Python使用深度神经网络对高光谱图像进行土地覆盖分类
一、前言
高光谱成像是遥感中的一项重要技术,它收集从可见光到近红外波长的电磁波谱。 高光谱成像传感器通常提供来自地球表面同一区域的数百个窄光谱带。 在高光谱图像 (HSI) 中,每个像素都可以看作是一个高维向量,其条目对应于特定波长的光谱反射率。
HSI 具有区分细微光谱差异的优势,已广泛应用于作物分析、地质测绘、矿产勘探、国防研究、城市调查、军事监视、洪水跟踪等各个领域。
二、数据介绍
我们将使用帕维亚大学高光谱图像进行分类。 帕维亚大学 HSI 是在意大利北部帕维亚上空的一次飞行活动中由 ROSIS 传感器获取的。 HSI 数据可在 Group De Inteligencia Computacional (GIC) 上公开获得。

帕维亚大学 HSI 有 103 个光谱波段,包含 610 * 340 像素,但图像的光谱样本不包含定义为零 (0) 的信息,必须在分析前将其丢弃。 几何分辨率为1.3米。 HSI 的 groundtruth 分为 9 类。 ground truth 的信息如下图所示。

三、数据读取
(1)相关依赖库导入
import matplotlib.pyplot as plt
import numpy as np
import earthpy.plot as ep
import seaborn as sns
import earthpy.spatial as es
import plotly.graph_objects as go
import plotly.express as px
from scipy.io import loadmat
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import (accuracy_score,
confusion_matrix, classification_report)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Input, Dense, Dropout, BatchNormalization
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tqdm import tqdm(2)数据读入
通常,此类数据采用 .mat 文件的形式。 所以我们需要读取数据并将其转换为 pandas 数据框以供进一步处理。
data = loadmat('PaviaU.mat')['paviaU']
gt = loadmat('PaviaU_gt.mat')['paviaU_gt']
df = pd.DataFrame(data.reshape(data.shape[0]*data.shape[1], -1))
df.columns = [f'band{i}' for i in range(1, df.shape[-1]+1)]
df['class'] = gt.ravel()(3)真彩色合成
让我们看看 Pavia 大学 HSI 的 ground truth,黑色代表没有信息的像素,在分类过程中将被丢弃。
def plot_data(data):
fig = plt.figure(figsize=(12, 10))
plt.imshow(data, cmap='nipy_spectral')
plt.colorbar()
plt.axis('off')
plt.show()
plot_data(gt)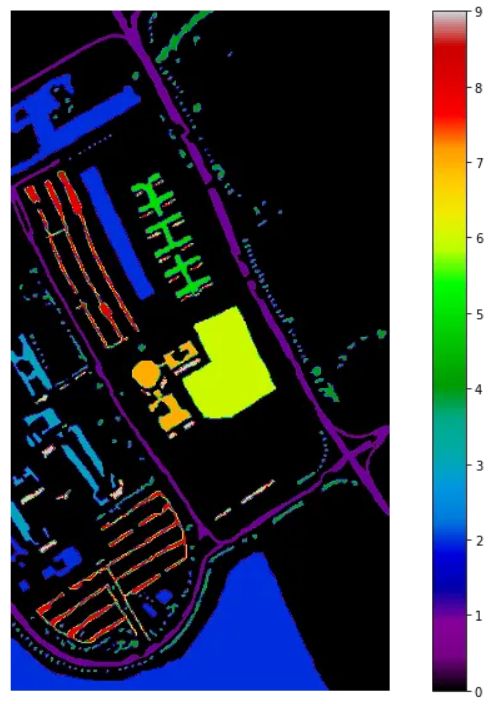
四、神经网络模型构建
一般来说,神经网络是一种用于模拟人脑活动的技术——具体来说,是模式识别和输入通过模拟神经连接的各个层。
深度神经网络定义为具有输入层、输出层和至少一个位于其间的隐藏层的网络。 每个层在一个过程中执行特定类型的排序和排序,有些人将其称为“特征层次结构”。 这些复杂的神经网络的主要用途之一是处理未标记或非结构化数据。 “深度学习”一词也用于描述这些深度神经网络,因为深度学习代表了机器学习的一种特定形式,其中使用人工智能方面的技术寻求以超越简单输入/输出协议的方式对信息进行分类和排序。

在本文中,我们使用具有 12 个全连接层或密集层、批归一化层和 Dropout 层的深度神经网络。
(1)深度神经网络的实现
让我们以 70:30 的比例以分层方式将数据拆分为训练和测试。
X = df[df['class']!=0].iloc[:, :-1].values
y = tf.keras.utils.to_categorical(df[df['class']!=0].iloc[:, -1].values ,
num_classes= np.unique(gt).shape[0],
dtype='float32')
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size = 0.7, stratify = y)
print(f"Train Data: {X_train.shape}\nTest Data: {X_test.shape}")让我们使用 Keras 构建深度神经网络 (DNN),用于帕维亚大学 HSI 的土地覆盖分类。 提到的深度神经网络有一个修正线性单元(ReLU)作为激活函数。
model = Sequential(name='Pavia_University')
model.add(Input(shape = X_train[0].shape, name = 'Input_Layer'))
model.add(BatchNormalization(name = 'BatchNormalization'))
model.add(Dense(units = 128, activation= 'relu', name = 'Layer1'))
model.add(Dense(units = 128, activation= 'relu', name = 'Layer2'))
model.add(Dense(units = 128, activation= 'relu', name = 'Layer3'))
model.add(Dense(units = 128, activation= 'relu', name = 'Layer4'))
model.add(Dropout(rate = 0.2, name = 'Dropout1',))
model.add(Dense(units = 64, activation= 'relu', name = 'Layer5'))
model.add(Dense(units = 64, activation= 'relu', name = 'Layer6'))
model.add(Dense(units = 64, activation= 'relu', name = 'Layer7'))
model.add(Dense(units = 64, activation= 'relu', name = 'Layer8'))
model.add(Dropout(rate = 0.2, name = 'Dropout2'))
model.add(Dense(units = 32, activation= 'relu', name = 'Layer9'))
model.add(Dense(units = 32, activation= 'relu', name = 'Layer10'))
model.add(Dense(units = 32, activation= 'relu', name = 'Layer11'))
model.add(Dense(units = 32, activation= 'relu', name = 'Layer12'))
model.add(Dense(units = y_train.shape[1], activation= 'softmax', name = 'Output_Layer'))
model.summary()(2) 神经网络训练
为了训练定义的 DNN,我使用了 Adam 优化器、分类交叉熵、作为度量的准确性和回调。 下面的代码用于编译和训练模型。
# Compile
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
# Callbacks
es = EarlyStopping(monitor = 'val_loss',
min_delta = 0,
patience = 15,
verbose = 1,
restore_best_weights = True)
checkpoint = ModelCheckpoint(filepath = 'Pavia_University_Model.h5',
monitor = 'val_loss',
mode ='min',
save_best_only = True,
verbose = 1)
# Fit
history = model.fit(x = X_train,
y = y_train,
validation_data = (X_test, y_test),
epochs = 100,
callbacks = [es, checkpoint])(3)Adam优化函数
Adam 是一种优化算法,可用于替代经典的随机梯度下降程序,以基于训练数据迭代更新网络权重。 使用 adam 优化器的优点是:
易于实施。
计算效率高。
内存需求小。
对梯度的对角线重新缩放不变。
非常适合数据和/或参数较大的问题。
适用于非固定目标。
适用于具有非常嘈杂/或稀疏梯度的问题。
超参数具有直观的解释,通常需要很少的调整。
(4)分类交叉熵
交叉熵是用于多类分类问题的默认损失函数。 在这种情况下,它旨在用于多类分类,其中目标值位于集合 {0, 1, 3, …, n} 中,其中每个类都分配有一个唯一的整数值。 在数学上,它是最大似然推理框架下的首选损失函数。 这是首先要评估的损失函数,只有在有充分理由的情况下才会更改。
交叉熵将计算一个分数,该分数总结了问题中所有类别的实际和预测概率分布之间的平均差异。 分数被最小化,完美的交叉熵值为 0。
通过在编译模型时指定“categorical_crossentropy”,可以将交叉熵指定为 Keras 中的损失函数。
(5)回调
EarlyStopping:减少神经网络过度拟合的一种技术是使用提前停止。 如果模型没有真正学到任何东西,提前停止可以通过终止训练过程来防止模型过度训练。 这非常灵活——您可以控制要监控的指标,需要更改多少才能被视为“仍在学习”,以及在模型停止训练之前它可以连续停顿多少个 epoch。
ModelCheckpoint:此回调将在每个成功的纪元后将您的模型作为检查点文件(hdf5 或 h5 格式)保存到磁盘。 您实际上可以将输出文件设置为根据纪元动态命名。 您还可以将损失值或准确度值作为日志文件名的一部分写入。
(6)构建图
训练期间的准确度和损失图的代码以及输出如下所示,X 轴代表时期,Y 轴代表百分比。
hist = pd.DataFrame(data= history.history)
fig = go.Figure()
fig.add_trace(go.Scatter(x = hist.index, y = hist.loss.values,
mode='lines+markers',
name='Train Loss'))
fig.add_trace(go.Scatter(x = hist.index, y = hist.accuracy.values,
mode='lines+markers',
name='Train Accuracy'))
fig.add_trace(go.Scatter(x = hist.index, y = hist.val_loss.values,
mode='lines+markers', name='Test loss'))
fig.add_trace(go.Scatter(x = hist.index, y = hist.val_accuracy.values,
mode='lines+markers', name='Test Accuracy'))
fig.show()
五、结果
分类模型的实证结果显示在表格分类报告中。
# predictions
pred = np.argmax(model.predict(X_test), axis=1)
# Classification Report
print(classification_report(pred, np.argmax(y_test, 1),
target_names = ['1. Asphalt', '2. Meadows', '3. Gravel', '4. Trees',
'5. Painted metal sheets','6. Bare Soil', '7. Bitumen',
'8. Self-Blocking Bricks', '9. Shadows']))
让我们看看混淆矩阵——一种表格表示形式,通常用于描述分类模型(或“分类器”)在一组真实值已知的测试数据上的性能。
plt.figure(figsize = (10,7))
classes = ['Asphalt', 'Meadows', 'Gravel', 'Trees', 'Painted metal sheets',
'Bare Soil', 'Bitumen', 'Self-Blocking Bricks', 'Shadows']
mat = confusion_matrix(np.add(pred, 1), np.add(np.argmax(y_test, 1), 1))
df_cm = pd.DataFrame(mat, index = classes, columns = classes)
sns.heatmap(df_cm, annot=True, fmt='d')
plt.show()
最后,让我们可视化分类图:
l = []
for i in tqdm(range(df.shape[0])):
if df.iloc[i, -1] == 0:
l.append(0)
else:
l.append(np.argmax(model.predict(df.iloc[i, :-1].values.reshape(-1, 103)), 1))
q = np.array(l).reshape(gt.shape).astype('float')
plot_data(q)
六、结论
本文正式介绍了帕维亚大学 HSI 的高光谱图像及其应用、深度神经网络 (DNN) 土地覆盖分类的实现,并以分类报告、混淆矩阵和分类图的形式对结果进行了解释。