Elastic Stack 概述
文章目录
- 一、Elastic Stack简介
- 二、elasticsearch
- 三、logstash
- 四、Beats
- 五、kibana
- 六、ELK工作流程
- 七、常见架构
-
- (一)简单的ELK应用架构
- (二)典型ELK架构
- (三)ELK集群架构
一、Elastic Stack简介
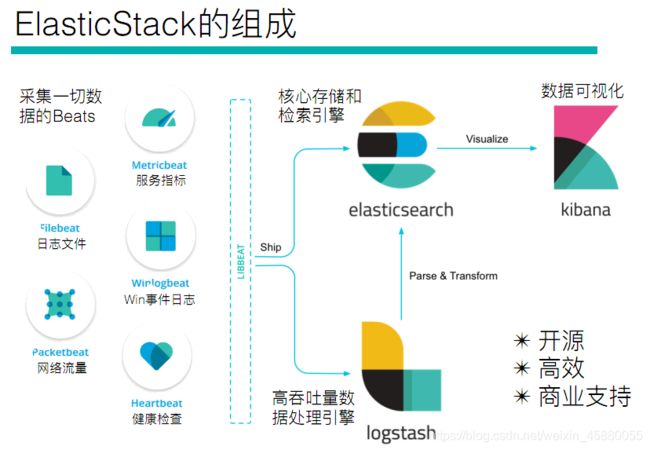
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
在 ELK Stack 这个生态圈慢慢发展过程中,加入了一个新成员 Beats(Beats是负责单一用途数据采集并推送给Logstash或Elasticsearch的轻量级产品),就更名为 Elastic Stack
Elastic Stack 是 ELK Stack 的更新换代产品。
所以,Elastic Stack技术栈的功能为,将系统、网络、应用系统日志等各种日志及相关数据进行收集、过滤、转换、然后进行集中存放并可用于实时检索、分析和展示。

全系的Elastic Stack技术栈包括:
二、elasticsearch
ElasticSearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch 是用 Java 开发的,并作为 Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
elasticsearch是一个采用Restful API标准的高扩展的和高可用的实时数据分析的全文搜索工具
相关概念

集群(cluster):集群就是一个或多个节点组成。其中一个节点为主节点,这个节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标识的名字,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的聚群名字。
节点(node):节点就是一台单一的服务器,单个ElasticSearch实例。是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。
索引(index):索引是有相似属性的系列文档的集合,是Elasticsearch对逻辑数据的逻辑存储。可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
文档(Document):文档是存储信息的基本单元,可以被索引。文档是以JSON格式表现的。用关系型数据库来类比的话,一个文档相当于数据库
表中的一行记录。
分片(shards):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分,而这些分布在不同节点的数据就是分片。ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿。
副本(Replicas):一个副本分片只是一个主分片的拷贝。ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个副本。
分片(shards)和副本(replicas):
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需 1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。
为了解决这个问题, elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量 b、分布式并行跨分片操作,提高性能和吞吐量。
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch 控制的,这些对用户 而言是透明的。网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。 为此,elasticsearch 让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
a. 高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
b. 提高性能,增大吞吐量。
搜索可以并行在所有副本上执行,总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
说明:
对于分布式搜索引擎来说,分片及副本的分配将是高可用及快速搜索响应的设计核心。主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求。
我们往 Elasticsearch 添加数据时需要用到 索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理 分片 的逻辑命名空间 。
一个 分片 是一个底层的 工作单元 ,它仅保存了 全部数据中的一部分。 在分片内部机制中,分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是 主分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。所以副本可以提高数据吞吐量,实现读写分离,读数据的时候从副本上读,写数据的时候只用主分片去写。需要注意的是,主分片的个数实在建立索引之前要确定,建立完索引之后,是不能够进行修改的,除非重新建索引。因此在建索引之前,一定要合理的配置分片个数,副本个数的话后期是可以改动的。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
Elasticsearch禁止同一个分片的主分片和副本分片在同一个节点上,所以如果是一个节点的集群是不能有副本的。
它在节点失败的情况下提供高可用性。由于这个原因,需要注意的是,副本分片永远不会分配到与主分片相同的节点上。
被混淆的概念是,一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个 Elasticsearch
索引是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后像执行分布式检索 提到的那样,合并每个分片的结果到一个全局的结果集。
三、logstash
LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。
LogStash的四大组件
- Shipper:发送事件(events)至LogStash;通常,远程代理端(agent)只需要运行这个组件即可;
- Broker and Indexer:接收并索引化事件;broker起数据缓存的作用,通过这个缓存器可以提高Logstash shipper发送日志到Logstash indexer的速度,同时避免由于突然断电等导致的数据丢失。可以实现broker功能的还有很多软件,例如kafka等,Redis服务器是logstash官方推荐的broker。
- Search and Storage:允许对事件进行搜索和存储;
- Web Interface:基于Web的展示界面
正是由于以上组件在LogStash架构中可独立部署,才提供了更好的集群扩展性。
LogStash主机分类
-
代理主机(agent host)
作为事件的传递者(shipper),将各种日志数据发送至中心主机;只需运行Logstash 代理(agent)程序;
-
中心主机(central host)
可运行包括中间转发器(Broker)、索引器(Indexer)、搜索和存储器(Search and Storage)、Web界面端(Web Interface)在内的各个组件,以实现对日志数据的接收、处理和存储。
主要功能:
-
输入、过滤器和输出
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
以下是常见的过滤器:
- grok:解析并构造任意文本。Grok是目前Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方式。Logstash内置了120种模式,您很可能会找到满足您需求的模式!
- mutate:对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
- drop:完全删除事件,例如调试事件。
- clone:制作事件的副本,可能添加或删除字段。
- geoip:添加有关IP地址的地理位置的信息
- 采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择,可以同时从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从服务器的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
以下是常见的输入来源:
- file:从文件系统上的文件读取,与UNIX命令非常相似 tail -0F
- syslog:在已知端口上侦听syslog消息进行解析
- redis:使用redis通道和redis列表从redis服务器读取。Redis通常用作集中式Logstash安装中的“代理”,该安装将Logstash事件从远程Logstash“托运人”排队。
- Beats:处理 Beats发送的事件,beats包括filebeat、packetbeat、winlogbeat。
-
实时解析和转换数据
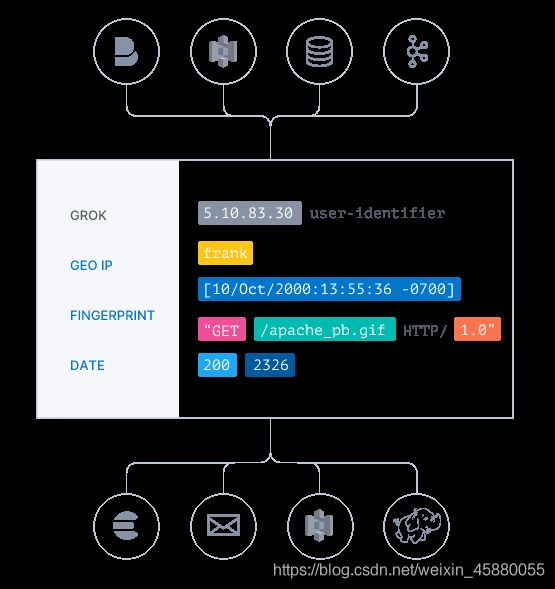
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便进行更强大的分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
- 使用丰富的过滤器库和功能多样的 Elastic Common Schema,可以实现无限丰富的可能。
-
选择存储库,导出数据

尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
常见的输出方向:
- elasticsearch:将事件数据发送给Elasticsearch。如果您计划以高效,方便且易于查询的格式保存数据… Elasticsearch是您的最佳选择
- file:将事件数据写入磁盘上的文件。
- graphite:将事件数据发送到graphite,这是一种用于存储和绘制指标的流行开源工具。
- statsd:将事件数据发送到statsd,这是一种“侦听统计信息,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入后端服务”的服务。
Logstash工作过程

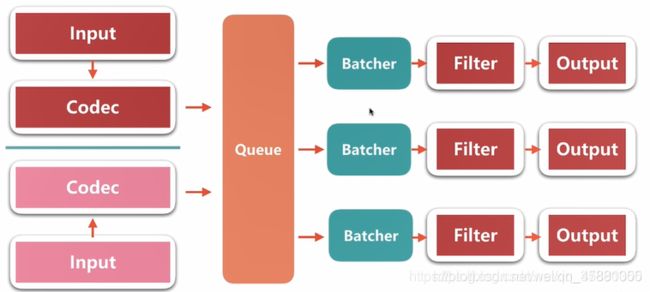
Logstash的数据处理过程主要包括:Inputs,Filters,Outputs 三部分,另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output,codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等
- Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等
- Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等
- Codecs:Codecs(编码插件)不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json, multiline。Logstash不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
Logstash优点
- 可伸缩性
节拍应该在一组Logstash节点之间进行负载平衡。建议至少使用两个Logstash节点以实现高可用性。每个Logstash节点只部署一个Beats输入是很常见的,但每个Logstash节点也可以部署多个Beats输入,以便为不同的数据源公开独立的端点。 - 弹性
Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。对于内部部署,建议您配置RAID。在云或容器化环境中运行时,建议您使用具有反映数据SLA的复制策略的永久磁盘。 - 可过滤
对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
可扩展插件生态系统,提供超过200个插件,以及创建和贡献自己的灵活性。
Logstash缺点
Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
四、Beats
Beats 是数据采集的得力工具。将 Beats 和您的容器一起置于服务器上,或者将 Beats 作为功能加以部署,然后便可在 Elasticsearch 中集中处理数据。Beats 能够采集符合 Elastic Common Schema (ECS) 要求的数据,如果希望拥有更加强大的处理能力,Beats 能够将数据转发至 Logstash 进行转换和解析后,Logstash再将处理后的数据发送给 Elasticsearch。
Beats是Elastic Stack技术栈中轻量级的数据采集产品,主要负责数据的转发和采集。 Beats家族包括以下几个成员:
-
Filebeat: filebeat是构建于beats之上的,应用于日志收集场景的实现,用来替代 Logstash Forwarder 的下一代 Logstash 收集器,是为了更快速稳定轻量低耗地进行收集工作,它可以很方便地与 Logstash 还有直接与 Elasticsearch 进行对接。
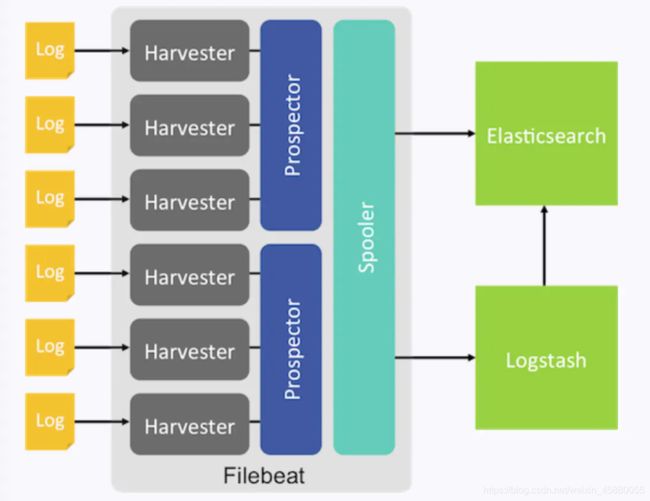
特点:
- 健壮性,filebeat 异常中断重启后会继续上次停止的位置(通过${filebeat_home}\data\registry文件来记录日志的偏移量);
- 智能调节传输速度,防止logstash、es 过载,Filebeat 使用压力敏感协议(backpressure-sensitive)来传输数据,在 logstash 忙的时候,Filebeat 会减慢读取-传输速度,一旦 logstash 恢复,则 Filebeat 恢复原来的速度。
-
Metricbeat:Metricbeat 是一个轻量级的系统级性能指标监控工具。收集CPU,内存,磁盘等系统指标和 Redis,nginx等各种服务的指标。
(1)通过在Linux,Windows,Mac上部署Metricbeat,可以收集cpu,内存,文件系统,磁盘IO,网络IO等统计信息。
(2)支持采集 Apache, NGINX, MongoDB, MySQL, PostgreSQL, Redis, and ZooKeeper等服务的指标。零依赖,只需要在配置文件中启用即可
(3)如果你使用Docker管理你的服务。可以在该主机上单独起一个Metricbeat容器,他通过从proc文件系统中直接读取cgroups信息来收集有关Docker主机上每个容器的统计信息。不需要特殊权限访问Docker API
(4)Metricbeats是ELK Stack全家桶中的一员,可以和ELK无缝协同工作。例如使用Logstash二次处理数据,用Elasticsearch分析,或者用Kibana创建和共享仪表盘。
-
Packetbeat:Packetbeat 是一个轻量级的网络数据包分析工具。Packetbeat可以通过抓包分析应用程序的网络交互。并且将抓到的数据发送到 Logstash 或者Elasticsearch。
(1)Packetbeat 轻松的实时监控并解析像HTTP这样的网络协议。以了解流量是如何经过你的网络。Packetbeat 是被动的,不增加延迟开销,无代码侵入,不干涉其他基础设施。
(2)Packetbeat是一个库,支持多种应用程序层协议,如 http、dns、mysal、icmp、postgres、redis 等。
(3)Packetbeat可以让你实时在目标服务器上进行抓包-解码-获取请求和响应-展开字段-将json格式的结果发送到Elasticsearch。

(4)Packetbeat是ELK Stack全家桶中的一员,可以和ELK无缝协同工作。例如使用Logstash二次处理数据,用Elasticsearch分析,或者用Kibana创建和共享仪表盘。 -
Winlogbeat:Winlogbeat 是一个轻量级的 Windows 事件日志收集工具。将 Windows 事件发送到 Elasticsearc h或者Logstash
-
Heartbeat:Heartbeat 是一个心跳检测工具,主要监控服务的可用性。
(1)不管你是测试同主机服务还是其他网络服务,Heartbeat都可以很轻松的生成正常运行时间和响应时间数据。而且修改配置不需要重启Heartbeat
(2)Heartbeat通过ICMP,TCP,和HTTP进行ping,也支持TLS,身份验证(authentication ),和代理(proxies)。由于简单的DNS解析,你可以监控所有负载均衡的服务(原文:You can monitor all the hosts behind a load-balanced server thanks to simple DNS resolution)
-
Auditbeat:轻量型审计日志采集器。收集主机审计框架的数据,监控文件完整性。Auditbeat 实时采集这些事件,然后发送到 Elastic Stack 其他部分做进一步分析。
-
Functionbeat:面向云端数据的无服务器采集器。在作为一项功能部署在云服务提供商的功能即服务 (FaaS) 平台上后,Functionbeat 即能收集、传送并监测来自云服务的相关数据。
logstash 和 beats的关系
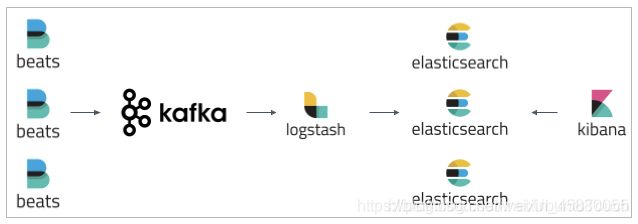
beats并不是用来替代logstash的。beats只是用来优化logstash的,因为logstash是jvm跑的,资源消耗比较大,消耗的性能比较多。如果只是单纯的为了收集日志,使用logstash就有点大材小用了,另外有点浪费资源。而beats是轻量级的用来收集日志的。而logstash更加专注一件事,那就是数据转换,格式化,过滤、分析等处理工作。比方说,日志数据是一行一行的非格式化的数据,想要存在elasticsearch就要有一定的结构。logstash就可以做这件事。
常用的日志采集方案中,大部分的做法就是通过filebeat将所有节点的日志进行采集,然后发送到消息队列redis或kafaka中,然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中,最后在 kibana 上呈现。
如图:
五、kibana
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash 和 Kibana 这三个技术的组合是大数据领域中常用的的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
主要功能
-
Elasticsearch无缝之集成
Kibana架构为Elasticsearch定制,可以将任何结构化和非结构化数据加入Elasticsearch索引。Kibana还充分利用了Elasticsearch强大的搜索和分析功能。
-
整合数据
Kibana能够更好地处理海量数据,并据此创建柱形图、折线图、散点图、直方图、饼图和地图。
-
复杂数据分析
Kibana提升了Elasticsearch分析能力,能够更加智能地分析数据,执行数学转换并且根据要求对数据切割分块。
-
接口灵活,分享更容易
使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
-
配置简单
Kibana的配置和启用非常简单,用户体验非常友好。Kibana 4自带Web服务器,可以快速启动运行。
-
可视化多数据源
Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats或第三方技术的数据整合到Elasticsearch,支持的第三方技术包括Apache Flume、Fluentd等。
-
简单数据导出
Kibana可以方便地导出感兴趣的数据,与其它数据集合并融合后快速建模分析,发现新结果。
-
与Elasticsearch REST API实现可视化交互
六、ELK工作流程
一般都是在需要收集日志的所有服务上部署logstash,作为logstash shipper用于监控并收集、过滤日志,接着,将过滤后的日志发送给Broker,然后,Logstash Indexer将存放在Broker中的数据再写入Elasticsearch,Elasticsearch对这些数据创建索引,最后由Kibana对其进行各种分析并以图表的形式展示。

有些时候,如果收集的日志量较大,为了保证日志收集的性能和数据的完整性,logstash shipper和logstash indexer之间的缓冲器(Broker)也经常采用kafka来实现。
七、常见架构
(一)简单的ELK应用架构
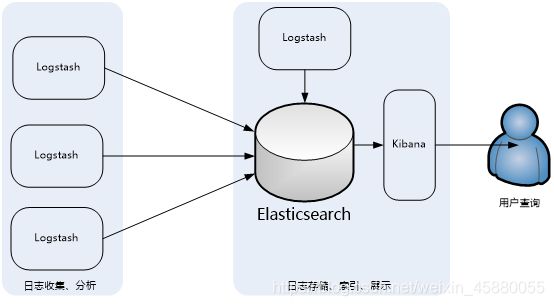
此架构主要是将Logstash部署在各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch再将数据以分片的形式压缩存储,并提供多种API供用户查询、操作。用户可以通过Kibana Web直观的对日志进行查询,并根据需求生成数据报表。
此架构的优点是搭建简单,易于上手。缺点是Logstash消耗系统资源比较大,运行时占用CPU和内存资源较高。另外,由于没有消息队列缓存,可能存在数据丢失的风险。此架构建议供初学者或数据量小的环境使用。
(二)典型ELK架构
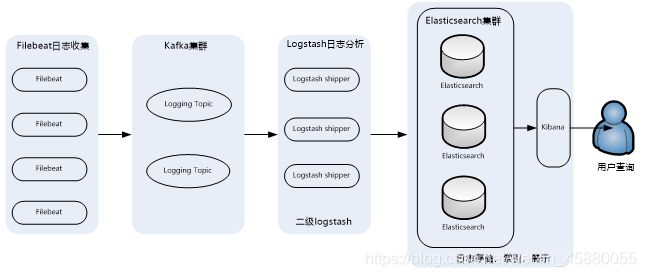
此架构主要特点是引入了消息队列机制,位于各个节点上的Logstash Agent(一级Logstash,主要用来传输数据)先将数据传递给消息队列(常见的有Kafka、Redis等),接着,Logstash server(二级Logstash,主要用来拉取消息队列数据,过滤并分析数据)将格式化的数据传递给Elasticsearch进行存储。最后,由Kibana将日志和数据呈现给用户。由于引入了Kafka(或者Redis)缓存机制,即使远端Logstash server因故障停止运行,数据也不会丢失,因为数据已经被存储下来了。
这种架构适合于较大集群、数据量一般的应用环境,但由于二级Logstash要分析处理大量数据,同时Elasticsearch也要存储和索引大量数据,因此它们的负荷会比较重,解决的方法是将它们配置为集群模式,以分担负载。
此架构的优点在于引入了消息队列机制,均衡了网络传输,从而降低了网络闭塞尤其是丢失数据的可能性,但依然存在Logstash占用系统资源过多的问题,在海量数据应用场景下,可能会出现性能瓶颈。
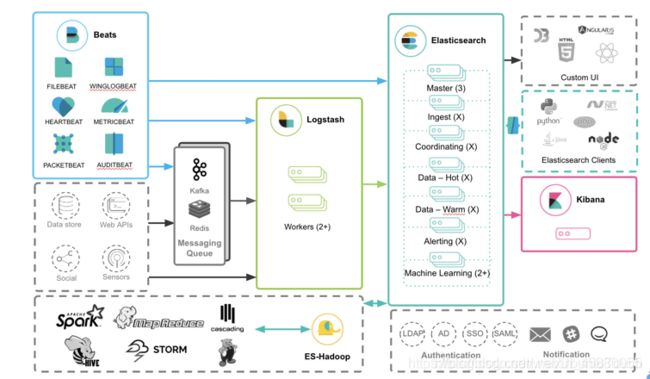
(三)ELK集群架构

这个架构是在上面第二个架构基础上改进而来的,主要是将前端收集数据的Logstash Agent换成了filebeat,消息队列使用了kafka集群,然后将Logstash和Elasticsearch都通过集群模式进行构建,此架构适合大型集群、海量数据的业务场景,它通过将前端Logstash Agent替换成filebeat,有效降低了收集日志对业务系统资源的消耗。同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。