C语言进阶之文件操作(案例实现:通讯录数据的持久化)
前言
实现静态版本和动态版本的通讯录都会有同一个问题,那就是数据在程序结束后便会消失,重新开启通讯录,数据又得重新输入,所以这篇博客就给大家分享一下有关C语言文件操作的知识点,大家可以通过对文件进行操作,实现数据持久化。
目录
1.文件概念及分类
2.文件打开和关闭
3.文件的读写
(1)顺序读写
(2)随机读写
4.文本文件和二进制文件的介绍
5.文件知识拓展
(1)文件读取结束判定
(2)文件缓冲区
1.文件概念及分类
文件一般是存放在磁盘上的。在程序设计中,从文件功能的角度来说,它分为两种:程序文件和数据文件。
程序文件一般为源程序文件(.c后缀),目标文件(windows环境后缀为.obj),可执行程序(windows环境后缀.exe)。
数据文件其内容不一定为程序,而是在程序运行时需要读写的数据。如我运行某个程序时从某个文件读取数据或输出内容到该文件,则称该文件为数据文件。这里我们主要分享的也是关于对数据文件的操作。
相信大家都用过scanf和printf函数,它们都是以终端为对象进行数据的输入输出。但是我们这里是从磁盘上的文件进行数据的输入输出。这时候一般就需要文件名(又称文件标识)来标识唯一文件,文件名一般由文件路径+文件名主干+文件后缀三部分,如c:\CTest\data.txt
2.文件打开和关闭
在介绍文件打开和关闭之前,先跟大家介绍一下一个重要知识点,那就是文件类型指针,即文件指针。FILE是描述某一个文件的结构体变量(对应一个文件信息区,文件信息区中存放有关该文件的一些基本信息,如文件名称,文件状态,文件当前位置等等,系统会自动创建并填充信息),而FILE*则是指向某一个文件结构体变量的指针。对它大家不用太过于深究,只需要知道通过它可以找到与它关联的文件就好了。我们可以这样创建FILE*的指针变量:
//文件指针变量
FILE* pf,pf1,pf2;
就跟我们通过整型指针找整型变量一样的逻辑。
对于数据文件操作来说,我们应该先打开它才能对它进行数据的输入输出,并在使用它之后关闭它,防止数据泄露。就像我们从瓶子里取水装水一样,都要先打开瓶盖再进行取水装水,之后拧紧瓶盖,防止水撒的到处都是。而一般我们使用fopen函数来打开文件,使用fclose来关闭文件。它们的使用需要包含stdio.h头文件。
fopen函数入参及返回值如下:

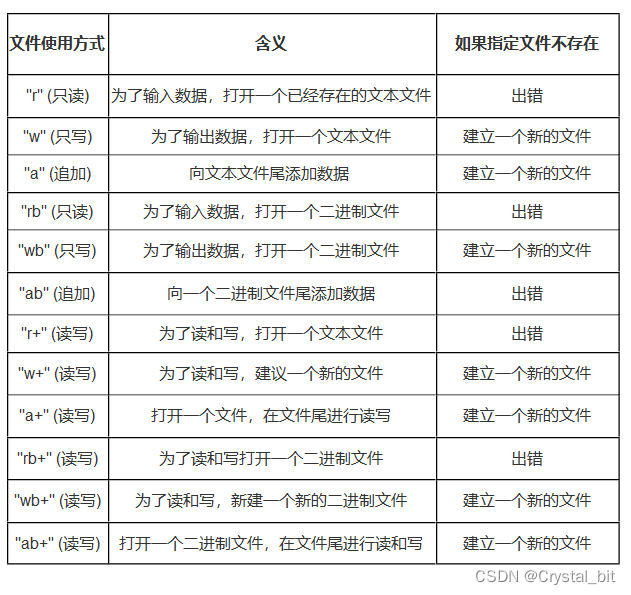
第一个参数为所需打开文件的文件名称,第二个参数为文件使用的方式。具体方式如下:
fclose函数入参及返回值如下:

其参数就是一个所需关闭的文件指针。
通过一个案例帮助大家理解:
//文件打开案例,记得包含stdio.h头文件哦
int main() {
//fopen函数以写的方式打开对应文件名文件并返回一个文件指针
//第一个也可以是绝对路径(具体的文件路径)
//我们这里采用相对路径,文件将会创建在我们该项目的路径底下
FILE* pF = fopen("data.txt", "w");
//因为pF不一定百分百开辟成功,所以可能返回空指针
//为了防止对空指针解引用,我们这里对pF判断一下
if (NULL == pF) {
return -1;
}
//因为我们还没学怎么读写文件所以这里我们不对data.txt文件进行读写操作
//但是我们以写的方式打开文件的话,会默认创建新的文件
fclose(pF);
return 0;
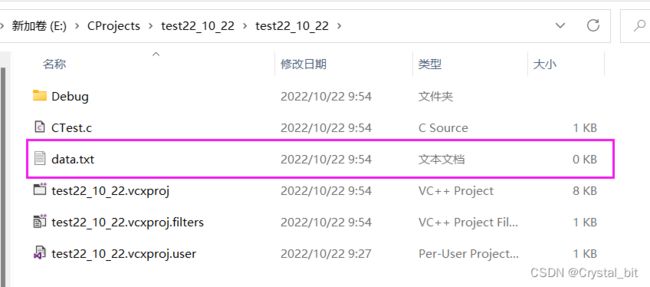
}打开CTest.c的路径,此时我们已经创建了空的data.txt文件,这样就可以通过文件读写函数去对该文件进行读写操作啦
3.文件的读写
(1)顺序读写
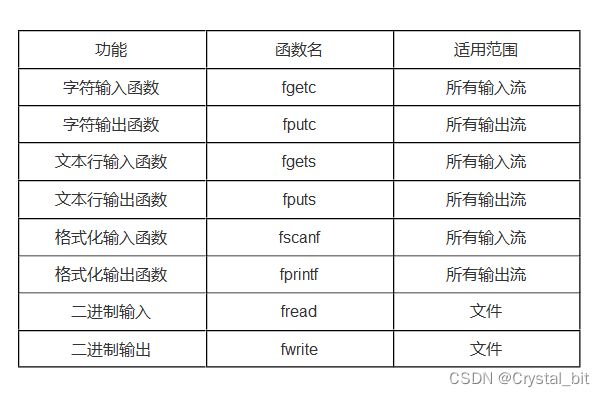
顺序读写函数操作如下:
int(成功返回读入的字符,失败则返回EOF-1) fgetc(FILE* 指向标识输入流的FILE对象的指针)
int(成功返回所需写出的字符ASCII码值,失败则返回EOF-1) fputc(int 所需写出的字符,FILE* 指向标识输出流的FILE对象的指针)
字符输入输出案例:
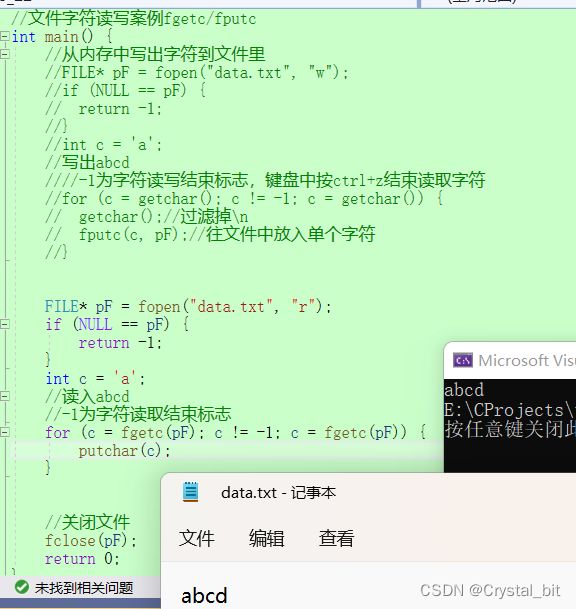
//字符读写案例fgetc/fputc
int main() {
//从内存中写出字符到文件里
//FILE* pF = fopen("data.txt", "w");
//if (NULL == pF) {
// return -1;
//}
//int c = 'a';
//写出abcd
-1为字符读写结束标志,键盘中按ctrl+z结束读取字符
//for (c = getchar(); c != -1; c = getchar()) {
// getchar();//过滤掉\n
// fputc(c, pF);//往文件中放入单个字符
//}
FILE* pF = fopen("data.txt", "r");
if (NULL == pF) {
return -1;
}
int c = 'a';
//读入abcd
//-1为字符读取结束标志
for (c = fgetc(pF); c != -1; c = fgetc(pF)) {
putchar(c);
}
//关闭文件
fclose(pF);
return 0;
}此时data.txt文件中内容如下:
char*(成功返回读取字符串的首元素地址,失败返回NULL) fgets(char* 要读入值的字符数组的指针,int 要复制到字符数组中的最大字符数,FILE* FILE对象的指针,从中读取数据的输入流)
int(成功返回非负值,失败则返回EOF-1) fputs(const char* 写出的字符串首元素指针,FILE* 指向标识输出流的FILE对象的指针)
注:1.换行符使fgets函数停止读取,但是它被函数视为有效字符,并包含在复制到 str 的字符串中。
2.fputs函数从指定的地址(str)开始复制,直到达到终止空字符 ('\0')
文本行输入输出案例:
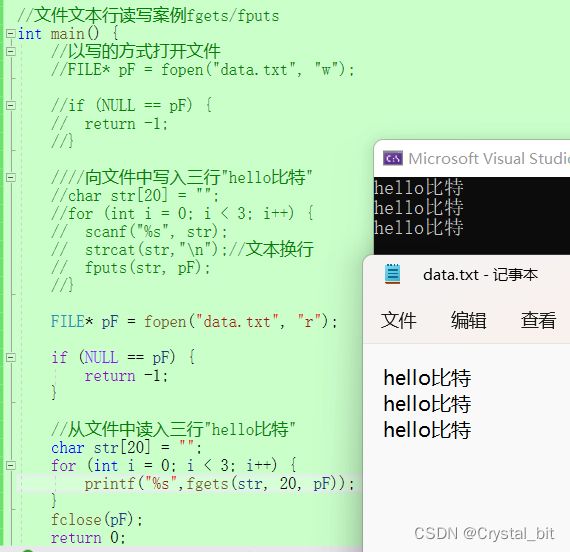
//文本行读写案例fgets/fputs
int main() {
//以写的方式打开文件
//FILE* pF = fopen("data.txt", "w");
//if (NULL == pF) {
// return -1;
//}
向文件中写入三行"hello比特"
//char str[20] = "";
//for (int i = 0; i < 3; i++) {
// scanf("%s", str);
// strcat(str,"\n");//文本换行
// fputs(str, pF);
//}
FILE* pF = fopen("data.txt", "r");
if (NULL == pF) {
return -1;
}
//从文件中读入三行"hello比特"
char str[20] = "";
for (int i = 0; i < 3; i++) {
printf("%s",fgets(str, 20, pF));
}
fclose(pF);
return 0;
}
int fprintf(FILE* 指向输出流的FILE对象的指针,const char* format 要写入流的一系列字符的C字符串 .....)
int fscanf(FILE* FILE对象的指针,从中读取数据的输入流,const char* format 要读取的一系列字符的C字符串....)
格式化输入输出函数案例:
//格式化读写案例fscanf/fprintf
typedef struct Person {
char name[20];
int age;
float height;
}Person;
int main() {
//往文件中写入格式化数据
//Person p = { "zhangsan张三",21,60.5 };
//FILE* pF = fopen("data.txt", "w");
//if (NULL == pF) {
// return -1;
//}
//fprintf(pF, "%s %d %f", p.name, p.age, p.height);
//从文件中读取格式化数据
Person p = { 0 };
FILE* pF = fopen("data.txt", "r");
if (NULL == pF) {
return -1;
}
fscanf(pF, "%s %d %f", p.name, &(p.age), &(p.height));
printf("%s %d %f", p.name, p.age, p.height);
fclose(pF);
return 0;
}
经过了几个输入输出函数的分享,目前文件中的数据不管是中文还是英文大家都是能用肉眼看出来的,但是接下来这个输入输出函数就是以二进制的方式输入和输出数据,所以就代表我们不能用肉眼看懂计算机能识别的二进制数据。
size_t (返回成功读取的元素总数,如果此数字与元素数不一样,则表示读取时发生读取错误或达到文件末尾) fread(void* 指向大小至少为(大小*计数)字节的内存块的指针,转换为void*,size_t 要读取的每个元素的大小(单位为字节且为无符号整型),size_t 元素数,指向指定输入流的FILE对象的指针)
fwrite的入参与fread类似不同的是最后一个参数为指向指定输出流的FILE对象的指针,且若返回的元素总数与计数不同的话,则写入错误会阻止函数完成
二进制输入输出案例:
//文件二进制读写案例fread/fwrite
typedef struct Person {
char name[20];
int age;
float height;
}Person;
int main() {
//以二进制写方式打开文件
//Person p = { "zhangsan张三",21,60.5f };
//FILE* pF = fopen("data.txt", "wb");
//if (NULL == pF) {
// return -1;
//}
//fwrite(&p, sizeof(p),1, pF);
Person p = { 0 };
FILE* pF = fopen("data.txt", "rb");
if (NULL == pF) {
return -1;
}
fread(&p, sizeof(p), 1, pF);
printf("%s %d %f", p.name, p.age, p.height);
fclose(pF);
return 0;
}
学到这里,相信我们已经了解了很多关于输入输出的函数了,但是还有一组输入输出sscanf和sprintf,大家可能觉得和scanf/printf,fscanf/fprintf很相似,我们先看看它们的入参及返回值:

第一个参数是作为源字符串,按照一定格式将其中数据存储到给定的位置中
第二个参数是格式字符串的C字符串,与scanf的格式相同的规范
第三个参数是格式字符串所需的一系列附加参数
成功后返回参数列表中成功填充的项数,如果在成功解释任何数据之前输入失败,则返回EOF。

第一个参数是指向存储生成的C字符串的缓冲区的指针,足够大能包含生成的字符串
第二个参数是包含格式字符串的C字符串,与printf中的格式相同的规范
第三个参数是格式字符串所需的一系列附加参数
成功后返回 参数列表中成功填充的项数。失败则返回EOF。
字符串格式化读写案例:
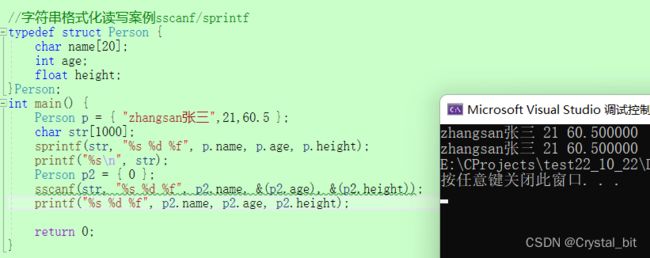
//字符串格式化读写案例sscanf/sprintf
typedef struct Person {
char name[20];
int age;
float height;
}Person;
int main() {
Person p = { "zhangsan张三",21,60.5 };
char str[1000];
//将格式化数据按一定规则输出到字符串中
sprintf(str, "%s %d %f", p.name, p.age, p.height);
printf("%s\n", str);
Person p2 = { 0 };
//从字符串中按一定规则读取数据到结构体中
sscanf(str, "%s %d %f", p2.name, &(p2.age), &(p2.height));
printf("%s %d %f", p2.name, p2.age, p2.height);
return 0;
}
(2)随机读写
fseek函数根据文件指针的位置和偏移量来定位文件指针。

第一个参数是指向标识流的FILE对象的指针
第二个参数对于二进制文件来说是从原点偏移的字节数,对于文本文件来说,是零或者ftell返回的值。
第三个参数是用作偏移参考的位置,有三类:

如果成功返回0,否则返回非零值。
fseek案例:
//随机读写之fseek函数案例
int main() {
//往文件中以二进制方式写入abcde文本行
//FILE* pF = fopen("data.txt", "wb");
//if (NULL == pF) {
// return -1;
//}
//char str[20] = "abcde";
//fputs(str, pF);
//案例
FILE* pF = fopen("data.txt", "rb");
if (NULL == pF) {
return -1;
}
//因为没有学到ftell所以这里我们先讲二进制文件的随机读写
//根据当前读写位置偏移2个字节
char str[20] = "";
//读取一个字符,此时当前位置不再是文件开始位置,而是文件开始的后一个位置
fgetc(pF);
fseek(pF, 2, SEEK_CUR);
fgets(str,20, pF);
printf("seek_cur:%s\n", str);
//从文件开始位置偏移2个字节
fseek(pF, 2, SEEK_SET);
fgets(str, 20, pF);
printf("seek_set:%s\n", str);
//从文件末尾向前偏移4个字节
fseek(pF, -4, SEEK_END);
fgets(str, 20, pF);
printf("seek_end:%s", str);
fclose(pF);
return 0;
}
ftell函数可以返回文件指针相对于起始位置的偏移量

参数为指向标识流的FILE对象的指针
成功返回位置指示器的当前值
失败则返回-1L,并将errno设置为系统特定的正值
ftell结合fseek案例:
//随机读写之ftell与fseek结合案例
int main() {
//往文件中写入hello比特 文本行
//FILE* pF = fopen("data.txt", "w");
//if (NULL == pF) {
// return -1;
//}
中文占两个字节
//char str[20] = "hello比特";
//fputs(str, pF);
//案例
FILE* pF = fopen("data.txt", "r");
if (NULL == pF) {
return -1;
}
//对于以文本模式打开的流,偏移量应为零或上一次调用 ftell 返回的值,并且原点必须SEEK_SET。
char str[20] = "";
//读取一个字符,此时当前位置不再是文件开始位置,而是文件开始的后一个位置
fgetc(pF);
fgetc(pF);
fseek(pF, ftell(pF), SEEK_SET);
fgets(str, 20, pF);
printf("seek_set->ftell:%s\n", str);
fseek(pF, 0, SEEK_SET);
fgets(str, 20, pF);
printf("seek_set->0:%s\n", str);
fclose(pF);
return 0;
}
rewind函数让文件指针回到文件的起始位置

参数为指向标识流的FILE对象的指针 无返回值
rewind案例:
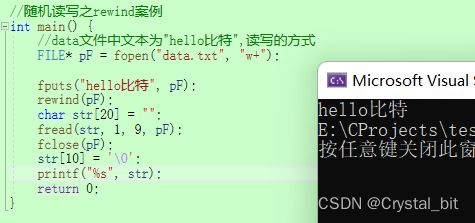
//随机读写之rewind案例
int main() {
//data文件中文本为"hello比特",读写的方式
FILE* pF = fopen("data.txt", "w+");
fputs("hello比特", pF);
rewind(pF);
char str[20] = "";
fread(str, 1, 9, pF);
fclose(pF);
str[10] = '\0';
printf("%s", str);
return 0;
}
注:这里忘记给pF判断NULL了,大家不要学我
4.文本文件和二进制文件的介绍
根据数据的组织形式,数据文件被分为文本文件(以ASCII字符的形式存储)或
二进制(在内存中以二进制的形式存储)文件。
存储10000示例:
复制data.txt文件到CTest路径下
右击源文件->选择打开方式为二进制形式:

文本文件:
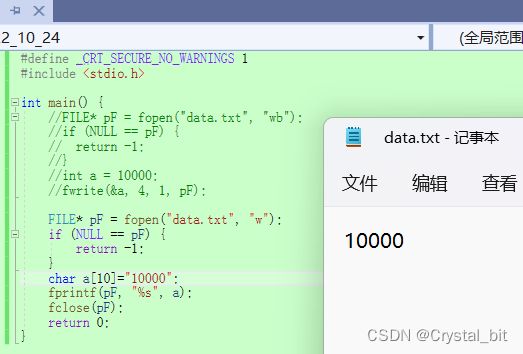
整数10000,如果以ASCII码形式输出到磁盘,则磁盘中占用5个字节(每个字符占一个字节)
而如果以二进制输出,则在磁盘上只占4个字节。
如图:

示例代码:
int main() {
//二进制存储十六进制显示
//FILE* pF = fopen("data.txt", "wb");
//if (NULL == pF) {
// return -1;
//}
//int a = 10000;
//fwrite(&a, 4, 1, pF);
//ASCII码形式
FILE* pF = fopen("data.txt", "w");
if (NULL == pF) {
return -1;
}
char a[10]="10000";
fprintf(pF, "%s", a);
fclose(pF);
return 0;
}5.文件知识拓展
(1)文件读取结束判定
feof函数使用的误区:文件读取时,是不能通过feof函数的返回值直接判断文件是否结束
feof函数的作用为当文件读取结束的时候,判断是I/O读取失败结束还是遇到文件尾结束
注:1.文本文件读取是否结束,判断返回值是否为EOF(fgetc),或者NULL(fgets)
2.二进制文件的读取结束判断,判断返回值是否小于实际要读的个数(fread)。
正常使用feof函数关于文本文件的示例:
//正常使用feof函数关于文本文件的示例
int main() {
//c为-1的时候,文件访问结束
int c;
FILE* pF = fopen("data.txt", "r");
if (NULL == pF) {
return -1;
}
while ((c = fgetc(pF)) != EOF) {// I/O读取文件循环
putchar(c);
}
printf("\n");
if (ferror(pF))
puts("I/O error when reading");
else if (feof(pF))
puts("END of file reached successfully");
fclose(pF);
return 0;
}
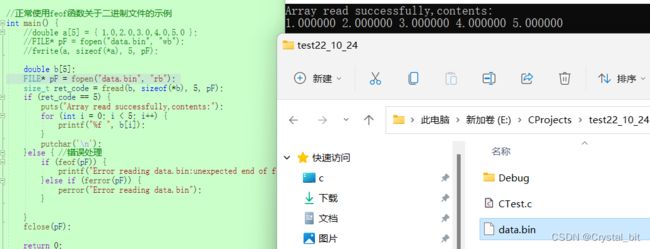
正常使用feof函数关于二进制文件的示例:
//正常使用feof函数关于二进制文件的示例
int main() {
//double a[5] = { 1.0,2.0,3.0,4.0,5.0 };
//FILE* pF = fopen("data.bin", "wb");
//fwrite(a, sizeof(*a), 5, pF);
double b[5];
FILE* pF = fopen("data.bin", "rb");
size_t ret_code = fread(b, sizeof(*b), 5, pF);
if (ret_code == 5) {
puts("Array read successfully,contents:");
for (int i = 0; i < 5; i++) {
printf("%f ", b[i]);
}
putchar('\n');
}else { //错误处理
if (feof(pF)) {
printf("Error reading data.bin:unexpected end of file\n");
}else if (ferror(pF)) {
perror("Error reading data.bin");
}
}
fclose(pF);
return 0;
}
(2)文件缓冲区
与其单讲概念,我的目的是让大家更好理解。如图:
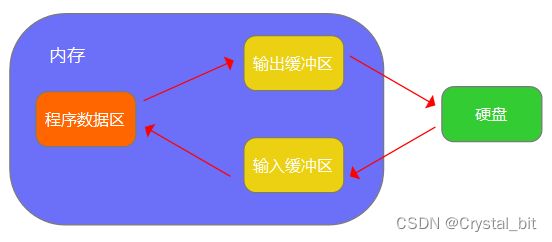
ANSIC标准中采用"缓冲文件系统"处理数据文件。该系统会自动在内存中为程序中每一个正在使用的文件开辟一块"文件缓冲区"。当我们从内存输出数据给硬盘时,不会直接输到硬盘,而是先到内存中的缓冲区,等待缓冲区满了之后再到磁盘。读取的话也是先到内存中的输入缓冲区(装满)中,然后再从输入缓冲区逐个将数据送到程序数据区。而缓冲区的大小根据C编译系统决定的。
注:因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或在文件操作结束的时候关闭文件。如果不做则可能导致读写文件的问题!
本篇关于文件操作知识点学习的博客分享完毕,断断续续花了近五天,终于写完了呜呜呜呜!(有学习就会有收获哦!!!大家冲冲冲!!!)
大家可以在学习完之后去试试实现文件版本的通讯录。不懂的可以评论区问我。
我的码云链接:10月14日C语言之实现通讯录的文件存储 · fd39316 · Crystal/C_Practice - Gitee.com