Kafka 3.0 源码笔记(9)-Kafka 服务端元数据的主从同步
文章目录
- 前言
- 1. 元数据主从同步的流程
-
-
- 1.1 两次 Fetch 完成 HW 同步
- 1.2 一次 Fetch 完成 HW 同步
-
- 2. 元数据主从同步源码分析
-
-
- 2.1 Follower 节点 Fetch 请求的发起
- 2.2 Leader 节点对 Fetch 请求的处理
- 2.3 Follower 节点对 Fetch 响应的处理
-
前言
在 Kafka 3.0 源码笔记(8)-Kafka 服务端对创建 Topic 请求的处理 中笔者分析介绍了 Kafka 集群的 Leader 节点更新保存元数据的流程,而元数据保存下来后必然要传播到整个集群,使其正常生效,这个传播的过程就是元数据的主从同步。在解析这个过程之前,我们首先要了解 Kafka 保证分区数据可靠性的机制,大致如下图所示:
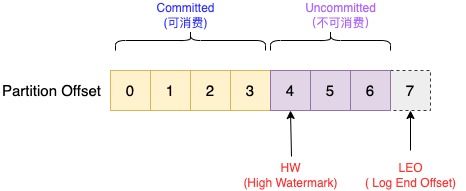
HW(High Watermark) 高水位
定义分区中消息的可见性,只有偏移量Offset 小于 HW 值的消息才是已备份或者已提交(Committed)的,可以被消费LEO(Log End Offset) 日志末端偏移量
指向分区副本底层日志文件将要写入的下一条消息的 Offset偏移量,也就是日志文件尾部的下一个位置
- Kafka 通过多副本机制实现故障自动转移,其每个分区都由若干副本组成,包括 Leader 副本和 Follower 副本。Leader 副本负责消息数据的读写请求,Follower 副本则定时同步 Leader 副本的数据,已备故障转移使用。主从数据同步并不是 Follower 把数据复制过来保存就结束了,还需要借助额外的 HW 标识表明数据的保存状态(Committed/Uncommitted),进而决定消息是否对外可见
- 所有副本底层的日志文件结构都是一样的,也就是说每个副本都有自己的 HW,但只有 Leader 副本的 HW 标识整个分区的消息可见性。主从副本的数据同步就是围绕 HW 展开,通过 Fetch 请求进行
1. 元数据主从同步的流程
Kafka 对集群元数据主从同步的管理并不要求强一致性,只要求 最终一致性,当集群内一半以上具有投票权的节点保存了元数据消息则认为该消息处于 Committed 状态,可以被消费
此处强调对集群元数据主从同步的管理不要求强一致性,是因为与之对应 Kafka 对客户端生产的消息的主从同步具有强一致性要求,关于这点本文暂不深入。总之由于非强一致性的要求,元数据分区 HW 的同步有以下两种情况:
两次 Fetch 完成 HW 同步一次 Fetch 完成 HW 同步
需注意,__cluster_metadata 这个元数据 topic 只有一个分区,而 Kafka 集群所有节点都会保存该分区的副本,只不过只有具备投票权的 Controller 节点才能参与维护元数据
1.1 两次 Fetch 完成 HW 同步
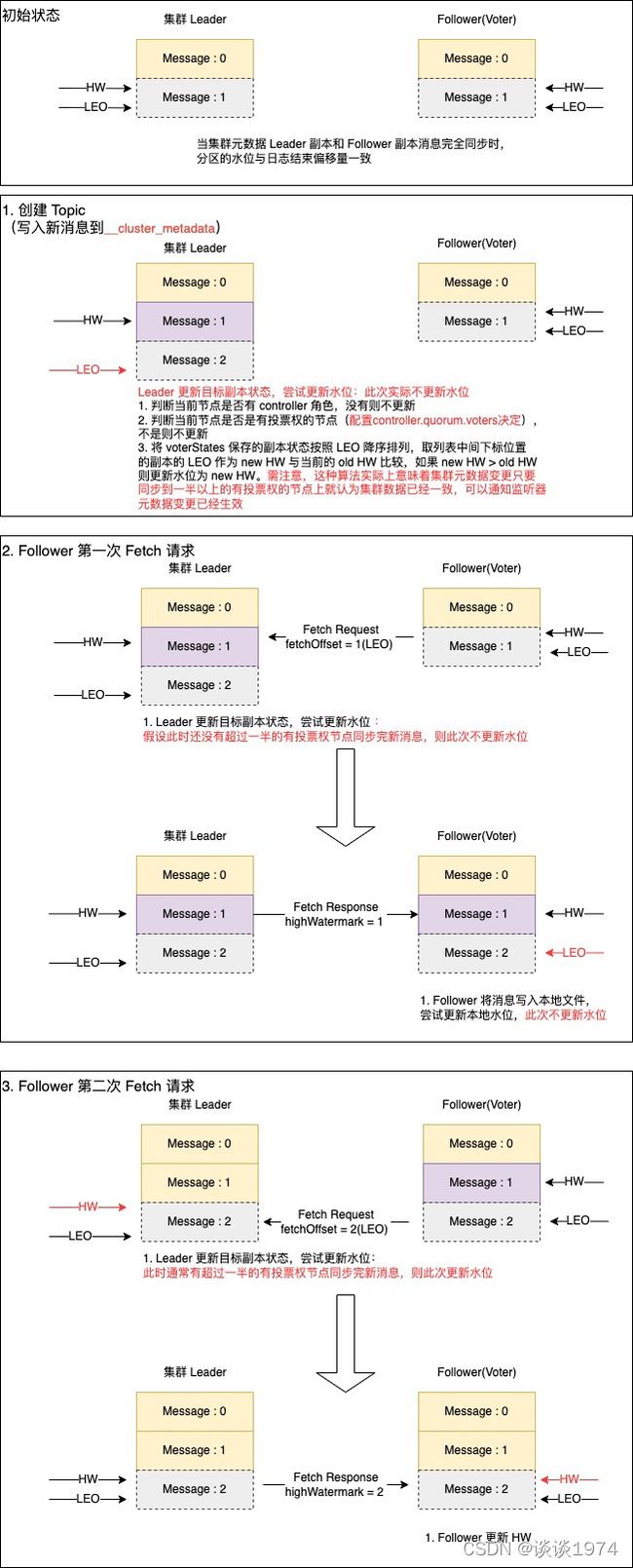
上图展示了 Follower(Voter) 两次 Fetch 请求 完成元数据及 HW 同步的过程,大致分为 4 个阶段:
初始状态
当 Kafka 集群处于某个静态初始时间点时,Leader 节点和所有 Follower 节点保存的元数据都是一致的,此时 HW 与 LEO 指向同一个位置。在以上示例图中,Leader 节点和 Follower(Voter) 节点都保存了 Offset=0 的数据,HW 和 LEO 都指向还未写入的 Offset=1 的位置元数据消息写入
以上示例中,Leader 节点接收外部请求,变更集群元数据时,会将元数据消息写入到本地的元数据分区副本,则 Leader 节点 LEO 指向 Offset=2 的位置。此时 Leader 节点还会尝试更新本地目标副本的状态,其中包括了 HW 水位更新的逻辑,不过在当前阶段实际不会更新 HW 水位。状态更新具体算法如下,下文提及的尝试更新本地目标副本的状态皆指代以下过程:
- 判断当前节点是否有 controller 角色,没有则不进行更新处理
- 判断当前节点是否是有投票权的节点(
配置controller.quorum.voters决定),不是则不进行更新处理- 将
voterStates保存的所有副本状态对象按照 LEO 降序排列,取排序列表中间下标位置的副本的 LEO 作为 new HW 与当前的 old HW 比较,如果 new HW > old HW 则更新水位为 new HW。这种算法实际上意味着元数据变更只要同步到一半以上的有投票权的节点上就认为集群元数据已经一致,也就是笔者提到的非强一致性要求的体现第一次 Fetch 请求的交互
Follower(Voter) 节点会定时发送 Fetch 请求到 Leader 节点同步元数据,发起的请求中会携带本地分区副本的 LEO=1。 Leader 节点接收到请求后,更新本地voterStates中保存的该 Follower 副本状态,尝试更新本地目标副本的状态。假设此时还没有一半以上有投票权的节点保存新消息,那 Leader 节点不会更新本地 HW,仅仅返回元数据消息。Follower 节点在处理 Fetch 响应时,仅会将元数据消息追加到本地副本,并将 LEO 指向 Offset=2 的位置第二次 Fetch 请求的交互
与第一次 Fetch 请求交互类似,只不过这时发起的请求中会携带本地分区副本的 LEO=2。假设此时已经有一半以上的有投票权的节点保存了新消息,那么 Leader 节点在尝试更新本地目标副本的状态时会更新本地 HW 指向 Offset=2 的位置,并在 Fetch 响应中将当前 HW 返回给 Follower。Follower 依据 Leader 的 HW 更新本地副本 HW 指向 Offset=2 的位置,最终完成 HW 同步
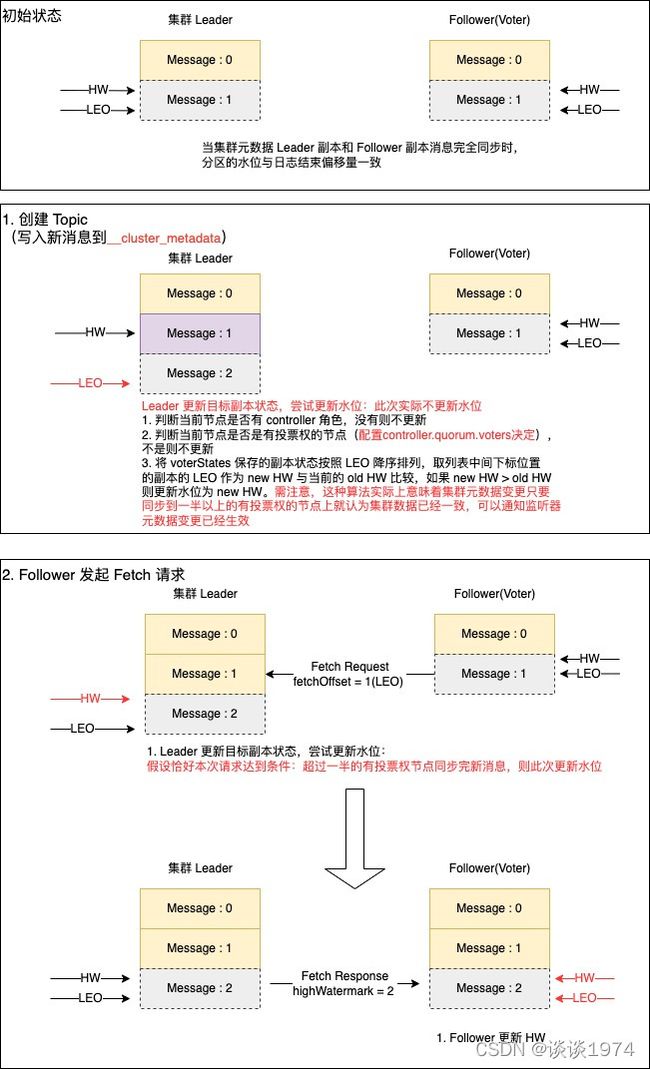
1.2 一次 Fetch 完成 HW 同步
下图是一次 Fetch 完成 HW 同步的示意,可以看到和上文1.1节 两次 Fetch 完成 HW 同步非常相似,读者大致了解即可
一次 Fetch 请求完成 HW 同步的不同点在于:当某个 Follower(Voter) 节点在元数据变更后第一次发起 Fetch 请求时,已经有一半以上有投票权的节点保存了新的元数据消息,则 Leader 的 HW 已经更新。此时这个 Follower(Voter) 节点可以在这第一次 Fetch 响应中感知到新的 HW,直接通过一次请求就完成本地 HW 同步
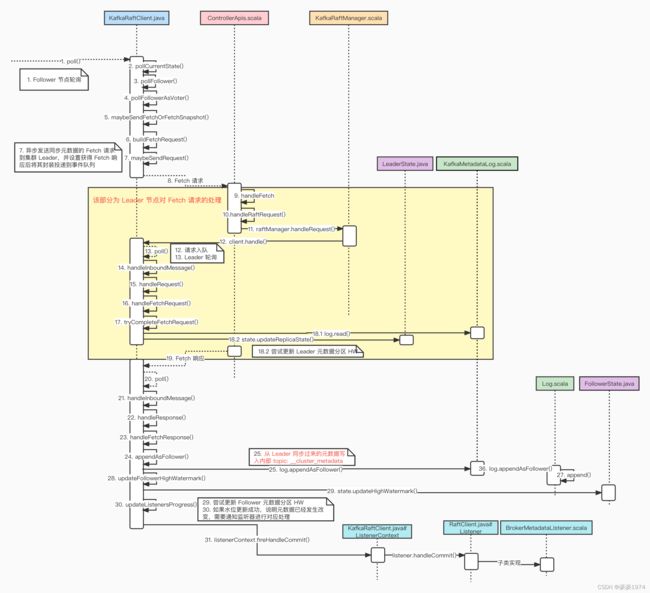
2. 元数据主从同步源码分析
以下为集群的 Follower 从 Leader 处同步元数据的处理过程,大致分为了 3 个步骤:
- Follower 节点 Fetch 请求的发起
- Leader 节点对 Fetch 请求的处理
- Follower 节点对 Fetch 响应的处理
2.1 Follower 节点 Fetch 请求的发起
-
在 服务端集群选主的流程 完成后,Kafka 集群中的节点都取得了各自身份,并且所有节点都将定时执行
KafkaRaftClient.java#poll()方法履行职能。以下源码中,和本文相关的是调用KafkaRaftClient.java#pollCurrentState()方法依据节点当前的身份进行相应处理public void poll() { pollListeners(); long currentTimeMs = time.milliseconds(); if (maybeCompleteShutdown(currentTimeMs)) { return; } long pollStateTimeoutMs = pollCurrentState(currentTimeMs); long cleaningTimeoutMs = snapshotCleaner.maybeClean(currentTimeMs); long pollTimeoutMs = Math.min(pollStateTimeoutMs, cleaningTimeoutMs); kafkaRaftMetrics.updatePollStart(currentTimeMs); RaftMessage message = messageQueue.poll(pollTimeoutMs); currentTimeMs = time.milliseconds(); kafkaRaftMetrics.updatePollEnd(currentTimeMs); if (message != null) { handleInboundMessage(message, currentTimeMs); } } -
KafkaRaftClient.java#pollCurrentState()方法是个分发入口,处于Follower状态的节点将执行KafkaRaftClien.javat#pollFollower()方法进入下一层分发,可以看到有投票权的 Follower 节点将调用KafkaRaftClien.javat#pollFollowerAsVoter()方法private long pollCurrentState(long currentTimeMs) { if (quorum.isLeader()) { return pollLeader(currentTimeMs); } else if (quorum.isCandidate()) { return pollCandidate(currentTimeMs); } else if (quorum.isFollower()) { return pollFollower(currentTimeMs); } else if (quorum.isVoted()) { return pollVoted(currentTimeMs); } else if (quorum.isUnattached()) { return pollUnattached(currentTimeMs); } else if (quorum.isResigned()) { return pollResigned(currentTimeMs); } else { throw new IllegalStateException("Unexpected quorum state " + quorum); } } private long pollFollower(long currentTimeMs) { FollowerState state = quorum.followerStateOrThrow(); if (quorum.isVoter()) { return pollFollowerAsVoter(state, currentTimeMs); } else { return pollFollowerAsObserver(state, currentTimeMs); } } -
KafkaRaftClien.javat#pollFollowerAsVoter()方法的关键处理分为两步:- 首先是进行
Leader探活,具体做法检查本节点上一次向 Leader 节点发起的 Fetch 请求响应时间是否已经过期,如果过期则 Leader 节点可能挂掉了,当前 Follower(Voter) 节点需进入候选者状态,发起新的选举 - 如果 Leader 节点正常工作,则调用
KafkaRaftClien.javat#maybeSendFetchOrFetchSnapshot()方法向 Leader 发起同步元数据的 Fetch 请求
private long pollFollowerAsVoter(FollowerState state, long currentTimeMs) { GracefulShutdown shutdown = this.shutdown.get(); if (shutdown != null) { // If we are a follower, then we can shutdown immediately. We want to // skip the transition to candidate in any case. return 0; } else if (state.hasFetchTimeoutExpired(currentTimeMs)) { logger.info("Become candidate due to fetch timeout"); transitionToCandidate(currentTimeMs); return 0L; } else { long backoffMs = maybeSendFetchOrFetchSnapshot(state, currentTimeMs); return Math.min(backoffMs, state.remainingFetchTimeMs(currentTimeMs)); } } - 首先是进行
-
KafkaRaftClien.javat#maybeSendFetchOrFetchSnapshot()方法如下,其中核心处理简单明了:- 如果当前节点不需要获取快照数据,则设置
KafkaRaftClien.javat#buildFetchRequest()方法作为请求构建器,构建 Fetch 请求 - 调用
KafkaRaftClien.javat#maybeSendRequest()方法将异步发送请求
private long maybeSendFetchOrFetchSnapshot(FollowerState state, long currentTimeMs) { final Supplier<ApiMessage> requestSupplier; if (state.fetchingSnapshot().isPresent()) { RawSnapshotWriter snapshot = state.fetchingSnapshot().get(); long snapshotSize = snapshot.sizeInBytes(); requestSupplier = () -> buildFetchSnapshotRequest(snapshot.snapshotId(), snapshotSize); } else { requestSupplier = this::buildFetchRequest; } return maybeSendRequest(currentTimeMs, state.leaderId(), requestSupplier); } - 如果当前节点不需要获取快照数据,则设置
-
KafkaRaftClien.javat#buildFetchRequest()方法简单易懂,需要注意的是此处会通过log.endOffset().offset取得本地日志的末端偏移量 LEO,将其填入 Fetch 请求private FetchRequestData buildFetchRequest() { FetchRequestData request = RaftUtil.singletonFetchRequest(log.topicPartition(), fetchPartition -> { fetchPartition .setCurrentLeaderEpoch(quorum.epoch()) .setLastFetchedEpoch(log.lastFetchedEpoch()) .setFetchOffset(log.endOffset().offset); }); return request .setMaxBytes(MAX_FETCH_SIZE_BYTES) .setMaxWaitMs(fetchMaxWaitMs) .setClusterId(clusterId) .setReplicaId(quorum.localIdOrSentinel()); } -
KafkaRaftClien.javat#maybeSendRequest()是通用的发送请求方法,重要的处理步骤如下:- 首先调用
RequestManager.java#getOrCreate()方法根据目标节点的ID 取得 ConnetcionState,接下来检查与目标节点的连接是否正常,连接就绪才进行下一步 - 连接正常,则调用请求构建器构建出对应的请求对象,然后将其封装到
RaftRequest.Outbound对象内部,并设置请求完成时的回调方法。回调方法的处理是将响应数据封装到RaftResponse.Inbound对象,并将其投入到消息队列中异步处理 - 最后调用
KafkaNetworkChannel.scala#send()方法将请求投入到底层异步发送
private long maybeSendRequest( long currentTimeMs, int destinationId, Supplier<ApiMessage> requestSupplier ) { ConnectionState connection = requestManager.getOrCreate(destinationId); if (connection.isBackingOff(currentTimeMs)) { long remainingBackoffMs = connection.remainingBackoffMs(currentTimeMs); logger.debug("Connection for {} is backing off for {} ms", destinationId, remainingBackoffMs); return remainingBackoffMs; } if (connection.isReady(currentTimeMs)) { int correlationId = channel.newCorrelationId(); ApiMessage request = requestSupplier.get(); RaftRequest.Outbound requestMessage = new RaftRequest.Outbound( correlationId, request, destinationId, currentTimeMs ); requestMessage.completion.whenComplete((response, exception) -> { if (exception != null) { ApiKeys api = ApiKeys.forId(request.apiKey()); Errors error = Errors.forException(exception); ApiMessage errorResponse = RaftUtil.errorResponse(api, error); response = new RaftResponse.Inbound( correlationId, errorResponse, destinationId ); } messageQueue.add(response); }); channel.send(requestMessage); logger.trace("Sent outbound request: {}", requestMessage); connection.onRequestSent(correlationId, currentTimeMs); return Long.MAX_VALUE; } return connection.remainingRequestTimeMs(currentTimeMs); } - 首先调用
2.2 Leader 节点对 Fetch 请求的处理
-
Follower 发送的同步元数据的 Fetch 请求将抵达 Leader 节点的
ControllerApis.scala#handle()方法进行分发,最终交由ControllerApis.scala#handleRaftRequest()方法处理。从以下代码可以看到,真正的核心处理是KafkaRaftManager.scala#handleRequest()方法调用override def handle(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = { try { request.header.apiKey match { case ApiKeys.FETCH => handleFetch(request) case ApiKeys.FETCH_SNAPSHOT => handleFetchSnapshot(request) case ApiKeys.CREATE_TOPICS => handleCreateTopics(request) case ApiKeys.DELETE_TOPICS => handleDeleteTopics(request) case ApiKeys.API_VERSIONS => handleApiVersionsRequest(request) case ApiKeys.ALTER_CONFIGS => handleLegacyAlterConfigs(request) case ApiKeys.VOTE => handleVote(request) case ApiKeys.BEGIN_QUORUM_EPOCH => handleBeginQuorumEpoch(request) case ApiKeys.END_QUORUM_EPOCH => handleEndQuorumEpoch(request) case ApiKeys.DESCRIBE_QUORUM => handleDescribeQuorum(request) case ApiKeys.ALTER_ISR => handleAlterIsrRequest(request) case ApiKeys.BROKER_REGISTRATION => handleBrokerRegistration(request) case ApiKeys.BROKER_HEARTBEAT => handleBrokerHeartBeatRequest(request) case ApiKeys.UNREGISTER_BROKER => handleUnregisterBroker(request) case ApiKeys.ALTER_CLIENT_QUOTAS => handleAlterClientQuotas(request) case ApiKeys.INCREMENTAL_ALTER_CONFIGS => handleIncrementalAlterConfigs(request) case ApiKeys.ALTER_PARTITION_REASSIGNMENTS => handleAlterPartitionReassignments(request) case ApiKeys.LIST_PARTITION_REASSIGNMENTS => handleListPartitionReassignments(request) case ApiKeys.ENVELOPE => handleEnvelopeRequest(request, requestLocal) case ApiKeys.SASL_HANDSHAKE => handleSaslHandshakeRequest(request) case ApiKeys.SASL_AUTHENTICATE => handleSaslAuthenticateRequest(request) case ApiKeys.ALLOCATE_PRODUCER_IDS => handleAllocateProducerIdsRequest(request) case ApiKeys.CREATE_PARTITIONS => handleCreatePartitions(request) case ApiKeys.DESCRIBE_ACLS => aclApis.handleDescribeAcls(request) case ApiKeys.CREATE_ACLS => aclApis.handleCreateAcls(request) case ApiKeys.DELETE_ACLS => aclApis.handleDeleteAcls(request) case _ => throw new ApiException(s"Unsupported ApiKey ${request.context.header.apiKey}") } } catch { case e: FatalExitError => throw e case e: ExecutionException => requestHelper.handleError(request, e.getCause) case e: Throwable => requestHelper.handleError(request, e) } } def handleFetch(request: RequestChannel.Request): Unit = { authHelper.authorizeClusterOperation(request, CLUSTER_ACTION) handleRaftRequest(request, response => new FetchResponse(response.asInstanceOf[FetchResponseData])) } private def handleRaftRequest(request: RequestChannel.Request, buildResponse: ApiMessage => AbstractResponse): Unit = { val requestBody = request.body[AbstractRequest] val future = raftManager.handleRequest(request.header, requestBody.data, time.milliseconds()) future.whenComplete { (responseData, exception) => val response = if (exception != null) { requestBody.getErrorResponse(exception) } else { buildResponse(responseData) } requestHelper.sendResponseExemptThrottle(request, response) } } -
KafkaRaftManager.scala#handleRequest()方法的关键处理如下:- 将接收的请求封装为
RaftRequest.Inbound对象 - 调用
KafkaRaftClient.java#handle()方法将其投入到异步消息队列中
override def handleRequest( header: RequestHeader, request: ApiMessage, createdTimeMs: Long ): CompletableFuture[ApiMessage] = { val inboundRequest = new RaftRequest.Inbound( header.correlationId, request, createdTimeMs ) client.handle(inboundRequest) inboundRequest.completion.thenApply { response => response.data } } - 将接收的请求封装为
-
KafkaRaftClient.java#handle()方法只是个请求入队操作,简单易懂public void handle(RaftRequest.Inbound request) { messageQueue.add(Objects.requireNonNull(request)); } -
队列中的请求最终还是需要通过定时执行的
KafkaRaftClient.java#poll()来处理,这个方法中与队列消息处理相关的则是KafkaRaftClient.java#handleInboundMessage(),进入该方法后还需要经过KafkaRaftClient.java#handleRequest()分发,最终 Leader 节点将执行KafkaRaftClient.java#handleFetchRequest()方法来完成 Fetch 请求处理public void poll() { pollListeners(); long currentTimeMs = time.milliseconds(); if (maybeCompleteShutdown(currentTimeMs)) { return; } long pollStateTimeoutMs = pollCurrentState(currentTimeMs); long cleaningTimeoutMs = snapshotCleaner.maybeClean(currentTimeMs); long pollTimeoutMs = Math.min(pollStateTimeoutMs, cleaningTimeoutMs); kafkaRaftMetrics.updatePollStart(currentTimeMs); RaftMessage message = messageQueue.poll(pollTimeoutMs); currentTimeMs = time.milliseconds(); kafkaRaftMetrics.updatePollEnd(currentTimeMs); if (message != null) { handleInboundMessage(message, currentTimeMs); } } private void handleInboundMessage(RaftMessage message, long currentTimeMs) { logger.trace("Received inbound message {}", message); if (message instanceof RaftRequest.Inbound) { RaftRequest.Inbound request = (RaftRequest.Inbound) message; handleRequest(request, currentTimeMs); } else if (message instanceof RaftResponse.Inbound) { RaftResponse.Inbound response = (RaftResponse.Inbound) message; ConnectionState connection = requestManager.getOrCreate(response.sourceId()); if (connection.isResponseExpected(response.correlationId)) { handleResponse(response, currentTimeMs); } else { logger.debug("Ignoring response {} since it is no longer needed", response); } } else { throw new IllegalArgumentException("Unexpected message " + message); } } private void handleRequest(RaftRequest.Inbound request, long currentTimeMs) { ApiKeys apiKey = ApiKeys.forId(request.data.apiKey()); final CompletableFuture<? extends ApiMessage> responseFuture; switch (apiKey) { case FETCH: responseFuture = handleFetchRequest(request, currentTimeMs); break; case VOTE: responseFuture = completedFuture(handleVoteRequest(request)); break; case BEGIN_QUORUM_EPOCH: responseFuture = completedFuture(handleBeginQuorumEpochRequest(request, currentTimeMs)); break; case END_QUORUM_EPOCH: responseFuture = completedFuture(handleEndQuorumEpochRequest(request, currentTimeMs)); break; case DESCRIBE_QUORUM: responseFuture = completedFuture(handleDescribeQuorumRequest(request, currentTimeMs)); break; case FETCH_SNAPSHOT: responseFuture = completedFuture(handleFetchSnapshotRequest(request)); break; default: throw new IllegalArgumentException("Unexpected request type " + apiKey); } responseFuture.whenComplete((response, exception) -> { final ApiMessage message; if (response != null) { message = response; } else { message = RaftUtil.errorResponse(apiKey, Errors.forException(exception)); } RaftResponse.Outbound responseMessage = new RaftResponse.Outbound(request.correlationId(), message); request.completion.complete(responseMessage); logger.trace("Sent response {} to inbound request {}", responseMessage, request); }); } -
KafkaRaftClient.java#handleFetchRequest()方法比较简单,处理流程如下:- 首先是对请求进行参数有效性检查
- 调用
KafkaRaftClient.java#tryCompleteFetchRequest()尝试完成 Fetch 请求处理,如果这个请求不需要立即返回响应,则调用FuturePurgatory.java#await()方法等待 - 在等待超时结束或者提前结束后,再次调用
KafkaRaftClient.java#tryCompleteFetchRequest()尝试完成 Fetch 请求处理
private CompletableFuture<FetchResponseData> handleFetchRequest( RaftRequest.Inbound requestMetadata, long currentTimeMs ) { FetchRequestData request = (FetchRequestData) requestMetadata.data; if (!hasValidClusterId(request.clusterId())) { return completedFuture(new FetchResponseData().setErrorCode(Errors.INCONSISTENT_CLUSTER_ID.code())); } if (!hasValidTopicPartition(request, log.topicPartition())) { // Until we support multi-raft, we treat topic partition mismatches as invalid requests return completedFuture(new FetchResponseData().setErrorCode(Errors.INVALID_REQUEST.code())); } FetchRequestData.FetchPartition fetchPartition = request.topics().get(0).partitions().get(0); if (request.maxWaitMs() < 0 || fetchPartition.fetchOffset() < 0 || fetchPartition.lastFetchedEpoch() < 0 || fetchPartition.lastFetchedEpoch() > fetchPartition.currentLeaderEpoch()) { return completedFuture(buildEmptyFetchResponse( Errors.INVALID_REQUEST, Optional.empty())); } FetchResponseData response = tryCompleteFetchRequest(request.replicaId(), fetchPartition, currentTimeMs); FetchResponseData.PartitionData partitionResponse = response.responses().get(0).partitions().get(0); if (partitionResponse.errorCode() != Errors.NONE.code() || FetchResponse.recordsSize(partitionResponse) > 0 || request.maxWaitMs() == 0) { return completedFuture(response); } CompletableFuture<Long> future = fetchPurgatory.await( fetchPartition.fetchOffset(), request.maxWaitMs()); return future.handle((completionTimeMs, exception) -> { if (exception != null) { Throwable cause = exception instanceof ExecutionException ? exception.getCause() : exception; // If the fetch timed out in purgatory, it means no new data is available, // and we will complete the fetch successfully. Otherwise, if there was // any other error, we need to return it. Errors error = Errors.forException(cause); if (error != Errors.REQUEST_TIMED_OUT) { logger.debug("Failed to handle fetch from {} at {} due to {}", request.replicaId(), fetchPartition.fetchOffset(), error); return buildEmptyFetchResponse(error, Optional.empty()); } } // FIXME: `completionTimeMs`, which can be null logger.trace("Completing delayed fetch from {} starting at offset {} at {}", request.replicaId(), fetchPartition.fetchOffset(), completionTimeMs); return tryCompleteFetchRequest(request.replicaId(), fetchPartition, time.milliseconds()); }); } -
KafkaRaftClient.java#tryCompleteFetchRequest()的关键处理如下:- 取出 Fetch 请求携带的参数,调用
ReplicatedLog#validateOffsetAndEpoch()校验其有效性,如果 Follower 节点与 Leader 节点的集群版本出现分歧,将在该步骤检测出来 - 有效性校验通过,调用
KafkaMetadataLog.scala#read()方法读取指定 Offset 偏移量之后的元数据消息,这部分是通用的流程,笔者在Kafka 3.0 源码笔记(4)-Kafka 服务端对客户端的 Fetch 请求处理 中分析过,本文不再赘述 - 调用
LeaderState.java#updateReplicaState()方法尝试更新 Follower 副本的状态,这个过程中如果完成当前节点的 HW 更新则调用KafkaRaftClient.java#onUpdateLeaderHighWatermark()方法通知本地监听器 - 最后调用
KafkaRaftClient.java#buildFetchResponse()方法构建 Fetch 响应
private FetchResponseData tryCompleteFetchRequest( int replicaId, FetchRequestData.FetchPartition request, long currentTimeMs ) { try { Optional<Errors> errorOpt = validateLeaderOnlyRequest(request.currentLeaderEpoch()); if (errorOpt.isPresent()) { return buildEmptyFetchResponse(errorOpt.get(), Optional.empty()); } long fetchOffset = request.fetchOffset(); int lastFetchedEpoch = request.lastFetchedEpoch(); LeaderState<T> state = quorum.leaderStateOrThrow(); ValidOffsetAndEpoch validOffsetAndEpoch = log.validateOffsetAndEpoch(fetchOffset, lastFetchedEpoch); final Records records; if (validOffsetAndEpoch.kind() == ValidOffsetAndEpoch.Kind.VALID) { LogFetchInfo info = log.read(fetchOffset, Isolation.UNCOMMITTED); if (state.updateReplicaState(replicaId, currentTimeMs, info.startOffsetMetadata)) { onUpdateLeaderHighWatermark(state, currentTimeMs); } records = info.records; } else { records = MemoryRecords.EMPTY; } return buildFetchResponse(Errors.NONE, records, validOffsetAndEpoch, state.highWatermark()); } catch (Exception e) { logger.error("Caught unexpected error in fetch completion of request {}", request, e); return buildEmptyFetchResponse(Errors.UNKNOWN_SERVER_ERROR, Optional.empty()); } } - 取出 Fetch 请求携带的参数,调用
-
LeaderState.java#updateReplicaState()方法的处理就是上文1.1节两次 Fetch 完成 HW 同步中提到的尝试更新本地目标副本的状态的具体算法实现,关键源码如下,读者可对照上文自行理解public boolean updateReplicaState(int replicaId, long fetchTimestamp, LogOffsetMetadata logOffsetMetadata) { // Ignore fetches from negative replica id, as it indicates // the fetch is from non-replica. For example, a consumer. if (replicaId < 0) { return false; } ReplicaState state = getReplicaState(replicaId); state.updateFetchTimestamp(fetchTimestamp); return updateEndOffset(state, logOffsetMetadata); } private boolean updateEndOffset(ReplicaState state, LogOffsetMetadata endOffsetMetadata) { state.endOffset.ifPresent(currentEndOffset -> { if (currentEndOffset.offset > endOffsetMetadata.offset) { if (state.nodeId == localId) { throw new IllegalStateException("Detected non-monotonic update of local " + "end offset: " + currentEndOffset.offset + " -> " + endOffsetMetadata.offset); } else { log.warn("Detected non-monotonic update of fetch offset from nodeId {}: {} -> {}", state.nodeId, currentEndOffset.offset, endOffsetMetadata.offset); } } }); state.endOffset = Optional.of(endOffsetMetadata); state.hasAcknowledgedLeader = true; return isVoter(state.nodeId) && updateHighWatermark(); } private boolean updateHighWatermark() { // Find the largest offset which is replicated to a majority of replicas (the leader counts) List<ReplicaState> followersByDescendingFetchOffset = followersByDescendingFetchOffset(); int indexOfHw = voterStates.size() / 2; Optional<LogOffsetMetadata> highWatermarkUpdateOpt = followersByDescendingFetchOffset.get(indexOfHw).endOffset; if (highWatermarkUpdateOpt.isPresent()) { // The KRaft protocol requires an extra condition on commitment after a leader // election. The leader must commit one record from its own epoch before it is // allowed to expose records from any previous epoch. This guarantees that its // log will contain the largest record (in terms of epoch/offset) in any log // which ensures that any future leader will have replicated this record as well // as all records from previous epochs that the current leader has committed. LogOffsetMetadata highWatermarkUpdateMetadata = highWatermarkUpdateOpt.get(); long highWatermarkUpdateOffset = highWatermarkUpdateMetadata.offset; if (highWatermarkUpdateOffset > epochStartOffset) { if (highWatermark.isPresent()) { LogOffsetMetadata currentHighWatermarkMetadata = highWatermark.get(); if (highWatermarkUpdateOffset > currentHighWatermarkMetadata.offset || (highWatermarkUpdateOffset == currentHighWatermarkMetadata.offset && !highWatermarkUpdateMetadata.metadata.equals(currentHighWatermarkMetadata.metadata))) { highWatermark = highWatermarkUpdateOpt; log.trace( "High watermark updated to {} based on indexOfHw {} and voters {}", highWatermark, indexOfHw, followersByDescendingFetchOffset ); return true; } else if (highWatermarkUpdateOffset < currentHighWatermarkMetadata.offset) { log.error("The latest computed high watermark {} is smaller than the current " + "value {}, which suggests that one of the voters has lost committed data. " + "Full voter replication state: {}", highWatermarkUpdateOffset, currentHighWatermarkMetadata.offset, voterStates.values()); return false; } else { return false; } } else { highWatermark = highWatermarkUpdateOpt; log.trace( "High watermark set to {} based on indexOfHw {} and voters {}", highWatermark, indexOfHw, followersByDescendingFetchOffset ); return true; } } } return false; } private List<ReplicaState> followersByDescendingFetchOffset() { return new ArrayList<>(this.voterStates.values()).stream() .sorted() .collect(Collectors.toList()); }
2.3 Follower 节点对 Fetch 响应的处理
-
Follower 节点收到 Fetch 响应后,将触发 2.1 节步骤6第2步动作,也就是将 Fetch 响应封装起来投递到消息队列。Follower 节点处理异步消息的触发点也是
KafkaRaftClient.java#poll(),与2.2节步骤4的分发流程类似,Fetch 的响应最终将会流转到KafkaRaftClient.java#handleFetchResponse()方法处理:- 首先检查 Fetch 响应中是否包含集群版本分歧的信息,如果有则可能是发生了 Leader 宕机重选等异常情况,这时需要调用
KafkaMetadataLog.scala#truncateToEndOffset()方法根据当前 Leader 节点版本信息进行日志截断以完成异常恢复,关于异常恢复的机制本文暂时不做深入讨论 - 如果没有异常情况,则首先将 Fetch 响应携带的元数据消息取出来,调用
KafkaRaftClient.java#appendAsFollower()方法将其追加到本地日志文件,然后调用KafkaRaftClient.java#updateFollowerHighWatermark()方法尝试更新本地 HW
private boolean handleFetchResponse( RaftResponse.Inbound responseMetadata, long currentTimeMs ) { FetchResponseData response = (FetchResponseData) responseMetadata.data; Errors topLevelError = Errors.forCode(response.errorCode()); if (topLevelError != Errors.NONE) { return handleTopLevelError(topLevelError, responseMetadata); } if (!RaftUtil.hasValidTopicPartition(response, log.topicPartition())) { return false; } FetchResponseData.PartitionData partitionResponse = response.responses().get(0).partitions().get(0); FetchResponseData.LeaderIdAndEpoch currentLeaderIdAndEpoch = partitionResponse.currentLeader(); OptionalInt responseLeaderId = optionalLeaderId(currentLeaderIdAndEpoch.leaderId()); int responseEpoch = currentLeaderIdAndEpoch.leaderEpoch(); Errors error = Errors.forCode(partitionResponse.errorCode()); Optional<Boolean> handled = maybeHandleCommonResponse( error, responseLeaderId, responseEpoch, currentTimeMs); if (handled.isPresent()) { return handled.get(); } FollowerState state = quorum.followerStateOrThrow(); if (error == Errors.NONE) { FetchResponseData.EpochEndOffset divergingEpoch = partitionResponse.divergingEpoch(); if (divergingEpoch.epoch() >= 0) { // The leader is asking us to truncate before continuing final OffsetAndEpoch divergingOffsetAndEpoch = new OffsetAndEpoch( divergingEpoch.endOffset(), divergingEpoch.epoch()); state.highWatermark().ifPresent(highWatermark -> { if (divergingOffsetAndEpoch.offset < highWatermark.offset) { throw new KafkaException("The leader requested truncation to offset " + divergingOffsetAndEpoch.offset + ", which is below the current high watermark" + " " + highWatermark); } }); long truncationOffset = log.truncateToEndOffset(divergingOffsetAndEpoch); logger.info("Truncated to offset {} from Fetch response from leader {}", truncationOffset, quorum.leaderIdOrSentinel()); } else if (partitionResponse.snapshotId().epoch() >= 0 || partitionResponse.snapshotId().endOffset() >= 0) { // The leader is asking us to fetch a snapshot if (partitionResponse.snapshotId().epoch() < 0) { logger.error( "The leader sent a snapshot id with a valid end offset {} but with an invalid epoch {}", partitionResponse.snapshotId().endOffset(), partitionResponse.snapshotId().epoch() ); return false; } else if (partitionResponse.snapshotId().endOffset() < 0) { logger.error( "The leader sent a snapshot id with a valid epoch {} but with an invalid end offset {}", partitionResponse.snapshotId().epoch(), partitionResponse.snapshotId().endOffset() ); return false; } else { final OffsetAndEpoch snapshotId = new OffsetAndEpoch( partitionResponse.snapshotId().endOffset(), partitionResponse.snapshotId().epoch() ); // Do not validate the snapshot id against the local replicated log // since this snapshot is expected to reference offsets and epochs // greater than the log end offset and high-watermark state.setFetchingSnapshot(log.storeSnapshot(snapshotId)); } } else { Records records = FetchResponse.recordsOrFail(partitionResponse); if (records.sizeInBytes() > 0) { appendAsFollower(records); } OptionalLong highWatermark = partitionResponse.highWatermark() < 0 ? OptionalLong.empty() : OptionalLong.of(partitionResponse.highWatermark()); updateFollowerHighWatermark(state, highWatermark); } state.resetFetchTimeout(currentTimeMs); return true; } else { return handleUnexpectedError(error, responseMetadata); } } - 首先检查 Fetch 响应中是否包含集群版本分歧的信息,如果有则可能是发生了 Leader 宕机重选等异常情况,这时需要调用
-
KafkaRaftClient.java#appendAsFollower()方法的核心是调用KafkaMetadataLog.scala#appendAsFollower()方法进行本地日志的追加,这部分是通用的流程,笔者在Kafka 3.0 源码笔记(7)-Kafka 服务端对客户端的 Produce 请求处理 中分析过,本文不再赘述private void appendAsFollower( Records records ) { LogAppendInfo info = log.appendAsFollower(records); log.flush(); OffsetAndEpoch endOffset = endOffset(); kafkaRaftMetrics.updateFetchedRecords(info.lastOffset - info.firstOffset + 1); kafkaRaftMetrics.updateLogEnd(endOffset); logger.trace("Follower end offset updated to {} after append", endOffset); } -
KafkaRaftClient.java#updateFollowerHighWatermark()方法的核心处理如下:- 首先调用
FollowerState.java#updateHighWatermark()方法尝试更新本地 HW - 如果 HW 更新成功,说明元数据变动开始生效,则需要两步处理:
- 调用
KafkaMetadataLog.scala#updateHighWatermark()方法更新日志文件的 HW - 调用
KafkaRaftClient.java#updateListenersProgress()方法通知本地的元数据监听器。
以创建 Topic 场景为例,HW 更新后,Kafka 集群的所有节点都需要检查自己是否需要负责新 Topic 下的分区的副本,如果是则进行本地日志文件创建等操作,而这些功能的实现就是借助这里的监听器通知机制
- 调用
private void updateFollowerHighWatermark( FollowerState state, OptionalLong highWatermarkOpt ) { highWatermarkOpt.ifPresent(highWatermark -> { long newHighWatermark = Math.min(endOffset().offset, highWatermark); if (state.updateHighWatermark(OptionalLong.of(newHighWatermark))) { logger.debug("Follower high watermark updated to {}", newHighWatermark); log.updateHighWatermark(new LogOffsetMetadata(newHighWatermark)); updateListenersProgress(newHighWatermark); } }); } - 首先调用
-
FollowerState.java#updateHighWatermark()方法比较简单,只需要注意 HW 是单调递增的,新的 HW 值比旧的 HW 大才能成功更新public boolean updateHighWatermark(OptionalLong highWatermark) { if (!highWatermark.isPresent() && this.highWatermark.isPresent()) throw new IllegalArgumentException("Attempt to overwrite current high watermark " + this.highWatermark + " with unknown value"); if (this.highWatermark.isPresent()) { long previousHighWatermark = this.highWatermark.get().offset; long updatedHighWatermark = highWatermark.getAsLong(); if (updatedHighWatermark < 0) throw new IllegalArgumentException("Illegal negative high watermark update"); if (previousHighWatermark > updatedHighWatermark) throw new IllegalArgumentException("Non-monotonic update of high watermark attempted"); if (previousHighWatermark == updatedHighWatermark) return false; } this.highWatermark = highWatermark.isPresent() ? Optional.of(new LogOffsetMetadata(highWatermark.getAsLong())) : Optional.empty(); return true; } -
KafkaRaftClient.java#updateListenersProgress()方法实现主要是通知监听器元数据变化,最终将回调到RaftClient.java#Listener监听器的接口方法。至此,服务端元数据的主从同步分析告一段落需注意,BrokerServer 启动过程中会调用
KafkaRaftManager.scala#register()方法将BrokerMetadataListener注册到KafkaRaftClient中以便完成元数据变动时的对应处理private void updateListenersProgress(long highWatermark) { for (ListenerContext listenerContext : listenerContexts.values()) { listenerContext.nextExpectedOffset().ifPresent(nextExpectedOffset -> { if (nextExpectedOffset < log.startOffset() && nextExpectedOffset < highWatermark) { SnapshotReader<T> snapshot = latestSnapshot().orElseThrow(() -> new IllegalStateException( String.format( "Snapshot expected since next offset of %s is %s, log start offset is %s and high-watermark is %s", listenerContext.listenerName(), nextExpectedOffset, log.startOffset(), highWatermark ) )); listenerContext.fireHandleSnapshot(snapshot); } }); // Re-read the expected offset in case the snapshot had to be reloaded listenerContext.nextExpectedOffset().ifPresent(nextExpectedOffset -> { if (nextExpectedOffset < highWatermark) { LogFetchInfo readInfo = log.read(nextExpectedOffset, Isolation.COMMITTED); listenerContext.fireHandleCommit(nextExpectedOffset, readInfo.records); } }); } }