Flink相关API开发及运行架构和实现原理详解
一、Flink相关API说明
-
flinkAPI官网:Apache Flink 1.12 Documentation: Flink DataStream API Programming Guide
Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
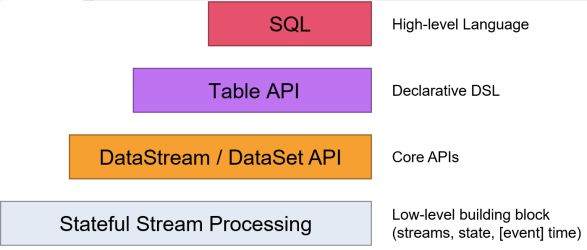
注意:我自己使用的是flink 1.7.2版本,但是在Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了,大家最好优先使用DataStream流式API,既支持无界数据处理/流处理,也支持有界数据处理/批处理!

二、Flink运行架构
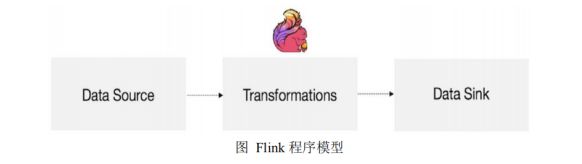
1、flink的编程模型
-
Flink程序主要包含三部分:Source/Transformation/Sink(源/转换操作/输出)
2、创建工程,maven依赖准备
-
properties
UTF-8
UTF-8
1.8
1.8
1.8
2.12
1.12.0
-
dependencies
-
build
src/main/java
org.apache.maven.plugins
maven-compiler-plugin
3.5.1
1.8
1.8
org.apache.maven.plugins
maven-surefire-plugin
2.18.1
false
true
**/*Test.*
**/*Suite.*
org.apache.maven.plugins
maven-shade-plugin
2.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.tjcu.TestDataStreamYarn
3、需求
-
使用Flink实现WordCount
4、编码步骤
-
编码步骤参考官网:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/datastream_api.html
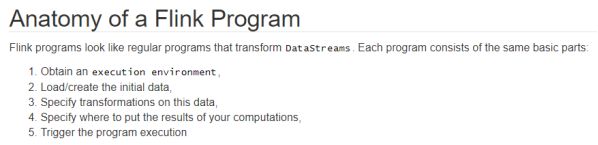
1.准备环境-env
2.准备数据-source
3.处理数据-transformation
4.输出结果-sink
5.触发执行-execute
-
其中创建环境参考官网:
getExecutionEnvironment() //推荐使用
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String... jarFiles)
5、代码实现

(1)DataSet(了解)
package com.tjcu;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author :王恒杰
* @date :Created in 2022/4/20 15:37
* @description:使用Flink完成WordCount-DataSet
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
*/
public class TestDataSet {
public static void main(String[] args) throws Exception {
//老版本的API如下,目前不推荐使用了
//1.准备环境 env
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//2.准备数据-source
DataSource stringDataSource = executionEnvironment.fromElements("whj hadoop spark", "whj hadoop spark", "whj hadoop spark");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
FlatMapOperator wordsDS = stringDataSource.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
DataSet> wordAndOne = wordsDS.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
//value就是每一个单词
return Tuple2.of(value, 1);
}
});
//分组
UnsortedGrouping> grouped = wordAndOne.groupBy(0);
//聚合
AggregateOperator> result = grouped.sum(1);
//输出结果-sink
result.print();
}
}
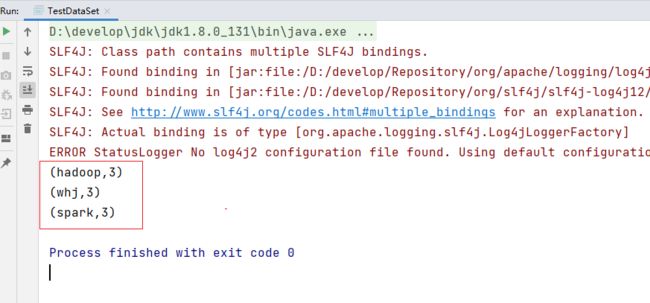
(2)基于DataStream(匿名内部类-处理流)
package com.tjcu;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;;
/**
* @author :王恒杰
* @date :Created in 2022/4/20 16:07
* @description:需求:使用Flink完成WordCount-DataStream 批处理
* * 编码步骤
* * 1.准备环境-env
* * 2.准备数据-source
* * 3.处理数据-transformation
* * 4.输出结果-sink
* * 5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
*/
public class TestDataStream {
public static void main(String[] args) throws Exception {
//新版本的流批统一API,既支持流处理也支持批处理
//1.准备环境 env
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// executionEnvironment.setRuntimeMode(RuntimeExecutionMode.BATCH);//注意:使用DataStream实现批处理
executionEnvironment.setRuntimeMode(RuntimeExecutionMode.STREAMING);//注意:使用DataStream实现流处理
//executionEnvironment.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//注意:使用DataStream根据数据源自动选择使用流还是批
//2.准备数据-source
DataStreamSource stringDataStreamSource = executionEnvironment.fromElements("whj hadoop spark", "whj spark", "whj");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
DataStream words = stringDataStreamSource.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out) throws Exception {
//value就是每一行数据
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});
DataStream> wordAndOne = words.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
//value就是一个个单词
return Tuple2.of(value, 1);
}
});
//分组:注意DataSet中分组是groupBy,DataStream分组是keyBy
KeyedStream, String> grouped = wordAndOne.keyBy(t -> t.f0);
//聚合
SingleOutputStreamOperator> result = grouped.sum(1);
//TODO 3.sink
result.print();
//启动并等待程序结束
executionEnvironment.execute();
}
}
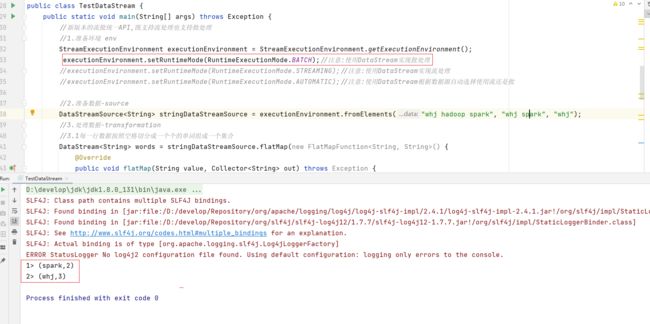
-
注意:在Flink1.12中DataStream既支持流处理也支持批处理,如何区分?
env.setRuntimeMode(RuntimeExecutionMode.BATCH);//注意:使用DataStream实现批处理
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//注意:使用DataStream实现流处理
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//注意:使用DataStream根据数据源自动选择使用流还是批
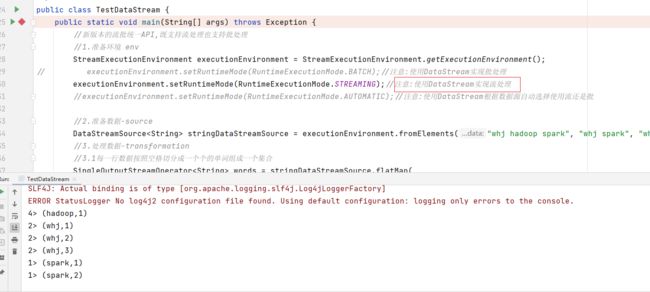
(3)代码实现-DataStream-Lambda
package com.tjcu;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;;import java.util.Arrays;
/**
* @author :王恒杰
* @date :Created in 2022/4/20 16:07
* @description:需求:使用Flink完成WordCount-DataStream 批处理
* * 编码步骤
* * 1.准备环境-env
* * 2.准备数据-source
* * 3.处理数据-transformation
* * 4.输出结果-sink
* * 5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
*/
public class TestDataStream {
public static void main(String[] args) throws Exception {
//新版本的流批统一API,既支持流处理也支持批处理
//1.准备环境 env
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// executionEnvironment.setRuntimeMode(RuntimeExecutionMode.BATCH);//注意:使用DataStream实现批处理
executionEnvironment.setRuntimeMode(RuntimeExecutionMode.STREAMING);//注意:使用DataStream实现流处理
//executionEnvironment.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//注意:使用DataStream根据数据源自动选择使用流还是批
//2.准备数据-source
DataStreamSource stringDataStreamSource = executionEnvironment.fromElements("whj hadoop spark", "whj spark", "whj");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
SingleOutputStreamOperator words = stringDataStreamSource.flatMap(
(String value, Collector out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING);
DataStream> wordAndOne = words.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING,Types.INT));
//分组:注意DataSet中分组是groupBy,DataStream分组是keyBy
KeyedStream, String> grouped = wordAndOne.keyBy(t -> t.f0);
//聚合
SingleOutputStreamOperator> result = grouped.sum(1);
//TODO 3.sink
result.print();
//启动并等待程序结束
executionEnvironment.execute();
}
}
(4)On-Yarn-掌握
-
注意:写入HDFS如果存在权限问题,进行如下设置:
hadoop fs -chmod -R 777 /
并在代码中添加:
System.setProperty("HADOOP_USER_NAME", "root")
-
代码实现:
package com.tjcu;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* @author :王恒杰
* @date :Created in 2022/4/20 16:28
* @description:使用Flink完成WordCount-DataStream--使用lambda表达式--修改代码使适合在Yarn上运行 编码步骤
* * 1.准备环境-env
* * 2.准备数据-source
* * 3.处理数据-transformation
* * 4.输出结果-sink
* * 5.触发执行-execute//批处理不需要调用!流处理需要
*/
public class TestDataStreamYarn {
public static void main(String[] args) throws Exception {
//获取参数
ParameterTool params = ParameterTool.fromArgs(args);
String output = null;
if (params.has("output")) {
output = params.get("output");
} else {
output = "hdfs://node1:8020/wordcount/output_" + System.currentTimeMillis();
}
//1.准备环境-env
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.准备数据源-source
DataStream linesDS = executionEnvironment.fromElements("whj hadoop spark", "whj hadoop spark", "whj hadoop", "whj");
//3.处理数据-transformation
DataStream> result = linesDS
.flatMap(
(String value, Collector out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING)
.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT))
//.keyBy(0);
.keyBy((KeySelector, String>) t -> t.f0)
.sum(1);
//4.输出结果-sink
result.print();
//如果执行报hdfs权限相关错误,可以执行 hadoop fs -chmod -R 777 /
System.setProperty("HADOOP_USER_NAME", "root");//设置用户名
//result.writeAsText("hdfs://node1:8020/wordcount/output_"+System.currentTimeMillis()).setParallelism(1);
result.writeAsText(output).setParallelism(1);
//5.触发执行-execute
executionEnvironment.execute();
}
}
-
打包
-
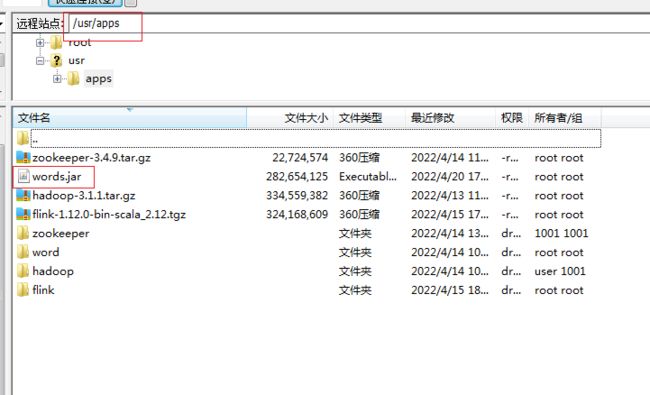
上传
-
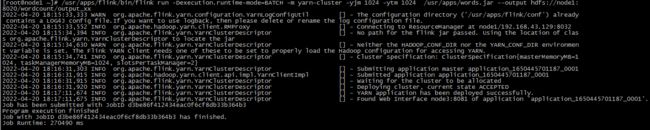
提交执行
/usr/apps/flink/bin/flink run -Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 1024 -ytm 1024
/usr/apps/words.jar --output hdfs://node1:8020/wordcount/output_xx
-
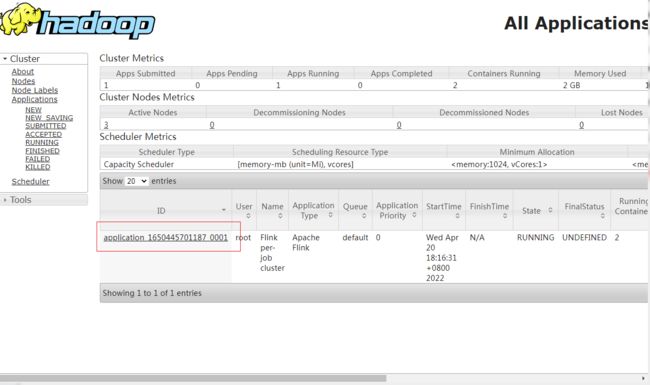
在Web页面可以观察到提交的程序:
http://node1:8088/cluster或者http://node1:50070/explorer.html#/
-
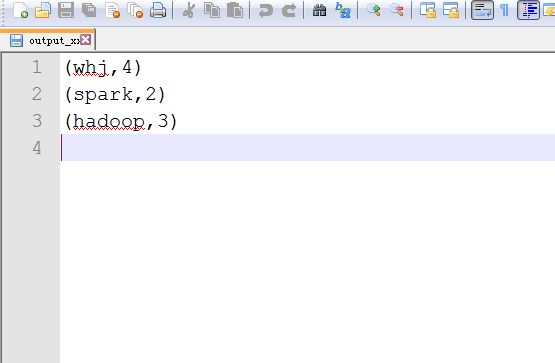
输出结果:http://192.168.43.129:50070/explorer.html#/wordcount
三、Flink原理
1、Flink角色分工
-
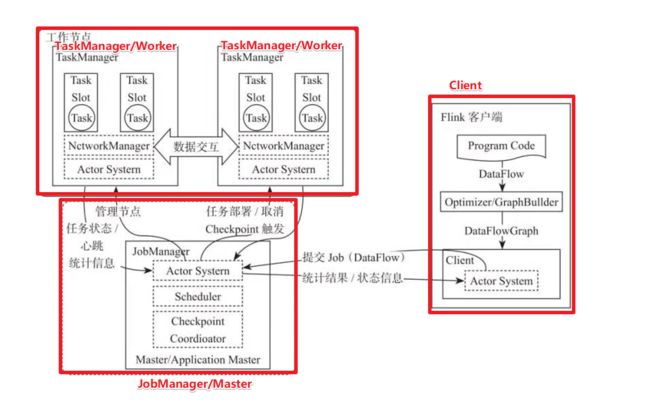
在实际生产中,Flink 都是以集群在运行,在运行的过程中包含了两类进程。
#1. JobManager
他扮演的是集群管理者的角色,负责调度任务,协调checkpoints、协调故障恢复、
收集 Job 的状态信息,并管理 Flink 集群中的从节点 TaskManager。
#2.TaskManager
实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task;
TaskManager 还是所在节点的管理员,
它负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向 JobManager 汇报。
#3.Client:
用户在提交编写好的 Flink 工程时,会先创建一个客户端再进行提交,这个客户端就是 Client
-
上面个案例的运行就是从节点执行的

-
角色分工
2、Flink执行流程
-
博客参考:Flink 基本工作原理_sxiaobei的博客-CSDN博客_flink原理
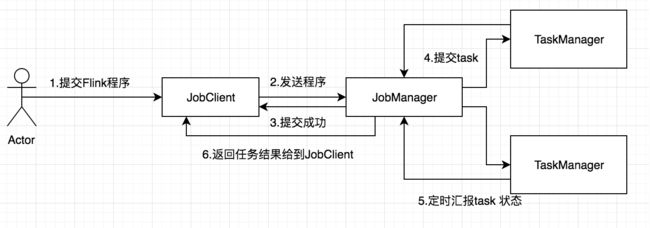
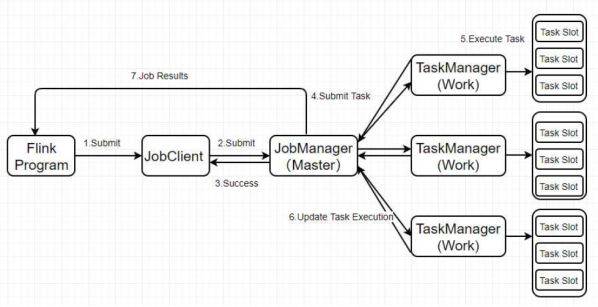
用户首先提交Flink程序到JobClient,经过JobClient的处理、解析、优化提交到JobManager,最后由TaskManager运行task。
(1)Standalone版本
(2)On Yarn版本实现原理
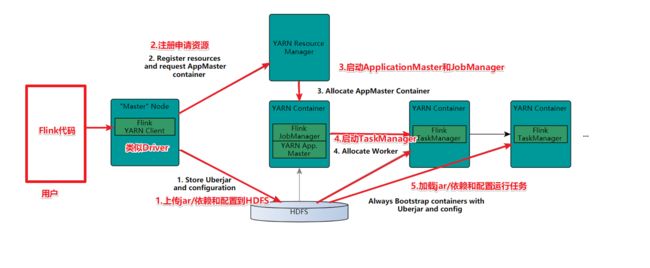
1. Client向HDFS上传Flink的Jar包和配置
2. Client向Yarn ResourceManager提交任务并申请资源
3. ResourceManager分配Container资源并启动ApplicationMaster,
然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
4. ApplicationMaster向ResourceManager申请工作资源,
NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
5. TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
3、Flink Streaming Dataflow
-
官网关于Flink的词汇表(我使用google翻译为中文的) Apache Flink 1.11 Documentation: Glossary
(1)Dataflow、Operator、Partition、SubTask、Parallelism
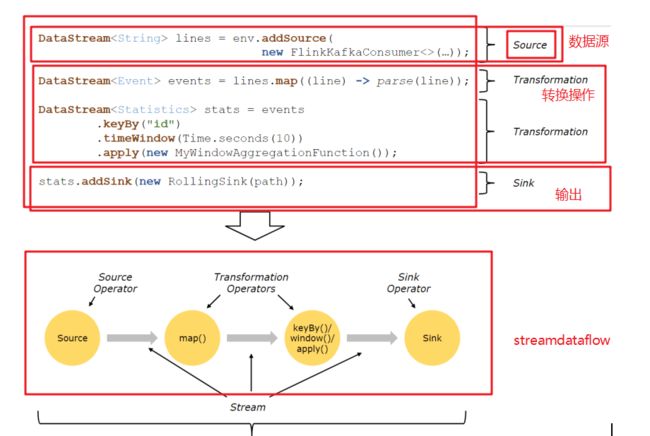
1. Dataflow:Flink程序在执行的时候会被映射成一个数据流模型
2. Operator:数据流模型中的每一个操作被称作Operator,Operator分为:Source/Transform/Sink
准备数据-Source
处理数据-Transformation
输出结果-Sink
3. Partition:数据流模型是分布式的和并行的,执行中会形成1~n个分区
4. Subtask:多个分区任务可以并行,每一个都是独立运行在一个线程中的,也就是一个Subtask子任务
5. Parallelism:并行度,就是可以同时真正执行的子任务数/分区数
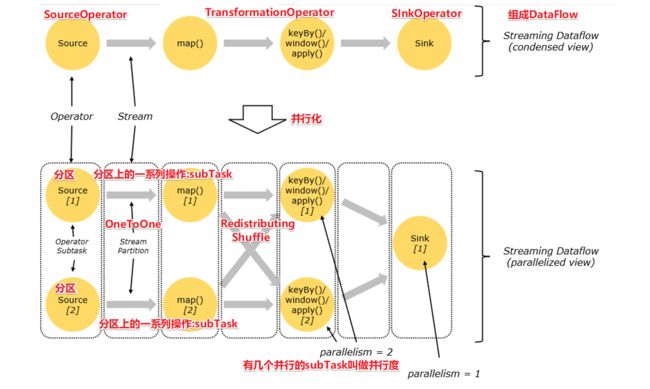
(2) Operator传递模式
数据在两个operator(算子)之间传递的时候有两种模式:
-
One to One模式:
两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性。--类似于Spark中的窄依赖
-
Redistributing 模式:
这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区。--类似于Spark中的宽依赖
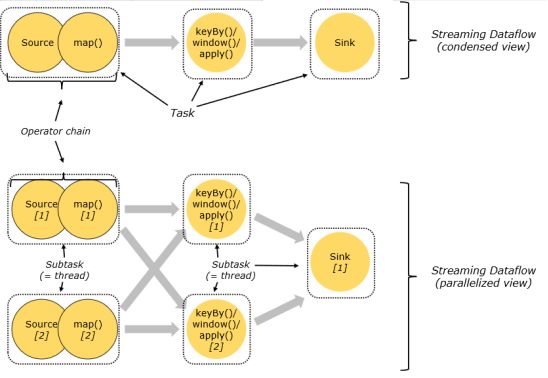
(3)Operator Chain(算子链)
客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行--就是SubTask。
(4)TaskSlot(任务槽) And Slot Sharing(槽共享)
-
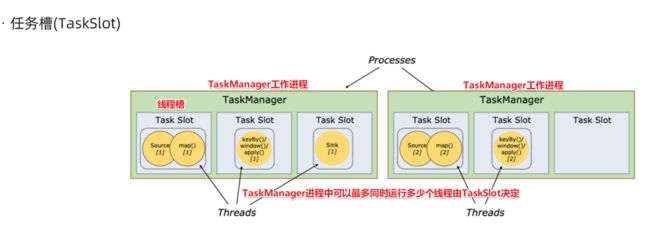
任务槽(TaskSlot)
每个TaskManager是一个JVM的进程, 为了控制一个TaskManager(worker)能接收多少个task,Flink通过Task Slot来进行控制。TaskSlot数量是用来限制一个TaskManager工作进程中可以同时运行多少个工作线程,TaskSlot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 TaskSlot 就意味着能支持多少并发的Task处理。
Flink将进程的内存进行了划分到多个slot中,内存被划分到不同的slot之后可以获得如下好处:
1. TaskManager最多能同时并发执行的子任务数是可以通过TaskSolt数量来控制的
2. TaskSolt有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。
-
槽共享(Slot Sharing)
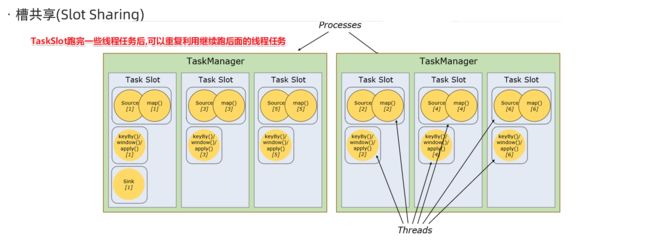
Flink允许子任务共享插槽,即使它们是不同任务(阶段)的子任务(subTask),只要它们来自同一个作业。比如图左下角中的map和keyBy和sink 在一个 TaskSlot 里执行以达到资源共享的目的。
允许插槽共享有两个主要好处:
1. 资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它。
2. 有了任务槽共享,可以提高资源的利用率。
-
注意:
slot是静态的概念,是指taskmanager具有的并发执行能力
parallelism(平行)是动态的概念,是指程序运行时实际使用的并发能力
(5)运行时组件
Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:
-
作业资源管理器(JobManager): 分配任务、调度checkpoint做快照
-
任务管理器(TaskManager):主要干活的
-
资源管理器(ResourceManager):管理分配资源
-
分发器(Dispatcher):方便递交任务的接口,WebUI
因为Flink是用Java和Scala实现的,所以所有组件都会运行在Java虚拟机上。每个组件的职责如下:
-
作业管理器(JobManager)
1. 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。
2. JobManager 会先接收到要执行的应用程序,这个应用程序会包括:
作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
3. JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),
包含了所有可以并发执行的任务。
4. JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,
也就是任务管理器(TaskManager)上的插槽(slot)。
一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
-
任务管理器(TaskManager)
1. Flink中的工作进程。通常在Flink中会有多个TaskManager运行,
每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
2. 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,
TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
3. 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
-
资源管理器(ResourceManager)
1. 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元。
2. Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。
3. 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。
如果ResourceManager没有足够的插槽来满足JobManager的请求,
它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
-
分发器(Dispatcher)
1. 可以跨作业运行,它为应用提交提供了REST接口。
2. 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
3. Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
4. Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
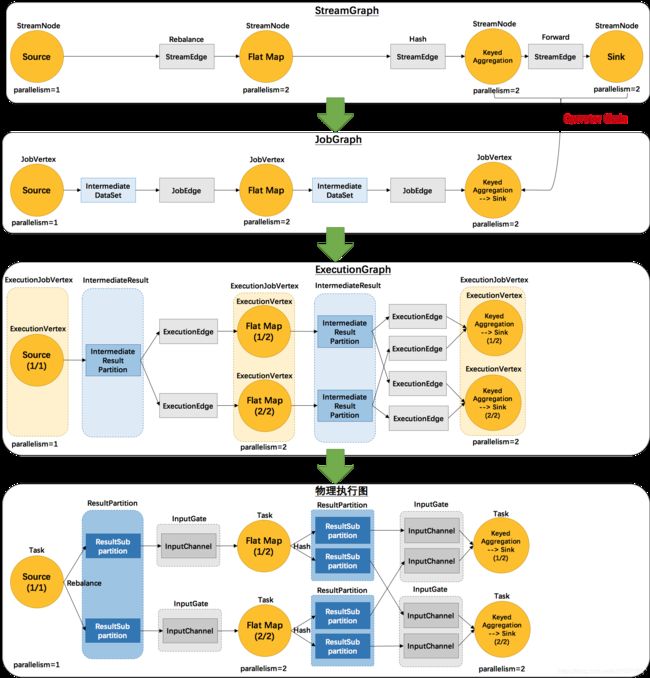
(6)Flink执行图(ExecutionGraph)
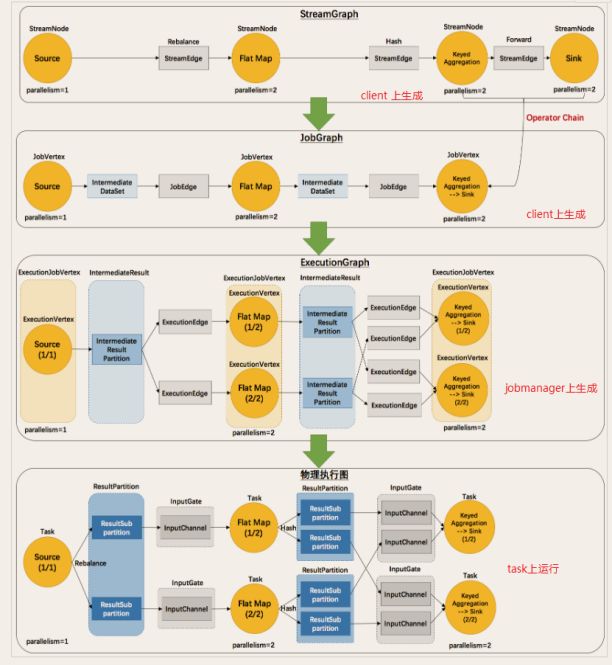
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
Flink 中的执行图可以分成四层:StreamGraph(逻辑流图) -> JobGraph -> ExecutionGraph -> 物理执行图。
1. StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑 [tuò pū] 结构。
2. JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
3. ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。方便调度和监控和跟踪各个 tasks 的状态。
ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
4. 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,
在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
-
Flink执行executor会自动根据程序代码生成DAG数据流图
-
简单理解:
1. StreamGraph:最初的程序执行逻辑流程,也就是算子之间的前后顺序--在Client上生成
2. JobGraph:将OneToOne的Operator合并为OperatorChain--在Client上生成
3. ExecutionGraph:将JobGraph根据代码中设置的并行度和请求的资源进行并行化规划!--在JobManager上生成
4. 物理执行图:将ExecutionGraph的并行计划,落实到具体的TaskManager上,将具体的SubTask落实到具体的TaskSlot内进行运行。