股票查询与分析系统(Qt 5.9.8)
逍股(ShareGo)——股票查询与分析系统
- 一、实现方法
-
- 1. 功能模块图
- 2. 模块说明
-
- (1)数据结构的定义
- (2)核心函数的定义
- 3. 页面流程图
- 二、实验结果
-
- 1. 查询功能:
-
- 1.1 基于哈希表的股票基本信息查询
- 1.2.1 基于二叉排序树的股票基本信息查询
- 1.2.2 基于二叉排序树的股票基本信息删除
- 1.3 基于KMP的股票网址查询
- 1.4 基于单链表的股票价格信息查询
- 2. 分析功能:
-
- 2.1.1 基于直接插入排序的股票价格分析
- 2.1.2 基于快速排序的股票价格分析
- 2.1.3 基于简单选择排序的股票价格分析
- 2.2 基于Floyd的股票相关性计算
- 2.3.1 基于Prim最小生成树的股票基金筛选
- 2.3.2 基于Kruskal最小生成树的股票基金筛选
- 2.4 基于二部图的股票基金筛选
- 三、尚存在的问题
- 四、结论分析
-
- 1. 知识方面
- 2. 能力方面
- 3. 素养方面
一、实现方法
1. 功能模块图
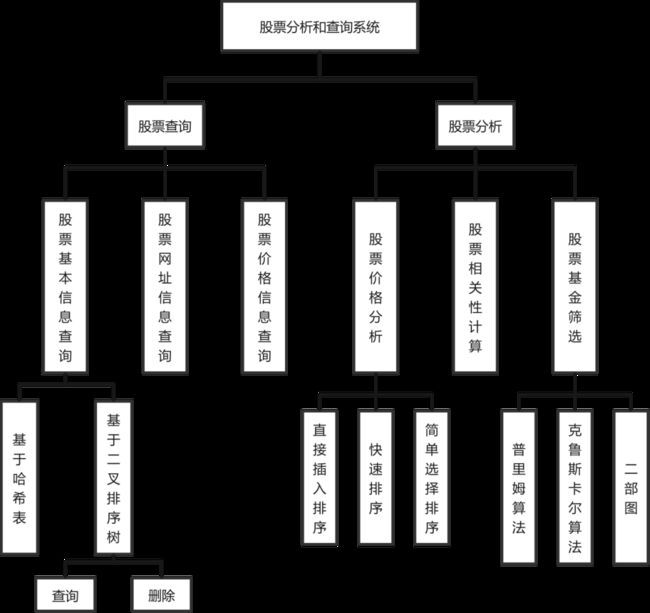
2. 模块说明
(1)数据结构的定义
① 每支股票的详细信息:
//每支股票的详细信息
typedef struct Detail{
QString date; //日期
double openPrice; //开盘价
double closePrice; //收盘价
double maxPrice; //最高价
double minPrice; //最低价
double volume; //成交量
int turnover; //成交额(万元)
QString rate; //换手率%
double iodAmount; //涨跌额
QString iodRate; //涨跌幅%
}Detail;
② 一支股票的信息:
//一支股票的信息
typedef struct Stock{
QString stockCode; //股票代码
QString name; //股票简称
QString tradeCode; //行业编码
QString firstTrade; //一级门类
QString secondTrade; //二级门类
QString place; //上市交易所
QString coName; //公司全称
QString launchDate; //上市日期
QString province; //省份
QString city; //城市
QString person; //法人
QString address; //地址
QString web; //网址
QString email; //邮箱
QString phone; //电话
QString business; //主营业务
QString area; //经营范围
Detail *details; //详细信息
int length; //详细信息长
}Stock;
③ 哈希表的定义:
// 哈希表
typedef struct Hash{
Stock stock;
struct Hash *next;
}Hash, *HashTable;
④ 二叉排序树的定义:
//二叉排序树
typedef struct BSTNode{
Stock st; //每个结点的数据域包括关键字项和其他数据项
struct BSTNode *lchild, *rchild;//左右孩子指针
}BSTNode, *BSTree;
⑤ 链表的定义:
typedef struct ElemType{
Stock st; //股票信息
int index; //股票详细信息的下标
}ElemType;
typedef struct LNode{
ElemType data; //数据域
struct LNode *next; //指针域
}LNode, *LinkList; //LinkList为指向结构体LNode的指针类型
⑥ 60支筛选的股票:
//筛选的股票
typedef struct SelectedStock{
int node; //点
QString name; //股票名称
QString stockCode; //股票代码
double score; //评分
}SelectedStock;
⑦ 筛选的股票与边组成的图:
//股票之间的边
typedef struct Edge{
int node1; //点1
int node2; //点2
int val; //边权
}Edge;
//筛选的股票与边组成的图
typedef SelectedStock VerTexType; //顶点的数据类型为股票
typedef int ArcType; //边的权值类型为整型
typedef struct
{
VerTexType vexs[MVNum]; //顶点表
ArcType arcs[MVNum][MVNum]; //邻接矩阵
int vexnum, arcnum; //图的当前点数和边数
}AMGraph;
//存储边的信息
struct Edg{
VerTexType head; //边的始点
VerTexType tail; //边的终点
ArcType lowcost; //边上的权值
};
(2)核心函数的定义
1.1 基于哈希表的股票基本信息查询:
void Inquire(); //查询功能
void CreateHashTable(HashTable *hash, Stock *st, double &ASL); //创建哈希表
bool SearchTable(HashTable *hash, QString code, Stock &s); //查找哈希表
1.2.1 基于二叉排序树的股票基本信息查询:
void Inquire(); //查询功能
int GetTotalWeight(BSTree T, int w); //计算所有点的查找长度之和
1.2.2 基于二叉排序树的股票基本信息删除:
void Delete(); //删除结点操作
void DeleteBST(BSTree &T, QString key); //从二叉排序树T中删除关键字等于key的结点
1.3 基于KMP的股票网址查询:
void Inquire(); //查询功能
bool KMP(QString S, QString T, int *next); //判断是否匹配
void GetNext(QString T, int *next); //计算next函数
1.4 基于单链表的股票价格信息查询:
void Inquire(); //查询功能
void CreateList(LinkList &L, Stock *s, QString dateInquire); //排序功能
void PrintList(LinkList L); //将链表信息写入文本框中
2.1.1 基于直接插入排序的股票价格分析:
void Sort(); //排序功能
void Export(); //导出功能
bool cmp(LNode *pre, LNode *p, int mode, int order); //排序方式
void InsertSort(LinkList &L, int mode, int order); //直接插入排序
2.1.2 基于快速排序的股票价格分析:
void Sort(); //排序操作
int Partition(SqList &L, int low, int high); //对子表[low, high]进行排序,返回枢轴位置
void QSort(SqList &L, int low, int high); //递归实现快速排序
2.1.3 基于简单选择排序的股票价格分析:
void Sort(); //排序功能
void Export(); //导出操作
void SelectSort(DetailStock *ds, int mode); //简单选择排序
2.2 基于Floyd的股票相关性计算:
void Analyse(); //分析功能
//用Floyd算法求无向图G中各对顶点i和j之间的最短路径
void ShortestPath_Floyd(AMGraph G, ArcType (*D)[MVNum], int (*path)[MVNum]);
2.3.1 基于Prim最小生成树的股票基金筛选:
void Analyse(); //分析功能
void CreateShortestDisG(AMGraph &shortestDisG, AMGraph G); //构建最短距离图
void MiniSpanTree_Prim(AMGraph G, VerTexType u); //无向图G以邻接矩阵形式存储,从顶点u出发构造G的最小生成树T,输出T的各条边
bool cmp(Edg e1, Edg e2); //比较方式
bool IsInsertable(SelectedStock *cntS, int cnt, SelectedStock s); //判断当前股票s是否与数组有重复
void Sort(Edg *e, int n); //对边进行排序
2.3.2 基于Kruskal最小生成树的股票基金筛选:
void Analyse(); //分析功能
void CreateShortestDisG(AMGraph &shortestDisG, AMGraph G); //构建最短距离图
bool cmp(Edg e1, Edg e2); //比较方式
bool IsInsertable(SelectedStock *cntS, int cnt, SelectedStock s); //判断当前股票s是否与数组有重复
void MiniSpanTree_Kruskal(AMGraph G); //无向图G以邻接矩阵形式存储,构造G的最小生成树T,输出T的各条边
void InitEdg(Edg *e, AMGraph G); //初始化辅助边
2.4 基于二部图的股票基金筛选:
void Analyse(); //分析功能
bool CreateSubGraph(AMGraph G, AMGraph& SubG, int* id, QSpinBox **nodeBox);//创建子图
bool DFS(AMGraph G, int v, int c, int *color); //给点染色
3. 页面流程图
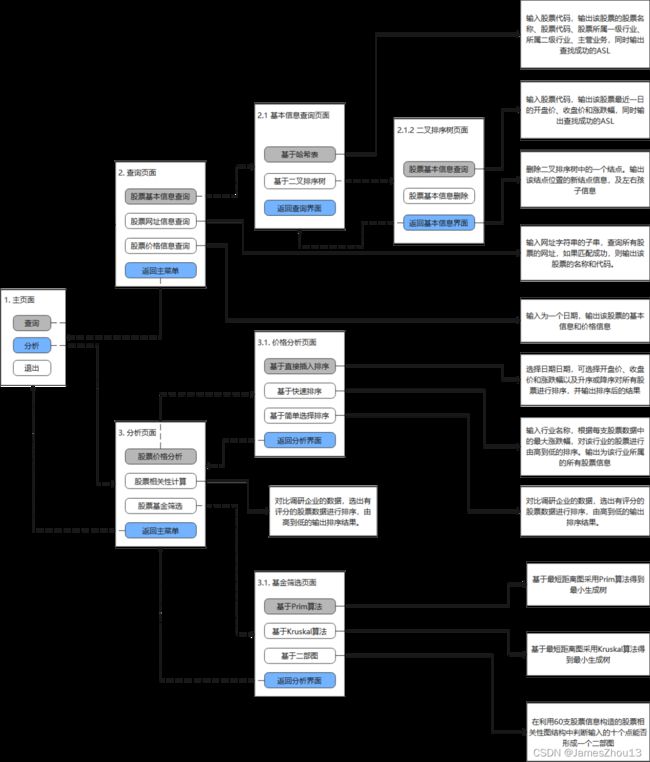
二、实验结果
1. 查询功能:
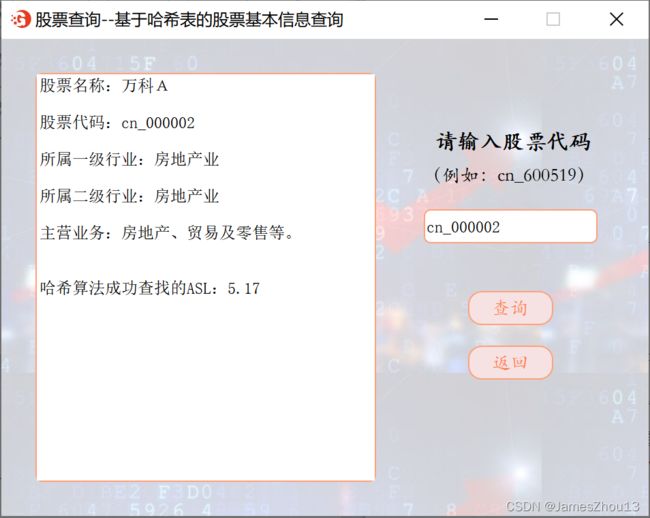
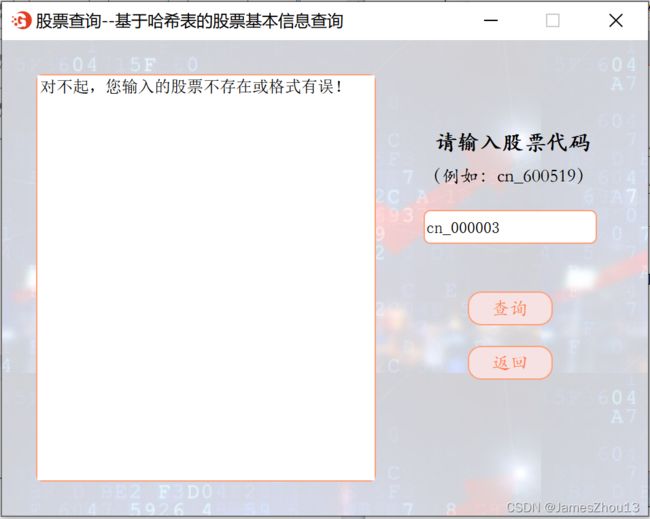
1.1 基于哈希表的股票基本信息查询
输入的“股票代码”。点击“查询”按钮,若该股票存在,则显示该股票的“股票名称”、“股票代码”、“股票所属一级行业”、“所属二级行业”、“主营业务”,同时输出查找成功的ASL(如图2.1.1);若所查询的股票不存在,则显示错误提示(如图2.1.2)。
1.2.1 基于二叉排序树的股票基本信息查询
输入“股票代码”。点击“查询”按钮,若该股票存在,则显示该股票最近一日的“开盘价”、“收盘价”和“涨跌幅”,同时输出查找成功的ASL(如图2.2.1);若所查询的股票不存在,则显示错误提示(如图2.2.2)。

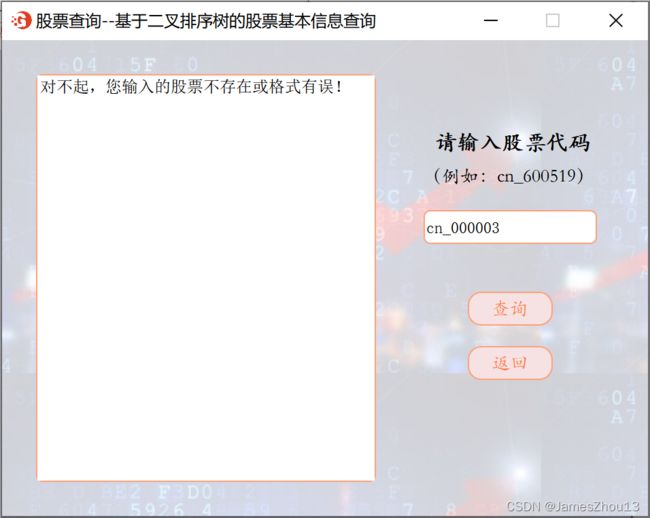
1.2.2 基于二叉排序树的股票基本信息删除
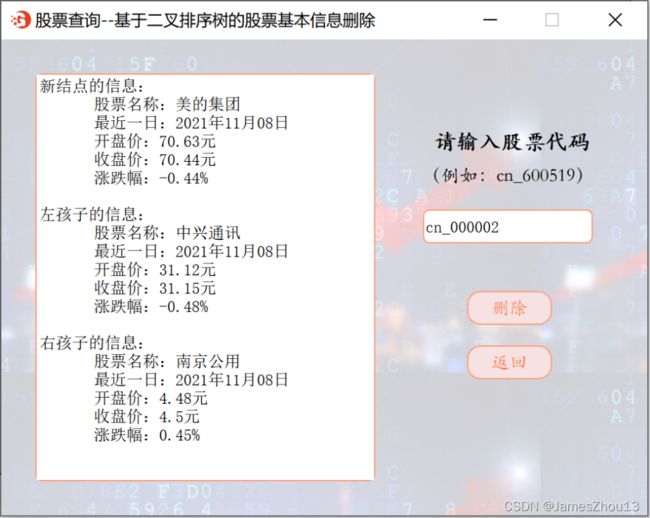
输入“股票代码”。点击“查询”按钮,若该股票存在,则删除二叉排序树中的一个结点,显示该结点位置的新结点信息及左右孩子信息。(如图2.3.1);若所查询的股票不存在,则显示错误提示(如图2.3.2)。
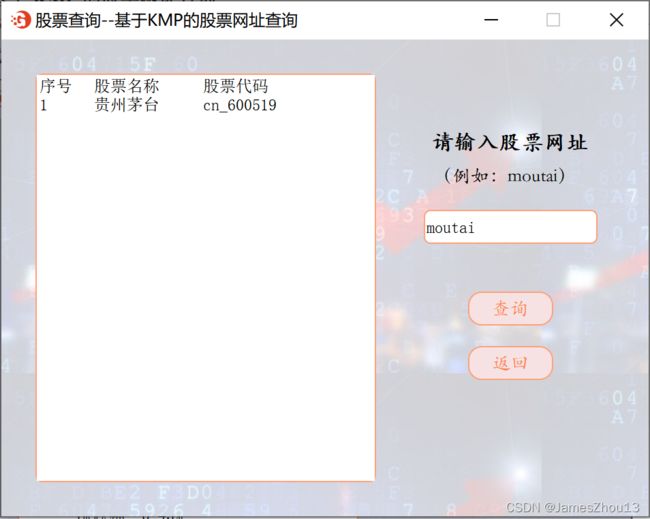
1.3 基于KMP的股票网址查询
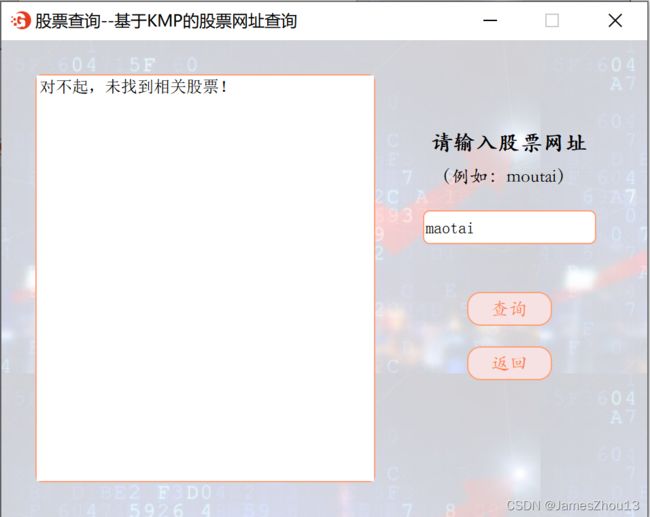
输入网址字符串的子串,点击“查询”按钮,查询所有股票的“网址”字段。如果匹配成功,则显示所有股票的名称和代码。(如图2.4.1);否则显示错误提示(如图2.4.2)。
1.4 基于单链表的股票价格信息查询
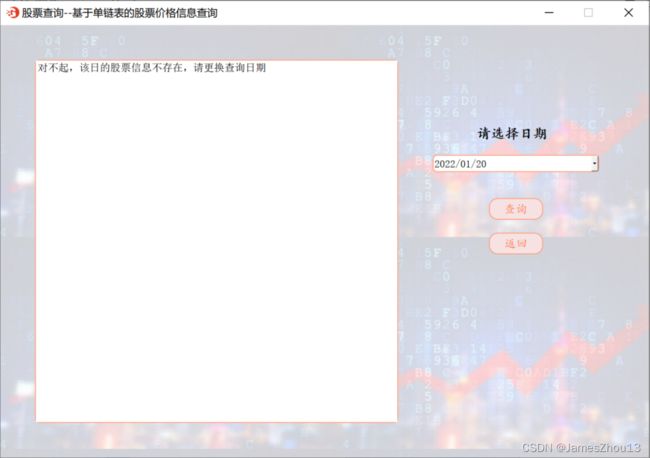
选择一个日期。点击“查询”按钮,若该日有股票信息,则显示该日所有股票的基本信息和价格信息(如图2.5.1);否则则显示错误提示(如图2.5.2)。

2. 分析功能:
2.1.1 基于直接插入排序的股票价格分析
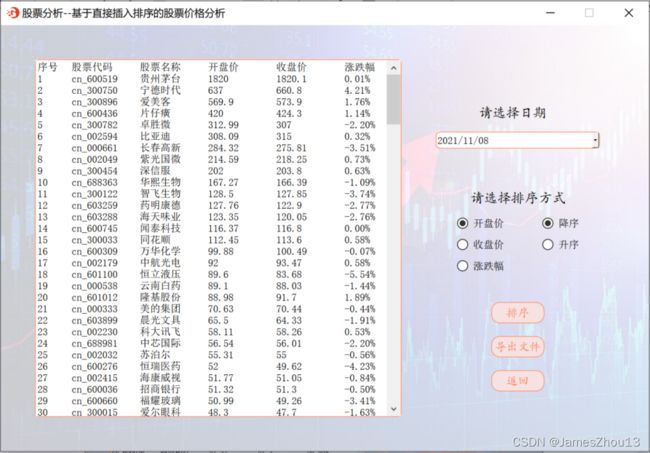
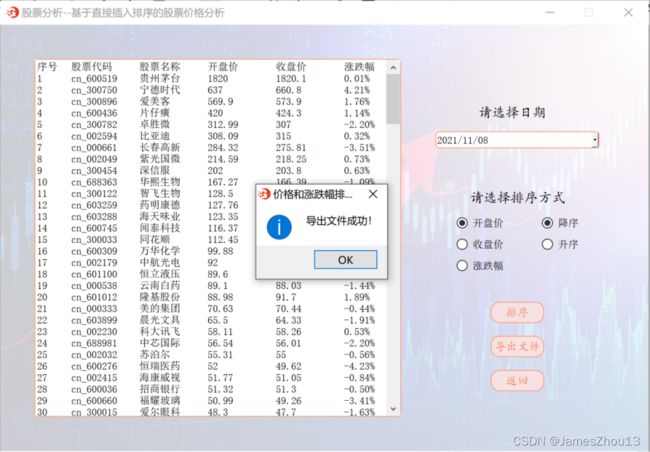
选择日期和根据“开盘价”、“收盘价”和“涨跌幅”对所有股票进行升序或降序排序。点击“排序”按钮,若该日有股票信息,并显示排序后的结果。每支股票信息占一行,每行包括“序号”、“股票代码”、“股票名称”、“开盘价”、“收盘价”、“涨跌幅”(如图2.6.1);否则显示错误提示(如图2.6.2)。点击“导出文件”按钮,可将排序后的结果按照存储在文件名为“价格和涨跌幅排序结果.csv”的文件中,并弹出提示信息“文件导出成功”(如图2.6.3)。

2.1.2 基于快速排序的股票价格分析
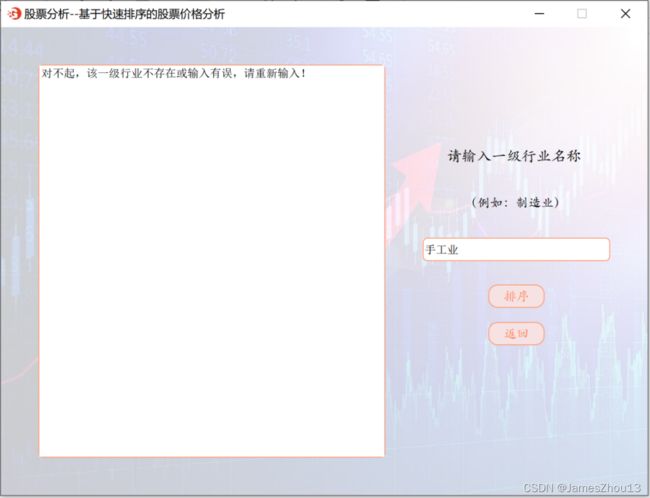
输入“一级行业名称”。点击“排序”按钮,根据每支股票数据中的最大涨跌幅,对同一行业内的股票进行由高到低的排序。若该日有股票信息,并显示排序后的结果。每支股票信息占一行,每行包括“序号”、“股票代码”、“股票名称”、“涨跌幅”、“日期”(如图2.7.1);若不存在输入的一级行业,则显示错误提示(如图2.7.2)。

2.1.3 基于简单选择排序的股票价格分析
选择根据“评分”和“收盘价”对所有股票进行降序排序。点击“排序”按钮,并显示排序后的结果。每支股票信息占一行,每行包括“序号”、“股票代码”、“股票名称”、“收盘价”(如图2.8.1)。点击“导出文件”按钮,可将排序后的结果按照输出的格式存储在文件名为“评分排序结果.csv”和“收盘价排序.csv”的文件中,并弹出提示信息“文件导出成功”。

2.2 基于Floyd的股票相关性计算
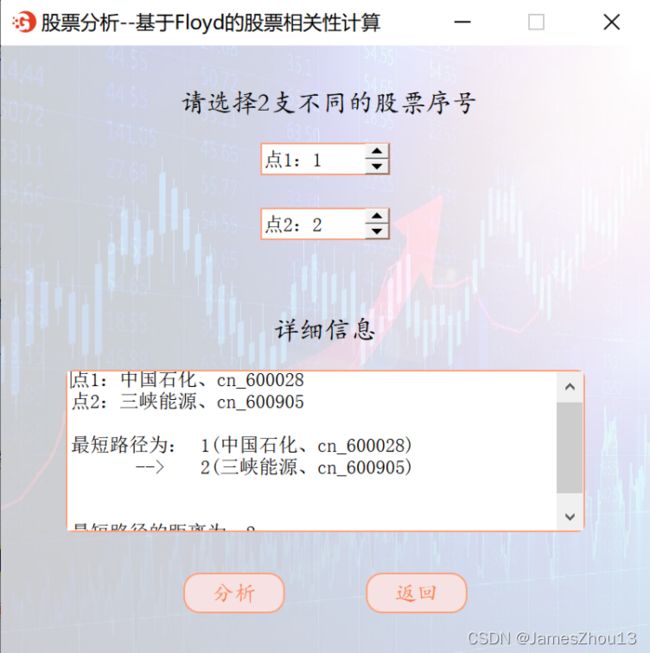
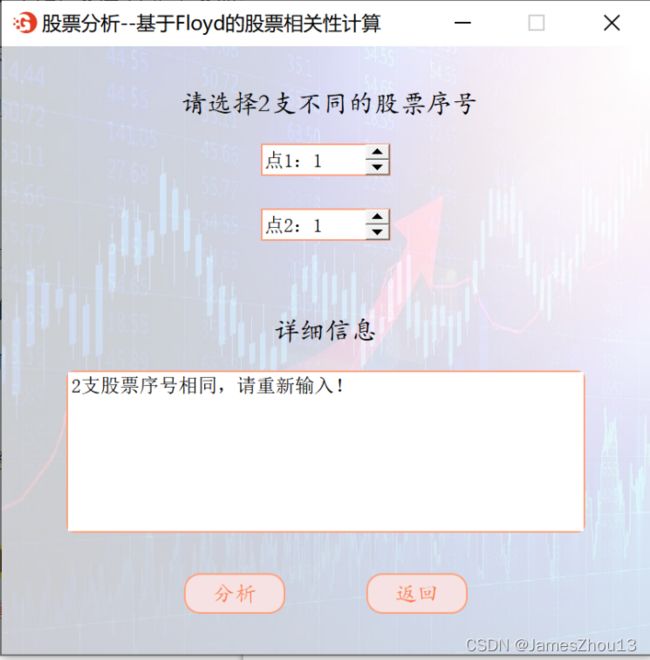
选择两个不同的股票编号,点击“分析”按钮。若编号不同,计算这两支股票的相关性,可以计算任意两支股票之间的最短距离。采用Floyd算法。输出任意两点间的最短路径(如图2.9.1);否则输出编号相同的错误提示信息(如图2.9.2)。
2.3.1 基于Prim最小生成树的股票基金筛选
点击“分析”按钮,利用60支股票的最短距离图,该图的任意两点之间都有边,边的权值为两点的最短距离。基于该图采用Prim算法得到最小生成树,然后挑选出该最小生成树中边权值最小的若干条边,获得6个结点,每行输出一条边,包含“边的权值”、“边的结点1:股票名称”、“边的结点2:股票名称”。(如图2.10.1)

2.3.2 基于Kruskal最小生成树的股票基金筛选
点击“分析”按钮,利用60支股票的最短距离图,该图的任意两点之间都有边,边的权值为两点的最短距离。基于该图采用Kruskal算法得到最小生成树,然后挑选出该最小生成树中边权值最小的若干条边,获得6个结点,每行输出一条边,包含“边的权值”、“边的结点1:股票名称”、“边的结点2:股票名称”。(如图2.10.2)

2.4 基于二部图的股票基金筛选
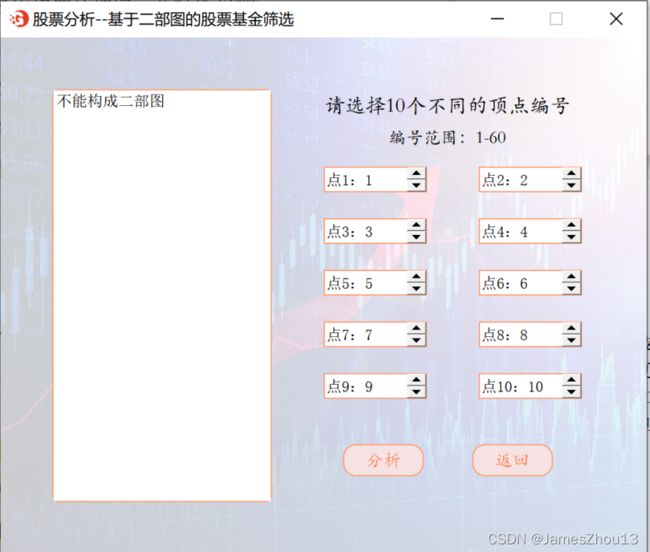
利用二部图的判别原理,在利用“60支股票信息”构造的股票相关性图结构中判断输入的十个点能否形成一个二部图。选择十个不重复的数字(数字范围为[1,60]),代表60支股票的序号,点击“分析”按钮。若10个点中有重复,则输出提示信息(如图2.11.1);否则,若能构成二部图,则给出该二部图(如图2.11.2);若不能构成二部图,则输出提示信息(如图2.11.3)。


三、尚存在的问题
- 由于时间所限,该系统目前点击按钮全部依托于鼠标,现在目前的按钮交互方式为鼠标点击按钮方可触发,尚未实现直接使用键盘便可触发按钮的点击,用户体验感较差,后续有时间将进行系统优化。
- 由于水平有限,该系统的数据全部是基于csv文件的读写操作,未使用数据库对数据进行加密而可能会导致数据泄露等问题的出现,将会在后续相关课程的学习中对本系统进行更新升级。
四、结论分析
1. 知识方面
-
二叉排序树和散列表
二叉排序树:平均查找长度和树的形态有关。当先后插入的关键字有序时,构成的二叉排序树蜕变为单支树。树的深度为 n n n ,其平均查找长度为 n + 1 2 \frac{n+1}{2} 2n+1 (和顺序查找相同),这是最差的情况。显然,最好的情况是,二叉排序树的形态和折半查找的判定树相似,其平均查找长度和 l o g 2 n log_{2}{n} log2n 成正比。就平均而言,二叉排序树的平均查找长度仍然和 l o g 2 n log_{2}{n} log2n 是同数量级的。
散列表:本次课设用到散列表处理冲突的方法为链地址法。把具有相同散列地址的记录放在同一个单链表中,称为同义词链表。有m个散列地址就有 m m m 个单链表,同时用数组 H T [ 0 … m − 1 ] HT[0…m−1] HT[0…m−1] 存放各个链表的头指针,凡是散列地址为i的记录都以结点方式插入到以 H T [ i ] HT[i] HT[i] 为头结点的单链表中,该方法的查找成功的平均长度的数量级接近1。
虽然散列表的ASL比二叉排序树来的更为高效,但是散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 $ O(n) $ 的时间复杂度内,输出有序的数据序列。 -
快速排序:
我之前深受 ACM 的影响,每次排序时直接使用 C++ 已经封装好的 s o r t sort sort 函数进行排序,而不是认认真真地将快速排序自己进行封装,因此对快速排序的理解不是很深入。通过查阅数据结构教材和深入分析,巩固和加深了快速排序的相关知识点,明白了快排的内部思想——在待排序的 n n n 个记录中任取一个记录(通常取第一个记录)作为枢轴,设其关键字为 p i v o t k e y pivotkey pivotkey 。经过一趟排序把所有关键字小于 p i v o t k e y pivotkey pivotkey 的记录交换到前面、大于 p i v o t k e y pivotkey pivotkey 的交换到后面,结果将待排序记录分成两个子表,最后将枢轴放置在分界处的位置。然后,分别对左、右子表重复上述过程,直至每一子表只有一个记录时,排序完成。 -
二部图:
在构建二部图时,由于不清楚二部图在数据结构中的具体实现方法,对染色法这种判断一个图是否为二部图方法也未尝涉猎,通过查阅应答网站StackOverflow、论坛等网络资源和深入分析,巩固和加深了图的遍历这一知识点,最终决定用深度优先搜索 D F S DFS DFS 来实现染色法遍历图。
2. 能力方面
主通过本次课设,提升了我的算法实现能力、算法分析能力、代码调试能力、解决复杂工程问题的能力和创新能力等等。
- 算法实现能力
平常更多接触到算法知识的便是做ACM相关的算法题目,而这么多算法一齐组成一个系统还是第一次去尝试,当将算法融入股票查询与分析系统时,便更加考验算法实现的能力。每次完成一个功能时便会很有成就感,同时,也使得我的算法实现能力得到飞速提升。 - 算法分析能力
本次课设,一个系统却包含了几乎这学期《数据结构》课上的所有重点算法,还有额外的二部图相关的算法。在该系统进行编写的过程中,让我的算法分析能力得到了提升。 - 代码调试能力
本次课设,我觉得调试代码的时间要远超编写代码的时间,有时一个功能写完后发现运行结果与自己预期不一致,毫不夸张的将,明明写只需一个小时,但调试却要花上几个小时。但是,当自己调试发现错误所在之处时,内心会无比的激动。同时,调试代码的过程中,也让我能力得到进一步的提升。 - 解决复杂工程问题的能力
对于这种大项目工程,一定要有整体的规划和布局,不能“随心所欲”的编程,要有大局观念,应当先分模块,绘制功能模块图,然后设计相关的数据结构以及相关的操作定义,接着是页面的流程图,最终编程实现每个功能。 - 创新能力
本次实验,在底层使用数据结构和算法之外,为了让系统更加具有实用性和发挥其价值,我使用了Qt这一开发的跨平台 C++ 图形用户界面应用程序开发框架,其良好封装机制使得其模块化程度非常高,可重用性较好,对于用户开发来说是非常方便的;为了更有系统的感觉和方便其商业利用,我自己设计了系统的 logo ——逍股(ShareGo);为了让系统更加美观,我使用Photoshop为系统绘制了背景以及使用“Web前端开发”这门课学过的CSS语言设计了按钮的样式和窗口的样式……诸如此类的设计让我觉得自己不只是在完成一门课程设计,而是真正在做一个系统、一个项目,这也让我更有动力,同时也提升了我的创造能力。
3. 素养方面
通过本次课设,提升了我全面看待问题、整体布局、职业道德规范等综合素养。
- 看待问题方面
通过之前对企业的调研,全面分析企业的基本面信息并对企业进行评分,从而我懂得了看待一个问题,要求我们看问题既要全面,又要善于分清主流和支流;此外,应该认清事物是变化发展的,要用发展的观点看问题,一支股票,不能因为其过去一直不景气或是未来趋势有所下降就一味的否定,也不可因为其过去一路飙升或是未来前途光明就一味的认同,而是要根据其过去、现在、未来综合考量,很多问题也一样,要用发展的眼光去看待。 - 整体布局方面
通过设计并实现课设的复杂系统,谈谈处理问题时应该如何进行全局统筹规划,具有大局意识。例如,对于本次课程设计——股票查询与分析系统这种大项目工程,一定要有整体的规划和布局,不能“随心所欲”的编程,要有大局观念,应当先分模块,绘制功能模块图,然后设计相关的数据结构以及相关的操作定义,接着是页面的流程图,最终编程实现每个功能。同样,面对人生许多问题也是如此,应该先整体统筹规划,分解成若干小问题,再逐一击破,方臻意境。 - 职业道德规范方面
通过阅读和学习《软件工程师职业道德规范和标准》,我认识到作为软件工程师在软件开发中应该遵守的职业道德规范。我觉得我们应该有高度的责任心和强烈的使命感、有自觉的规范化和标准化意识、有强烈的相互协作的团队精神、有良好的和同事沟通的能力、正确对待客户需求,认真弄懂客户需求,不任意解释客户需求、有自觉的保密意识和产权意识、通过实践养成良好的文档习惯、通过学习和总结而引发出创新精神和创新能力、服从上级主管分配的任务和安排、具有软件工程的概念。计算机世界是一个日新月异的世界。我们作为后备力量,应该在自己的整个学习过程和职业生涯中,不仅要不断更新和完善自己的专业知识,而且还要不断提升自己的道德情操和职业操守的水平以及管理能力。