互联网架构
互联网架构
- 一、特点
- 二、思维
- 三、目标与度量
- 四、方法论
一、特点
互联网应用架构具有高并发、大数据、快迭代、高风险等特点。
二、思维
互联网思维讲究“专注、极致、口碑、快”。
(1)“专注”是指技术发展路线专注于行业发展方向,设计上要“高内聚、低耦合”。
(2)“极致”是指互联网架构要对每个环节都做到极致的思考。
(3)“口碑”是指互联网架构一定要具备较高的可靠性和安全性。
(4)“快”是指互联网架构要满足快速开发迭代、快速诊断和部署的要求。
三、目标与度量
要满足低成本、高性能、易扩展、高可用、高安全的目标。
(1)低成本,实现技术架构要尽量控制成本,从时间阶段上可以分为建设成本、维护成本,从支出类型上可以分为硬件成本、商业中间件成本、软件开发成本等。
(2)高性能,网站性能指标具体体现在响应时间、并发数、吞吐量、系统错误率、系统负载等技术指标上。
系统的响应时间是指系统完成某一功能需要使用的时间,也就是从用户发出请求到收到结果所需要的时间,响应时间可能包括网络传输时间、服务处理、数据库处理时间等。
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量,准确地说是指同时发出请求的用户数。
系统的吞吐量(TPS)是指系统每秒处理的总的用户请求数。在性能测试中,TPS=VU×R/T,其中VU是同时发出请求的虚拟用户数目,R是每个虚拟用户发出的请求数目,T是性能测试所用的时间。
系统错误率是指系统在负载情况下,失败交易的概率。错误率=(失败交易数/交易总数)×100%。稳定性较好的系统,其错误率应该由超时引起,即为超时率。
资源利用率是各种计算机资源的使用情况,包括系统负载(Load)、内存利用率、SWAP内存交换空间利用率、网络I/O、硬盘I/O等。其中系统负载是系统CPU繁忙程度的度量,是指当前正在被CPU执行和等待被CPU执行的进程数目总和。
(3)高可用,系统的可用性(availability)指系统在面对各种异常时可以正确提供服务的能力。在系统测试过程中通过可靠性测试和稳定性测试保障系统的高可用。
可靠性指标:在双机热备、集群、备份和恢复等场景中,模拟主备切换、节点变更、备份与恢复的过程。
稳定性指标:系统按照最大容量的80%或在标准压力(系统的预期日常压力)情况下运行,能够稳定运行的最短时间。
(4)易扩展,系统的扩展性(scalability)指分布式系统通过扩展集群机器规模提高系统性能(吞吐、延迟、并发)、存储容量、计算能力的特性。互联网架构在设计时应支持无限扩展,在实施时可以按单日处理情况的三倍部署,遇重大营销推广活动时需要提前规划准备。
扩展能力的计算公式为:(增加性能/原始性能)/(增加资源/原始资源)×100%。
(5)高安全,系统上线前要使用代码检查工具和漏洞扫描工具对系统进行安全检查。业务场景较重要的,按照行业主管要求,达到三级等保标准,并按等保要求定期开展安全等级评测。
四、方法论
- CAP模型
CAP是指任何分布式系统在可用性、一致性、分区容错性方面,不能兼得,最多只能得其二,因此,任何分布式系统的设计只是在三者中的不同取舍而已。
■ C指Consistency,即一致性。
一致性被称为原子对象,任何读写都应该看起来是“原子”的或串行的。写后面的读一定能读到前面写的内容,所有的读写请求都好像被全局排序。即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。
■ A指Availability,即可用性。
对任何非失败节点都应该在有限时间内给出请求的回应。
■ P指Partition tolerance,即分区容错性。
允许节点之间丢失任意多的消息,当网络分区发生故障时,节点之间的消息可能会完全丢失。即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
要满足分区容错性的分布式系统,只能在一致性和可用性两者中选择一个。
- CAP应用
(1)CA:优先保证一致性和可用性,放弃分区容错。
(2)CP:优先保证一致性和分区容错性,放弃可用性。(ZooKeeper)
(3)AP:优先保证可用性和分区容错性,放弃一致性。(NoSQL中的Cassandra)
- BASE理论
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(StrongConsistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consistency)。
BASE是指基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency)。
基本可用:基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务,这就是损失部分可用性的体现。
软状态:软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中,一般一份数据至少有三个副本,允许不同节点间副本同步的延时就是软状态的体现。
最终一致性:最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
- ACID
关系型数据库的事务操作遵循ACID原则,ACID原则是指在写入/异动资料的过程中,为保证交易正确可靠而必须具备的四个特性。
原子性(Atomicity,又称不可分割性)
在事务中执行的多个操作是原子性的,要么事务中的操作全部执行,要么一个都不执行。
一致性(Consistency)
保证进行事务的过程中整个数据库的状态是一致的,不会出现数据不一致的情况。
隔离性(Isolation,又称独立性)
两个事务不会相互影响,覆盖彼此数据等。
持久性(Durability)
事务一旦完成,那么数据应该被写到安全的、持久化存储的设备上(比如磁盘)。
- AKF Scale Cube扩展立方体
模型
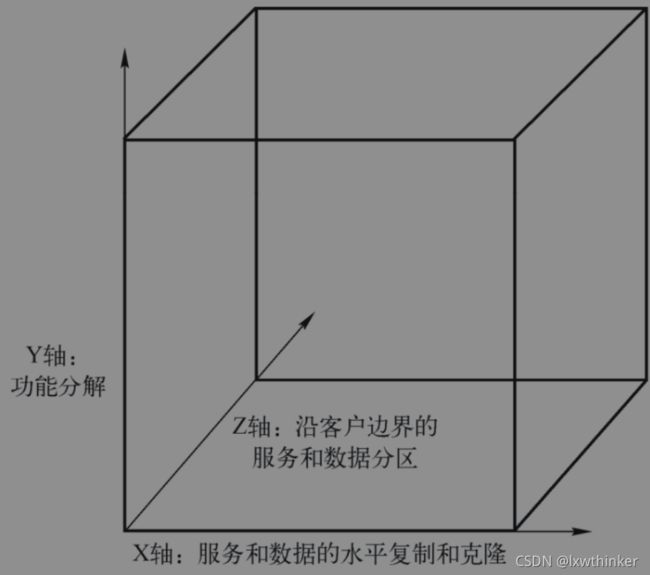
(1)X轴扩展
水平复制,复制同样的工作或数据镜像给多个实体,通过克隆的方式水平扩展。一般是在负载均衡后面放置多个相同的应用服务,如果有N个相同的应用部署,那么每个单独的应用只需要处理1/N份的负载请求。
优点是简单易扩展。
缺点是当单体应用本身的复杂性提高时所带来的管理及运维挑战,例如针对特定事件的处理需要对整个应用进行发布部署,同时数据库的水平复制存在挑战。
(2)Y轴扩展
功能分解,拆分不同的事务进行扩展。针对X轴扩展产生的问题,从Y轴这个方向扩展,将巨型应用拆解,分解为一组不同的服务,把分割的工作职责和数据分配给多个实体,这也是微服务理论诞生的基础。例如将购物应用分解为购物车服务、订单服务、支付服务等。
优点是服务拆解以后便于维护和有针对性的扩展。
缺点是按功能拆解以后,服务数量增多,部署成本增高;服务与服务之间调用传输成本增高;由内存调用转变为网络传输,故障率增高。
(3)Z轴扩展
数据分区,是指按照客户的需求、位置或者价值分割或分配工作职责,一般来说就是对数据的扩展,将事务产生的数据按照一定的特征分区在不同的服务器上。如按照客户ID进行分库分表。
优点是对数据进行隔离,不同数据的请求被分发到不同的服务器上。
缺点是Z轴扩展是所有扩展中复杂度最高的。从传统的巨大的单体结构到如今面向服务的去IOE的架构,互联网核心架构的演变和发展就是在不断应用AKF扩展立方体模型。
三种扩展方式可以根据需要组合使用,但一定要选择与应用规模相符合的架构,例如一个面向小企业的企业内部信息系统就没必要进行Y轴扩展。