hadoop HA高可用搭建流程
前置准备:有可用的zookeeper。
| 节点名 | zookeeper | namenode | datanode | journalnode | zkfc | resourcemanager | nodemanager |
|---|---|---|---|---|---|---|---|
| hadoop171 | √ | √ | √ | √ | √ | √ | |
| hadoop172 | √ | √ | √ | √ | √ | √ | √ |
| hadoop173 | √ | √ | √ | √ | √ |
安装包下载地址:
hadoop官网,版本全下载速度慢。
清华开源镜像,下载速度快,版本少。
tar -zxvf hadoop-3.2.1.tar.gz -C /opt/module
修改名称(可选)
mv hadoop-3.2.1.tar.gz hadoop
解压好后,进入hadoop/etc/hadoop下
修改文件,建议先在一台机器中全部修改完后把文件复制到其他节点中。
hadoop-env.sh
增加java路径
vim hadoop-env.sh
export JAVA_HOME=路径
配置文件
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://kingvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop171:2181,hadoop172:2181,hadoop173:2181value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop/data/hadoop/hdfs/tmpvalue>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>kingvalue>
property>
<property>
<name>dfs.ha.namenodes.kingname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.king.nn1name>
<value>hadoop171:9820value>
property>
<property>
<name>dfs.namenode.rpc-address.king.nn2name>
<value>hadoop172:9820value>
property>
<property>
<name>dfs.namenode.http-address.king.nn1name>
<value>hadoop171:9870value>
property>
<property>
<name>dfs.namenode.http-address.king.nn2name>
<value>hadoop172:9870value>
property>
<property>
<name> dfs.namenode.shared.edits.dir name>
<value>qjournal://hadoop171:8485;hadoop172:8485;hadoop173:8485/kingvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.kingname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/module/hadoop/data/hadoop/hdfs/jnvalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/jinghang/.ssh/id_rsavalue>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>/opt/module/hadoop/data/hadoop/hdfs/editsvalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/opt/module/hadoop/data/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/opt/module/hadoop/data/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.hostsname>
<value>/opt/module/hadoop/etc/hadoop/whitelistvalue>
property>
<property>
<name>dfs.hosts.excludename>
<value>/opt/module/hadoop/etc/hadoop/blacklistvalue>
property>
configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname>
<value>/opt/module/hadoop/etc/hadoop:/opt/module/hadoop/share/hadoop/mapreduce/*:/opt/module/hadoop/share/hadoop/mapreduce/lib/*:/opt/module/hadoop/share/hadoop/common/*:/opt/module/hadoop/share/hadoop/common/lib/*:/opt/module/hadoop/share/hadoop/hdfs/*:/opt/module/hadoop/share/hadoop/hdfs/lib/*:/opt/module/hadoop/share/hadoop/yarn/*:/opt/module/hadoop/share/hadoop/yarn/lib/*value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop173:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop173:19888value>
property>
configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>kingvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop172value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop173value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>hadoop172:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>hadoop173:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop171:2181,hadoop172:2181,hadoop173:2181value>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.application.classpathname>
<value>/opt/module/hadoop/etc/hadoop:/opt/module/hadoop/share/hadoop/common/lib/*:/opt/module/hadoop/share/hadoop/common/*:/opt/module/hadoop/share/hadoop/hdfs:/opt/module/hadoop/share/hadoop/hdfs/lib /*:/opt/module/hadoop/share/hadoop/hdfs/*:/opt/module/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop/share/hadoop/yarn:/opt/module/hadoop/share/hadoop/yarn/lib/*:/opt/module/hadoop/share/hadoop/yarn/*:/opt/module/hbase/lib/*value>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/opt/module/hadoop/data/hadoop/localvalue>
property>
<property>
<name>yarn.nodemanager.log-dirsname>
<value>/opt/module/hadoop/data/hadoop/yarn/logsvalue>
property>
configuration>
设置workers
vim workers
hadoop171
hadoop172
hadoop173
如果设置了黑白名单,则需要创建,没设置这一步可以跳过
设置白名单
vim whitelist
hadoop171
hadoop172
hadoop173
创建黑名单
touch blacklist
创建目录,我的配置文件中自定义了一些路径,如果没设置可以省略这一步,自定义的路径我在上面的xml文件中备注了。
在hadoop下面创建data文件夹
mkdir -p data/hadoop
cd data/hadoop
mkdir -p hdfs/data hdfs/edits hdfs/jn hdfs/name hdfs/tmp
mkdir local
mkdir -p yarn/local yarn/logs
配置完成后,将hadoop拷贝到其他节点中
scp -r hadoop 用户@节点名称:/opt/module
配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin
刷新
source /etc/profile
格式化namenode
温馨提示:zookeeper一定要开着哦!
首先在三台机器中启动journalnode
hdfs --daemon start journalnode
在hadoop171中格式化namenode
hdfs namenode -format
格式化后启动
hdfs --daemon start namenode
在hadoop172中同步节点中的namenode元数据
hdfs namenode -bootstrapStandby
在hadoop171节点上关闭namenode
hdfs --daemon stop namenode
在hadoop171上格式化zkfc
hdfs zkfc -formatZK
在三台节点中关闭journalnode
hdfs --daemon stop journalnode
启动hadoop集群
start-all.sh
验证HA高可用
namenode验证HA高可用
hdfs haadmin -getAllServiceState

停止掉active的NameNode
kill -9 进程号
再次查看
hdfs haadmin -getAllServiceState
![]() 可以看到状态由standby变为active,而停掉的节点使用此命令会报拒绝连接的异常
可以看到状态由standby变为active,而停掉的节点使用此命令会报拒绝连接的异常
启动停掉的namenode再次查看

resourcemanager验证HA
yarn rmadmin -getAllServiceState
步骤和namenode一样。
至此,hadoop HA的搭建和测试完成,接下来说一下安装过程中需要注意的地方和可能会遇到的报错在
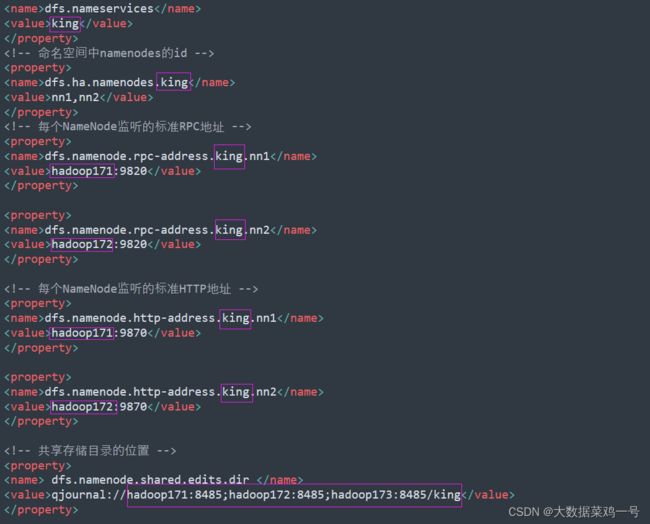
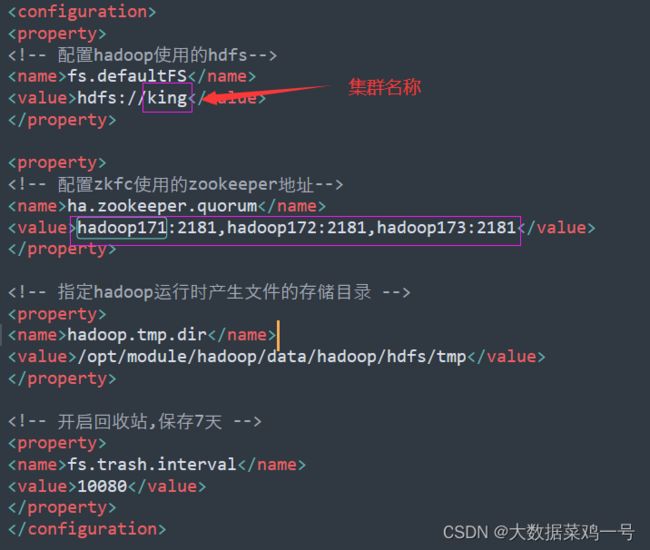
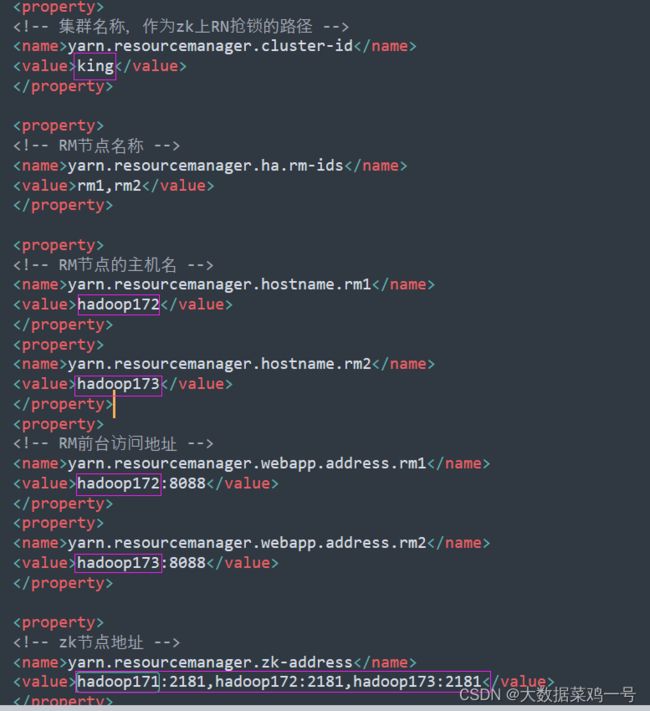
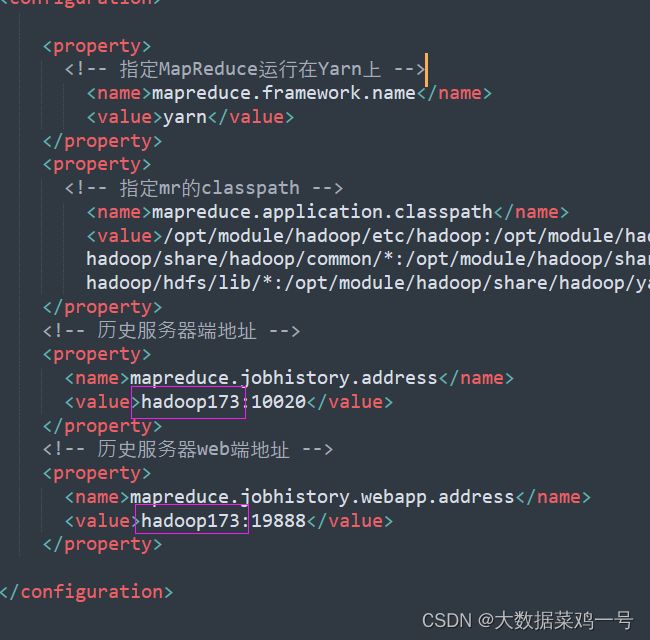
1.在上面配置文件中,需要注意,我这里是 ‘king’ 如果需要改的话,记得将上面配置文件中所有涉及到 ’king‘ 的全部改成你修改的集群名称。还有注意节点名称也需要修改,我下面将需要修改的地方高亮出来。
hdfs-site.xml
core-site.xml
yarn-site.xml
core-site.xml
2.NameNode 无法自动故障转移(切换active)
原因是因为hdfs-site.xml中有下面的配置
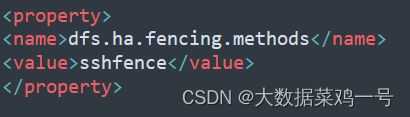
解决办法:安装包含fuster程序的软件包Psmisc(每个机器上都要安装):
yum -y install psmisc