TensorRT系列教程-ONNX基础
TensorRT系列教程-ONNX基础
文章目录
- TensorRT系列教程-ONNX基础
- 概述
- 一、TensorRT 模型
- 二、TensorRT C++ 接口模型构建
-
- 1.示例
- 备注:
- 2. TensorRT C++ 基本接口 模型推理
-
- 备注:
- 动态shape
-
- 备注:
- ONNX文件结构及其增删改
- 编译onnx-ml.proto文件
- ONNX 文件结构
-
- 改onnx文件
- 总结
概述
TensorRT 的核心在于对模型算子的优化(合并算子、利用当前 GPU 特性选择特定的核函数等多种策略),通过 TensorRT,能够在 Nvidia 系列 GPU 上获得最好的性能。
TensorRT 模型需要在目标 GPU 上以实际运行的方式选择最优的算法和配置(不同的 GPU 的许多特性的不一样,在特定 GPU 上跑一跑,再知道怎样最快)。
也因此 TensorRT 得到的模型只能在特定的环境下运行(编译时的 TensorRT 版本、CUDA 版本、GPU 型号等)。如果不是在完全相同的环境下运行 TensorRT 引擎来推理有时是直接无法运行的、有时是可以运行,但是并不能保证是最佳的,因此尽量不要这么做。
本节主要知识点
- TensorRT 模型定义的方式
- 编译过程配置
- 推理过程实现
- 插件实现
- onnx 理解
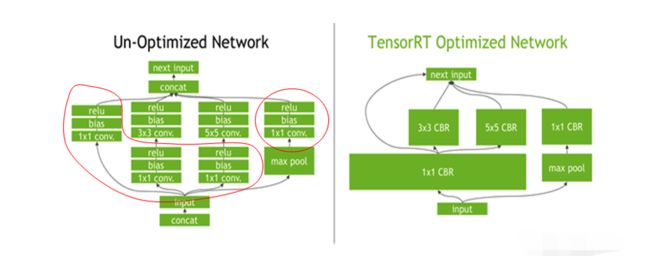
下图展示了 TensoRT 优化前后的模型,TensorRT 会找到一些可以合并、优化的算子,进行合并。
一、TensorRT 模型
- 最底层:TensorRT C++接口、Python 接口
- 常见的工作流:uff, onnx, caffe

- TensorRT,这是一个 github 上第三方的库,在官方接口的基础上封装了 ResNet 等常用的网络模型。
- 本课程的选择:PyTorch -> ONNX -> TensorRT
选择 ONNX 的一个好处是:ONNX 是一个通用的网络模型的中间格式,熟悉了 ONNX 格式之后,不仅是转到 TensorRT 引擎,如果后续有其他需要也可以方便地转换到其他推理引擎如 ncnn、mnn 等 - TensorRT 的一般需要包含的头文件是 NvInfer.h 和 NvInferRuntime.h,而 TensorRT 的库文件一览如下:

二、TensorRT C++ 接口模型构建
1.示例
代码如下(示例):下面的代码通过一个最简单的网络展示了 TensorRT C++ 一些基本接口来构建一个模型的过程。
// tensorRT include
#include 备注:
- 必须使用 createNetworkV2 ,并制定 1(表示显性 batch),createNetwork 已经废弃,非显性 batch 官方不推荐。这个直接影响到推理时是 enqueue 还是 enqueueV2
- builder、config 等指针,记得释放,使用 ptr->destroy(),否则会有内存泄漏
- markOutput 表示是该模型的输出节点,mark 几次,就有几个输出,addInput 几次,就有几个输入,这与推理时的输入输出相呼应
- workSpaceSize 是工作空间的大小,某些 layer 需要使用额外存储时,不会自己分配空间,而是为了内存复用,直接找 TensorRT 要 workspace 空间,指的是这个意思
- 一定要记住,保存的模型只能适应编译时的 TensorRT版本、CUDA 版本、GPU 型号等环境。也只能保证在完全相同的配置时是最优的。如果模型跨不同设备执行,有时也可以运行,但是不是最优的,也不推荐。
2. TensorRT C++ 基本接口 模型推理
代码如下(示例):下面的代码对上一小节构建的简单网络进行推理。
// tensorRT include
#include
#include
// cuda include
#include
// system include
#include
#include
#include
#include
#include
using namespace std;
// 上一节的代码
class TRTLogger : public nvinfer1::ILogger{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override{
if(severity <= Severity::kINFO){
printf("%d: %s\n", severity, msg);
}
}
} logger;
nvinfer1::Weights make_weights(float* ptr, int n){
nvinfer1::Weights w;
w.count = n;
w.type = nvinfer1::DataType::kFLOAT;
w.values = ptr;
return w;
}
bool build_model(){
// 这里的build_model函数即是做了和上面构建模型小节一样的事情,不再赘述
}
vector load_file(const string& file){
ifstream in(file, ios::in | ios::binary);
if (!in.is_open())
return {};
in.seekg(0, ios::end);
size_t length = in.tellg();
std::vector data;
if (length > 0){
in.seekg(0, ios::beg);
data.resize(length);
in.read((char*)&data[0], length);
}
in.close();
return data;
}
void inference(){
// ------------------------------ 1. 准备模型并加载 ----------------------------
TRTLogger logger;
auto engine_data = load_file("engine.trtmodel");
// 执行推理前,需要创建一个推理的runtime接口实例。与builer一样,runtime需要logger:
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 将模型从读取到engine_data中,则可以对其进行反序列化以获得engine
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());
if(engine == nullptr){
printf("Deserialize cuda engine failed.\n");
runtime->destroy();
return;
}
nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();
cudaStream_t stream = nullptr;
// 创建CUDA流,以确定这个batch的推理是独立的
cudaStreamCreate(&stream);
/*
Network definition:
image
|
linear (fully connected) input = 3, output = 2, bias = True w=[[1.0, 2.0, 0.5], [0.1, 0.2, 0.5]], b=[0.3, 0.8]
|
sigmoid
|
prob
*/
// ------------------------------ 2. 准备好要推理的数据并搬运到GPU ----------------------------
float input_data_host[] = {1, 2, 3};
float* input_data_device = nullptr;
float output_data_host[2];
float* output_data_device = nullptr;
cudaMalloc(&input_data_device, sizeof(input_data_host));
cudaMalloc(&output_data_device, sizeof(output_data_host));
cudaMemcpyAsync(input_data_device, input_data_host, sizeof(input_data_host), cudaMemcpyHostToDevice, stream);
// 用一个指针数组指定input和output在gpu中的指针。
float* bindings[] = {input_data_device, output_data_device};
// ------------------------------ 3. 推理并将结果搬运回CPU ----------------------------
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
printf("output_data_host = %f, %f\n", output_data_host[0], output_data_host[1]);
// ------------------------------ 4. 释放内存 ----------------------------
printf("Clean memory\n");
cudaStreamDestroy(stream);
execution_context->destroy();
engine->destroy();
runtime->destroy();
// ------------------------------ 5. 手动推理进行验证 ----------------------------
const int num_input = 3;
const int num_output = 2;
float layer1_weight_values[] = {1.0, 2.0, 0.5, 0.1, 0.2, 0.5};
float layer1_bias_values[] = {0.3, 0.8};
printf("手动验证计算结果:\n");
for(int io = 0; io < num_output; ++io){
float output_host = layer1_bias_values[io];
for(int ii = 0; ii < num_input; ++ii){
output_host += layer1_weight_values[io * num_input + ii] * input_data_host[ii];
}
// sigmoid
float prob = 1 / (1 + exp(-output_host));
printf("output_prob[%d] = %f\n", io, prob);
}
}
int main(){
if(!build_model()){
return -1;
}
inference();
return 0;
}
备注:
- bindings 是对 TensorRT 输入输出张量的描述,bindings = input_tensor + output_tensor,比如 input 有 a,output 有 b, c, d,那么 bindings = [a, b, c, d],可以就当成个数组:bindings[0] = a,bindings[2] = c。获取 bindings:engine->getBindingDimensions(0)
- enqueueV2 是异步推理,加入到 stream 队列等待执行,输入的 bindings 则是 tensor 指针(注意是 device pointer)。其 shape 对应于编译时指定的输入输出的 shape(目前演示的shape都是静态的)
- createExecutionContext 可以执行多次,允许一个引擎具有多个执行上下文,不过看看就好,别当真。
动态shape
动态 shape,即在构建模型时可以先不确定 shape,而是指定一个动态范围: [ L − H ] ,推理时再确定 shape,允许的范围即是: L < = s h a p e < = H
在构建时,主要是在这几行代码,指定 shape 的动态范围,其他与之前类似:
int maxBatchSize = 10;
printf("Workspace Size = %.2f MB\n", (1 << 28) / 1024.0f / 1024.0f);
// 配置暂存存储器,用于layer实现的临时存储,也用于保存中间激活值
config->setMaxWorkspaceSize(1 << 28);
// --------------------------------- 2.1 关于profile ----------------------------------
// 如果模型有多个输入,则必须多个profile
auto profile = builder->createOptimizationProfile();
// 配置最小允许1 x 1 x 3 x 3
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4(1, num_input, 3, 3));
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4(1, num_input, 3, 3));
// 配置最大允许10 x 1 x 5 x 5
// if networkDims.d[i] != -1, then minDims.d[i] == optDims.d[i] == maxDims.d[i] == networkDims.d[i]
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4(maxBatchSize, num_input, 5, 5));
config->addOptimizationProfile(profile);
在推理时,增加的是这些,来指定具体的 shape:
int ib = 2;
int iw = 3;
int ih = 3;
// 明确当前推理时,使用的数据输入大小
execution_context->setBindingDimensions(0, nvinfer1::Dims4(ib, 1, ih, iw));
备注:
- OptimizationProfile 是一个优化配置文件,用来指定输入的 shape 可以变化的动态范围
- 如果 ONNX 的某个维度是 -1,表示该维度是动态的,否则表示该维度是明确的,明确维度的 minDims, optDims, maxDims 一定是一样的。
ONNX文件结构及其增删改
- ONNX 的本质是一个 protobuf 文件
- protobuf 则通过 onnx-ml.proto 编译得到 onnx-ml.pb.h 和 onnx-ml.pb.cc 或 onnx_ml_pb2.py 。
- 然后用 onnx-ml.pb.cc 和代码来操作 ONNX 模型文件,实现增删改。
- onnx-ml.proto 则是描述 ONNX 文件是如何组成的,具有什么结构,他是操作 ONNX 经常参照的东西。 https://github.com/onnx/onnx/blob/main/onnx/onnx-ml.proto
- ONNX 模型一般是通过常用的模型训练框架(如 PyTorch 等)导出,当然也可以自己手动构建 ONNX 模型或节点
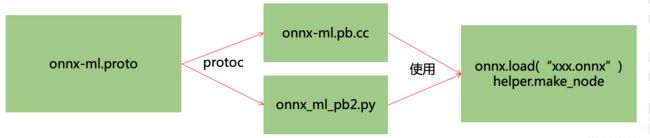
编译onnx-ml.proto文件
#!/bin/bash
# 请修改protoc为你要使用的版本protoc
export LD_LIBRARY_PATH=${@NVLIB64}
protoc=${@PROTOC_PATH}
rm -rf pbout
mkdir -p pbout
$protoc onnx-ml.proto --cpp_out=pbout --python_out=pbout
ONNX 文件结构
下面一段代码是 onnx-ml.proto 文件中的一部分关键代码:
message NodeProto {
repeated string input = 1; // namespace Value
repeated string output = 2; // namespace Value
// An optional identifier for this node in a graph.
// This field MAY be absent in ths version of the IR.
optional string name = 3; // namespace Node
// The symbolic identifier of the Operator to execute.
optional string op_type = 4; // namespace Operator
// The domain of the OperatorSet that specifies the operator named by op_type.
optional string domain = 7; // namespace Domain
// Additional named attributes.
repeated AttributeProto attribute = 5;
// A human-readable documentation for this node. Markdown is allowed.
optional string doc_string = 6;
}
表示 onnx 中有节点类型叫 node
它有 input 属性,是 repeated ,即重复类型,数组
它有 output 属性,是 repeated ,即重复类型,数组
它有 name 属性,是 string 类型
后面的数字是 id,一般不用管
关键要看的两个:
repeated :表示是数组
optional:可选,通常无视即可
我们只关心是否是数组,类型是什么
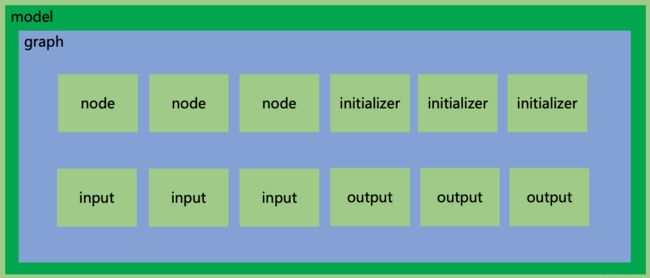 上图是 onnx 文件结构的一个示意图,
上图是 onnx 文件结构的一个示意图,
model:表示整个 ONNX 模型,包含图结构和解析器格式、opset 版本、导出程序类型等
model.graph:表示图结构,通常是我们 netron 可视化看到的主要结构
model.graph.node:表示图中的所有节点,是数组,例如 conv、bn 等算子就是在这里的,通过 input、output 表示节点间的连接关系
model.graph.initializer:权重类的数据大都储存在这里
model.graph.input:整个模型的输入储存在这里,表明哪个节点是输入节点,shape 是多少
model.graph.output:整个模型的输出储存在这里,表明哪个节点是输入节点,shape 是多少
对于 anchor grid 类的常量数据,通常会存储在 model.graph.node 中,并指定类型为 Constant 该类型节点在 netron 中可视化时不会显示出来
读写改ONNX文件
PyTorch导出onnx文件
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.onnx
import os
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 1, 3, padding=1)
self.relu = nn.ReLU()
self.conv.weight.data.fill_(1)
self.conv.bias.data.fill_(0)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
# 这个包对应opset11的导出代码,如果想修改导出的细节,可以在这里修改代码
# import torch.onnx.symbolic_opset11
print("对应opset文件夹代码在这里:", os.path.dirname(torch.onnx.__file__))
model = Model()
dummy = torch.zeros(1, 1, 3, 3)
torch.onnx.export(
model,
# 这里的args,是指输入给model的参数,需要传递tuple,因此用括号
(dummy,),
# 储存的文件路径
"demo.onnx",
# 打印详细信息
verbose=True,
# 为输入和输出节点指定名称,方便后面查看或者操作
input_names=["image"],
output_names=["output"],
# 这里的opset,指,各类算子以何种方式导出,对应于symbolic_opset11
opset_version=11,
# 表示他有batch、height、width3个维度是动态的,在onnx中给其赋值为-1
# 通常,我们只设置batch为动态,其他的避免动态
dynamic_axes={
"image": {0: "batch", 2: "height", 3: "width"},
"output": {0: "batch", 2: "height", 3: "width"},
}
)
print("Done.!")
创建onnx文件
直接从构建onnx,不经过任何框架的转换。通过import onnx和onnx.helper提供的make_node,make_graph,make_tensor等等接口我们可以轻易的完成一个ONNX模型的构建。
需要指定 node,initializer,input,output,graph,model 参数
import onnx # pip install onnx>=1.10.2
import onnx.helper as helper
import numpy as np
# https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.proto
nodes = [
helper.make_node(
name="Conv_0", # 节点名字,不要和op_type搞混了
op_type="Conv", # 节点的算子类型, 比如'Conv'、'Relu'、'Add'这类,详细可以参考onnx给出的算子列表
inputs=["image", "conv.weight", "conv.bias"], # 各个输入的名字,结点的输入包含:输入和算子的权重。必有输入X和权重W,偏置B可以作为可选。
outputs=["3"],
pads=[1, 1, 1, 1], # 其他字符串为节点的属性,attributes在官网被明确的给出了,标注了default的属性具备默认值。
group=1,
dilations=[1, 1],
kernel_shape=[3, 3],
strides=[1, 1]
),
helper.make_node(
name="ReLU_1",
op_type="Relu",
inputs=["3"],
outputs=["output"]
)
]
initializer = [
helper.make_tensor(
name="conv.weight",
data_type=helper.TensorProto.DataType.FLOAT,
dims=[1, 1, 3, 3],
vals=np.array([1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], dtype=np.float32).tobytes(),
raw=True
),
helper.make_tensor(
name="conv.bias",
data_type=helper.TensorProto.DataType.FLOAT,
dims=[1],
vals=np.array([0.0], dtype=np.float32).tobytes(),
raw=True
)
]
inputs = [
helper.make_value_info(
name="image",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", 1, 3, 3]
)
)
]
outputs = [
helper.make_value_info(
name="output",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", 1, 3, 3]
)
)
]
graph = helper.make_graph(
name="mymodel",
inputs=inputs,
outputs=outputs,
nodes=nodes,
initializer=initializer
)
# 如果名字不是ai.onnx,netron解析就不是太一样了
opset = [
helper.make_operatorsetid("ai.onnx", 11)
]
# producer主要是保持和pytorch一致
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, "my.onnx")
print(model)
print("Done.!")
读onnx文件
通过graph可以访问参数,数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存。需要用np.frombuffer方法还原成类型为float32的ndarray。注意还原出来的ndarray是只读的。
import onnx
import onnx.helper as helper
import numpy as np
model = onnx.load("demo.change.onnx")
#打印信息
print("==============node信息")
# print(helper.printable_graph(model.graph))
print(model)
conv_weight = model.graph.initializer[0]
conv_bias = model.graph.initializer[1]
# 数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存,通过np.frombuffer方法还原成类型为float32的ndarray
print(f"===================={conv_weight.name}==========================")
print(conv_weight.name, np.frombuffer(conv_weight.raw_data, dtype=np.float32))
print(f"===================={conv_bias.name}==========================")
print(conv_bias.name, np.frombuffer(conv_bias.raw_data, dtype=np.float32))
将得到类似如下输出:
==============node信息
ir_version: 6
producer_name: "pytorch"
producer_version: "1.9"
graph {
node {
input: "image"
input: "conv.weight"
input: "conv.bias"
output: "3"
name: "Conv_0"
op_type: "Conv"
attribute {
name: "dilations"
ints: 1
ints: 1
type: INTS
}
attribute {
name: "group"
i: 1
type: INT
}
attribute {
name: "kernel_shape"
ints: 3
ints: 3
type: INTS
}
attribute {
name: "pads"
ints: 1
ints: 1
ints: 1
ints: 1
type: INTS
}
attribute {
name: "strides"
ints: 1
ints: 1
type: INTS
}
}
node {
input: "3"
output: "output"
name: "Relu_1"
op_type: "Relu"
}
name: "torch-jit-export"
initializer {
dims: 1
dims: 1
dims: 3
dims: 3
data_type: 1
name: "conv.weight"
raw_data: "\000\000\000\000\000\000\200?\000\000\000@\000\000@@\000\000\200@\000\000\240@\000\000\300@\000\000\340@\000\000\000A"
}
initializer {
dims: 1
data_type: 1
name: "conv.bias"
raw_data: "\000\000\000\000"
}
input {
name: "image"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_param: "batch"
}
dim {
dim_value: 1
}
dim {
dim_param: "height"
}
dim {
dim_param: "width"
}
}
}
}
}
output {
name: "output"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_param: "batch"
}
dim {
dim_value: 1
}
dim {
dim_param: "height"
}
dim {
dim_param: "width"
}
}
}
}
}
}
opset_import {
version: 11
}
====================conv.weight==========================
conv.weight [0. 1. 2. 3. 4. 5. 6. 7. 8.]
====================conv.bias==========================
conv.bias [0.]
改onnx文件
由于protobuf任何支持的语言,我们可以使用 c/c++/python/java/c# 等等实现对onnx文件的读写操作
掌握onnx和helper实现对onnx文件的各种编辑和修改
增
一般伴随增加 node 和 tensor
graph.initializer.append(xxx_tensor)
graph.node.insert(0, xxx_node)
例子:比如我们想要在 yolov5s.onnx 的模型前面添加一个预处理,将预处理功能继承到 ONNX 模型里面,将 opencv 读到的图片先预处理成我们想要的格式。这个过程中直接在 ONNX 模型中添加是比较麻烦的,我们的思路是想用 PyTorch 写一个预处理模块并导出为 preprocess.onnx ,再将其添加到 yolov5s.onnx 前面。后处理等其他添加节点的操作类似。
步骤:
先用 PyTorch 实现预处理并导出 ONNX 模型 preprocess_onnx
将 preprocess_onnx 中所有节点以及输入输出名称都加上前缀,避免与原模型的名称冲突
将 yolov5s 中以 image 为输入的节点,修改为 preprocess_onnx 的输出节点
将 preprocess_onnx 的 node 全部放到 yolov5s 的 node 中
将 preprocess_onnx 的输入名称作为 yolov5s 的 input 名称
代码如下:
import torch
import onnx
import onnx.helper as helper
# 步骤1
class PreProcess(torch.nn.Module):
def __init__(self):
super().__init__()
self.mean = torch.randn(1, 1, 1, 3) # 这里的均值标准差就直接随机了,实际模型按需调整
self.std = torch.randn(1, 1, 1, 3)
def forward(self, x):
# 输入: B H W C uint8
# 输出: B C H W float32, 减255, 减均值除标准差
x = x.float()
x = (x / 255.0 - self.mean) / self.std
x = x.permute(0, 2, 3, 1)
return x
preprocess = PreProcess()
torch.onnx.export(
preprocess, (torch.zeros(1, 640, 640, 3, dtype=torch.uint8), ) 'preprocess.onxx')
)
preprocess_onnx = onnx.load('preprocess.onnx')
model = onnx.load('yolov5s.onnx')
# 步骤2
for item in preprocess_onnx.graph.node:
item.name = f"pre/{item.name"
for i in range(len(item.input)):
item.input[i] = f"pre/{item.input[i]}"
for i in range(len(item.output)):
item.output[i] = f"pre/{item.output[i]}"
# 步骤3
for item in model.graph.node:
if item.name == 'Conv_0':
item.input[0] = f"pre/{preprocess_onnx.graph.output[0].name}"
# 步骤4
for item in pre_onnx.graph.node:
model.graph.node.append(item)
# 步骤5
input_name = f"pre/{preprocess_onnx.graph.input[0].name}"
model.graph.input[0].CopyFrom(preprocess_onnx.graph.input[0])
model.graph.input[0].name = input_name
onnx.save(model, "yolov5s_with_proprecess.onnx")
删
删除节点时需要注意的是要将前一个节点的输出接到下一个节点的输入上,就像删除链表节点一样。
# 删除一个节点
import onnx
model = onnx.load('yolox_s.onnx')
find_node_with_input = lambda name: [item for item in model.graph.node if name in item.input][0]
find_node_with_output = lambda name: [item for item in model.graph.node if name in item.output][0]
remove_nodes = []
for item in model.graph.node:
if item.name == "Transpose_236":
# 上一个节点的输出是当前节点的输入
_prev = find_node_with_output(item.input[0])
# 下一个节点的输入是当前节点的输出
_next = find_node_with_input(item.)
_next.input[0] = _prev.output[0]
remove_nodes.append(item)
for item in remove_nodes[::-1]:
model.graph.node.remove(item)
改
# 改数据
input_node.name = 'data'
# 改掉整个节点
new_item = helper.make_node(...)
item.CopyFrom(new_item) # `CopyFrom` 是 protobuf 中的函数
通常也可以通过 for loop 去找我们想要的 initializer 或 node 来查看或修改:
for item in model.graph.initializer:
if item.name == 'conv1.weight':
# do something
pass
for item in model.graph.node:
if item.name == 'Constant':
# do something
pass
例子,修改 yolov5s.onnx 的动态 batch size 静态尺寸改为静态 batch size,动态尺寸:
import onnx
import onnx.helper as helper
model = onnx.load('yolox_s.onnx')
static_batch_size = 4
# 原来的输入尺寸是: [batch, 3, 640, 640], 动态batch size, 固定图像尺寸
new_input = helper.make_tensor_value_info("images", 1, [static_batch_size, 3, 'height', 'width'])
model.graph.input[0].CopyFrom(new_input)
# 原来的输出尺寸是: [batch, 25200, 85], 动态batch size, 固定锚框数和类别数
new_output = helper.make_tensor_value_info("output", 1, [static_batch_size, 'anchors', 'classes'])
model.graph.output.CopyFrom(new_output)
onnx.save(model, 'static_bs4.onnx')
总结
ONNX重点
ONNX 的主要结构:graph、graph.node、graph.intializer、graph.input、graph.output
ONNX 的节点构造方式:onnx.helper、各种 make 函数
ONNX 的 onnx-ml.proto 文件
理解模型结构的储存、权重的储存、常量的储存、netron 的可视化解读对应到模型文件中的相应部分
ONNX 解析器的理解,包括如何使用 nvidia 发布的解析器源代码 https://github.com/onnx/onnx-tensorrt
学习如何编辑 ONNX 模型的原因是:在模型的转换过程中肯定会遇到各种各样的不匹配之类的困难,能够自如地编辑 ONNX 模型文件,那无论遇到什么问题,我们都可以通过直接编辑 ONNX 模型文件来解决。
参考资料:https://arleyzhang.github.io/articles/7f4b25ce/