 02 80
03 03 80
score2.txt
04 01 50
04 02 30
04 03 20
05 01 76
05 02 87
06 01 31
06 03 34
07 02 89
07 03 98
3.1、静态分区
3.1.1、创建分区表
创建分区的关键字就是partitioned by,里面有个字段dt这个字段是根据用户的想法自定义的,比如根据日期进行分区等方式
create table score
(
sid string,
cid string,
sscore int
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
3.1.2、加载数据
这里按照时间给数据增加了两个分区,分完区后可以去HDFS文件中观察数据的变化
load data local inpath '/hivedatas/score1.txt' into table score partition (dt='2022-10-16');
load data local inpath '/hivedatas/score2.txt' into table score partition (dt='2022-10-17');
3.1.3、根据分区查询数据
select * from score where dt='2022-10-16';
3.1.4、多级分区操作
这里不多赘述,看SQL
# 建表
create table score2
(
sid string,
cid string,
sscore int
)
partitioned by (year string, month string ,dt string)
row format delimited fields terminated by '\t';
# 加载数据
load data local inpath '/hivedatas/score.txt'
into table score2 partition (year='2022',month='10',dt='16');
# 查询数据
select * from score2;
3.2、动态分区
动态分区比静态分区麻烦一些,需要借助临时表进行实现,其建表操作与静态分区类似,不同的点在于加载数据是从临时表中加载过去的,具体如图。

操作的过程
注意:这里加载数据到分区表的时候,分区表的字段有三个,所以会以最后一个字段作为分区的依据进行分区,加载完成后可以查看数据的情况,同时查看HDFS上的文件夹有啥变化
-- 1、开启动态分区
set hive.exec.dynamic.partition=true; -- 开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict;-- 设置为非严格格式
-- 2、模拟数据
/*
1 2022-01-01 zhangsan 80
2 2022-01-01 lisi 70
3 2022-01-01 wangwu 90
1 2022-01-02 zhangsan 90
2 2022-01-02 lisi 65
3 2022-01-02 wangwu 96
1 2022-01-03 zhangsan 91
2 2022-01-03 lisi 66
3 2022-01-03 wangwu 96
*/
-- 3、创建一个中间普通表(该表用来存入原始数据)
create table test1
(
id int,
date_val string,
name string,
score int
)
row format delimited fields terminated by '\t';
-- 4、给普通表加载数据
load data local inpath '/hivedatas/partition.txt' into table test1;
-- 5、来创建最终的分区表
create table test2
(
id int,
name string,
score int
)
partitioned by (dt string)
row format delimited fields terminated by ',';
insert overwrite table test2 partition (dt)
select id, name, score, date_val from test1;
4、分桶表
Hive中的分桶,其实就是MapReduce中的分区,表现为:将一个大文件拆分成多个小文件,这样做的目的是:1、提高多表join的效率,2、有利于数据的抽样。分桶的方式:拿到分桶字段的值,然后取hash值对分桶的个数取模。
4.1、分桶的具体操作
分桶同动态分区一样,需要借助中间表来实现,关键字为cluster by
course.txt
01 语文 02
02 数学 01
03 英语 03
04 物理 04
05 化学 05
06 生物 06
-- 1、创建分桶表
create table course
(
cid string,
c_name string,
tid string
)
clustered by (cid) into 3 buckets
row format delimited fields terminated by '\t';
-- 2、创建普通表
create table course_common
(
cid string,
c_name string,
tid string
) row format delimited fields terminated by '\t';
-- 3、给普通表加载数据
load data local inpath '/hivedatas/course.txt' into table course_common;
select * from course_common;
-- 4、将普通表的数据进行查询插入到普通表
insert overwrite table course
select * from course_common cluster by (cid);