hive sql常用函数总结
1. limit 与offset用法
1. LIMIT [参数1]--m,参数2--n; #表示从跳过m条数据开始取n行数据 #参数1为可选参数,表示跳过m条数据(默认为0),
-- eg:1表示从第二行开始 #参数2为必选参数,表示取几行数据
-- eg1:
SELECT * FROM table LIMIT 5; //检索前 5 个记录行
等价于
SELECT * FROM table LIMIT 0,5; //检索前 5 个记录行
-- eg2:
SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15 ,为了检索某行开始到最后的所有数据,可以设置第二个参数为-1
-- eg3:
SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last
//注意:这个有时会报错2. LIMIT OFFSET
语法:
-- LIMIT 参数1--m OFFSET 参数2--n
-- 表示跳过n个数据,取m个数据
-- 参数1表示读取m条数据
-- 参数2表示跳过n个数据
-- eg4:
SELECT * FROM table
LIMIT 2 OFFSET 1; //跳过1条数据读取2条数据,即读取2-3条数据
3. 区别
-- 直接看例子
-- eg5:
SELECT * FROM table LIMIT 2,1; //跳过2条数据读取1条数据,即读取3条数据
SELECT * FROM table LIMIT 2 OFFSET 1; //跳过1条数据读取2条数据,即读取2-3条数据
2. Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)
select id
, name
,rank() over(order by score desc) as r
, DENSE_RANK() OVER(order by score desc) as dense_r
, row_number() OVER(order by score desc) as row_r
from students;
//结果如下图所示: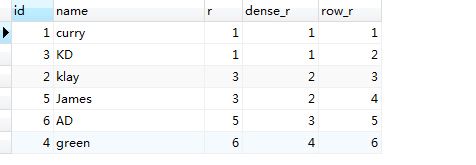
总结:
在使用排名函数的时候需要注意以下三点:
1、排名函数必须有 OVER 子句。
2、排名函数必须有包含 ORDER BY 的 OVER 子句。
3、分组内从1开始排序。
3. 数据库常用函数DECODE()、LAG()、LEAD() 基础用法
(1)DECODE() 如果expression的值等于if1的值,返回value1,如果不等,再和if2比较,相等返回value2,以此类推,如果所有的条件都不满足,返回default默认值。
(2)LAG()这个函数可以取出某个字段前N条记录的值
(3)LEAD()函数与此类似,不过它是查询某字段的后N条记录的值
4. datediff(date1,date2) #返回两个日期之间的天数
select datediff('2021-3-31','2021-3-30');
1
select datediff('2021-3-30','2021-3-31');
-15. mod(id,2)=1,取奇数;mod(id,2)=0,取偶数
6. 剪切
left(str, length) 左剪切
select left('sqlstudy.com', 3);
+-------------------------+
| left('sqlstudy.com', 3) |
+-------------------------+
| sql |
+-------------------------+right(str, length) 右剪切
select right('sqlstudy.com', 3);
+--------------------------+
| right('sqlstudy.com', 3) |
+--------------------------+
| com |
+--------------------------+substring(str, pos); substring(str, pos, len)
-- 从字符串的第 4 个字符位置开始取,直到结束
select substring('sqlstudy.com', 4);
+------------------------------+
| substring('sqlstudy.com', 4) |
+------------------------------+
| study.com |
+------------------------------+
-- 从字符串的第 4 个字符位置开始取,取前五个字符
select substring('sqlstudy.com', 4,5);
+------------------------------+
| substring('sqlstudy.com', 4,5) |
+------------------------------+
| study |
+------------------------------+
-- 从字符串的第 4 个字符位置(倒数)开始取,直到结束。
select substring('sqlstudy.com', -4);
+-------------------------------+
| substring('sqlstudy.com', -4) |
+-------------------------------+
| .com |
+-------------------------------+substring index()
7. 拼接
基础拼接:concat()
分组拼接:group_concat(distinct 字段 order by 字段 separator '连接符号')
8. 累积求和
基础结构:sum(字段) over()
复杂结构:sum(字段) over(partition by 字段 order by 字段 rows between ... and...)
- partition by 需要分组的字段,可省略
- order by 需要排序的字段,按照这个排序进行累加求和,可省略
- rows between 参与计算的行起始位置 and 参与计算的行末尾位置,可省略
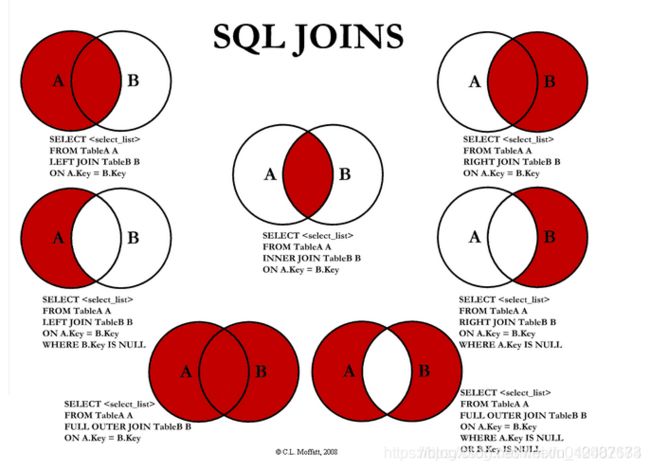
9. LEFT OUTER JOIN 与 LEFT JOIN,RIGHT OUTER JOIN 与RIGHT JOIN ,FULL OUTER JOIN 与 FULL JOIN区别与联系
9. case when 与聚合函数
聚合函数只能套用在case when 外面,例如:
sum(case when ...)
count(case when...)
10. 每天回刷7天数据
-- CREATE TABLE if not exists 表名(
-- status_name STRING
-- )
-- COMMENT "名"
-- PARTITIONED by (
-- ds STRING
-- )LIFECYCLE 7; -- 回刷订单状态 保留最新7天数据