AWS云计算技术架构探索系列之六-数据库
一、前言
数据库是软件工程重要的组件,号称软件界的三座大山之一(另外两个为操作系统,浏览器)。目前的数据库种类,可以分为关系型和非关系型:
(1)关系型数据库,如MySQL,Oracle,SQL Server,PostreSQL等。
(2)非关系型数据,又可以细分:
- 键值存储数据库,如Redis,Memcache。
- 面向文档型数据库,如MongoDB。
- 列式存储数据库,如HBase,ClickHouse
- 时序数据库,如InfluxDB
- 搜索数据库,如Solr,Elasticsearch。
- 图数据库,如Neo4J,GraphDB。
AWS针对关系型和非关系型数据库在兼容这些开源数据库协议的同时,又充分考虑了云的特点,推出了多种云原生数据库,主要包括Aurora,DynamoDB,ElastiCache ,Redshift。
二、Aurora
AWS提供了托管基于MySQL,Oracle,PostgreSQL等关系型数据库服务,支持原先基于这些数据库的数据快速迁移到云上。同时,AWS还提供了云原生关系型数据Aurora,兼容MySQL和PostgreSQL协议,为用户直接上云提供了更多了选择。那么问题来了,即提供了基于开源的RDS服务,为何还要再提供一套全新的数据库呢?我们先来看Aurora的牛逼之处。
基本同样规格的实例,官网给出了"5倍于MySQL,3倍于PostgreSQL"的吞吐量性能指标。这个数据是非常亮眼的(对于阿里的PolarDB在3倍于MySQL性能左右),意味着绝不是基于MySQL引擎的小修小补。
1、计算和存储分离
先来看下MySQL数据库的正常写入,如下图所示:

为了确保数据写入磁盘安全,进行写放大,由于MySQL的IO设计主要是针对本地磁盘优化,并不适合网络存储。同时,在多节点的情况下,还需要同步到其他从节点,再由从节点写入磁盘,为了保证副本的高可用,这些写入都是串行的(即图示的3,5)随着节点数增多,延迟增大。
在云环境下,计算和存储是分离的,数据库的主要矛盾由IO性能瓶颈变成了网络传输性能瓶颈。我们看下Aurora的解决思路。

MySQL无法对存储控制,所以才用放大写入来确保存储的安全,当机器突然断电造成数据不一致的情况下也能恢复。对于Aurora来说,存储恰恰是它的可以控制的,所以放大写就不那么重要了。
我们知道Redolog即数据,只要写入Log,就可以回放成数据,并可以备份和故障恢复,优化的第一步就是把冗余的写入改成了一次Log写入。同样是因为MySQL无法控制存储,所以多节点的数据同步必须是通过MySQL的实例引擎之间同步完成,那么优化的第二步就是,统一由主节点并行写入各个副本,Replica 节点只需要接收 Primay 的 Log 信息来更新本地的缓存和一些全局的配置,无需写入存储,MySQL 实例引擎从纷杂繁复的任务中解放出来,只需要 SQL 相关的工作就可以了。
2、基于Quorum模型的一致性
传统的MySQL数据库为了确保多节点的一致性,采用的2PC协议,但是2PC对错误的容忍度太低,Aurora采用基于Quorum协议来保证存储节点的一致性。
对于N个副本,一次性写入数据,需要W节点写入成功才算成功,剩下的节点通过相互之间的一致性协议(如gossip协议)可以达到共同的状态;读取数据,要求至少从 R个节点中读出相同的数据才能决定哪个数据是最新的。满足R+W>N,就能保证能读到最新节点数据。
Aurora采用的是6副本,部署到3个AZ,也就是每个AZ有2个副本,写入的时候,允许一个AZ不可用,也就是4/6,读取的时候,允许一个AZ以及另一个节点不可用,也就是3/6。
3、数据分片
通过Quorum模型,Aurora可以保证AZ级别不同时发生,数据库可用性和正确性就能得到保证,属于降低故障的发生频率(MTTF,Mean Time to Fail),但是故障发生后,还需要考虑如何降低故障的修复时间(MTTR,Mean Time To Repair)。
Aurora将存储进行分片管理,每个分片10G,6个10G副本构成一个PGs(Protection Groups),Aurora存储由若干个PGs构成。这样,一个副本就分为了多个分片,并分散在多台机器上。一方面,读取的时候利用多台主机的 IO 带宽,对性能也有提升;另一方面,分片作为故障的恢复最小单元,在10Gbps网络下,一个10G的分片可以在10s内恢复,可以极大的降低修复时间。
当然,数据分片后,对于事务的管理也带来了复杂性。
总之,Aurora与传统的数据库区别的关键点是计算和存储分离,这种分离的架构下,主要矛盾由磁盘的IO转化为网络的IO,网络将成为最大的瓶颈,因此Aurora集中精力优化网络以便提高系统吞吐能力。将日志下推到分布式存储服务层,减少写放大,通过Quorum模型,在性能影响可控的前提下,解决云环境下的各种异常错误;对数据进行分片,减少了故障恢复时间。
三、DynamoDB
DynamoDB从种类上看是NoSQL数据库,从存储数据类型看,是分布式的K-V和文档的类型的集合体,不同于Aurora等关系型数据库,为广大开发者所熟知,我们先来理解下DynamoDB的核心概念。
1、核心组件
- 表,DynamoDB 将数据存储在表中,表是数据的集合,可以类比关系型数据的表。
- 项目,每个表包含零个或更多个项目,项目是一组属性,具有不同于所有其他项目的唯一标识。可以类比关系型数据库的行或者记录。
- 属性, 每个项目包含一个或多个属,属性是基础的数据元素,无需进一步分解。可以类似关系型数据库的列和字段。
- 主键,主键唯一标识表中的每个项目。DynamoDB支持两种不同类型的主键。
分区键,一个称之为分区键的属性构成简单主键,这分区键的值作为内部Hash函数的输入,Hash函数的输出决定了项目将存储到的分区(DynamoDB 内部的物理存储)。
分区键和排序键,组成的复合键,此类型的键由两个属性组成。第一个属性是分区键,第二个属性排序键,分区键决定项目数据存储的物理分区,排序键决定在该分区上的排序。

如图所示,Artist是分区键,SongTitle是排序键,Artist+SongTitle组成复合主键。
- 二级索引,除了根据主键查询外,DynamoDB还支持二级索引,二级索引页分为两类
全局二级索引 ,分区键和排序键可与基表中的这些键不同的索引。
本地二级索引 ,分区键与基表相同但排序键不同的索引。
DynamoDB 中的每个表具有 20 个全局二级索引(默认配额)和 5 个本地二级索引的配额。
对于Music表,可以创建基于Genre分区键以及AlbumTitle排序键的全局二级索GenreAlbumTitle。

对于二级索引GenreAlbumTitle,具有以下特点。
(1)每个索引属于一个基表,比如上例中的music就是GenreAlbumTitle索引的基表。
(2)创建索引时,可以指定哪些属性可以复制或者投影到索引,基表的键属性是必须要从基表中投影到索引的,比如上例中的Artist和SongTitle属性。
(3)自动维护索引,当变更某个项目时,DynamoDB 会变更索引中的对应项目。
2、架构
Dynamo是一个为Amazon的平台上构建的可扩展和高度可用的分布式数据存储系统,提供一个”永远在线”的用户体验。AWS就Dynamo设计通过下面的论文进行了详细的阐述。
英文版本:http://www.read.seas.harvard.edu/~kohler/class/cs239-w08/decandia07dynamo.pdf
译文版本:[转][译] [论文] Dynamo: Amazon's Highly Available Key-value Store(SOSP 2007) - 简书
下面就论文中核心设计原理进行介绍:
(1)可扩展
Dynamo 的核心需求之一是:系统必须支持增量扩展。这就要求有一种机制能够将数据分散到系统中的不同的节点上。Dynamo 的分散方案基于一致性哈希。
我们先来看下一致性哈希的原理。
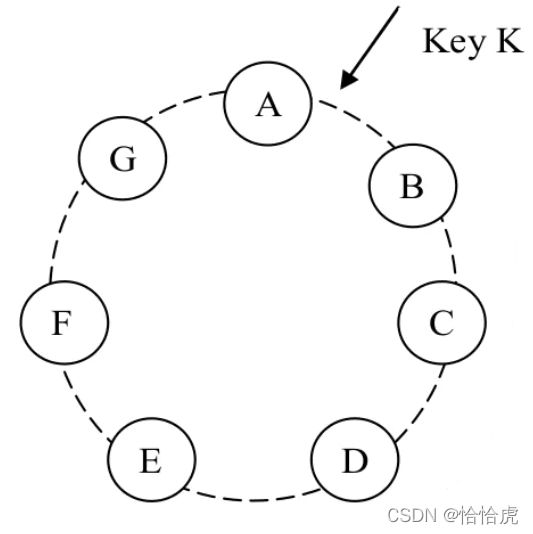
在一致性哈希中,哈希函数的输出是一个固定的范围,通常作为一个循环空间,或称环(ring)。每个节点都会随机分配一个在这个循环空间内的值(position或者token),这个值代表了节点在这个环上的位置position。比如A,B,C。
当我们存储一条数据项时,首先对它的 key 做哈希得到一个哈希值,其次在环上沿着顺时针方向找到第一个position比这个哈希值更大的节点,进行保存。比如这里的key,计算并查找后,发现位于A和B之间,那么就保存到B节点。
一致性哈希的优势在于扩充或者缩容节点时,只会影响相邻的节点,其他节点不受影响。比如这里的C是后续新增的,那只需要迁移D节点上一部分数((B,C]),其他节点数据保持不变。
但是一致性哈希也存在劣势,即负载不均。比如Key哈希值大部分落在DE之间的区域,那么E节点负载就会很重,而其他节点就很轻闲。同时,一致性哈希也没有考虑各节点存在的性能差异。
为了解决这个问题,Dynamo采用了一致性哈希的一个变种,使用虚拟节点的概念,一个虚拟节点看上去和一个普通节点一样,但一个普通节点实际上可能管理不止一台虚拟节点。也就是一个节点,不是映射到环上某一个节点,而是多个点(虚拟节点)。
新加一个节点,分配相同的虚拟节点个数,就会获得与其他节点大致相同的负载,同时可以根据节点容量,调整虚拟节点的个数,实现异构情况的性能差异的均衡负载。
删除一个节点,这个节点分配的虚拟节点会均匀分配到其他节点上,实现负载的均衡。
(2)高度可用
根据CAP理论,当满足P的情况下,C和A只能满足一个,也就是一致性和可用性是无法同时满足的。Dynamo强调的是可用性,所以需要牺牲一致性。Dynamo被设计成最终一致性(eventually consistent)的数据存储,即所有的更新操作,最终达到所有副本。
- Data version
DynamoDB最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就需要多个副本节点都可以写入(MySQL只能主节点写),才能达到这个要求。由于最终一致性,多节点并发写,会导致写冲突。DynamoDB采用多版本的机制解决这一问题,Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这其中的关键技术就是Vector Clock ,如下图所示:

我们来分析下这个过程:
第一步,客户端通过节点Sx一个对象,并创建对象的向量时钟 vector clock。至此,系统有了一个对象 D1 和它的向量时钟 [(Sx, 1)]。
第二步,客户端通过节点Sx更新这个对象,先读取现有的对象以及向量时钟,发现是Sx节点上次写入的,就直接覆盖,写入新的对象D2以及向量时钟 [(Sx, 2)]。
第三步,此时在节点Sy,Sz上并发写,先读取各自节点的对象和时钟,此时都读到Sx同步的对象D2[(Sx, 2)],然后再覆盖写入(因为D3和D4都是D2的后代,所以可以覆盖),由于是不同节点写入,需要保留上一节点的时钟,即D3([Sx,2],[Sy,1]),D4([Sx,2],[Sz,1])。
第四步,经过第三步,就产生了分支了,D3,D4同步到Sx节点,并被客户端从Sx节点读到后,客户端执行reconciliation,节点 Sx 执行协调写,Sx 会更新自己在 clock 中的序列号,最终新生成的数据 D5 的 clock 格式如下:[(Sx, 3), (Sy, 1), (Sz, 1)]。
一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。通过对比两份不同数据的Vector Clock就能发现他们的关系。所以应用层在读取数据的时候,系统会连带这Vector Clock一同返回;在操作数据的时候也需要带上数据的Vector Clock一同提交。
- 读冲突解决
Data version其实质解决了数据写入冲突的问题,由于DynamoDB是最终一致性,副本节点间的数据同步需要一定的时间,那如何保证在这个时间内读取到最新的数据,DynamoDB采用了类似Quorum一致性(参见上面Quorum模型),读取到做个版本,通过对Vector Clock分析,如果存在没有因果关系的版本(如D3,D4),都会返回给客户端,由客户端进行reconciliation。
DynamoDB的通常配置[N,W,R]为[3,2,2]
- 数据复制
可扩展性部分讲到,通过变种的一致性哈希算法,将数据写入到对应的节点上,为了保证数据的可用性,必须同步复制到副本上,那如何选择副本节点呢?
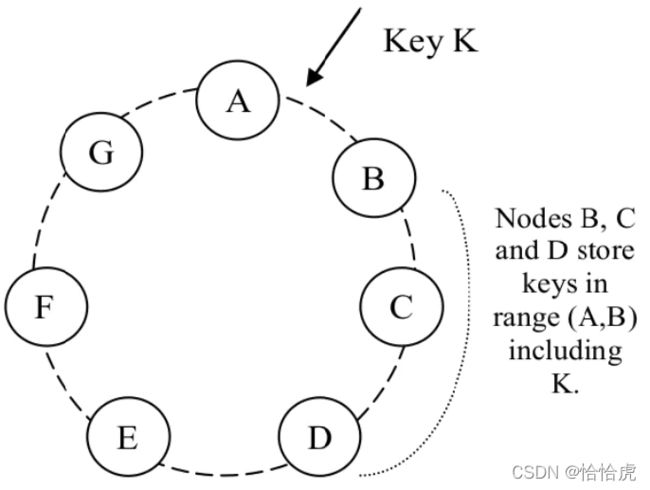
DynamoDB会沿着顺时针方向,选择N-1个节点作为数据副本几点。如上图所示,B节点的数据,会在C,D节点进行冗余。对于D节点来说,其存储的数据key的范围包括(A,B],(B,C],(C,D]。
存储某个特定 key 的所有节点组成一个列表,称为 preference list(优先列表)。由于引入了虚拟节点,可能存在副本节点对应同一个物理节点,比如B,C两个虚拟节点实际是一个物理节点,3副本实际只有2副本。为了避免这种情况,preference list在选择节点时,会跳过一些位置,以保证副本节点处于不同的物理节点上。
- 短时故障处理(Hinted Handoff)
DynamoDB设计的核心是要确保"Always Writeable",在某个节点故障情况下,需要不影响写入。Dynamo 采用了一种宽松的仲裁机制(sloppy quorum):所有读和写操作在 preference list 的前 N 个健康节点上执行;注意这 N 个节点不一定就是前 N 个节点, 因为遇到不健康的节点,会沿着一致性哈希环的顺时针方向顺延。
以上图为例,如果N设置为3,(A,B]的数据,可以在B,C,D写入,但是此时B节点故障,所以B节点的写入就转移到E节点,E节点会单独保存一份数据,一旦B节点可用了,就将数据返回到B节点,同时删除E节点上数据。
使用这种 hinted handoff 的方式,Dynamo 保证了在节点或网络发生短时故障时读和写 操作不会失败。
- 持久故障处理(副本跨数据中心同步)
在节点成员变动较小、节点故障只是短时的情况下,hinted handoff 方式工作良好。但如果是整个数据中心故障,如掉电,网络故障等会导致整个数据中心的不可用,此时需要将副本在多个数据中心同步。
Dynamo 实现了一种 逆熵(副本同步)协议来保证副本是同步的。其核心思想是快速检测出副本间的不一致,实现最小的数据转移。Dynamo 使用了 Merkle trees。
Merkle trees是一个哈希树,其叶子节点是 key 对应的 value 的哈希值,父节点是其子节点的哈希。所以对比根节点就能知道整个树是否一致,如果不一致,继续向下检测,直到叶节点,找到未同步的key,针对这些key进行同步即可。
四、ElastiCache
ElasticCache是AWS提供的全托管的内存数据库,集成并兼容Redis和Memcached两大主流的内存引擎。一般用于高并发读的场景,比如社交网络、游戏、媒体分享和问答门户。
我们先来对比下Memcached与redis。
| 特性 | Memcached | redis |
| 延迟 | 亚毫秒 | 亚毫秒 |
| 分布式架构 | 支持,数据增加时可扩展节点 | 支持,数据增加时可扩展节点 |
| 支持语言 | C,C++,java,python等 | C,C++,java,python等 |
| 复杂数据结构 | 不支持 | 支持,如set,sortset,hash,bit arrays等 |
| 多线程 | 支持 | 不支持,单线程 |
| 高可用 | 不支持 | 支持,快照和复制 |
| 事务 | 不支持 | 支持,可以保证一串 命令的原子性 |
| Lua 脚本 | 不支持 | 支持 |
| 地理位置查询 | 不支持 | 支持 |
当对于数据可用性较高,且数据结构复杂,选择redis更合适,目前redis的使用更加广泛,重点描述redis的特性。
ElasticCache设计需要满足高性能,高可用以及可扩展的特性。
1、高性能
相比于RDS,S3等基于磁盘的数据存储,内存数据存储在并发,延迟上具有巨大的优势。如下图所示:
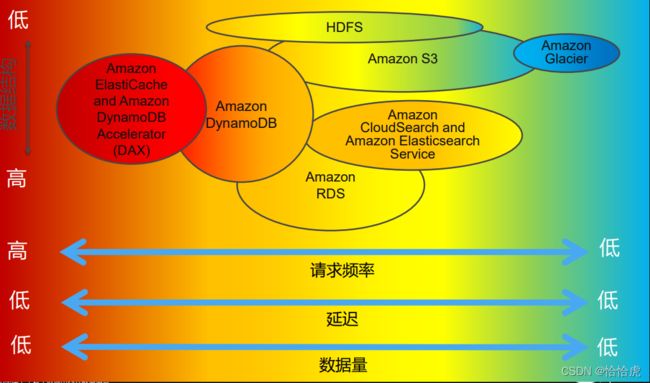
2、高可用
对于访问频率要求高的场景,可用性对系统的要求非常用,比如在秒杀的场景下,如果系统宕机,那么对于业务的影响是致命的。
ElasticCache for redis 采用多副本,多可用区,以及备份恢复等多种手段达到这一目的。
ElasticCache for redis采用集群模式,每个集群支持500个节点,对于一个分片,可以有1个主分片节点和最多5个副本分片节点。那么这个集群支持的分片数范围介于 83 个分片(一个主分片和 5 个副本分片)和 500 个分片(一个主分片,无副本分片)之间。

自动进行故障检查,当发生主节点故障,将会将其中的副节点提升为主节点,继续提供服务。

如果shard中所有的节点都放在一个可用区,那么该可用区故障,会导致所有的节点不可用,此时需要Redis集群跨可用区,将shard的副本进行打散。

由于内存的易失性,节点的硬件故障会导致数据丢失,需要对数据进行快照备份。
ElasticCache for redis支持自动定时以及手动备份,备份后的数据保存到S3中。快照实际是使用BIGSAVE命令生成RDB,会对节点的性能有一定影响,特别是内存的使用率(写时复制,如果存在数据改变,需要复制一份),一般建议使用副本进行备份。
3、高扩展性
redis有16384个哈希槽,当数据量不大情况下,可以部署较少的节点,如三个节点,每个节点承载三分之一的流量。

当数据量增大,三个节点无法承载流量时,需要扩充节点,如有3个节点扩充到5个。原先分布在3个节点的数据需要在线迁移到新的节点上。如下图所示:
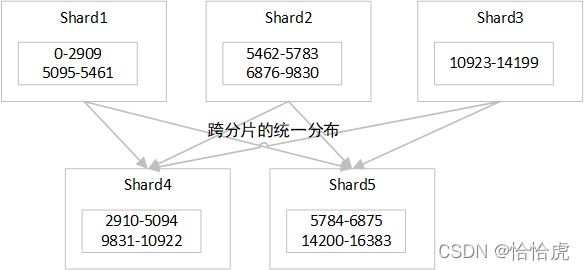
由于涉及到数据重新分布,对于在线业务有一定的影响,一般在业务低峰期实施。
五、Redshift
Redshift是AWS提供的完全托管式的数据仓库产品,可以跨运营数据库、数据湖、数据仓库,具备PB级数据处理分析能力。可以类比开源的OLTP产品,比如Clickhouse,TIDB。
1、架构
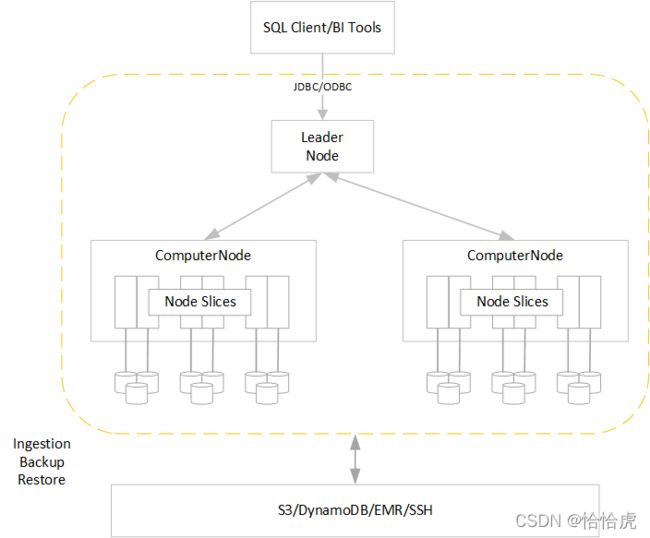
Redshift的架构如下图所示:

(1)SQL Client/Bi Tools可以通过jdbc/odbc连接到redshift的Leader节点,支持SQL语句查询。
(2)Leader节点,领导负责与客户的连接,对SQL的解析,并制定执行计划,它与计算节点并行执行这些计划,并合并中间查询结果,最终返回给客户端。
(3)Computer节点,接受领导节点的计算任务并执行,每个计算节点具拥有自己的专用 CPU、内存和连接的磁盘存储,用户的数据存储在计算节点上。计算节点是分布式的,可扩展的,根据工作负载,实现节点增加和删除。
(4)计算分片,一个计算节点分为多个切片。将为每个切片分配节点的内存和磁盘空间的一部分,从而处理分配给节点的工作负载的一部分。领导节点管理向切片分发数据的工作,并将任何查询或其他数据库操作的工作负载分配给切片。然后,切片将并行工作以完成操作。
(5)Redshift具有强大的AWS生态,与其他服务一起使用。支持与S3结合,通过Redshift spetrum分析S3存储数据,并将分析后的结果数据保存到S3;也可以从DynamoDB中copy数据到Redshift数仓中进行分析;同时COPY 使用 SSH 连接到远程主机并在远程主机上运行命令以生成数据。
Redshift是典型的分布式+master-woker架构,具备高性能,快速扩容,大规模并行查询,安全性等特点。
2、内部组件和功能概述
(1)客户端通过JDBC、ODBC进行连接Lead 节点,发起查询
(2)在Lead节点内:
- 通过监听和交流层进行连接处理,接收查询请求
- 解析查询请求
- 将命令分为:Queries and Joins 或者 非查询命令
- 解析,生成执行计划并优化
- 生成执行代码,分发给计算节点
- 同时在Lead节点内会有
1). 查询、工作负载管理器
2). 调度器
3). 通讯层
这三种内容,来管理和调度计算节点的工作
(3)计算节点通过通讯层接收到执行代码后
(4)会通过分发器进行查询切片
(5)并将代码应用在每个具体的切片上
(6)对切片应用的作业会对磁盘进行IO查询检索
(7) 查询完成后,每个计算节点将各自的中间结果返回给Lead节点
(8) Lead节点聚合结果
(9) 通过通讯层,将结果范围给客户端
3、高性能
Redshift在数据仓库和分析工作负载方面实现了比传统数据库高出 10 倍的性能,这是如何做到的呢。
(1)列式存储
传统的OLTP数据库采用的是行式存储,便于事务的处理。Redshift采用列式存储。

对于OLAP,通常是对于大数据集的聚合操作,仅查询所涉及的。将列的数据按顺序存储在介质中,基于列存储的系统,有效的减少了I/O操作,从而提高了查询性能。
(2)数据压缩
由于采用了列式存储,相同类型的数据按照顺序存储,相比较行式存储,可以实现显著的压缩。Redshift 能够应用与列式数据类型关联的自适应压缩编码,选择最合适的压缩技术。
(3)大规模并行处理
Redshift自动在各个节点之间分配数据并加载查询。
Redshift 将表行分配给计算节点,以便能并行处理数据。通过为每个表选择相应的分配键,可以优化数据分配以均衡工作负载,并最大程度地减少节点间的数据移动。
多个计算节点处理所有查询处理以获得最终结果聚合。
六、总结
本篇主要介绍了AWS的四类主要数据库的架构。
Aurora是基于云原生的关系型数据库,其核心的架构特点是计算和分离,将传统数据库的磁盘IO转化为网络的IO,通过对于分布式存储EBS的网络优化,大大提升了性能。
DynamoDB是NoSQL数据库,也是分布式的K-V和文档的类型的集合体,其架构设计重点聚焦可用性和可扩展性两个核心问题。对于可用性,强调的是写可用,即任何情况下都可以写入,通过向量时钟解决多版本。对于可扩展,采用一致性哈希的变种算法,实现节点的快速扩展和负载均衡。
ElasticCache是内存数据库,包括Memcached和Redis两种引擎,对于Redis,通过集群的分片和副本技术实现扩展性和可用性。
Redshift是数据仓库产品,其架构采用典型的Master-Worker模式,通过大规模的并行查询,列式存储和压缩提升性能,并与其他服务一起,提供大数据分析的整套解决方案。
附件:
AWS云计算技术架构探索系列之一-开篇
AWS云计算技术架构探索系列之二-身份账户体系(IAM)
AWS云计算技术架构探索系列之三-计算
AWS云计算技术架构探索系列之四-存储
AWS云计算技术架构探索系列之五-网络
AWS云计算技术架构探索系列之六-数据库
AWS云计算技术架构探索系列之七-DevOps