数据处理之pandas库
什么是pandas
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
pandas索引操作
1.Series和DataFrame中的索引都是index对象
[1].创建Series对象
pd1 = pd.Series(range(5),index=['a','b','c','d','e'])
pd1
[2] 创建DataFrame对象
pd2 = pd.DataFrame(np.random.randint(1,10,size=(3,4)),index=list('abc'),columns=['1','2','3','4'])
pd2
索引对象一旦建立就不可变,保证数据的安全性。
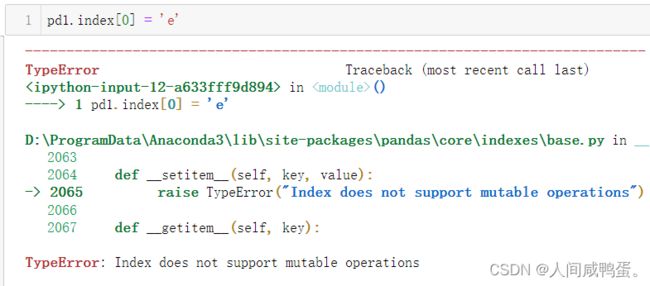
Series索引
1.index指定行索引名
pd1 = pd.Series(range(5),index=['a','b','c','d','e'])
2. 行索引
行索引可根据改行对应index索引寻找对应的value,也可以根据改行所在位置寻找指定value
pd1['a'] // 根据index索引寻找value
pd1[0] // 根据行数寻找value
3. 连续切片索引
pd1[1:3] // 根据行区间寻找指定连续数据
pd1['a':'c'] // 根据index寻找指定连续数据
4.不连续索引
pd1[[1,3]] // 根据指定行数锁定指定数据
pd1[['a','b']] // 根据指定index锁定指定数据
5.布尔索引
布尔索引即是返回条件为真值的数据
pd1[pd1 > 2] // 返回value大于2的所有数据
DataFrame索引
1.columns指定列索引名
pd2 = pd.DataFrame(np.random.randint(1,10,size=(3,4)),index=list('abc'),columns=['1','2','3','4'])
2.列索引
pd2['1'] // 返回列索引为1的所有 值,为Series对象
pd2[['1']] // 返回列索引为1的所有值,但是为DataFrame对象
3.不连续索引
pd2[['1','3']] // 返回列索引为1和3的数据,为DataFrame对象
4.loc标签索引
pd2.loc['a'] // 返回index为a的行数据,为Series对象
pd2.loc['a','1'] // 返回index为a,column为1对应的数据
pd2.loc[['a','b','c'],'1'] // 返回index为a,b,c,column为1的数据
pd2.loc['a':'c','1'] // 效果同上
pd2.loc[['a','b'],['1','3']] // 返回index为a,b,column为1 和i3的数据
pd2.loc['a':'c','1':'3'] // 返回index为a~c,column为1~3的所有数据,为DataFrame对象
5.iloc位置索引
pd2.iloc[1,2] // 返回第二行第三列的数据
pd2.iloc[1:3,1:3] // 返回第二行到第三行,第二列到第三列的数据
pd2.iloc[[0,2],[0,2]] // 返回第一行和第第三行,第一列和第三列的数据
Pandas的对齐运算
Series对齐运算
Series按行,索引对齐运算
// 按索引对齐进行运算,如果没对齐的位置则补NaN,最后填充NaN
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
s1 + s2
DataFrame对齐运算
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])
df1 + df2
填充数据
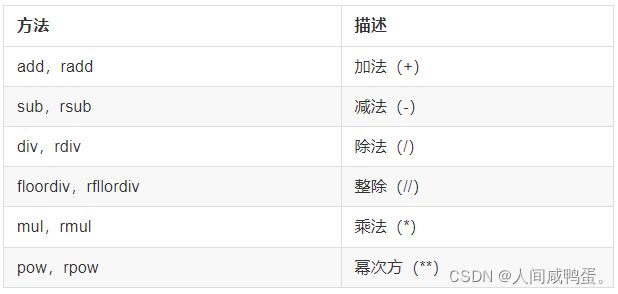
1.fill_value:使用add,sub,div,mul函数式,可对NAN值进行fill填充
s1.add(s2, fill_value = -1) // s1和s2对齐运算,将NAN值填充为-1
df1.sub(df2, fill_value = 2.) // df1减df2,NAN值使用2.0替换,此种填充会将数据类型变为float类型
算术方法表
Pandas函数应用
排序
1.索引排序
Series排序操作
s4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5))
s4.sort_index(ascending=True) // 按照索引进行升序,ascending默认为True,升序;当为False时,降序排列
DataFrame排序操作,注意轴方向
df4 = pd.DataFrame(np.random.randint(3, 5,size=(3,5)),
index=np.random.randint(3, size=3),
columns=np.random.randint(5, size=5))
df4.sort_index(ascending=True,axis=1) # 当axis等于1时,操作纵轴 , 当axis=0时,操作横轴
2. 按值排序
df4.sort_values(by=4, ascending=True) # 暗中列名为4,升序排列
处理缺失数据
1.判断是否存在缺失值,isnull()
df4.isnull()
2.删除缺失数据,dropna()
df4.dropna(axis=1) // 根据轴方向,删除NAN的行或列
3.填充缺失数据
df4.fillna(-100.)
层级索引
创建层级索引Series对象
ser_obj = pd.Series(np.random.randn(12),index=[
['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]
])
选取子集
1.外层选取
ser_obj['c'] // 选取外层索引为c的数据
2. 内层选取
ser_obj[:, 2] // 选取内层索引为2的数据
交换分层
1.交换分层顺序swaplevel()
ser_obj.swaplevel()
2.交换并排序分层sortlevel()
ser_obj.swaplevel().sortlevel()
Pandas统计计算
1. sum()
pd2 = pd.DataFrame(np.random.randint(1,10,size=(3,4)),index=list('abc'),columns=['1','2','3','4'])
pd2.sum(axis=1)
mean()
pd2.mean(axis=1)
max(),min()
pd2.max(axis=1)
pd2.min(axis=1)
describe()汇总统计描述
pd2.describe()
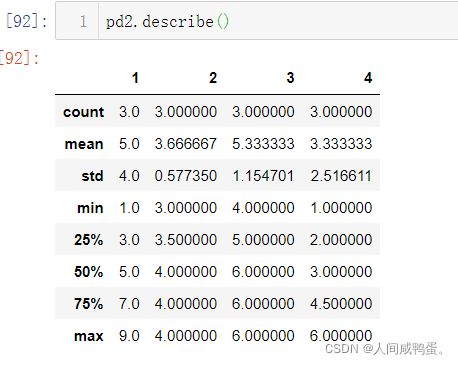
参数解读
count:求和
mean:平均值
std:方差
min:最小值
25%:第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
50%:第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
75%:第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
Pandas数据清洗
1.处理缺失数据
pd.fillna() :填充缺失值
pd.dropna():删除缺失值
pd.isnull():判断是否为空
pd.notnull():判断是否不为空
2.数据转换
pd.duplicated():判断每行重复
pd.drop_duplicates():过滤重复行,默认判断全部列,也可指定某些列
pd.replace():根据内容进行替换
3.字符串操作
s.count()
s.endswith()
s.index()
s.find()
s.replace()
s.rfind()
s.strip()
s.split()
s.lower()
s.upper()