依赖倒置如何升华架构设计
一、听说你是架构师不会自己写架构
百科:系统架构师是一个最终确认和评估系统需求,给出开发规范,搭建系统实现的核心构架,并澄清技术细节、扫清主要难点的技术人员。
你对核心架构有什么认识?
核心架构在软件领域是为软件系统提供结构、行为和属性的高级抽象结构。在不同领域不同业务,核心架构都关注抽象、业务规则分离。核心架构指导大型软件系统各个方面的设计。架构师在设计系统时,慎重选择各种依赖关系 - 基础框架,身份验证,存储;在规划业务战略、组建组员、项目周期、系统基础设施、调度资源都对核心架构有着重大影响。
那么,什么是架构?
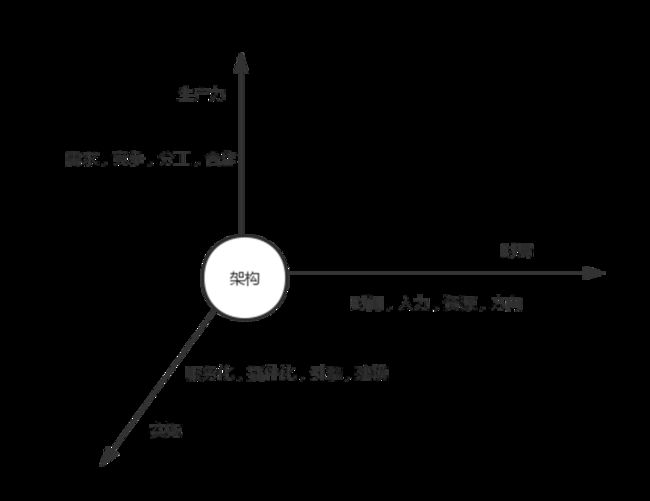
架构建设的整体的认知包括三个部分:
- 架构为了提升生产力: 这个框架提升了我们的生产力和效率吗?是否从需求,竞争,合作方面进行了充分的思考和调研;架构的边界是否能够匹配合作的形式?是否能够让参与的各方实现共赢?
- 架构有时势: 时间和局势。时间包括实施的时间长短,当前业务的紧急程度;局势包括了团队的资源情况,业务的侧重点等;任何一个架构都是理想和当下的平衡。
- 架构来自哪些抽象思想和历史方案: 有蓝图做指导,有基础设施和资源 ,下一步就是实施和创新,实施也要考虑清楚,使用飞机还是火箭?是游艇还是航母?这些就需要在落地的时候想清楚。
二、依赖是什么?有哪些重要的具体体现?
答案似乎很简单。如果你的系统依赖某些东西来运行,那就是一个依赖。然而,这只是冰山一角。
更加形象的例子,动物的特征有新陈代谢,能繁殖。而要有生命力,需要氧气、水、食物等,就是说,动物依赖于氧气和水。它们之间是依赖关系,为了让软件设计人员拥有共同的交流方式,我们规定了依赖关系用虚线箭头表示。普通箭头指向被依赖的事物(例如:动物 指向氧气,指向水)。
//通过构造函数,动物依赖于氧气、水,形成依赖关系
abstract class Animal {
//新陈代谢
public Metabolism ( Oxygen oxygen ,Water water)
{
}
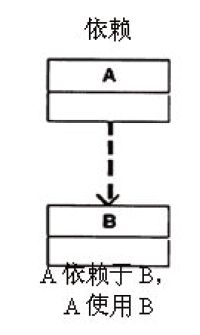
}总结:依赖关系是一种使用关系,即一个类的实现需要另一个类的协助。
表述方式:A依赖于B,A使用B
问题:如何在代码体现依赖关系,如何表达依赖?如何发现两个类(多个事物)是否存在依赖关系?在java中形成依赖关系的方式有哪些?依赖与设计原则有什么关系?
三、如何通过对依赖的认识设计业务架构呢?
依赖为什么能升华架构设计?
也许你是高手,但对依赖的问题的经历记忆深刻,反复遇到的两个事件:对象创建和对象之间的交互, 它们混合在一起,这会导致紧密耦合和不必要的依赖关系,这反过来又使维护和单元测试变得痛苦。
下面,试着用一个非常简单的例子(学生、教师、课程)来解释依赖:
class MyClass {
private Teacher a; //A is an interface
private Student b; //B is an interface
//Object creation within constructor
MyClass(Teacher a, Student b) {
a = new AImpl(); //AImpl is the concrete impl of A
b = new BImpl(); //BImpl is the concrete impl of B
}
//Application logic lies within this method
public void doSomething() {
//Do A specific thing
//Do B specific thing
Class c = new CImpl(); //Object creation within the method.
//Do C specific thing
}
}public interface Teacher {
}
public class AImpl implements Teacher {
}
public interface Student {
}
public class BImpl implements Student {
}
public interface Class {
}
public class CImpl implements Class {
}这个MyClass 类的问题是:
- 它无法将对象创建与业务逻辑分开,从而导致紧密耦合。
- 这里已经完成了“编程到实现”,而不是接口。明天,如果需要 A、B 或 C 的不同实现,则必须更改类中的代码。
- 测试 MyClass 需要首先测试 A、B、C。
因此,每个软件设计师在设计时,都会经历测试痛苦过程,而产生对依赖的问题的经历记忆深刻。
那么, 依赖的认识已经有了,那么设计业务时候,你能从依赖 升华 设计吗?
为了深刻,可以继续思考下面的依赖的例子:
//抽象观察者,为所有的具体观察者定义一个接口,在得到主题的通知时更新自己。
abstract class AbObserver {
public abstract void Update();//更新方法
}
//会计员同事
public class AccountantObserver {
private String name;
//秘书---关联秘书
private Secretary sub;
public AccountantObserver(String name,Secretary sub){
this.name=name;
this.sub=sub;
}
public void SayUpdate(){
//得到前台的通知,赶快行动
String s=sub.getAction();
System.out.printf(this.name);
System.out.printf("工作。");
System.out.printf("因为前台通知:");
System.out.printf(s,sub.getAction().toString());
}
}
//前台秘书
public class Secretary {
//同事列表
private LinkedHashSet observers =new LinkedHashSet() ;
//行为
private String action;
//增加,就是有几个同事请前台帮忙,于是就给集合增加几个对象
public void Attach(AccountantObserver observer){
observers.add(observer);
}
//通知
public void Notify(){
for (AccountantObserver o: observers) {
o.SayUpdate();
}
}
//前台秘书的工作状态---前台通过电话,说话、或所做的事情变化,
public String getAction() {
return action;
}
public void setAction(String action) {
this.action = action;
}
}
//前台秘书小丽发消息
Secretary xiaoli =new Secretary();
//打游戏的会计同事
AccountantObserver xiaogao =new AccountantObserver("小高",xiaoli);
//喝茶的会计同事
AccountantObserver xiaozhao =new AccountantObserver("小赵",xiaoli);
//前台记录两位同事
xiaoli.Attach(xiaogao);
xiaoli.Attach(xiaozhao);
//发现老板回来
xiaoli.setAction("老板回来了!!!");
//通知同事
xiaoli.Notify();四、伟大的DIP原则是怎么指导业务架构的实施呢?
DIP原则是面向对象编程中最着名的原则之一。这个原则提出有一段时间了,是 Robert C. Martin 于1996年制定了依赖性倒置原则(DIP)。它代表“ SOLID ”原则中的字母“ D ”。
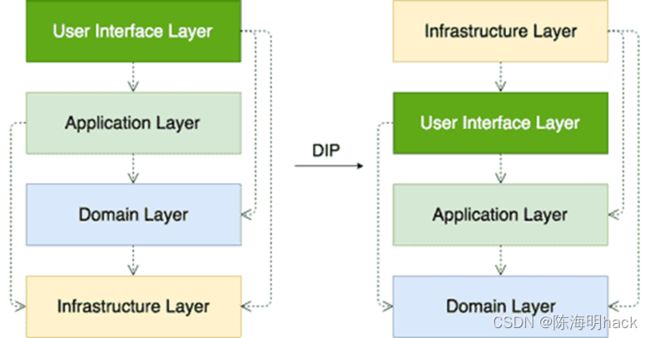
Vaughn Vernon(2013)演示了如何在典型的4层架构中应用DIP:
为了深刻研究,继续发现:
例子1:假设我们设计一套流程:先设计用户界面层,然后根据用户设计应用层,接着根据应用设计领域层,最后根据领域层设计基础设施层,并组装好整个系统依赖。这里就出现了一个“依赖”关系:该模式不指定层数,而是一个简单的规则:一层可以与其下面的任何层形成强的耦合关系,并形成简单的分层架构。从上图也明显发现,高层模块依赖底层模块,都依赖基础设施层。
例子2:假设我们设计一辆汽车:先设计轮子,然后根据轮子大小设计底盘,接着根据底盘设计车身,最后根据车身设计好整个汽车。而这个设计的“依赖”关系体现在:汽车依赖车身,车身依赖底盘,底盘依赖轮子。
而Vaughn Vernon(2013)演示主要目标是解决分层架构的紧耦合问题。通过如图的设计,进行模块的反转,领域层是所有其他层依赖的域层。这种方法消除了与基础设施层的直接耦合。
通过上图分析,基于DIP的架构的好处:
- 独立于UI
- 独立于数据库和其他外部系统
- 独立于技术特定的库和框架
- 可互换的基础设施模块
- 任意数量和类型的客户端
- 测试简单了很多
五、你能描述清楚依赖倒置吗
问题1:你描述对依赖倒置的认识?
这个问题,你联系我吧。
问题2:依赖倒置的架构有什么缺点?
1.不理解原理的过程和思想就会很复杂。
2.术语模糊。
3.易受错误依赖影响。idea中依赖项理清楚、说清楚依赖关系更加复杂。
4.你还会设计模式吗?你还会选择模式吗?如何选择模式?
六、如何理解依赖注入与依赖倒置的关系
1.依赖注入
或者你已经从各种途径获取到他的定义,但是,这依赖注入为什么这个样呢?为了分析这个问题,还是先整理大家的共同认知:先从上面最简单的依赖例子:
//将原来的构造函数进行最简单实现依赖关系整合
MyClass(Teacher a, Student b, Class c) {
//Only Assignment
this.a = a;
this.b = b;
this.c = c;
}
//添加一个 简单的 Factory
class MyFactory {
public MyClass createMyClass() {
return new MyClass(new AImpl(), new BImpl(), new CImpl());
}
}描述依赖注入的最简单定义:由于对象没有在MyClass的构造函数中创建。构造函数进行对象引用 分配。在这里,构造函数要求将依赖项作为参数,但不创建它们 ,这就是最简单的依赖注入啦。
进一步讨论依赖关系中对象的行为,从现有的java的框架实际上使用以下三种基本技术的框架执行服务和部件间的绑定:
- 类型1 (基于接口): 可服务的对象需要实现一个专门的接口,该接口提供了一个对象,可以重用这个对象查找依赖(其它服务)。早期的容器Excalibur使用这种模式。
- 类型2 (基于setter): 通过JavaBean的属性(setter方法)为可服务对象指定服务。HiveMind和Spring采用这种方式。
- 类型3 (基于构造函数): 通过构造函数的参数为可服务对象指定服务。PicoContainer只使用这种方式。HiveMind和Spring也使用这种方式。
于是,我们都总结出来的依赖注入的三种写法:
①构造函数传递依赖对象(构造函数注入)
②Setter方法传递依赖对象(setter依赖注入)
③接口声明依赖对象(接口注入)---为注入定义和使用接口。使用这种技术,首先定义一个接口,
其实这个三种写法只是两种方式(构造函数(对象引用,接口对象注入),成员变量(Setter方法)),还有一种方式。。。。。。。。
先讲Spring的依赖注入。这个过程将注解(本质是接口),将对象行为与依赖解析分开,并通过
private MapiocBeanMap=new ConcurrentHashMap(32)提前组装对象的属性和方法,由于接口需要进行特殊处理,因此注入过程的识别方式有
field.set(obj,iocBeanMap.get(myAutowired.value()))和
Object obj =iocBeanMap.get(beanName),使抽象免于管理依赖项生命周期的职责,而识别方式就将以前new的方式,变成设置成参数,需要的时候传进去【即写类的时候,类允许有参数,我把这个类需要的类(这个对象 )注入进来(参数传递进来)】,完成注入过程。进行类对象的识别的代码如下:
Field[] fields=obj.getClass().getDeclaredFields();
for (Field field:fields){
if (field.getAnnotation(MyAutowired.class)!=null){
/**
* 在字段是私有变量的时候,也能获得访问权限
*/
field.setAccessible(true);
MyAutowired myAutowired=field.getAnnotation(MyAutowired.class);
Class fieldClass=field.getType();
//接口不能被实例化,需要对接口进行特殊处理获取其子类,获取所有实现类
if (fieldClass.isInterface()){
//如果有指定获取子类名
if (StringUtils.isNotEmpty(myAutowired.value())){
field.set(obj,iocBeanMap.get(myAutowired.value()));
}else {
//当注入接口时,属性的名字与接口实现类名一致则直接从容器中获取
Object objByName=iocBeanMap.get(field.getName());
if (objByName != null){
field.set(obj,objByName);
//递归依赖注入
addAutowiredToField(field.getType());
} else {
//注入接口时,如果属性名称与接口实现类名不一致
List回顾上面的例子2的简单依赖,然后进行优化:

2.依赖倒置
有了上面对依赖注入的认识,简单理解倒置过程: 把生产对象需要的各种属性方法都提前做好,需要什么对象就直接使用,形成耦合关系弱的聚合关系。倒置就是提前做new的过程。因此,
设计好的类交给系统去控制,而不是在类内部控制实例化。这称为控制反转。
3.依赖注入与依赖倒置过程
因为框架帮助程序员将整个程序的执行流程通过框架来控制,因而,从依赖关系、依赖注入、依赖倒置和依赖倒置原则的整个发展过程都有层层递进关系。
回顾:这个演变过程精彩绝伦。
依赖倒置原则:1.高层模块不应该依赖底层模块,两个都应该依赖抽象。
2.抽象不应该依赖细节,细节应该依赖抽象。
3.针对接口编程,不要对实现编程。
七、总结
升华架构设计就是 从最简单(概念性)的层次开始,然后逐渐添加细节和特征,随着逐步深入,设计也渐趋向复杂的过程。对象的属性和行为就复杂化了,但是,复杂过程和依赖倒置本是面对对象和使用设计模式的对象抽象和分离思想。从最最开始的Class到 Object 、Object到Class、 依赖关系、依赖注入、依赖倒置过程都充满分析对象行为的思考。