《动手学深度学习》(3)多层感知机
目录
- 感知机
- 多层感知机
-
- 解决XOR问题
- 单隐藏层
-
- 激活函数
-
- Sigmoid激活函数
- Tanh激活函数
- ReLU激活函数
- 多类分类
- 多隐藏层
- 总结
- 多层感知机的实现
- 模型选择
-
- 两种误差
- 验证数据集和测试数据集
- K折交叉验证
- 总结
- 过拟合和欠拟合
-
- 模型容量
- 估计模型容量
-
- VC维
- 数据复杂度
- 总结
- 其他知识点
- 权重衰退
-
- 使用均方范数作为硬性限制
- 使用均方范数作为柔性限制
- 参数更新法则
- 总结
- 其他知识点
- 丢弃法(dropout)
- 数值稳定性
- 模型初始化和激活函数
-
- 让训练更加稳定
- 让每层的方差是一个常数
- 权重初始化
- 例子:MLP
-
- 正向方差
- 反向均值和方差
- Xavier初始
- 假设线性的激活函数
- 反向传播时的情况
- 检查常用激活函数
- 总结
- 其他知识点
感知机
感知机就是一个二分类的模型,最早的AI模型之一。

注:
- 感知机输出-1(或0)或1
- 线性回归输出一个实数
- Softmax回归输出的是概率,如果有多个类,则会输出多个概率,适用于多分类问题
- 感知机训练过程等价于批量大小为1的梯度下降,且损失函数为: l ( y , x , w ) = m a x ( 0 , − y < w , x > ) l(y, \bold x, \bold w) = max(0, -y<\bold w, \bold x>) l(y,x,w)=max(0,−y<w,x>)。当分类正确时,损失函数值为0,是一个常数,不会梯度更新。
- 感知机的收敛定理:

其中数据半径 r r r越大,则收敛步数越多, ρ \rho ρ越小,则说明两类之间的区分余量线越难找,则需要的收敛步数就越多。 - 感知机不能拟合XOR函数,它只能产生线性分隔面(二分类的输入分隔面是一条线)
多层感知机
解决XOR问题

对以上XOR问题,使用三个分类器:蓝色分类器左边的值为正,右边为负;黄色分类器上面的值为正,下面为负。然后将1,2,3,4的两个值分别相乘,最终第三个分类器中值为正的是一类,值为负的是另一类。

单隐藏层

注:
- 此时输入是 n n n维向量;
- 隐藏层参数 w 1 \bold w_1 w1是 m ∗ n m*n m∗n维矩阵,偏置 b 1 \bold b_1 b1是 m m m维向量;
- 输出层的权重 w 2 \bold w_2 w2是 m m m维向量,偏置 b 1 b_1 b1是个常数;
- 这个单分类器最终的输出 o o o也是个常数。
- 激活函数 σ \sigma σ是非线性的,因为如果是线性的,则输出层函数仍然是线性,这个网络就相当于最一个简单线性模型了
激活函数
Sigmoid激活函数

注:
- 如果选择 x x x大于0时,值为1,其余情况下值为0的激活函数,则在 x = 0 x=0 x=0点处,没有导数;
- Sigmoid函数是一个soft版本,在 x = 0 x=0 x=0处比较平滑,图像如下:

Tanh激活函数
将输入投影到 ( − 1 , 1 ) (-1, 1) (−1,1)的区间内,公式如下:

图像如下:

ReLU激活函数
Rectified Linear Unit 函数,公式为: R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x, 0) ReLU(x)=max(x,0),图像如下:
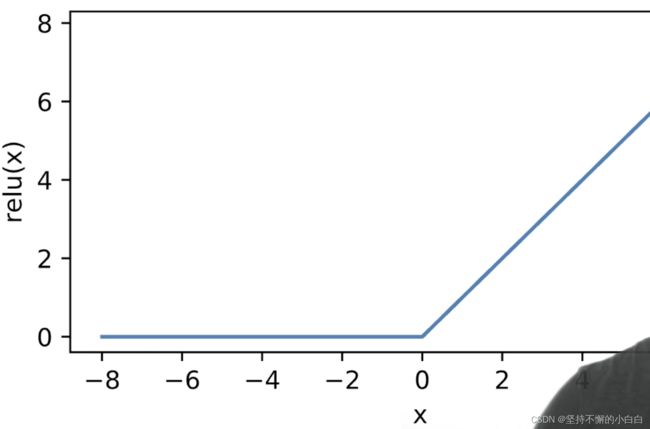
注:CPU上一次指数运算约等价于100次乘法运算的成本,GPU上成本稍微低一点,但是指数运算还是很贵,所以ReLU相对于前面的激活函数,计算上比较简单
多类分类
Softmax回归:
多类分类与Softmax回归的区别:多类分类加了一层隐藏层,如下:

注:多类分类与单类分类的区别:多类分类在输出层计算最后加了一步Softmax回归计算
多隐藏层

注:
- 前一层的输出是下一层的输入
- 每层都要过一次激活函数(激活函数主要用来避免层数的塌陷,因为不用激活函数,就是一个简单的线性模型,不管是设置几层隐藏层,没有激活函数都实际上只有1层隐藏层),输出层的计算不需要再使用激活函数
- 超参数有:
- 隐藏层数
- 每层隐藏层的大小(根据数据大小,选择隐藏层大小)
- 如输入是128,单隐藏层可以选择64,128或者256大小
- 也可以选择多隐藏层,如输入是128维,选择3层隐藏层,则每一层越来越小,如3层分别选择:64,32,16;或者先扩张一下再缩回去,如:256,128,64等;或者比输入稍微扩一点点
- 先扩张一点的方法,会避免模型的overfitting
- 如果是单隐藏层很容易过拟合,隐藏层数多的话,网络深一点,训练起来比较方便且容易找到比较好的解。
总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型
- 常用激活函数是:Sigmoid,Tanh,ReLU
- 使用Softmax来处理多类分类
- 超参数为隐藏层数和各个隐藏层大小
多层感知机的实现
跟着李沐老师视频,这里是一些知识点:
- 参数 w \bold w w的初始化是随机的数,而不是全为0,原因是:当全为0时,非线性激活函数会导致梯度全部相同,为了防止梯度爆炸。
- 多层感知机训练FashionMNIST数据集比上一章Softmax回归训练的结果损失Loss更小,原因是:模型更大了,数据的拟合性更好,所以损失在下降。
- MLP:Multi-Layer Perceptron,用MLP比较多的原因在于MLP效果不好转CNN和RNN,代码不用更改太多,但是先用SVM然后转,代码需要调的部分就比较多。
模型选择
两种误差
- 训练误差:模型在训练数据集上的误差
- 泛化误差:模型在新数据集上的误差
- 我们关心的是泛化误差
验证数据集和测试数据集
- 验证数据集:一个用来评估模型好坏的数据集
- 例如拿出50%训练数据
- 不要跟训练数据混在一起
- 测试数据集:只用一次的数据集(不能在这个上面调参),例如
- 未来的考试
- 出价的房子的实际成交价
- 用在Kaggle私有排行榜中的数据集
K折交叉验证
- 在没有足够多数据时使用(这是常态)
- 算法:
- 将训练数据分割成K块
- For i = 1 , 2 , … , K i =1, 2, \dots, K i=1,2,…,K
- 使用第 i i i块作为验证数据集,其余的作为训练数据集
- 报告K个验证集误差的平均
- 常用:K=5或10
总结
- 训练数据集:训练模型超参数
- 验证数据集:选择模型超参数
- 非大数据集上通常使用K折交叉验证
过拟合和欠拟合


注:
- 模型容量:模型复杂度,复杂的模型,可以学习更复杂的函数
- 数据:简单数据 & 复杂数据
- 根据数据集的复杂程度来选择对应的模型的容量
模型容量
- 拟合各种函数的能力
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记住所有的训练数据
- 模型容量的影响,如下图:
- 取泛化误差最小的模型容量
- 泛化误差和训练误差中间的gap通常用来衡量过拟合和欠拟合的程度
- 过拟合不是坏处,首先模型容量得足够大,然后通过各种手段控制模型容量,使得最后得到泛化误差的下降,这就是深度学习的核心。

估计模型容量
- 难以在不同种类算法之间比较
- 例如树模型和神经网络
- 给定一个模型种类,将有两个主要因素,如下图(d: x \bold x x维度,m: 隐藏层节点数,k: 输出个数):
- 参数的个数
- 参数值的选择范围

VC维
- 统计学习理论的一个核心思想
- 对于一个分类模型,VC等于一个最大的数据集的大小,不管如何给定标号(label),都存在一个模型来对它进行完美分类
- 线性分类器的VC维
- 2维输入感知机,VC维=3
- 能分类任何3个点,但4个不行(如XOR异或4个点的分类不可以)
- 支持N维输入的感知机的VC维是N+1
- 一些多层感知机的VC维: O ( N l o g 2 N ) O(Nlog_2N) O(Nlog2N)
- 2维输入感知机,VC维=3
- VC维的用处
- 提供为什么一个模型好的理论依据
- 它可以衡量训练误差和泛化误差之间的间隔
- 但深度学习中很少使用
- 衡量不是很准确
- 计算深度学习模型的VC维很困难
- 提供为什么一个模型好的理论依据
数据复杂度
- 多个重要因素
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性(多少类的分类)
总结
- 模型容量需要匹配数据复杂度,否则可能导致过拟合和欠拟合
- 统计机器学习提供数学工具来衡量模型复杂度
- 实际中一般靠观察训练误差和验证误差
其他知识点
- SVM主要是通过一个kernel来匹配模型复杂度,计算不容易,很难做到100w个数据量,数据不大(比如10w个数据)的话比较容易,数据大的话感知机通过梯度下降解比较容易;SVM的可调性也不是很行,可以调的东西不多
- 泛化误差实际上是测试误差,是只有一次的
- 用validation set来看是否overfitting
- 时序序列的数据,一般验证集的选取在训练集的后面,时间上必须验证集比训练集晚
- 实际操作中,如果能拿到验证集的数据,则训练集和验证集的数据最好统一做数据处理,拿不到就只做训练集
权重衰退
最常见的处理过拟合的方法;权重衰退是最广泛使用的正则化的技术之一。
使用均方范数作为硬性限制
 注:正则化可以使我们拟合的曲线更平滑
注:正则化可以使我们拟合的曲线更平滑 
使用均方范数作为柔性限制


注:降低模型复杂度,增加 λ \lambda λ的值即可
参数更新法则

总结
- 权重衰退通过L2正则项使得模型参数不会过大,从而控制模型复杂度
- 正则项权重是控制模型复杂度的超参数
其他知识点
- 权重衰减将最优解往回拉,一般因为训练的数据有噪音,所以往回拉是正确的,至于往回拉多少,要看 λ \lambda λ的值的设置
- weight decay的值一般是 1 0 − 2 , 1 0 − 3 , 1 0 − 4 10^{-2}, 10^{-3}, 10^{-4} 10−2,10−3,10−4
- 权重衰减调整什么时候得到最优,靠直觉,没有数学理论证明
丢弃法(dropout)
- 动机
- 一个好的模型需要对输入数据的扰动鲁棒
- 使用有噪音的数据等价于Tikhonov正则
- 丢弃法:在层之间加入噪音
- 一个好的模型需要对输入数据的扰动鲁棒
- 无偏差的加入噪音

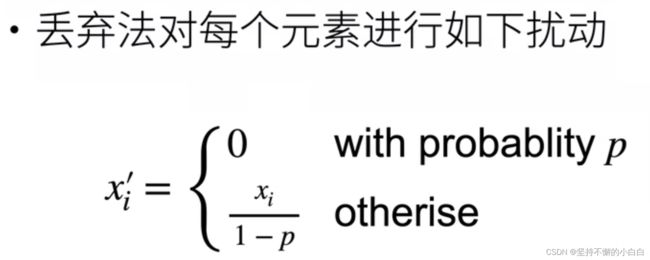
- 使用丢弃法
- 通常将丢弃法作用在隐藏全连接层的输出上

- 通常将丢弃法作用在隐藏全连接层的输出上
- 推理中的丢弃法
- 正则项只在训练中使用:他们影响模型参数的更新
- 在推理过程中,丢弃法直接返回输入(预测过程中的dropout还是直接输出 h \bold h h本身)
- h = d r o p o u t ( h ) \bold h=dropout(\bold h) h=dropout(h)
- 这样也能保证确定性的输出
注:
- dropout可以当作一个正则项(因为它的实验结果跟正则项的效果是一样的),在训练的时候使用,但是在推理(即预测)的时候不使用,因为预测时,权重不需要发生变化
- dropout是每次都随机置0,如果是固定的话,就相当于隐藏层变小了,没有意义
- 总结
- 丢弃法将一些输出项随机置0来控制模型复杂度(效果很可能比L2好一点点)
- 常作用在多层感知机的隐藏层输出上(很少用在CNN等模型上面)
- 丢弃概率是控制模型复杂度的超参数(最常见的取值:0.5,0.9,0.1)
- 其他知识点
- dropout如果想重复的话,将random seed固定,运行两次,每次丢弃的神经元应该相同;但是CUDNN加速出来的结果随机性很大,不可重复,因为CUDNN并行加速,每次数相加的顺序不一样,结果也不一样,所以如果想重复先前的训练,则需要禁掉CUDNN
- dropout是给全连接层用的,BN是给卷积层CNN用的
- 推理(预测)的时候开dropout会导致结果的随机性(可能不正确),多预测几次也是可以的
- dropout和regularization是两种不同的防止过拟合的方法,可以一起使用,也可以单独使用
- dropout更好调参一点,比较直观,权重衰退的 λ \lambda λ不是很好调
数值稳定性
当神经网络变得很深的时候,数值非常容易不稳定
-
神经网络的梯度

-
数值稳定性常见的两个问题
- 梯度爆炸:一个梯度大于1的数,100层的神经网络,100次方后会变得很大
- 梯度消失:一个梯度小于1的数,100次方后会变得很小
-
例子:MLP

-
梯度爆炸

注: -
d-t很大,也就是网络比较深
-
ReLU激活函数使激活后的值非0即1,所以有些 W i W^i Wi变0,有些维持原状
- 梯度爆炸的问题
- 值超出值域(infinity)
- 对16位浮点数尤为严重(数值区间: 6 e − 5 6 e 4 6e^{-5}~6e^4 6e−5 6e4)
- (在使用GPU时,通常会使用16位浮点数,现在好一点的GPU使用16位浮点数计算会比32位浮点数计算速度要快2倍)
- 对学习率 η \eta η敏感
- 学习率太大—>大参数值—>更大的梯度
- 学习率太小—>训练无进展
- 我们可能需要在训练过程中不断调整学习率
- 值超出值域(infinity)
- 梯度爆炸的问题
-
梯度消失


- 梯度消失的问题
- 梯度值变成0
- 对16位浮点数尤为严重
- 训练没有进展
- 不管如何选择学习率
- 对于底部层尤为严重(当神经网络比较深时)
- 仅仅顶部层训练的较好(越往下,梯度越小)
- 无法让神经网络更深
- 梯度值变成0
- 总结
- 当数值过大或者过小时会导致深度问题
- 常发生在深度模型中,因为其会对n个数累乘
模型初始化和激活函数
让训练更加稳定
- 目标:让梯度值在合理的范围内
- 例如: [ 1 e − 6 , 1 e 3 ] [1e^{-6}, 1e^3] [1e−6,1e3]
- 将乘法变加法
- ResNet,LSTM
- 归一化
- 梯度归一化,梯度裁剪
- 合理的权重初始和激活函数
让每层的方差是一个常数
- 将每层的输出和梯度都看作随机变量
- 让它们的均值和方差都保持一致

权重初始化
- 在合理的值区间里随机初始参数
- 训练开始的时候更容易有数值不稳定
- 远离最优解的地方损失函数表面可能很复杂
- 最优解附近表面会比较平
- 使用 N ( 0 , 0.01 ) N(0, 0.01) N(0,0.01)来初始化可能对小网络没问题,但不能保证深度神经网络
例子:MLP

正向方差

注:
- 均值为0,所以 E [ h i t ] 2 E[h_i^t]^2 E[hit]2=0;
- iid,所以相关性cov为0;
- 均值为0,所以将第三个等号后面的内容分别减去均值的平方(即0),得到各自方差var;
- 对j累加,相当于 n t − 1 n_{t-1} nt−1项两个方差的积相乘, w i , j t w_{i,j}^t wi,jt的方差前面假设了为 γ t \gamma_t γt;( n t − 1 n_{t-1} nt−1:第t层的输入的维度, n t n_t nt:第t层的输出的维度)
- 要想让每一层的方差都保持一致,则 n t − 1 γ t n_{t-1}\gamma_t nt−1γt=1。
反向均值和方差

Xavier初始

注:
- n t − 1 n_{t-1} nt−1:第t层的输入的维度, n t n_t nt:第t层的输出的维度;所以除非两者相等, n t − 1 γ t = 1 n_{t-1}\gamma_t=1 nt−1γt=1和 n t γ t = 1 n_t\gamma_t=1 ntγt=1不可能同时满足;
- Xavier方法解决这个问题,考虑对第t层初始化的时候,采用什么分布
假设线性的激活函数

注: E ( h i ′ ) E(h'_i) E(hi′)=0
反向传播时的情况

检查常用激活函数

总结
- 合理的权重初始值和激活函数的选取可以提升数值稳定性
其他知识点
- nan出现的原因:计算中除以0了;inf出现的原因:权重初始值太大或learning rate太大了
- 训练几个epoch之后,准确率降低的原因:权重坏掉了,变成了一些乱七八糟的值;可以将learning rate调小一点试试,或者更改激活函数,如果还不能解决问题,通常是因为模型的数据稳定性不行,很容易就跑歪了
- 一般出现nan,是梯度爆炸造成的
参考:
[1] 动手学深度学习PyTorch版B站李沐老师视频列表
[2] 动手学深度学习 (第二版)
[3] Datawhale组队学习