FLUME的架构 Flume NG
Flume架构以及应用介绍
先给大家看一下Hadoop业务的整体开发流程:
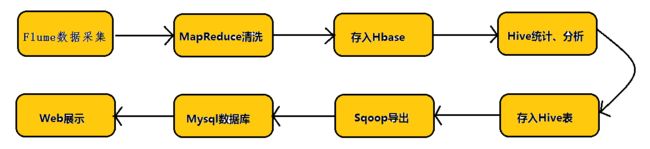
从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出我们本文的主角—Flume。本文将围绕Flume的架构、Flume的应用(日志采集)进行详细的介绍。
(一)Flume架构介绍
1、Flume的概念
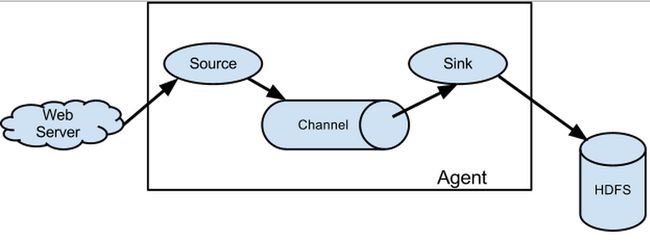
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。
2、Event的概念
在这里有必要先介绍一下flume中event的相关概念:flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
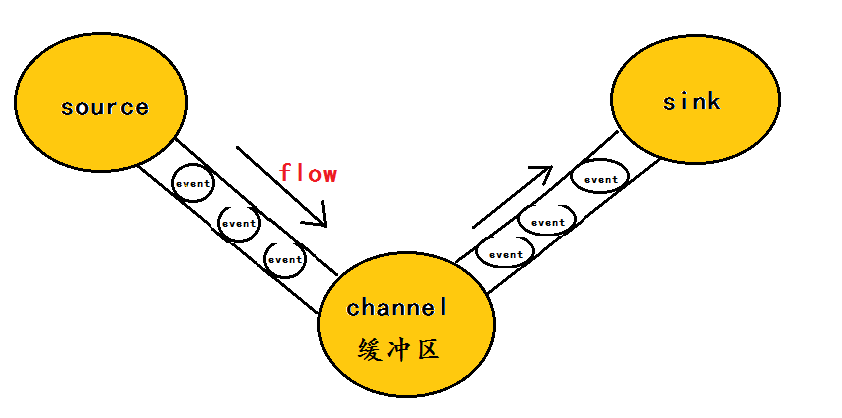
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
为了方便大家理解,给出一张event的数据流向图:
==
3、flume架构介绍
flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent,agent本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。
agent里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
==
(二)flume应用—日志采集
对于flume的原理其实很容易理解,我们更应该掌握flume的具体使用方法,flume提供了大量内置的Source、Channel和Sink类型。而且不同类型的Source、Channel和Sink可以自由组合—–组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。下面我将用具体的案例详述flume的具体用法。
其实flume的用法很简单—-书写一个配置文件,在配置文件当中描述source、channel与sink的具体实现,而后运行一个agent实例,在运行agent实例的过程中会读取配置文件的内容,这样flume就会采集到数据。
配置文件的编写原则:
1>从整体上描述代理agent中sources、sinks、channels所涉及到的组件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1- 1
- 2
- 3
- 4
2>详细描述agent中每一个source、sink与channel的具体实现:即在描述source的时候,需要
指定source到底是什么类型的,即这个source是接受文件的、还是接受http的、还是接受thrift
的;对于sink也是同理,需要指定结果是输出到HDFS中,还是Hbase中啊等等;对于channel
需要指定是内存啊,还是数据库啊,还是文件啊等等。
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3>通过channel将source与sink连接起来
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 1
- 2
- 3
启动agent的shell操作:
flume-ng agent -n a1 -c ../conf -f ../conf/example.file
-Dflume.root.logger=DEBUG,console - 1
- 2
参数说明: -n 指定agent名称(与配置文件中代理的名字相同)
-c 指定flume中配置文件的目录
-f 指定配置文件
-Dflume.root.logger=DEBUG,console 设置日志等级
==
几个flume source进行适当总结:
① NetCat Source:监听一个指定的网络端口,即只要应用程序向这个端口里面写数据,这个source组件
就可以获取到信息。
②Spooling Directory Source:监听一个指定的目录,即只要应用程序向这个指定的目录中添加新的文
件,source组件就可以获取到该信息,并解析该文件的内容,然后写入到channle。写入完成后,标记
该文件已完成或者删除该文件。
③Exec Source:监听一个指定的命令,获取一条命令的结果作为它的数据源
常用的是tail -F file指令,即只要应用程序向日志(文件)里面写数据,source组件就可以获取到日志(文件)中最新的内容 。
④Avro Source:监听一个指定的Avro 端口,通过Avro 端口可以获取到Avro client发送过来的文件 。即只要应用程序通过Avro 端口发送文件,source组件就可以获取到该文件中的内容。
==
- Flume Source
| Source类型 | 说明 |
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source | 支持Thrift协议,内置支持 |
| Exec Source | 基于Unix的command在标准输出上生产数据 |
| JMS Source | 从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 |
| Spooling Directory Source | 监控指定目录内数据变更 |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
| Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本) |
- Flume Channel
| Channel类型 | 说明 |
| Memory Channel | Event数据存储在内存中 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel | Event数据存储在磁盘文件中 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
| Pseudo Transaction Channel | 测试用途 |
| Custom Channel | 自定义Channel实现 |
- Flume Sink
| Sink类型 | 说明 |
| HDFS Sink | 数据写入HDFS |
| Logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink | 数据在IRC上进行回放 |
| File Roll Sink | 存储数据到本地文件系统 |
| Null Sink | 丢弃到所有数据 |
| HBase Sink | 数据写入HBase数据库 |
| Morphline Solr Sink | 数据发送到Solr搜索服务器(集群) |
| ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群) |
| Kite Dataset Sink | 写数据到Kite Dataset,试验性质的 |
| Custom Sink | 自定义Sink实现 |
==
Flume NG:Flume next generation ,即Flume 1.x版本,它由Agent、Client等组件构成。
Flume OG:Flume original generation 即Flume 0.9.x版本,它由agent、collector、master等组件构成。
==