免费可商用开源GPT模型问世,50G权重直接下载,性能不输GPT-3
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
真·开源GPT模型,终于来了。
参数量级130亿,大小比肩最近Meta开放的LLaMA-13B,但从数据集、模型权重到计算优化训练,全部开源。
最关键的是,可商用。
没错,虽然就GPT-3而言,之前DeepMind、Meta等组织陆陆续续开源过几个模型,不过基本都是半遮半掩。
尤其最接近GPT-3的Meta OPT模型,不仅权重只开放给研究者,而且不可商用:
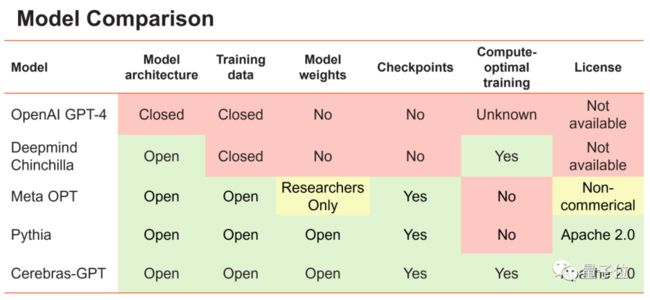
这意味着之前企业就算能抄作业,抄来的也没办法直接用。
现在,一家名叫Cerebras的公司开源了这一系列GPT模型,业界终于有机会追赶了。
模型性能如何?
Cerebras一共开源了7个GPT模型,参数量分别达到1.11亿、2.56亿、5.9亿、13亿、27亿、67亿和130亿。

据Cerebras公司表示,他们开放出来的模型不仅包含数据集,可用于研究也可商用,而且关键是预训练模型权重开放(从下图来看文件大小近50G)。

基于他们公开的预训练模型,大伙儿只需要用少量的数据对对模型进行微调,就能构建出效果不错的模型来。
除此之外,这次GPT模型的训练还额外考虑到了计算优化训练 (Compute-Optimal Training)。
这个方法最早由DeepMind在2022年提出,名叫Chinchilla,它认为大语言模型的语料数量和模型效果之间符合一个凸曲线,因此模型参数量和训练程度成一定比例。
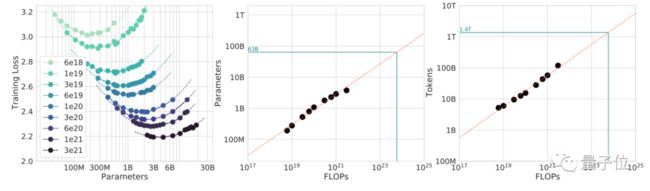
依据这个方法,DeepMind认为,包括GPT-3在内的超大参数LLM模型,有很多都是训练不足的。
基于此,Cerebras搞出了这一系列GPT模型,并将背后的流程进行了开源。
所以,Cerebras-GPT系列模型性能如何呢?
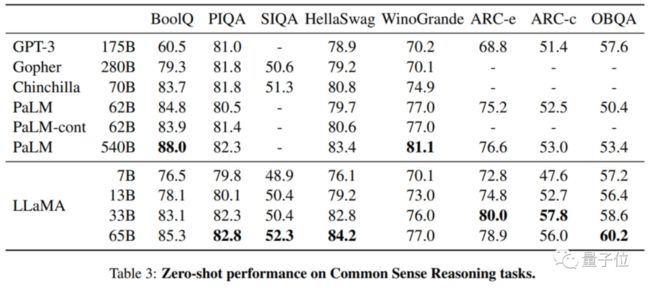
团队将Cerebras-GPT系列和LLaMA、GPT-3等模型的性能进行了对比。
这是包括GPT-3、Gopher、Chinchilla和LLaMA在内的其他GPT模型,在完成句子、问答等特定任务上表现的效果。
这是不同大小的Cerebras-GPT模型零次学习(0-shot)的效果:
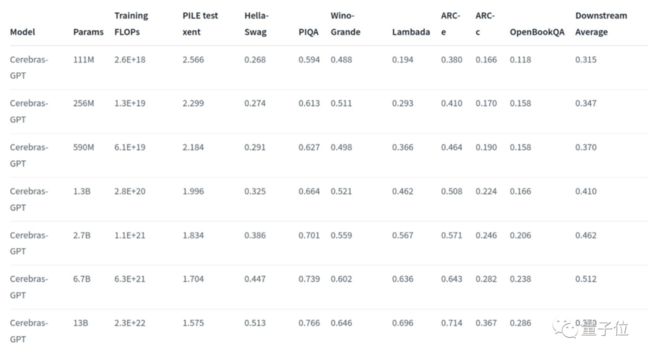
数据对比不是特别直观,团队还将结果进行了可视化。
可以看出,在最终性能相差不大的情况下,Cerebras-GPT的训练效率要更高一些。

曾开发最大AI芯片
其实,Cerebras的“本职”是一家AI芯片公司。
Cerebras公司由Sean Lie和Andrew Feldman等人于2016年创立。
其中,Andrew Feldman曾创建微型服务器公司SeaMicro,并以3.34亿美元的价格出售给AMD。
与其他AI芯片公司不同,Cerebras开发的芯片超大,像晶圆一样(但确实是芯片):

他们当年做出来过一个名叫“晶圆级引擎”(Cerebras Wafer Scale Engine,简称WSE)的AI芯片,将逻辑运算、通讯和存储器集成到单个硅片上,一口气创下了4项世界纪录:
-
晶体管数量最多的运算芯片:总共包含1.2万亿个晶体管。虽然三星曾造出2万亿个晶体管的芯片,却是用于存储的eUFS。
-
芯片面积最大:尺寸约20厘米×23厘米,总面积46,225平方毫米。面积和一块晶圆差不多。
-
片上缓存最大:包含18GB的片上SRAM存储器。
-
运算核心最多:包含40万个处理核心。

后来这个超大WSE又升级了二代,然后团队基于WSE-2打造出了一个名叫Cerebras CS-2的AI超算。
这次的Cerebras-GPT系列模型,就是在这个Cerebras CS-2的AI超算中训练出来的。对此这家公司表示:
虽然训练这么大体量的模型通常需要几个月时间,但我们几周就能搞定。
Cerebras还表示,虽然很多硬件公司都声称训练效果能接近英伟达GPU的水平,但他们还没看到任何一家亲自推动开源LLM的硬件公司,这势必不利于开源LLM的发展。
这波啊,这波Cerebras格局大了(手动狗头)
模型地址:
https://huggingface.co/cerebras/Cerebras-GPT-13B
卡奥斯开源社区是为开发者提供便捷高效的开发服务和可持续分享、交流的IT前沿阵地,包含技术文章、群组、互动问答、在线学习、大赛活动、开发者平台、OpenAPI平台、低代码平台、开源项目等服务,社区使命是让每一个知识工人成就不凡。
官网链接:Openlab.cosmoplat—打造工业互联网顶级开源社区