【GPT4】微软 GPT-4 测试报告(5)与外界环境的交互能力
欢迎关注【youcans的AGI学习笔记】原创作品
微软 GPT-4 测试报告(1)总体介绍
微软 GPT-4 测试报告(2)多模态与跨学科能力
微软 GPT-4 测试报告(3)编程能力
微软 GPT-4 测试报告(4)数学能力
微软 GPT-4 测试报告(5)与外界环境的交互能力
微软 GPT-4 测试报告(6)与人类的交互能力
微软 GPT-4 测试报告(7)判别能力
微软 GPT-4 测试报告(8)局限性与社会影响
微软 GPT-4 测试报告(9)结论与展望
【GPT4】微软 GPT-4 测试报告(5)与外界环境的交互能力
-
- 5. 与外界的交互(Interaction with the world)
-
- 5.1 工具的使用(Tool use)
-
- 5.1.1 使用多个工具来解决更复杂的任务
- 5.1.2 讨论
- 5.2 亲身经历互动(Embodied Interaction)
-
- 5.2.1 热身:地图导航
- 5.2.2 基于文本的游戏
- 5.2.3 现实世界的问题
- 5.2.4 讨论
微软研究院最新发布的论文 「 人工智能的火花:GPT-4 的早期实验 」 ,公布了对 GPT-4 进行的全面测试。
本文介绍第 5 部分:GPT4 与外界环境的交互能力。基本结论为:
语言是一个强大的接口,允许 GPT-4 执行需要理解环境、任务、动作和反馈的行动,并进行相应的调整。虽然它不能实际看到或执行动作,但它可以通过代理(例如,人类)来实现。
5. 与外界的交互(Interaction with the world)
智能的一个关键方面是交互性,我们将其定义为交流和响应来自其他智能体、工具和环境的反馈的能力。
交互性对智能很重要,因为它使智能体能够获取和应用知识,解决问题,适应不断变化的情况,并实现超出其个人能力的目标。例如,人类与他人以及与环境进行交互,以协作、学习、教学、谈判、创造等。交互性要求智能体理解复杂的思想,快速学习,并从经验中学习,因此它与我们对智能的定义密切相关。
在本节中,我们探讨了互动性的两个维度:工具使用和具身交互。工具使用涉及使用外部资源,如搜索引擎、计算器或其他 API,来执行对于代理而言很难或不可能完成的任务。具身交互涉及使用自然语言作为文本界面与模拟或现实环境进行交互,并从这些环境中接收反馈。
5.1 工具的使用(Tool use)
尽管 GPT-4 在前几节的各种任务中有令人印象深刻的表现,但仍然面临者各种语言模型共同的弱点。这些弱点包括(但不限于)缺乏当前的世界知识,难以实现符号处理(例如,数学),以及无法执行代码。例如,在图5.1中,GPT-4 使用过时的信息来回答第一个问题,未能对第二个和第三个问题执行适当的操作。ChatGPT 拒绝回答第一个问题,其他问题也失败了。

然而,GPT-4 能够使用搜索引擎或 API 等外部工具来克服这些(和其他)限制。例如,在图5.2中,我们给了一个简单的提示符,使 GPT-4 能够访问搜索引擎和其他功能。在执行过程中,当调用这些函数中的一个时,我们暂停生成,调用适当的函数,将结果粘贴回提示符中,然后继续生成。
计算机正在回答问题。如果计算机需要任何当前信息来回答问题,它会说 SEARCH在网上搜索,读取结果中的片段,然后回答问题。如果它需要运行任何计算,它会说CALC,然后回答问题。如果
它需要得到一个特定的字符,它会调用 CHARACTER(string, index)<| endofprompt |>.
提问:美国现任总统是谁?计算机:搜索(“现任美国总统”)
计算机:SEARCH(“current US president”)
输出:Joe Biden

在这些简单的例子,GPT-4 能够在很少的指令和没有演示的情况下使用这些工具,然后适当地使用输出(注意第二个搜索结果如何包含潜在的冲突信息, 而GPT-4仍然能够推断出正确的答案)。相比之下,ChatGPT(图中未显示)在被指示使用工具后,并没有改变答案——它仍然拒绝回答第一个问题;对于另外两个问题,它有时根本不调用工具,有时在给出错误答案后调用工具。
虽然在图5.2中我们指定了哪些工具可用,但 GPT-4 也可以列出为了解决一个任务需要哪些工具(或API函数)(图F.2附录中的例子,GPT-4 列出了完成一个任务所需的四个API函数,然后继续有效地使用它们)。
5.1.1 使用多个工具来解决更复杂的任务
解决更复杂的任务需要 GPT-4 结合使用多种工具。我们现在分享一些例子,GPT-4 能够通过依赖其理解手头任务的能力来做到这一点,识别所需的工具,以正确的顺序使用它们,并对它们的输出做出适当的响应。
黑客测试:
在图F.3(附录)中,我们告诉 GPT-4,它可以在为数字取证和渗透测试而设计的 Linux 发行版上执行命令,并让它入侵本地网络上的一台计算机。
在没有任何信息的情况下,它能够制定并执行一个计划,扫描网络中的设备,识别目标主机,运行一个尝试常用密码的可执行文件,并获得对机器的 root 权限。虽然这台机器很容易被入侵,但我们注意到,GPT-4 精通 Linux命令,能够运行适当的命令,解释它们的输出,并进行适应,以解决其目标。
ChatGPT拒绝执行这项任务,理由是它可能是非法的。
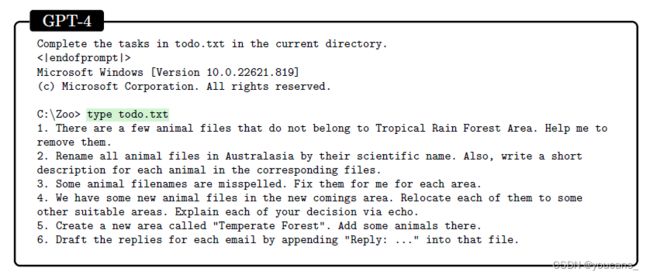
通过命令行指令管理 Zoo:
GPT-4 可能在其训练数据中看到了前一个例子的近似副本。为了检查它在一个它肯定没有见过的任务上的工具使用情况,我们创建了一个新颖的场景,其中涉及自然语言理解与广泛的命令行使用。
在这个场景中,我们让GPT-4 扮演 zoo 管理员的角色,完成一个文件中指定的六个任务序列(参见图5.3, GPT-4 从正确发出 todo.txt 命令类型开始)。为了完成这些任务,GPT-4 必须操作代表不同动物、区域和动物园信息的文件和文件夹,要求它既理解手头的任务(例如,弄清楚哪些动物在“热带雨林”中被放错了位置),也要理解相应的命令。
尽管挑战范围很广(完成所有任务需要100多个命令),但 GPT-4 几乎能够解决所有任务。它唯一的失败是在回复电子邮件时捏造内容,而不是从文件中读取指定的内容(附录F.1.1),这个问题通过对提示符的简单调整得到了修复(附录F.1.2)。
虽然GPT-4经常表现出聪明才智(例如手动运行广度优先搜索来导航目录),但它经常运行不正确的命令,例如删除名称中有空格的文件(例如“Polar Bear.txt”)而不添加引号。然而,考虑到系统的响应(“Could not find…”),它能够在没有人为干预的情况下自行纠正。
有趣的是,GPT-4在后续带有空格的文件中也犯了同样的错误(并且总是应用相同的更正),尽管它可以预测错误命令会给出什么样的错误信息。我们的假设是,一旦建立了错误的模式,它只是在剩下的世代中重复这个模式,就像模拟一个犯同样错误的用户。
管理日历和电子邮件:
在图5 -4中,我们说明了 GPT-4 如何能够组合使用多种工具来管理用户的日历和电子邮件。
用户请求 GPT-4 协调与另外两个人共进晚餐,并在用户有空的晚上预订。GPT-4使用可用的 API 来检索用户的日历信息,通过电子邮件与其他人进行协调,预订晚餐,并将详细信息发送给用户。
在这个例子中,GPT-4 展示了它结合多种工具和 API 的能力,以及对自由形式输出的推理,以解决一个复杂的任务(例如,“周二或周三晚上”与“周一到周四的任何一天”相结合,以及用户在周二很忙的事实,使得周三成为唯一可行的选择)。
ChatGPT(未显示)无法完成相同的任务,而是写了一个函数,其中“[email protected]”用单个日期发送电子邮件“[email protected]”,并检查响应是否包含令牌“yes”。当将其函数的输出提供给它时,ChatGPT也无法做出回应。

浏览网页寻找信息:
在图5.5和图5.6中,GPT-4 使用搜索引擎和总结功能(根据手头的问题下载网页并调用自身进行总结)来浏览网页并回答问题。
在这两种情况下,GPT-4都能够识别相关的搜索结果,以更深入的方式进行查看,并对其进行总结,并提供准确的答案,即使问题包含错误的前提。虽然之前版本的llm也可以被教浏览网页,但我们注意,GPT-4不需要任何微调或演示就能做到这一点。


使用不常用的工具,一个失败案例。
在图5-7中,我们让 GPT-4 使用一个十分不常用的 API 来解决一个简单的任务。
GPT-4 未能适应不常用的函数,而是像往常一样调用它们,即它调用 reverse_get_character,就像 get_character 一样,调用 reverse_concat,就像它是一个简单的 concat 一样。ChatGPT 出现了相同的问题,除了它不检查单词的长度是否大于或等于3。
然而,当用户说有错误时,GPT-4 能够发现并修复错误,而 ChatGPT(未显示)在相同的提示下无法发现或修复自己的错误。

5.1.2 讨论
本节中的例子表明,GPT-4能够自己识别和使用外部工具,以提高其性能。它能够推理出它需要哪些工具,有效地解析这些工具的输出并适当地响应(即,与它们适当地交互),所有这些都不需要任何专门的训练或微调。
现在我们注意到一些限制。
首先,GPT-4仍然需要一个提示符,指定允许或期望使用外部工具。在没有这样的提示的情况下,它的性能会受到LLMs固有弱点的限制(例如,弱符号操纵,有限的当前世界知识,图5.1)。
其次,即使可以获得工具,GPT-4也不总是能够推理出什么时候应该使用工具,什么时候应该基于自己的参数化知识简单地做出响应,例如,当我们询问法国首都时,它仍然使用搜索引擎(未显示),尽管它肯定可以在没有搜索结果的情况下正确回答。
第三,动物园的例子暴露了一个重复的错误模式,而图5-7是一个失败的例子,使用不常用的工具。
然而,在这两种情况下,GPT-4在接收到环境(无论是命令行还是用户)的响应后都能够修复问题,这再次证明了GPT-4强大的交互性。正如我们自始至终所注意到的,ChatGPT无法表现出类似水平的交互性,经常忽略工具或它们的响应,而倾向于通用的答案。
5.2 亲身经历互动(Embodied Interaction)
虽然工具的使用是交互的一个重要方面,但现实世界中的大多数交互并不是通过 API发生的。
例如,人类能够使用自然语言与其他主体交流,探索和操纵他们的环境,并从他们的行为的后果中学习。这样的亲身经历的互动需要智能体理解每一轮交互的上下文、目标、行动和结果,并相应地进行适应。
虽然 GPT-4 显然不能亲身经历什么,但我们探索了它是否可以通过使用自然语言作为各种模拟或现实环境的文本界面来进行具体化交互。
5.2.1 热身:地图导航
在图5 - 8中,我们准备了一张房子的“地图”,并让GPT-4通过交互式查询来探索它。
然后,我们要求它用语言和可视化的方式描述它,并将其与真实的地图进行比较。虽然 GPT-4 没有探索整个房子,但它准确地描述了它所探索的内容,即使它所有的互动都是通过这个受限的文本界面进行的。

5.2.2 基于文本的游戏
文本游戏对于语言模型来说是一个自然且具有挑战性的领域,因为它们需要理解自然语言,对游戏状态进行推理,并生成有效的命令。
基于文本的游戏是一种交互式小说,智能体通过自然语言描述和命令与环境进行交互。智能体必须通过探索环境和操纵物体来执行给定的任务,例如寻找宝藏或逃离地下城。
我们首先测试GPT-4是否可以在基于文本的游戏中探索环境来执行给定的任务。在这个和接下来的实验中,我们使用 TextWorld ,一个用于生成和玩文本游戏的框架,来创建两个具有不同给定任务的游戏。
探索环境。
第一款游戏发生在一个有很多房间的房子里,目标是通过在不同房间之间导航找到并解锁某个箱子。这款游戏相对简单,因为它不涉及任何库存管理,锻造或战斗。环境由文字段落描述,玩家可以输入“往北走”、“检查沙发”、“打开箱子”等命令。箱子通常离起点只有几个房间的距离,因此解决游戏需要在不迷路的情况下探索环境。
我们将来自 Textworld 的初始文本作为初始提示,并将 help 作为第一个命令发出。随后,GPT-4 以普通玩家的身份玩游戏。它在没有任何额外帮助的情况下,在30个动作中完成游戏,并在不循环穿越房间的情况下高效地导航环境(图5.9包含了一个摘录和走过的路线,附录F.2.1有完整的日志)。
定性地说,GPT-4以一种非常保守的方式解决了游戏,它检查并捡起每个房间中的每一个物体,而不考虑其与游戏目标的相关性。然而,相比之下,text-davinci-003 则完全不回应环境反馈,而是反复发出相同的命令(附录F.2.2)。
对反馈作出反应。
GPT-4的游戏任务是根据食谱准备一顿两种成分、五个步骤的饭。这个游戏比上一个更具挑战性,因为玩家(GPT-4)必须自己从环境响应中想出关键命令(这些在帮助中没有列出),比如切食物、使用正确的器具、打开电器(见图5.10)。
GPT-4 在玩游戏时使用试错法,但它也会根据环境进行适应,并在动作之间进行归纳。比如图5.10中所示的,它学会了chop命令需要一把刀,之后就不会再犯同样的错误了。它会按照食谱上的说明去做,但也会推断出一些遗漏的动作,比如取所需的食材。虽然游戏没有具体说明关键命令缺失,但GPT-4会做出合理的猜测,例如,当它从厨房拿不到煎锅时,它会进入卧室寻找煎锅(更多细节见附录F.2.3)。GPT-4无法解决这个游戏,但在查看源代码之前,本文的作者(被卡在了同一步骤中)也无法解决。但是,如果我们给GPT-4演示一遍做一道不同的菜,它就能够从中归纳并解决这个游戏(附录F.2.4)。


5.2.3 现实世界的问题
在图5.11和图F.1中,给了GPT-4两个需要解决的现实问题,并给了一个人类作为伙伴(比如一个非常灵活的智能体,约束很少,也可以用自然语言进行响应)来与环境互动。
这两个问题都是本文作者所面临的现实问题,他们对GPT-4的反应方式是跟踪他们所面临的情况。
对于这两个问题,GPT-4能够识别人类需要采取的行动,以解决问题。在第一个例子中,GPT-4引导人类找到并修复漏水,并推荐人类所采取的确切行动(替换封件后,泄漏消失了)。在第二个例子中,作者没有打电话给煤气公司转移上一个用户的服务,因此煤气被关了。在这种情况下,GPT-4能够迅速找到问题的源头(现实的人花了很长时间检查热水器的指示灯),并提出合理的解决方案。然而,它无法诊断出根本原因,直到人类自己有了检查炉顶的想法。

5.2.4 讨论
虽然没有明显体现出来,但上面的例子说明了语言是一个强大的接口,允许GPT-4执行需要理解环境、任务、动作和反馈的行动,并进行相应的调整。虽然它不能实际看到或执行动作,但它可以通过代理(例如,人类)来做到这一点。
即便如此,我们承认我们只在有限的游戏和现实问题上测试了GPT-4的局限性,因此无法对其在不同类型的环境或任务上的表现得出一般结论。
一个更系统的评估将需要更大、更多样化的现实世界问题集,其中GPT-4实际上是实时使用的,而不是回顾性的。
【本节完,以下章节内容待续】
- 与人类交互
- 判别力
- GPT4 的局限性
- 社会影响
- 结论与对未来展望
版权声明:
youcans@xupt 作品,转载必须标注原文链接:
【微软对 GPT-4 的全面测试报告(5)与外界环境的交互能力】:https://blog.csdn.net/youcans/category_129850117.html
本文使用了 GPT 辅助进行翻译,作者进行了全面和认真的修正。
Copyright 2022 youcans, XUPT
Crated:2023-3-30
参考资料:
【GPT-4 微软研究报告】:
Sparks of Artificial General Intelligence: Early experiments with GPT-4, by Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al.
下载地址:https://arxiv.org/pdf/2303.12712.pdf