Netty in Action -ChannelHandler和ChannelPipeline
本章主要内容
- Channel
- ChannelHandler
- ChannePipeline
- ChannelHandlerContext
我们在上一章研究的 bytebuf 是一个容器用来“包装”数据。在本章我们将探讨这些容器如何通过应用程序来移动,传入和传出,以及他们的内容是如何处理的。
Netty 提供了应用开发的数据处理方面的强大支持。我们已经看到了channelhandler 如何链接在一起 ChannelPipeline 使用结构处理更加灵活和模块化。
在这一章中,下面我们会遇到各种各样Channelhandler,ChannelPipeline的使用案例,以及重要的相关的类Channelhandlercontext 。我们将展示如何将这些基本组成的框架可以帮助我们写干净可重用的处理实现。
ChannelHandler 家族
在我们深入研究 Channelhandler 内部之前,让我们花几分钟了解下这个领域的 Netty 组件模型的基础。这里提供一个 Channelhandler 及其子类的研究有价值的背景。
Channel 生命周期
Channel 有个简单但强大的状态模型,与 ChannelInboundHandler API 密切相关。下面表格是 Channel 的四个状态
Table 6.1 Channel lifeycle states
| 状态 | 描述 |
|---|---|
| channelUnregistered | channel创建但未注册到一个 EventLoop. |
| channelRegistered | channel 注册到一个 EventLoop. |
| channelActive | channel 的活动的(连接到了它的 remote peer(远程对等方)),现在可以接收和发送数据了 |
| channelInactive | channel 没有连接到 remote peer(远程对等方) |
Channel 的正常的生命周期如下图,当这些状态变化出现,对应的事件将会生成,这样与 ChannelPipeline 中的 ChannelHandler 的交互就能及时响应
Figure 6.1 Channel State Model

ChannelHandler 生命周期
ChannelHandler 定义的生命周期操作如下表,当 ChannelHandler 添加到 ChannelPipeline,或者从 ChannelPipeline 移除后,这些将会调用。每个方法都会带 ChannelHandlerContext 参数
Table 6.2 ChannelHandler lifecycle methods
| 类型 | 描述 |
|---|---|
| handlerAdded | 当 ChannelHandler 添加到 ChannelPipeline 调用 |
| handlerRemoved | 当 ChannelHandler 从 ChannelPipeline 移除时调用 |
| exceptionCaught | 当 ChannelPipeline 执行发生错误时调用 |
ChannelHandler 子接口
Netty 提供2个重要的 ChannelHandler 子接口:
- ChannelInboundHandler - 处理进站数据,并且所有状态都更改
- ChannelOutboundHandler - 处理出站数据,允许拦截各种操作
ChannelHandler 适配器
Netty 提供了一个简单的 ChannelHandler 框架实现,给所有声明方法签名。这个类 ChannelHandlerAdapter 的方法,主要推送事件 到 pipeline 下个 ChannelHandler 直到 pipeline 的结束。这个类 也作为 ChannelInboundHandlerAdapter 和ChannelOutboundHandlerAdapter 的基础。所有三个适配器类的目的是作为自己的实现的起点;您可以扩展它们,覆盖你需要自定义的方法。
ChannelInboundHandler
ChannelInboundHandler 的生命周期方法在下表中,当接收到数据或者与之关联的 Channel 状态改变时调用。之前已经注意到了,这些方法与 Channel 的生命周期接近
Table 6.3 ChannelInboundHandler methods
| 类型 | 描述 |
|---|---|
| channelRegistered | Invoked when a Channel is registered to its EventLoop and is able to handle I/O. |
| channelUnregistered | Invoked when a Channel is deregistered from its EventLoop and cannot handle any I/O. |
| channelActive | Invoked when a Channel is active; the Channel is connected/bound and ready. |
| channelInactive | Invoked when a Channel leaves active state and is no longer connected to its remote peer. |
| channelReadComplete | Invoked when a read operation on the Channel has completed. |
| channelRead | Invoked if data are read from the Channel. |
| channelWritabilityChanged | Invoked when the writability state of the Channel changes. The user can ensure writes are not done too fast (with risk of an OutOfMemoryError) or can resume writes when the Channel becomes writable again.Channel.isWritable() can be used to detect the actual writability of the channel. The threshold for writability can be set via Channel.config().setWriteHighWaterMark() and Channel.config().setWriteLowWaterMark(). |
| userEventTriggered(...) | Invoked when a user calls Channel.fireUserEventTriggered(...) to pass a pojo through the ChannelPipeline. This can be used to pass user specific events through the ChannelPipeline and so allow handling those events. |
注意,ChannelInboundHandler 实现覆盖了 channelRead() 方法处理进来的数据用来响应释放资源。Netty 在 ByteBuf 上使用了资源池,所以当执行释放资源时可以减少内存的消耗。
Listing 6.1 Handler to discard data
@ChannelHandler.Sharable
public class DiscardHandler extends ChannelInboundHandlerAdapter { //1
@Override
public void channelRead(ChannelHandlerContext ctx,
Object msg) {
ReferenceCountUtil.release(msg); //2
}
}
1.扩展 ChannelInboundHandlerAdapter
2.ReferenceCountUtil.release() 来丢弃收到的信息
Netty 用一个 WARN-level 日志条目记录未释放的资源,使其能相当简单地找到代码中的违规实例。然而,由于手工管理资源会很繁琐,您可以通过使用 SimpleChannelInboundHandler 简化问题。如下:
Listing 6.2 Handler to discard data
@ChannelHandler.Sharable
public class SimpleDiscardHandler extends SimpleChannelInboundHandler { //1
@Override
public void channelRead0(ChannelHandlerContext ctx,
Object msg) {
// No need to do anything special //2
}
}
1.扩展 SimpleChannelInboundHandler
2.不需做特别的释放资源的动作
注意 SimpleChannelInboundHandler 会自动释放资源,而无需存储任何信息的引用。
更多详见 “Error! Reference source not found..” 一节
ChannelOutboundHandler
ChannelOutboundHandler 提供了出站操作时调用的方法。这些方法会被 Channel, ChannelPipeline, 和 ChannelHandlerContext 调用。
ChannelOutboundHandler 另个一个强大的方面是它具有在请求时延迟操作或者事件的能力。比如,当你在写数据到 remote peer 的过程中被意外暂停,你可以延迟执行刷新操作,然后在迟些时候继续。
下面显示了 ChannelOutboundHandler 的方法(继承自 ChannelHandler 未列出来)
Table 6.4 ChannelOutboundHandler methods
| 类型 | 描述 |
|---|---|
| bind | Invoked on request to bind the Channel to a local address |
| connect | Invoked on request to connect the Channel to the remote peer |
| disconnect | Invoked on request to disconnect the Channel from the remote peer |
| close | Invoked on request to close the Channel |
| deregister | Invoked on request to deregister the Channel from its EventLoop |
| read | Invoked on request to read more data from the Channel |
| flush | Invoked on request to flush queued data to the remote peer through the Channel |
| write | Invoked on request to write data through the Channel to the remote peer |
几乎所有的方法都将 ChannelPromise 作为参数,一旦请求结束要通过 ChannelPipeline 转发的时候,必须通知此参数。
ChannelPromise vs. ChannelFuture
ChannelPromise 是 特殊的 ChannelFuture,允许你的 ChannelPromise 及其 操作 成功或失败。所以任何时候调用例如 Channel.write(...) 一个新的 ChannelPromise将会创建并且通过 ChannelPipeline传递。这次写操作本身将会返回 ChannelFuture, 这样只允许你得到一次操作完成的通知。Netty 本身使用 ChannelPromise 作为返回的 ChannelFuture 的通知,事实上在大多数时候就是 ChannelPromise 自身(ChannelPromise 扩展了 ChannelFuture)
如前所述,ChannelOutboundHandlerAdapter 提供了一个实现了 ChannelOutboundHandler 所有基本方法的实现的框架。 这些简单事件转发到下一个 ChannelOutboundHandler 管道通过调用 ChannelHandlerContext 相关的等效方法。你可以根据需要自己实现想要的方法。
资源管理
当你通过 ChannelInboundHandler.channelRead(...) 或者 ChannelOutboundHandler.write(...) 来处理数据,重要的是在处理资源时要确保资源不要泄漏。
Netty 使用引用计数器来处理池化的 ByteBuf。所以当 ByteBuf 完全处理后,要确保引用计数器被调整。
引用计数的权衡之一是用户时必须小心使用消息。当 JVM 仍在 GC(不知道有这样的消息引用计数)这个消息,以至于可能是之前获得的这个消息不会被放回池中。因此很可能,如果你不小心释放这些消息,很可能会耗尽资源。
为了让用户更加简单的找到遗漏的释放,Netty 包含了一个 ResourceLeakDetector ,将会从已分配的缓冲区 1% 作为样品来检查是否存在在应用程序泄漏。因为 1% 的抽样,开销很小。
对于检测泄漏,您将看到类似于下面的日志消息。
LEAK: ByteBuf.release() was not called before it’s garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced
leak reporting, specify the JVM option ’-Dio.netty.leakDetectionLevel=advanced’ or call ResourceLeakDetector.setLevel()
Relaunch your application with the JVM option mentioned above, then you’ll see the recent locations of your application where the leaked buffer was accessed. The following output shows a leak from our unit test (XmlFrameDecoderTest.testDecodeWithXml()):
Running io.netty.handler.codec.xml.XmlFrameDecoderTest
15:03:36.886 [main] ERROR io.netty.util.ResourceLeakDetector - LEAK:
ByteBuf.release() was not called before it’s garbage-collected.
Recent access records: 1
#1:
io.netty.buffer.AdvancedLeakAwareByteBuf.toString(AdvancedLeakAwareByteBuf.java:697)
io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithXml(XmlFrameDecoderTest.java:157)
io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithTwoMessages(XmlFrameDecoderTest.java:133)
泄漏检测等级
Netty 现在定义了四种泄漏检测等级,可以按需开启,见下表
Table 6.5 Leak detection levels
| Level Description | DISABLED |
|---|---|
| Disables | Leak detection completely. While this even eliminates the 1 % overhead you should only do this after extensive testing. |
| SIMPLE | Tells if a leak was found or not. Again uses the sampling rate of 1%, the default level and a good fit for most cases. |
| ADVANCED | Tells if a leak was found and where the message was accessed, using the sampling rate of 1%. |
| PARANOID | Same as level ADVANCED with the main difference that every access is sampled. This it has a massive impact on performance. Use this only in the debugging phase. |
修改检测等级,只需修改 io.netty.leakDetectionLevel 系统属性,举例
# java -Dio.netty.leakDetectionLevel=paranoid
这样,我们就能在 ChannelInboundHandler.channelRead(...) 和 ChannelOutboundHandler.write(...) 避免泄漏。
当你处理 channelRead(...) 操作,并在消费消息(不是通过 ChannelHandlerContext.fireChannelRead(...) 来传递它到下个 ChannelInboundHandler) 时,要释放它,如下:
Listing 6.3 Handler that consume inbound data
@ChannelHandler.Sharable
public class DiscardInboundHandler extends ChannelInboundHandlerAdapter { //1
@Override
public void channelRead(ChannelHandlerContext ctx,
Object msg) {
ReferenceCountUtil.release(msg); //2
}
}
- 继承 ChannelInboundHandlerAdapter
- 使用 ReferenceCountUtil.release(...) 来释放资源
所以记得,每次处理消息时,都要释放它。
SimpleChannelInboundHandler -消费入站消息更容易
使用入站数据和释放它是一项常见的任务,Netty 为你提供了一个特殊的称为 SimpleChannelInboundHandler 的 ChannelInboundHandler 的实现。该实现将自动释放一个消息,一旦这个消息被用户通过channelRead0() 方法消费。
当你在处理写操作,并丢弃消息时,你需要释放它。现在让我们看下实际是如何操作的。
Listing 6.4 Handler to discard outbound data
@ChannelHandler.Sharable public class DiscardOutboundHandler extends ChannelOutboundHandlerAdapter { //1
@Override
public void write(ChannelHandlerContext ctx,
Object msg, ChannelPromise promise) {
ReferenceCountUtil.release(msg); //2
promise.setSuccess(); //3
}
}
- 继承 ChannelOutboundHandlerAdapter
- 使用 ReferenceCountUtil.release(...) 来释放资源
- 通知 ChannelPromise 数据已经被处理
重要的是,释放资源并通知 ChannelPromise。如果,ChannelPromise 没有被通知到,这可能会引发 ChannelFutureListener 不会被处理的消息通知的状况。
所以,总结下:如果消息是被 消耗/丢弃 并不会被传入下个 ChannelPipeline 的 ChannelOutboundHandler ,调用 ReferenceCountUtil.release(message) 。一旦消息经过实际的传输,在消息被写或者 Channel 关闭时,它将会自动释放。
ChannelPipeline
如果我们认为 ChannelPipeline 只是一系列 ChannelHandler 实例,用于拦截 流经一个 Channel 的入站和出站事件,然后很容易理解这些 ChannelHandler 可以提供的交互的核心应用程序的数据和事件处理逻辑。
每一个创建新 Channel ,分配一个新的 ChannelPipeline。这个关联是永久性的;Channel 既不能附上另一个 ChannelPipeline 也不能分离当前这个。这是一个 Netty 的固定方面的组件生命周期,开发人员无需特别处理。
根据它的起源,一个事件将由 ChannelInboundHandler 或ChannelOutboundHandler 处理。随后它将调用 ChannelHandlerContext 实现转发到下一个相同的超类型的处理程序。
ChannelHandlerContext
一个 ChannelHandlerContext 使 ChannelHandler 与 ChannelPipeline 和其他处理程序交互。一个处理程序可以通知下一个 ChannelPipeline 中的 ChannelHandler 甚至动态修改 ChannelPipeline 的归属。
下图展示了用于入站和出站 ChannelHandler 的 典型 ChannelPipeline 布局。

Figure 6.2 ChannelPipeline and ChannelHandlers
上图说明了 ChannelPipeline 主要是一系列 ChannelHandler。通过ChannelPipeline ChannelPipeline 还提供了方法传播事件本身。如果一个入站事件被触发,它将被传递的从 ChannelPipeline 开始到结束。举个例子,在这个图中出站 I/O 事件将从 ChannelPipeline 右端开始一直处理到左边。
ChannelPipeline 相对论
你可能会说,从 ChannelPipeline 事件传递的角度来看,ChannelPipeline 的“开始” 取决于是否入站或出站事件。然而,Netty 总是指 ChannelPipeline 入站口(图中的左边)为“开始”,出站口(右边)作为“结束”。当我们完成使用 ChannelPipeline.add() 添加混合入站和出站处理程序,每个 ChannelHandler 的“顺序”是它的地位从“开始”到“结束”正如我们刚才定义的。因此,如果我们在图6.1处理程序按顺序从左到右第一个ChannelHandler被一个入站事件将是#1,第一个处理程序被出站事件将是#5*
随着管道传播事件,它决定下个 ChannelHandler 是否是相匹配的方向运动的类型。如果没有,ChannelPipeline 跳过 ChannelHandler 并继续下一个合适的方向。记住,一个处理程序可能同时实现ChannelInboundHandler 和 ChannelOutboundHandler 接口。
修改 ChannelPipeline
ChannelHandler 可以实时修改 ChannelPipeline 的布局,通过添加、移除、替换其他 ChannelHandler(也可以从 ChannelPipeline 移除 ChannelHandler 自身)。这个 是 ChannelHandler 重要的功能之一。
Table 6.6 ChannelHandler methods for modifying a ChannelPipeline
| 名称 | 描述 |
|---|---|
| addFirst addBefore addAfter addLast | 添加 ChannelHandler 到 ChannelPipeline. |
| Remove | 从 ChannelPipeline 移除 ChannelHandler. |
| Replace | 在 ChannelPipeline 替换另外一个 ChannelHandler |
下面展示了操作
Listing 6.5 Modify the ChannelPipeline
ChannelPipeline pipeline = null; // get reference to pipeline;
FirstHandler firstHandler = new FirstHandler(); //1
pipeline.addLast("handler1", firstHandler); //2
pipeline.addFirst("handler2", new SecondHandler()); //3
pipeline.addLast("handler3", new ThirdHandler()); //4
pipeline.remove("handler3"); //5
pipeline.remove(firstHandler); //6
pipeline.replace("handler2", "handler4", new ForthHandler()); //6
- 创建一个 FirstHandler 实例
- 添加该实例作为 "handler1" 到 ChannelPipeline
- 添加 SecondHandler 实例作为 "handler2" 到 ChannelPipeline 的第一个槽,这意味着它将替换之前已经存在的 "handler1"
- 添加 ThirdHandler 实例作为"handler3" 到 ChannelPipeline 的最后一个槽
- 通过名称移除 "handler3"
- 通过引用移除 FirstHandler (因为只有一个,所以可以不用关联名字 "handler1").
- 将作为"handler2"的 SecondHandler 实例替换为作为 "handler4"的 FourthHandler
以后我们将看到,这种轻松添加、移除和替换 ChannelHandler 能力,适合非常灵活的实现逻辑。
ChannelHandler 执行 ChannelPipeline 和阻塞
通常每个 ChannelHandler 添加到 ChannelPipeline 将处理事件传递到 EventLoop( I/O 的线程)。至关重要的是不要阻塞这个线程,它将会负面影响的整体处理I/O。有时可能需要使用阻塞 api 接口来处理遗留代码。对于这个情况下,ChannelPipeline 已有 add() 方法,它接受一个EventExecutorGroup。如果一个定制的EventExecutorGroup 传入事件将由含在这个 EventExecutorGroup 中的 EventExecutor之一来处理,并且从 Channel 的 EventLoop本身离开。一个默认实现,称为来自 Netty 的 DefaultEventExecutorGroup
除了上述操作,其他访问 ChannelHandler 的方法如下:
Table 6.7 ChannelPipeline operations for retrieving ChannelHandlers
| 名称 | 描述 |
|---|---|
| get(...) | Return a ChannelHandler by type or name |
| context(...) | Return the ChannelHandlerContext bound to a ChannelHandler. |
| names() iterator() | Return the names or of all the ChannelHander in the ChannelPipeline. |
发送事件
ChannelPipeline API 有额外调用入站和出站操作的方法。下表列出了入站操作,用于通知 ChannelPipeline 中 ChannelInboundHandlers 正在发生的事件
Table 6.8 Inbound operations on ChannelPipeline
| 名称 | 描述 |
|---|---|
| fireChannelRegistered | Calls channelRegistered(ChannelHandlerContext) on the next |
ChannelInboundHandler in the ChannelPipeline.fireChannelUnregistered | Calls channelUnregistered(ChannelHandlerContext) on the nextChannelInboundHandler in the ChannelPipeline.fireChannelActive | Calls channelActive(ChannelHandlerContext) on the nextChannelInboundHandler in the ChannelPipeline.fireChannelInactive | Calls channelInactive(ChannelHandlerContext)on the nextChannelInboundHandler in the ChannelPipeline.fireExceptionCaught | Calls exceptionCaught(ChannelHandlerContext, Throwable) on thenext ChannelHandler in the ChannelPipeline.fireUserEventTriggered | Calls userEventTriggered(ChannelHandlerContext, Object) on thenext ChannelInboundHandler in the ChannelPipeline.fireChannelRead | Calls channelRead(ChannelHandlerContext, Object msg) on the nextChannelInboundHandler in the ChannelPipeline.fireChannelReadComplete | Calls channelReadComplete(ChannelHandlerContext) on the nextChannelStateHandler in the ChannelPipeline.
在出站方面,处理一个事件将导致底层套接字的一些行动。下表列出了ChannelPipeline API 出站的操作。
Table 6.9 Outbound operations on ChannelPipeline
| 名称 | 描述 |
|---|---|
| bind | Bind the Channel to a local address. This will call |
bind(ChannelHandlerContext, SocketAddress, ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline.connect | Connect the Channel to a remote address. This will call connect(ChannelHandlerContext, SocketAddress,ChannelPromise) on the next ChannelOutboundHandler in theChannelPipeline.disconnect | Disconnect the Channel. This will calldisconnect(ChannelHandlerContext, ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline.close | Close the Channel. This will call close(ChannelHandlerContext,ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline.deregister | Deregister the Channel from the previously assigned EventExecutor (the EventLoop). This will call deregister(ChannelHandlerContext,ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline.flush | Flush all pending writes of the Channel. This will call flush(ChannelHandlerContext) on the next ChannelOutboundHandler in the ChannelPipeline.write | Write a message to the Channel. This will callwrite(ChannelHandlerContext, Object msg, ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline.Note: this does not write the message to the underlying Socket, but only queues it. To write it to the Socket call flush() or writeAndFlush().writeAndFlush | Convenience method for calling write() then flush().read | Requests to read more data from the Channel. This will call read(ChannelHandlerContext) on the next ChannelOutboundHandler in the ChannelPipeline.
总结下:
- 一个 ChannelPipeline 是用来保存关联到一个 Channel 的ChannelHandler
- 可以修改 ChannelPipeline 通过动态添加和删除 ChannelHandler
- ChannelPipeline 有着丰富的API调用动作来回应入站和出站事件。
ChannelHandlerContext
接口 ChannelHandlerContext 代表 ChannelHandler 和ChannelPipeline 之间的关联,并在 ChannelHandler 添加到 ChannelPipeline 时创建一个实例。ChannelHandlerContext 的主要功能是管理通过同一个 ChannelPipeline 关联的 ChannelHandler 之间的交互。
ChannelHandlerContext 有许多方法,其中一些也出现在 Channel 和ChannelPipeline 本身。然而,如果您通过Channel 或ChannelPipeline 的实例来调用这些方法,他们就会在整个 pipeline中传播 。相比之下,一样的的方法在 ChannelHandlerContext的实例上调用, 就只会从当前的 ChannelHandler 开始并传播到相关管道中的下一个有处理事件能力的 ChannelHandler 。
ChannelHandlerContext API 总结如下:
Table 6.10 ChannelHandlerContext API
| 名称 | 描述 |
|---|---|
| bind | Request to bind to the given SocketAddress and return a ChannelFuture. |
| channel | Return the Channel which is bound to this instance. |
| close | Request to close the Channel and return a ChannelFuture. |
| connect | Request to connect to the given SocketAddress and return a ChannelFuture. |
| deregister | Request to deregister from the previously assigned EventExecutor and return a ChannelFuture. |
| disconnect | Request to disconnect from the remote peer and return a ChannelFuture. |
| executor | Return the EventExecutor that dispatches events. |
| fireChannelActive | A Channel is active (connected). |
| fireChannelInactive | A Channel is inactive (closed). |
| fireChannelRead | A Channel received a message. |
| fireChannelReadComplete | Triggers a channelWritabilityChanged event to the next |
ChannelInboundHandler.handler | Returns the ChannelHandler bound to this instance.isRemoved | Returns true if the associated ChannelHandler was removed from the ChannelPipeline.name | Returns the unique name of this instance.pipeline | Returns the associated ChannelPipeline.read | Request to read data from the Channel into the first inbound buffer. Triggers a channelRead event if successful and notifies the handler of channelReadComplete.write | Request to write a message via this instance through the pipeline.
其他注意注意事项:
- ChannelHandlerContext 与 ChannelHandler 的关联从不改变,所以缓存它的引用是安全的。
- 正如我们前面指出的,ChannelHandlerContext 所包含的事件流比其他类中同样的方法都要短,利用这一点可以尽可能高地提高性能。
使用 ChannelHandler
本节,我们将说明 ChannelHandlerContext的用法 ,以及ChannelHandlerContext, Channel 和 ChannelPipeline 这些类中方法的不同表现。下图展示了 ChannelPipeline, Channel,ChannelHandler 和 ChannelHandlerContext 的关系

- Channel 绑定到 ChannelPipeline
- ChannelPipeline 绑定到 包含 ChannelHandler 的 Channel
- ChannelHandler
- 当添加 ChannelHandler 到 ChannelPipeline 时,ChannelHandlerContext 被创建
Figure 6.3 Channel, ChannelPipeline, ChannelHandler and ChannelHandlerContext
下面展示了, 从 ChannelHandlerContext 获取到 Channel 的引用,通过调用 Channel 上的 write() 方法来触发一个 写事件到通过管道的的流中
Listing 6.6 Accessing the Channel from a ChannelHandlerContext
ChannelHandlerContext ctx = context;
Channel channel = ctx.channel(); //1
channel.write(Unpooled.copiedBuffer("Netty in Action",
CharsetUtil.UTF_8)); //2
- 得到与 ChannelHandlerContext 关联的 Channel 的引用
- 通过 Channel 写缓存
下面展示了 从 ChannelHandlerContext 获取到 ChannelPipeline 的相同示例
Listing 6.7 Accessing the ChannelPipeline from a ChannelHandlerContext
ChannelHandlerContext ctx = context;
ChannelPipeline pipeline = ctx.pipeline(); //1
pipeline.write(Unpooled.copiedBuffer("Netty in Action", CharsetUtil.UTF_8)); //2
- 得到与 ChannelHandlerContext 关联的 ChannelPipeline 的引用
- 通过 ChannelPipeline 写缓冲区
流在两个清单6.6和6.7是一样的,如图6.4所示。重要的是要注意,虽然在 Channel 或者 ChannelPipeline 上调用write() 都会把事件在整个管道传播,但是在 ChannelHandler 级别上,从一个处理程序转到下一个却要通过在 ChannelHandlerContext 调用方法实现。

- 事件传递给 ChannelPipeline 的第一个 ChannelHandler
- ChannelHandler 通过关联的 ChannelHandlerContext 传递事件给 ChannelPipeline 中的 下一个
- ChannelHandler 通过关联的 ChannelHandlerContext 传递事件给 ChannelPipeline 中的 下一个
Figure 6.4 Event propagation via the Channel or the ChannelPipeline
为什么你可能会想从 ChannelPipeline 一个特定的点开始传播一个事件?
- 通过减少 ChannelHandler 不感兴趣的事件的传递,从而减少开销
- 排除掉特定的对此事件感兴趣的处理程序的处理
想要实现从一个特定的 ChannelHandler 开始处理,你必须引用与 此ChannelHandler的前一个ChannelHandler 关联的 ChannelHandlerContext 。这个ChannelHandlerContext 将会调用与自身关联的 ChannelHandler 的下一个ChannelHandler 。
下面展示了使用场景
Listing 6.8 Events via ChannelPipeline
ChannelHandlerContext ctx = context;
ctx.write(Unpooled.copiedBuffer("Netty in Action", CharsetUtil.UTF_8));
- 获得 ChannelHandlerContext 的引用
- write() 将会把缓冲区发送到下一个 ChannelHandler
如下所示,消息将会从下一个ChannelHandler开始流过 ChannelPipeline ,绕过所有在它之前的ChannelHandler。

- ChannelHandlerContext 方法调用
- 事件发送到了下一个 ChannelHandler
- 经过最后一个ChannelHandler后,事件从 ChannelPipeline 移除
Figure 6.5 Event flow for operations triggered via the ChannelHandlerContext
我们刚刚描述的用例是一种常见的情形,当我们想要调用某个特定的 ChannelHandler操作时,它尤其有用。
ChannelHandler 和 ChannelHandlerContext 的高级用法
正如我们在清单6.6中看到的,通过调用ChannelHandlerContext的 pipeline() 方法,你可以得到一个封闭的 ChannelPipeline 引用。这使得可以在运行时操作 pipeline 的 ChannelHandler ,这一点可以被利用来实现一些复杂的需求,例如,添加一个 ChannelHandler 到 pipeline 来支持动态协议改变。
其他高级用例可以实现通过保持一个 ChannelHandlerContext 引用供以后使用,这可能发生在任何 ChannelHandler 方法,甚至来自不同的线程。清单6.9显示了此模式被用来触发一个事件。
Listing 6.9 ChannelHandlerContext usage
public class WriteHandler extends ChannelHandlerAdapter {
private ChannelHandlerContext ctx;
@Override
public void handlerAdded(ChannelHandlerContext ctx) {
this.ctx = ctx; //1
}
public void send(String msg) {
ctx.writeAndFlush(msg); //2
}
}
- 存储 ChannelHandlerContext 的引用供以后使用
- 使用之前存储的 ChannelHandlerContext 来发送消息
因为 ChannelHandler 可以属于多个 ChannelPipeline ,它可以绑定多个 ChannelHandlerContext 实例。然而,ChannelHandler 用于这种用法必须添加 @Sharable 注解。否则,试图将它添加到多个ChannelPipeline 将引发一个异常。此外,它必须既是线程安全的又能安全地使用多个同时的通道(比如,连接)。
清单6.10显示了此模式的正确实现。
Listing 6.10 A shareable ChannelHandler
@ChannelHandler.Sharable //1
public class SharableHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println("channel read message " + msg);
ctx.fireChannelRead(msg); //2
}
}
- 添加 @Sharable 注解
- 日志方法调用, 并专递到下一个 ChannelHandler
上面这个 ChannelHandler 实现符合所有包含在多个管道的要求;它通过@Sharable 注解,并不持有任何状态。而下面清单6.11中列出的情况则恰恰相反,它会造成问题。
Listing 6.11 Invalid usage of @Sharable
@ChannelHandler.Sharable //1
public class NotSharableHandler extends ChannelInboundHandlerAdapter {
private int count;
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
count++; //2
System.out.println("inboundBufferUpdated(...) called the "
+ count + " time"); //3
ctx.fireChannelRead(msg);
}
}
- 添加 @Sharable
- count 字段递增
- 日志方法调用, 并专递到下一个 ChannelHandler
这段代码的问题是它持有状态:一个实例变量保持了方法调用的计数。将这个类的一个实例添加到 ChannelPipeline 并发访问通道时很可能产生错误。(当然,这个简单的例子中可以通过在 channelRead() 上添加 synchronized 来纠正 )
总之,使用@Sharable的话,要确定 ChannelHandler 是线程安全的。
为什么共享 ChannelHandler
常见原因是要在多个 ChannelPipelines 上安装一个 ChannelHandler 以此来实现跨多个渠道收集统计数据的目的。
我们的讨论 ChannelHandlerContext 及与其他框架组件关系的 到此结束。接下来我们将解析 Channel 状态模型,准备仔细看看ChannelHandler 本身。
转载自:Netty in Action 《Netty 实战(精髓)》
===================================
对上面的文档做一个解读和补充:
首先,我们提出2个问题:
1、怎么在CannelHandler中完成一个通道写操作?
2、怎么确定CannelHandler在ChannelPipeline的顺序?
在CannelHandler中完成一个通道写操作
一个很常见的场景是,服务端接收到客户端发送来的数据,触发了ChannelHandler的通道读事件(ChannelInboundHandler的channelRead()方法或者ChannelOutboundHandler的read()方法),在读完数据并进行处理后,这时我们想返回某个数据给客户端作为响应要怎么做呢?
这时就需要一个通道写操作。更常见的方案是在一个ChannelOutboundChannel中做通道写操作。
如前面的文档所说,在ChannelHandler中做通道写操作有三种方式:
1、得到与ChannelHandlerContext关联的Channel的引用,通过Channel写缓存。
ChannelHandlerContext ctx = context;
Channel channel = ctx.channel();
channel.write(unpooled.copiedbuffer(""));
2、得到与ChannelHandlerContext关联的ChannelPipeline的引用,通过ChannelPipeline写缓存。
ChannelHandlerContext ctx = context;
ChannelPipeline pipeline = ctx.pipeline();
pipeline.write(unpooled.copiedbuffer(""));
3、直接使用ChannelHandlerConext,通过ChannelHandlerContext写缓存。
ChannelHandlerContext ctx = context;
ctx.write(unpooled.copiedbuffer(""));
三种方式的比较如上所述。
下面以dubbo为例,介绍它在哪里完成通道写操作
另外,上面还说到一种高级用法,就是存储ChannelHandlerConext的引用供以后使用。
在dubbo框架的netty4模块中,就有类似的用法,不过不是存储ChannelHandlerContext,而是存储channel.
public class NettyServerHandler extends ChannelDuplexHandler {
private final Map channels = new ConcurrentHashMap(); //
private final URL url;
private final ChannelHandler handler;
public NettyServerHandler(URL url, ChannelHandler handler) {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
if (handler == null) {
throw new IllegalArgumentException("handler == null");
}
this.url = url;
this.handler = handler;
}
public Map getChannels() {
return channels;
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelActive();
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
try {
if (channel != null) {
channels.put(NetUtils.toAddressString((InetSocketAddress) ctx.channel().remoteAddress()), channel);
}
handler.connected(channel);
} finally {
NettyChannel.removeChannelIfDisconnected(ctx.channel());
}
}
..............................
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
try {
handler.received(channel, msg);
} finally {
NettyChannel.removeChannelIfDisconnected(ctx.channel());
}
}
.............................
} 那么,dubbo的服务端是在哪里进行通道写操作呢?
首先,我们要知道,NettyServerHandler封装了DecodeHandler->HeaderExchangeHandler->DubboProtocol.requestHandler,
在HeaderExchangeHandler.received中的代码,在handleRequest之后,调用channel.send把Response发送到客户端,这个channel封装客户端-服务端通信链路,最终会调用Netty框架,把响应写回到客户端。
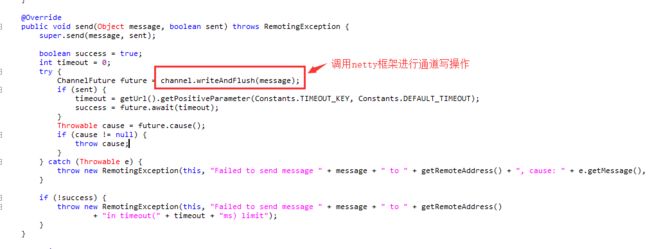
参考:dubbo源码浅析-远程服务调用流程
第二个问题:
确定ChannelHandler在Channelpipeline中的顺序
在netty3中
下行事件的事件处理器调用顺序是从后到前,即后添加的处理器先执行。
上行事件处理器调用顺序是从前到后执行,即先添加的处理器先执行。
所以,一般而言,添加业务handler放在最后一句addLast()添加。
以dubbo为例
框架在创建NettyServer时,也会创建netty框架的IO事件处理器链:NettyCodecAdapter.decoder->NettyCodecAdapter.encoder->NettyHandler
com.alibaba.dubbo.remoting.transport.netty.NettyServer.doOpen() 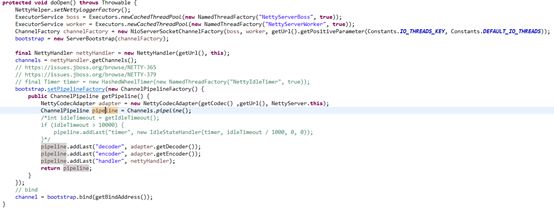
客户端发送数据到服务端时会触发服务端的上行IO事件并且启动处理器回调,NettyCodecAdapter.decoder和NettyHandler是上行事件处理器,上行事件处理器调用顺序是从前到后执行,即先添加的处理器先执行,所以先触发NettyCodecAdapter.decoder再触发NettyHandler。
服务端往客户端回写响应时产生下行事件,处理下行事件处理器,NettyCodecAdapter.encoder和NettyHandler是下行事件处理器,先激活NettyHandler,再激活NettyCodecAdapter. encoder
======================================
上面的ChannelHandler文档并不完整,所以我要补充一下:
除了ChannelInboundHandler拦截和处理入站事件,ChannelOutboundHandler拦截和处理出站事件,还有ChannnelDuplexHandler。
ChannelDuplexHandler同时实现了ChannelInboundHandler和ChannelOutboundHandler接口。如果一个所需的ChannelHandler既要处理入站事件又要处理出站事件,推荐继承此类。
其他的还有netty自带的LoggingHnadler和TimeHandler等。
自顶向下深入分析Netty(八)--ChannelHandler
8.1 总述
由第七节的讲述可知ChannelHandler并不处理事件,而由其子类代为处理:ChannelInboundHandler拦截和处理入站事件,ChannelOutboundHandler拦截和处理出站事件。ChannelHandler和ChannelHandlerContext通过组合或继承的方式关联到一起成对使用。事件通过ChannelHandlerContext主动调用如fireXXX()和write(msg)等方法,将事件传播到下一个处理器。注意:入站事件在ChannelPipeline双向链表中由头到尾正向传播,出站事件则方向相反。
当客户端连接到服务器时,Netty新建一个ChannelPipeline处理其中的事件,而一个ChannelPipeline中含有若干ChannelHandler。如果每个客户端连接都新建一个ChannelHandler实例,当有大量客户端时,服务器将保存大量的ChannelHandler实例。为此,Netty提供了Sharable注解,如果一个ChannelHandler状态无关,那么可将其标注为Sharable,如此,服务器只需保存一个实例就能处理所有客户端的事件。
8.2 源码分析
8.2.1 核心类

ChannelHandler的核心类类图,其继承层次清晰,我们逐一分析。
1.ChannelHandler
ChannaleHandler 作为最顶层的接口,并不处理入站和出站事件,所以接口中只包含最基本的方法:
// Handler本身被添加到ChannelPipeline时调用
void handlerAdded(ChannelHandlerContext ctx) throws Exception;
// Handler本身被从ChannelPipeline中删除时调用
void handlerRemoved(ChannelHandlerContext ctx) throws Exception;
// 发生异常时调用
void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception;
其中也定义了Sharable标记注解:
@Inherited
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@interface Sharable {
// no value
}
作为ChannelHandler的默认实现,ChannelHandlerAdapter有个重要的方法isSharable(),代码如下:
public boolean isSharable() {
Class clazz = getClass();
// 每个线程一个缓存
Map, Boolean> cache =
InternalThreadLocalMap.get().handlerSharableCache();
Boolean sharable = cache.get(clazz);
if (sharable == null) {
// Handler是否存在Sharable注解
sharable = clazz.isAnnotationPresent(Sharable.class);
cache.put(clazz, sharable);
}
return sharable;
}
这里引入了优化的线程局部变量InternalThreadLocalMap,将在以后分析,此处可简单理解为线程变量ThreadLocal,即每个线程都有一份ChannelHandler是否Sharable的缓存。这样可以减少线程间的竞争,提升性能。
2.ChannelInboundHandler
ChannelInboundHandler处理入站事件,以及用户自定义事件:
// 类似的入站事件
void channeXXX(ChannelHandlerContext ctx) throws Exception;
// 用户自定义事件
void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception;
ChannelInboundHandlerAdapter作为ChannelInboundHandler的实现,默认将入站事件自动传播到下一个入站处理器。其中的代码高度一致,如下:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
3.ChannelOutboundHandler
ChannelOutboundHandler处理出站事件:
// 类似的出站事件
void read(ChannelHandlerContext ctx) throws Exception;
同理,ChannelOutboundHandlerAdapter作为ChannelOutboundHandler的事件,默认将出站事件传播到下一个出站处理器:
@Override
public void read(ChannelHandlerContext ctx) throws Exception {
ctx.read();
}
4.ChannelDuplexHandler
ChannelDuplexHandler则同时实现了ChannelInboundHandler和ChannelOutboundHandler接口。如果一个所需的ChannelHandler既要处理入站事件又要处理出站事件,推荐继承此类。
至此,ChannelHandler的核心类已分析完毕,接下来将分析一些Netty自带的Handler。
8.3 ChannelHandler实例
8.3.1 LoggingHandler
日志处理器LoggingHandler是使用Netty进行开发时的好帮手,它可以对入站\出站事件进行日志记录,从而方便我们进行问题排查。首先看类签名:
@Sharable
public class LoggingHandler extends ChannelDuplexHandler
注解Sharable说明LoggingHandler没有状态相关变量,所有Channel可以使用一个实例。继承自ChannelDuplexHandler表示对入站出站事件都进行日志记录。最佳实践:使用static修饰LoggingHandler实例,并在生产环境删除LoggingHandler。
该类的成员变量如下:
// 实际使用的日志处理,slf4j、log4j等
protected final InternalLogger logger;
// 日志框架使用的日志级别
protected final InternalLogLevel internalLevel;
// Netty使用的日志级别
private final LogLevel level;
// 默认级别为Debug
private static final LogLevel DEFAULT_LEVEL = LogLevel.DEBUG;
看完成员变量,在移目构造方法,LoggingHandler的构造方法较多,一个典型的如下:
public LoggingHandler(LogLevel level) {
if (level == null) {
throw new NullPointerException("level");
}
// 获得实际的日志框架
logger = InternalLoggerFactory.getInstance(getClass());
// 设置日志级别
this.level = level;
internalLevel = level.toInternalLevel();
}
在构造方法中获取用户实际使用的日志框架,如slf4j、log4j等,并日志设置记录级别。其他的构造方法也类似,不在赘述。
记录出站、入站事件的过程类似,我们以ChannelRead()为例分析,代码如下:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
logMessage(ctx, "RECEIVED", msg); // 记录日志
ctx.fireChannelRead(msg); // 传播事件
}
private void logMessage(ChannelHandlerContext ctx, String eventName, Object msg) {
if (logger.isEnabled(internalLevel)) {
logger.log(internalLevel, format(ctx, formatMessage(eventName, msg)));
}
}
protected String formatMessage(String eventName, Object msg) {
if (msg instanceof ByteBuf) {
return formatByteBuf(eventName, (ByteBuf) msg);
} else if (msg instanceof ByteBufHolder) {
return formatByteBufHolder(eventName, (ByteBufHolder) msg);
} else {
return formatNonByteBuf(eventName, msg);
}
}
其中的代码都简单明了,主要分析formatByteBuf()方法:
protected String formatByteBuf(String eventName, ByteBuf msg) {
int length = msg.readableBytes();
if (length == 0) {
StringBuilder buf = new StringBuilder(eventName.length() + 4);
buf.append(eventName).append(": 0B");
return buf.toString();
} else {
int rows = length / 16 + (length % 15 == 0? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(eventName.length() +
2 + 10 + 1 + 2 + rows * 80);
buf.append(eventName)
.append(": ").append(length).append('B').append(NEWLINE);
appendPrettyHexDump(buf, msg);
return buf.toString();
}
其中的数字计算,容易让人失去耐心,使用逆向思维,放上结果反推:

有了这样的结果,请反推实现。需要注意的是其中的
appendPrettyHexDump()方法,这是在 ByteBufUtil里的 static方法,当我们也需要查看多字节数据时,这是一个特别有用的展现方法,记得可在以后的Debug中可加以使用。
8.3.2 TimeoutHandler
在开发TCP服务时,一个常见的需求便是使用心跳保活客户端。而Netty自带的三个超时处理器IdleStateHandler,ReadTimeoutHandler和WriteTimeoutHandler可完美满足此需求。其中IdleStateHandler可处理读超时(客户端长时间没有发送数据给服务端)、写超时(服务端长时间没有发送数据到客户端)和读写超时(客户端与服务端长时间无数据交互)三种情况。这三种情况的枚举为:
public enum IdleState {
READER_IDLE, // 读超时
WRITER_IDLE, // 写超时
ALL_IDLE // 数据交互超时
}
以IdleStateHandler的读超时事件为例进行分析,首先看类签名:
public class IdleStateHandler extends ChannelDuplexHandler
注意到此Handler没有Sharable注解,这是因为每个连接的超时时间是特有的即每个连接有独立的状态,所以不能标注Sharable注解。继承自ChannelDuplexHandler是因为既要处理读超时又要处理写超时。
该类的一个典型构造方法如下:
public IdleStateHandler(int readerIdleTimeSeconds, int writerIdleTimeSeconds,
int allIdleTimeSeconds) {
this(readerIdleTimeSeconds, writerIdleTimeSeconds,
allIdleTimeSeconds, TimeUnit.SECONDS);
}
分别设定各个超时事件的时间阈值。以读超时事件为例,有以下相关的字段:
// 用户配置的读超时时间
private final long readerIdleTimeNanos;
// 判定超时的调度任务Future
private ScheduledFuture readerIdleTimeout;
// 最近一次读取数据的时间
private long lastReadTime;
// 是否第一次读超时事件
private boolean firstReaderIdleEvent = true;
// 状态,0 - 无关, 1 - 初始化完成 2 - 已被销毁
private byte state;
// 是否正在读取
private boolean reading;
首先看初始化方法initialize():
private void initialize(ChannelHandlerContext ctx) {
switch (state) {
case 1: // 初始化进行中或者已完成
case 2: // 销毁进行中或者已完成
return;
}
state = 1;
lastReadTime = ticksInNanos();
if (readerIdleTimeNanos > 0) {
readerIdleTimeout = schedule(ctx, new ReaderIdleTimeoutTask(ctx),
readerIdleTimeNanos, TimeUnit.NANOSECONDS);
}
初始化的工作较为简单,设定最近一次读取时间lastReadTime为当前系统时间,然后在用户设置的读超时时间readerIdleTimeNanos截止时,执行一个ReaderIdleTimeoutTask进行检测。其中使用的方法很简洁,如下:
long ticksInNanos() {
return System.nanoTime();
}
ScheduledFuture schedule(ChannelHandlerContext ctx, Runnable task,
long delay, TimeUnit unit) {
return ctx.executor().schedule(task, delay, unit);
}
然后,分析销毁方法destroy():
private void destroy() {
state = 2; // 这里结合initialize对比理解
if (readerIdleTimeout != null) {
// 取消调度任务,并置null
readerIdleTimeout.cancel(false);
readerIdleTimeout = null;
}
}
可知销毁的处理也很简单,分析完初始化和销毁,再看这两个方法被调用的地方,initialize()在三个方法中被调用:
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
if (ctx.channel().isActive() &&
ctx.channel().isRegistered()) {
initialize(ctx);
}
}
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
if (ctx.channel().isActive()) {
initialize(ctx);
}
super.channelRegistered(ctx);
}
public void channelActive(ChannelHandlerContext ctx) throws Exception {
initialize(ctx);
super.channelActive(ctx);
}
当客户端与服务端成功建立连接后,Channel被激活,此时channelActive的初始化被调用;如果Channel被激活后,动态添加此Handler,则handlerAdded的初始化被调用;如果Channel被激活,用户主动切换Channel的执行线程Executor,则channelRegistered的初始化被调用。这一部分较难理解,请仔细体会。destroy()则有两处调用:
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
destroy();
super.channelInactive(ctx);
}
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
destroy();
}
即该Handler被动态删除时,handlerRemoved的销毁被执行;Channel失效时,channelInactive的销毁被执行。
分析完这些,在分析核心的调度任务ReaderIdleTimeoutTask:
private final class ReaderIdleTimeoutTask implements Runnable {
private final ChannelHandlerContext ctx;
ReaderIdleTimeoutTask(ChannelHandlerContext ctx) {
this.ctx = ctx;
}
@Override
protected void run() {
if (!ctx.channel().isOpen()) {
// Channel不再有效
return;
}
long nextDelay = readerIdleTimeNanos;
if (!reading) {
// nextDelay<=0 说明在设置的超时时间内没有读取数据
nextDelay -= ticksInNanos() - lastReadTime;
}
// 隐含正在读取时,nextDelay = readerIdleTimeNanos > 0
if (nextDelay <= 0) {
// 超时时间已到,则再次调度该任务本身
readerIdleTimeout = schedule(ctx, this, readerIdleTimeNanos,
TimeUnit.NANOSECONDS);
boolean first = firstReaderIdleEvent;
firstReaderIdleEvent = false;
try {
IdleStateEvent event =
newIdleStateEvent(IdleState.READER_IDLE, first);
channelIdle(ctx, event); // 模板方法处理
} catch (Throwable t) {
ctx.fireExceptionCaught(t);
}
} else {
// 注意此处的nextDelay值,会跟随lastReadTime刷新
readerIdleTimeout = schedule(ctx, this, nextDelay, TimeUnit.NANOSECONDS);
}
}
}
这个读超时检测任务执行的过程中又递归调用了它本身进行下一次调度,请仔细品味该种使用方法。再列出channelIdle()的代码:
protected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt)
throws Exception {
ctx.fireUserEventTriggered(evt);
}
本例中,该方法将写超时事件作为用户事件传播到下一个Handler,用户需要在某个Handler中拦截该事件进行处理。该方法标记为protect说明子类通常可覆盖,ReadTimeoutHandler子类即定义了自己的处理:
@Override
protected final void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt)
throws Exception {
assert evt.state() == IdleState.READER_IDLE;
readTimedOut(ctx);
}
protected void readTimedOut(ChannelHandlerContext ctx) throws Exception {
if (!closed) {
ctx.fireExceptionCaught(ReadTimeoutException.INSTANCE);
ctx.close();
closed = true;
}
}
可知在ReadTimeoutHandler中,如果发生读超时事件,将会关闭该Channel。当进行心跳处理时,使用IdleStateHandler较为麻烦,一个简便的方法是:直接继承ReadTimeoutHandler然后覆盖readTimedOut()进行用户所需的超时处理。
此处转载自: 自顶向下深入分析Netty(八)--ChannelHandler