AI实践之路:线性/逻辑回归背后的广义线性模型与最大似然估计
写上一篇文章的过程中,讲到逻辑回归是如何利用Sigmoid函数将线性回归的数值转换为概率时,才意识到自己对逻辑回归的理解十分浅显,为什么是Sigmoid函数?它一个![]() 就说是概率了?数学原理是什么?为了增加理解,尝试整理了所查资料的知识点,文中会放上不同信息的参考来源。
就说是概率了?数学原理是什么?为了增加理解,尝试整理了所查资料的知识点,文中会放上不同信息的参考来源。
1.广义线性模型 Generalized linear model
首先需要知道广义线性模型,即GLM,说实话没学过啥统计学这那的课,看到很多数学术语、专业刻板的描述、数学公式简直读到头大,尝试按自己目前理解的去描述,如果有错误还希望指正。
广义线性模型是线性回归模型的推广。数学家们发明了线性回归这一方法用来解决现实中的问题,比如预测房价啦等等,但是这个模型显然是受很多假设限制的,它只能用来预测数值,无法进行分类;它假设随机误差服从0均值的正态分布;回归模型对参数来说是纯线性的...具体可以参照这篇文章:经典线性回归模型十大假定。
可以看到,想使用传统线性回归模型(y=wx+b)的条件是较为严苛的,面对现实情况各种更复杂的问题,很多传统假设不再适用,但其中依然隐含线性关系可以让我们解决,那么就推广出了更具代表性的,更广义的线性模型。
----------------------------------------------------------
经过抽象,广义线性模型由三个部分组成,具体参考了这篇文章:广义线性模型(GLM)概述
1.随机部分:我们拥有N个数量的真实值y,如掌握了N个房子的房价,这N个y是彼此相互独立的,同时每个y都是受同一组参数控制的,比如计算房价的过程中我们只要用到一组w来左右不同信息对结果的影响,也就是不同的信息乘上这组w 产生了不同的y。
2.系统部分:这部分建立了输入的数据(如房价预测中房子的面积、楼层、是否学区房这些特征信息)与初步预测值(也叫线性预报)  之间的关系,即
之间的关系,即 ![]() ,如果是经典线性回归,那这就直接是我们的预测值了,但是对于GLM来说,它需要应对更多的情况,举个例子,若实际房价模型是
,如果是经典线性回归,那这就直接是我们的预测值了,但是对于GLM来说,它需要应对更多的情况,举个例子,若实际房价模型是 ![]() ,线性求出的结果取掉ln才是真实值,所以GLM没有把话说满,留一步用来应对更多情况。
,线性求出的结果取掉ln才是真实值,所以GLM没有把话说满,留一步用来应对更多情况。
3.连接函数或者联系函数:其定义是,如果该函数的反函数能够将线性方程映射到某个广义线性模型的期望,则该函数为联系函数。我们获得的真实值y抛开误差、噪声后,认为y的期望是 ![]() ,这个
,这个  作为我们期望的真实值,刚才系统部分已经说明了我们拥有了线性预报 ,GLM认为挡在线性预报和期望真实值之间的函数(如系统部分例子中举的ln函数)就是我们的联系函数,记为
作为我们期望的真实值,刚才系统部分已经说明了我们拥有了线性预报 ,GLM认为挡在线性预报和期望真实值之间的函数(如系统部分例子中举的ln函数)就是我们的联系函数,记为 ![]() ,所以
,所以 ![]() 。所以上面的例子我们实际需要找的广义线性模型是
。所以上面的例子我们实际需要找的广义线性模型是 ![]() 。
。
以上就是(我)关于广义线性模型的通俗理解。
----------------------------------------------------------
那么如果将上面的联系函数换成sigmoid函数呢?这里参考了一篇文章,写的真的很好:面试题解答:为什么逻辑斯蒂回归的输出值可以作为概率
终于回到正题,逻辑回归实际也是广义线性模型,其联系函数的反函数就是sigmoid函数
![]() ,联系函数:
,联系函数:![]()
这一联系函数将线性函数映射到了伯努利分布的期望上,这使其输出可以作为概率,所以这也是为什么它可以做二元分类,因为伯努利分布就是二元分布。
整理思路,重新想一下sigmoid函数是哪来的,为啥当时上来就说它套上线性回归就是概率了?因为伯努利分布的中 ![]() 。
。
目前一切都明朗了,统计学家们为了处理二元分类的问题,他们把线性模型映射到伯努利分布上来进行二分类,所以采用了sigmoid函数,将它的反函数作为联系函数(有点绕)构造了这个广义线性模型中的一员:逻辑回归模型。
那么,到底是符合什么样的特征的模型才能被称作广义线性模型呢?在广义线性模型的定义中,要求原模型符合指数分布即可,这些模型的集合我们称之为指数分布族(exponential family),伯努利分布,就是指数分布族中的一个特例。所以也还有其他分布来帮助我们处理不同的任务,此处参考:指数分布族与广义线性模型
- 多项式分布(multinomial),用来对多元分类问题进行建模;
- 泊松分布(Poisson),用来对计数过程进行建模,如网站的访客数量、商店的顾客数量等;
- 伽马分布(gamma)和指数分布(exponential),用来对时间间隔进行建模,如等车时间等;
- β分布(beta)和Dirichlet分布(Dirichlet),用于概率分布;
- Wishart分布(Wishart),用于协方差矩阵分布。
- ...
那么softmax原理与二元分类异曲同工,它能进行多元分类是因为模型将线性函数映射到了多项式分布,计算多种类别的概率以进行分类。
2.最大似然估计 Maximum likelihood estimate
最大似然估计也就是人们常说的MLE,线性回归和逻辑回归模型都使用了MLE的思想来进行优化。
什么是似然likelihood,它是统计学的概念,提到统计学我们自然想到概率,其实似然与概率同样可以表示事件发生的可能性大小,但是二者有着很大的区别。概率possibility是已知事件参数的情况下,推算结果发生的可能性,概率越大,事件越可能发生,比如我们有一个袋子,里面一个黑球一个白球,那么我们通过已有的这个知识来推断出我们拿出白球的概率是0.5。那么似然likelihood呢,则是不知道参数,通过实验的结果来推测真实的参数,似然越大,当前推测的参数越可能接近真实的参数,还是一个袋子,我们不知道里面什么样,每次拿出一个球记录,通过很多很多次实验发现黑球白球出现的次数是相同的,我们推测袋子里黑球白球的数量相等。
用公式可以更加直接,若 ![]() ,说明观测到x,
,说明观测到x,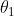 更接近真实的参数。
更接近真实的参数。
既然找到的参数越接近真实参数,似然就越大,那么当似然最大的时候,我们有理由认为我们找到了我们能找到的最好的参数,这就是最大似然估计。
求最值是我们最熟悉的环节,求导求梯度呗,让导数为0的值就是极值/最值,如果函数足够简单,极值便是最值,如果函数比较复杂,那就要了解自适应学习率来帮助我们了。
----------------------------------------------------------
那么回归标题,线性回归逻辑回归都用到了最大似然估计,重新回想我们想要解决的那些问题,我们观测到了房子的占地面积,房龄,希望找到那组能够预测房价的参数,逻辑回归中,我们拥有莺尾花的种种属性,什么花瓣大小之类的,我们想要找到那组参数帮我们判断花的种类,这都是最大似然估计的思想。再顺着回想我们的目标函数,逻辑回归那里十分清楚,我们计算的总概率其实就是已知x对参数的概率即似然的乘积,那么线性回归的目标函数呢?它看起来十分简单,就是直接算一个两数的平方差,它是如何使用最大似然估计的呢?
很多前辈已经写的十分详细了,懒得再打一行又一行的公式了。如果已经读了我的文章,直接看后半段即可:
最大似然估计:从概率角度理解线性回归的优化目标