【《游戏引擎架构》提炼总结】(二)游戏支持系统
目录
- 前言
- 子系统的启动和终止
- 内存管理
-
- 优化动态内存分配
-
- 基于堆栈的分配器
- 池分配器
- 单帧和双缓冲内存分配器
- 内存碎片
- 容器
- 总结
前言
每个游戏都需要一些底层支持系统,来管理一些例行却关键的任务。例如
- 启动和终止引擎
- 存取(多个)文件系统
- 存取不同类型的资产(网格,纹理,动画,音频)
- 游戏团队的调试工具
本篇文章将讨论大多数游戏引擎中都会出现的底层支持系统
子系统的启动和终止
游戏引擎是一个复杂软件,由多个子系统组合而成。当引擎启动时,必须依次配置和初始化每个子系统,而子系统之间的相互依赖关系,隐性的确定了子系统的启动次序。
但令人遗憾的是,C++的静态初始化并不支持这种功能。在C++中,在进入 main() 函数之前,全局及静态对象就已经被构建,我们完全不知道它们的构建顺序。同样的,在 main() 函数结束后,我们也不知道它们析构的顺序。
要应对此问题,可以使用C++的一个小技巧:在函数内申明的静态变量并不会在 main() 之前构建,而是会在第一次函数调用时构建,这样我们就可以控制它们的构建次序。
而要控制析构顺序,一个简单粗暴的方式是明确的为各个类定义启动和终止函数,并手动调用它们。用以取代原生的构造和析构函数。
下面是一个典型实现:
class rendermanager{
public:
//于首次调用时被构建
static rendermanager& get(){
static rendermanager sSingleton;
return sSingleton;
}
rendermanager(){
//不做事情
}
~rendermanager(){
//不做事情
}
void startup(){
//手动启动
//先启动需依赖的管理器
videomanager::get()
//现在启动渲染管理器
// ... ::get()
}
void shutDown(){
//终止管理器
}
}
内存管理
代码的运行效率是游戏程序员永恒的追求。而任何软件的效能,除了受算法的选择和算法编码的效率影响,数据的组织和存放方式也是一个重要因素,即程序如何运用内存(RAM)。内存对于效能的影响主要有两方面:
- 以 malloc( ) 或者 new 进行动态内存分配是非常慢的操作,要提升效能,最佳方法是避免进行动态内存分配,或者使用自制的内存分配器。
- 根据局部性原理,把数据置于细小的连续的内存块,效率要远高于把数据分散到广阔的内存地址中。
本节将会介绍如何从上述两个方面来优化内存的使用。
优化动态内存分配
通过 malloc() / free() 或者 new / delete 运算符动态分配内存被称为“堆分配”。堆分配的低效主要来自于两个方面:
- 堆分配器是通用基础设施,它需要处理任何大小的分配请求,从 1 字节到 1000 兆字节,其中需要大量的管理开销
- 在多数操作系统中,堆内存分配伴随着从 用户模式 切换到 内核模式 再切换回来的过程,这些上下文的切换会消耗很多时间
因此游戏开发中的一个常见的经验法则是:维持最低限度的堆分配,并且永不在紧凑的循环中使用堆分配。
当然任何游戏引擎都无法避免堆分配,所以它们会实现一个和多个定制分配器。定制分配器比起操作系统的分配器性能更优,原因有二。第一,定制分配器从预分配的内存中完成分配请求(预分配的内存来自于堆分配)从而避免了上下文切换。第二,通过对定制分配器的使用模式做出假设,可以使其比通用的堆分配器高效的多。下面将会介绍以下几种常见的定制分配器:
- 基于堆栈的分配器
- 池分配器
- 含对齐功能的分配器
- 单帧和双缓冲内存分配器
基于堆栈的分配器
许多游戏会以堆栈般的形式分配内存。当载入新的游戏关卡时,就会为关卡分配内存,在关卡被载入后就不会再动态分配内存了,而当关卡结束后,关卡占用的内存则被卸下。对于这类的内存分配,非常适合使用堆栈。
堆栈分配器是很容易实现的(stack allocator),我们用 new 分配一大块连续的内存作为待分配空间,同时安排一个指针指向堆栈的顶端,指针以上是未分配的,指针以下是已分配的。对于每个分配请求,只需要把指针向上移动相应的字节数量,要释放最后分配的内存,也只需要下移指针即可。
根据上文的描述,很多读者大概都注意到:使用堆栈分配器时,内存的释放必须是以分配时相反的次序。要实施这个限制的方法也很简单,我们完全不允许个别内存块的释放,而是提供了两个函数,第一个函数可以在当前栈顶打上标记,第二个函数可以把指针回滚到标记过的位置。
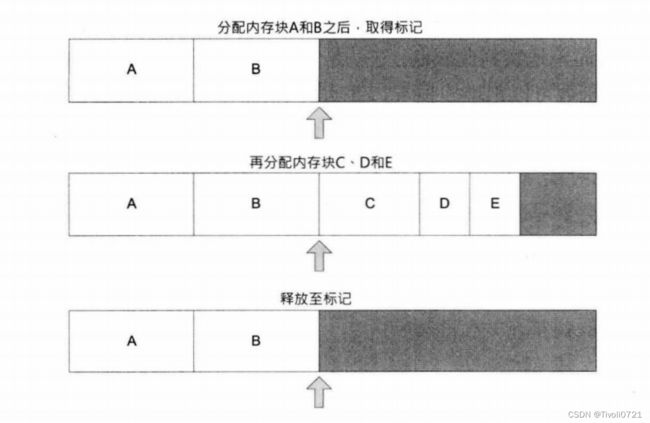
在此基础上,有些游戏采用了更高效的双端堆栈分配器,一块内存其实可以分给两个堆栈分配器使用,它们分别从两端向中间分配内存。在街机游戏 Hydro Thunder 中,设计师使用底堆栈来载入关卡,使用顶堆栈分配临时内存,这种设计获得了极其优异的表现。
池分配器
当我们在游戏编程中,需要分配大量同等尺寸的小块内存时,池分配器是其完美选择。
池分配器的工作方式如下,它首先会预分配一大块内存,其大小刚好是待分配元素大小的倍数。然后这大块内存会按照待分配元素大小切割成小块并挂载到一个链表中。当池分配器收到分配请求时,就会取出链表的下一小块,释放元素时也只需要把这一小块重新挂到链表上。
这样,无论是分配还是释放,都只需要几个指针的运算。
单帧和双缓冲内存分配器
在游戏循环中,我们经常会需要分配一些临时用数据,这些数据要么在循环迭代结束时被丢弃,要么在下一次循环迭代结束时被丢弃。很多游戏引擎都支持这两种分配模式,分别称为单帧分配器和双缓冲分配器
单帧分配器顾名思义就是内存只在某一帧中是有效的。对于单帧分配器,我们先预留一块内存并使用前文的堆栈分配器管理,在每帧开始时,把堆栈的顶端指针重置到内存块的低端地址。如此往复。
双缓冲分配器则是建立两个相同尺寸的单帧分配器,并在每帧交替使用。这样我们在 i + 1 帧时,就可以安心的使用第 i 帧分配的内存里的内容(里面可能存储了第 i 帧产生的数据),这在缓存非同步处理的结果时非常有用。
内存碎片
动态内存分配的另一个问题是,会随时间产生“内存碎片”。关于内存碎片的概念,这里就不多赘述。内存碎片的问题在于,就算有足够的内存,分配请求依然会失败。问题的症结在于分配的内存必须是连续的。在支持虚拟内存的操作系统中,内存碎片并不是大问题,虚拟内存会让应用程序看上去觉得内存是连续的。但碍于其高昂的开销,大多数游戏机都不会使用虚拟内存。
关于如何解决这个问题,首先要说的是:上文中的堆栈及池分配器都不会产生内存碎片。这里介绍另一种方法:碎片整理和重定位
碎片整理的过程非常直观易懂:

我们按上图的方式把内存“压实”是很容易的事。但真正棘手的是:我们移动了已分配的内存块,那么指向这些内存块的指针就会失效。我们需要逐个更新指针,让指针重新指到更新后的地址,这称为“重定位”。
遗憾的是,在C++中,我们无法搜寻指向某个地址范围的所有指针。所以,若要在游戏引擎中支持碎片整理功能,我们就不得不舍弃指针,使用某些在重定位时更容易修改的构件,比如智能指针或者句柄。
智能指针实际上是一个很小的类(class),它包含了一个指针,它的行为和指针几乎完全相同。但是由于它是用类实现的,我们可以让所有的智能指针加入到一个全局链表中,在移动内存时,扫描全局链表并更新指向该内存的指针。
而句柄实际上是一个索引,它指向一个句柄表,句柄表中的每个元素存储着指针。当需要移动内存时,我们扫描句柄表并修改相应的指针即可。需要注意的是,句柄本身是不应被重定位的。
重定位的另一个难题是,一些第三方库可能是不使用句柄或者智能指针的。对此,通用的做法是,指定一块区域给这些库使用,而不参与重定位过程。如果这种内存块数量少且体积小,重定位系统依然能获得不错的效率。
容器
游戏引擎中使用了各式各样的集合型数据结构,被称为“容器”或者“集合”。这里只作大略的介绍,详细的使用方法并不是本系列文章的重点(可能会更新在【C++总结提炼】系列中)。
每种容器的作用都是安置和管理容器,但它们在细节和运作方式上有很大的差异,常见的容器类型包括但肯定不限于以下:
- 数组:在内存中连续存储的,支持随机访问的元素集合,每个数组的长度是在编译器静态定义的。
- 动态数组:在运行时可以动态改变长度的数据。
- 链表:但数据在内存中非连续存储,不支持随机访问,但能够高效的插入删除。
- 堆栈:采用后进先出的方式新增和移除数据。
- 队列:采用先进先出的方式新增和移除数据。
- 双端队列:可以在两端进行插入和删除操作的队列。
- 优先队列:队列中的元素不再按插入时间排序,而是按优先级拍戏,一般用堆实现。
- 字典:由键值对组成的表,可以高效的通过键查找到对应的值。
- 集合:无重复元素。
使用容器,另一个需要讨论的重点是迭代器。迭代器像是缩影或指针,它知道如何高效的访问容器中的某个元素。下例中分别使用指针和迭代器访问容器:
void processArray(int container[], int numElements){
int *pBegin() = &container[0];
int *pEnd() = &container[numElements];
for(int *p = pBegin(); p != pEend(); p++){
int element = *p;
}
}
void processArray(list<int>& container){
iterator pBegin() = container().begin();
iterator pEnd() = container().end();
iterator p;
for(p = pBegin(); p != pEnd(); p++){
int element = *p;
}
}
读者可能留意到,上例的循环中使用的后置递增 p++。前置和后置递增在for循环的更新中是完全等效的,但此微小的差异有可能对优化很重要。++p首先对运算数进行递增,然后再传回修改后的值,p++先传回修改后的值再进行递增。这意味着,++p会在代码中产生“数据依赖”,必须等完成自增运算后,才能使用该值,在深度流水化的CPU中,这种数据依赖可能会造成“流水线停顿”。而 p++ 则不会产生这种问题,因此对于游戏程序员,最好的习惯总是使用后置递增(除非是使用类类型变量)。
总结
本篇文章介绍了大多数游戏引擎中都会出现的底层支持系统,包括子系统的启动和终止顺序,内存管理,容器的使用等。本系列文章只对《游戏引擎架构》一书中笔者感兴趣的内容做提炼总结,若要了解更多内容,还建议读者自行阅读原书。