论文笔记:BPR-Bayesian Personalized Ranking from Implicit Feedback | 推荐系统BPR算法分析
BPR:Bayesian Personalized Ranking from Implicit Feedback
论文链接:BPR:Bayesian Personalized Ranking from Implicit Feedback
会议:UAI2009
转载请声明出处: https://blog.csdn.net/angus_huang_xu/article/details/114499030
文章目录
-
-
- BPR:Bayesian Personalized Ranking from Implicit Feedback
-
- 1. 背景
- 2. 问题建模
- 3. BPR基本思想
- 4. 算法中的应用
- 5. 实验结果
-
1. 背景
物品推荐主要任务是为每个用户创建特定的商品排序,用户对于物品的偏好是根据用户以往的购买记录等信息学习到的。根据获得的用户数据来分类可以将推荐任务分为两类,基于显式反馈的推荐和基于隐式反馈的推荐。
显式反馈一般指的是用户对商品的喜好程度被量化表示,比如豆瓣上用户对电影的打分,分数越高就代表越喜欢。
隐式反馈则是无法量化表示用户对物品喜好程度的数据,比如用户浏览或者点击某商品。
在商品推荐领域常用的方法有矩阵分解(Matrix Factorization)和最近邻搜索(kNN)等。但是这两种方法都没有针对推荐排序问题的优化方法,因此本文提出一个关于针对个性化推荐排序问题的优化方法——BPR-OPT,并将其应用到MF和kNN方法之中。
本文的主要贡献有:
- 提出了一种基于最大后验估计的优化指标BPR-OPT;
- 为了最大化BPR-OPT,提出了一种通用的基于带有bootstrap采样的随机梯度下降学习算法LearnBPR;
- 将LearnBPR算法应用到MF和kNN两种模型中;
2. 问题建模
U , I U, I U,I 分别表示为所有的user和item的集合,隐式反馈 S ⊆ U × I S\subseteq U\times I S⊆U×I(一般表现为0-1矩阵,即user和item有交互对应位置为1,否则为0)。用 > u ⊂ I 2 >_u \subset I^2 >u⊂I2 表示用户 u u u 对物品直接的偏好关系。若 i > u j i>_uj i>uj 表示用户 u u u 更喜欢物品 i i i。
为了方便表示,我们记:
I u + = { i ∈ I : ( u , i ) ∈ S } U i + = { u ∈ U : ( u , i ) ∈ S } I_u^+ = \{i\in I:(u, i)\in S\}\\ U_i^+ = \{u\in U:(u, i)\in S\}\\ Iu+={i∈I:(u,i)∈S}Ui+={u∈U:(u,i)∈S}
值得一提的是,这种序关系满足三条性质:
∀ i , j ∈ I : i ≠ j ⇒ i > u j ∨ j > u i (totality) ∀ i , j ∈ I : i > u j ∧ j > u i ⇒ i = j (antisymmetry) ∀ i , j , k ∈ I : i > u j ∧ j > u k ⇒ i > u k (transitivity) \begin{array}{lr} \forall i, j \in I: i \neq j \Rightarrow i>_{u} j \vee j>_{u} i & \text { (totality) } \\ \forall i, j \in I: i>_{u} j \wedge j>_{u} i \Rightarrow i=j & \text { (antisymmetry) } \\ \forall i, j, k \in I: i>_{u} j \wedge j>_{u} k \Rightarrow i>_{u} k & \text { (transitivity) } \end{array} ∀i,j∈I:i=j⇒i>uj∨j>ui∀i,j∈I:i>uj∧j>ui⇒i=j∀i,j,k∈I:i>uj∧j>uk⇒i>uk (totality) (antisymmetry) (transitivity)
实际上我们的问题转换成下图所示:已知左侧的矩阵信息,预测出矩阵中未知的信息。

当然,实际情况并不是像图中表示的只需要预测出0-1,一般算出user对item的rating,一般情况分数越高表示偏好程度越高,而后根据此分数来进行排序。
在本文中,解决问题的一个方式是每次优化一个item对,优化的并不是用户对单个item的评分,而是用户对两个item的
偏好关系。有:
D S : = { ( u , i , j ) ∣ i ∈ I U + ∧ j ∈ I \ I u + } D_S:=\{(u,i,j)|i\in I_U^+\land j\in I \backslash I_u^+ \} DS:={(u,i,j)∣i∈IU+∧j∈I\Iu+}
那么, ( u , i , j ) ∈ D S (u,i,j)\in D_S (u,i,j)∈DS 就表示 u u u 在 i , j i,j i,j 中更喜欢 i i i,此为正样本,那么反过来 ( u , j , i ) (u,j,i) (u,j,i) 即为负样本。

这种建模方法有两个优点:
- 这样处理后data既包含正样本也包含负样本以及缺失信息的样本。比如两个都没有交互的物品之间的序关系就是未知的,是我们要学的;
- 这样构造的数据是直接为了学习排序的,体现了一种序关系。
3. BPR基本思想
-
BPR-OPT优化指标
首先根据贝叶斯公式有:
p ( Θ ∣ > u ) ∝ p ( > u ∣ Θ ) p ( Θ ) p(\Theta|>_u) \propto p(>_u|\Theta)p(\Theta) p(Θ∣>u)∝p(>u∣Θ)p(Θ)这里,我们有两个基本假设:
1. 所有user之间的偏好关系是相互独立的 2. 同一用户对不同物品的偏序相互独立,即我们假设用户对 (i,j) 的偏好是不受其他商品影响的。这里我们需要最大化的有两项,第一项跟数据有关,第二项跟模型参数有关。首先我们来看第一项,那么有:
∏ u ∈ U p ( > u ∣ Θ ) = ∏ ( u , i , j ) ∈ U × I × I p ( i > u j ∣ Θ ) δ ( ( u , i , j ) ∈ D S ) ⋅ ( 1 − p ( i > u j ∣ Θ ) ) δ ( ( u , i , j ) ∉ D S ) \prod_{u\in U} p(>_u|\Theta) = \prod_{(u,i,j)\in U\times I\times I}p(i>_u j|\Theta)^{\delta((u,i,j)\in D_S)}\cdot (1-p(i>_u j|\Theta))^{\delta((u,i,j)\notin D_S)} u∈U∏p(>u∣Θ)=(u,i,j)∈U×I×I∏p(i>uj∣Θ)δ((u,i,j)∈DS)⋅(1−p(i>uj∣Θ))δ((u,i,j)∈/DS)
(注意,原论文中第二个概率上角标有误)
现在让我们来化简该项,对于每个user,给定商品对 (i,j) ,其关系有四种:δ ( ( u , i , j ) ∈ D S ) \delta((u,i,j)\in D_S) δ((u,i,j)∈DS) i是正样本 i是未观测的样本 j是正样本 0 0 j是未观测的样本 1 0 根据以上关系,上式可以化简为:
∏ u ∈ U p ( > u ∣ Θ ) = ∏ ( u , i , j ) ∈ D S p ( i > u j ∣ Θ ) 2 \prod_{u\in U} p(>_u|\Theta) = \prod_{(u,i,j)\in D_S}p(i>_u j|\Theta)^2 u∈U∏p(>u∣Θ)=(u,i,j)∈DS∏p(i>uj∣Θ)2
根据概率的非负性,上面式子将平方去掉和原式等价,那么就有论文中的形式:
∏ u ∈ U p ( > u ∣ Θ ) = ∏ ( u , i , j ) ∈ D S p ( i > u j ∣ Θ ) \prod_{u\in U} p(>_u|\Theta) = \prod_{(u,i,j)\in D_S}p(i>_u j|\Theta) u∈U∏p(>u∣Θ)=(u,i,j)∈DS∏p(i>uj∣Θ)
为了最大化上面的式子,我们需要找到一个用来合理表示 p ( i > u j ∣ Θ ) p(i>_u j|\Theta) p(i>uj∣Θ)的函数,它需要具有上面讲到的三个性质,论文中选择 sigmoid 函数。即:
p ( i > u j ∣ Θ ) = σ ( x ^ u i j ( Θ ) ) p(i>_uj|\Theta) = \sigma(\hat x_{uij}(\Theta)) p(i>uj∣Θ)=σ(x^uij(Θ))
其中, σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1.为什么要选择sigmoid函数呢?
这里个人的理解是因为在这种偏序关系的体现中,用户在正样本和未观测样本之间偏向一个正样本的概率应该很接近1,所以sigmoid作为一个很接近阶跃函数的可导函数很适用。x ^ u i j ( Θ ) \hat x_{uij(\Theta)} x^uij(Θ)为模型对用户u对 i 和 j 相对的打分,视模型而定
看完贝叶斯公式中对似然函数项的分析后,我们接下来看看对第二项先验分布的优化:
采用的方法是先假定 Θ \Theta Θ 服从高斯分布,均值为0,方差为协方差矩阵 ∑ Θ \sum_\Theta ∑Θ
p ( Θ ) ∼ N ( 0 , ∑ Θ ) p(\Theta)\sim N(0, {\sum}_{\Theta}) p(Θ)∼N(0,∑Θ)为了减少参数的数量,令 ∑ Θ = λ Θ I \sum_{\Theta}=\lambda_{\Theta}I ∑Θ=λΘI,那么原先的优化问题就转换为:
BPR-OPT : = ln p ( Θ ∣ > u ) = ln p ( > u ∣ Θ ) p ( Θ ) = ln ∏ ( u , i , j ) ∈ D S σ ( x ^ u i j ) p ( Θ ) = ∑ ( u , i , j ) ∈ D S ln σ ( x ^ u i j ) + ln p ( Θ ) = ∑ ( u , i , j ) ∈ D S ln σ ( x ^ u i j ) − λ Θ ∥ Θ ∥ 2 \begin{aligned} \text { BPR-OPT } &:=\ln p\left(\Theta \mid>_{u}\right) \\ &=\ln p\left(>_{u} \mid \Theta\right) p(\Theta) \\ &=\ln \prod_{(u, i, j) \in D_{S}} \sigma\left(\hat{x}_{u i j}\right) p(\Theta) \\ &=\sum_{(u, i, j) \in D_{S}} \ln \sigma\left(\hat{x}_{u i j}\right)+\ln p(\Theta) \\ &=\sum_{(u, i, j) \in D_{S}} \ln \sigma\left(\hat{x}_{u i j}\right)-\lambda_{\Theta}\|\Theta\|^{2} \end{aligned} BPR-OPT :=lnp(Θ∣>u)=lnp(>u∣Θ)p(Θ)=ln(u,i,j)∈DS∏σ(x^uij)p(Θ)=(u,i,j)∈DS∑lnσ(x^uij)+lnp(Θ)=(u,i,j)∈DS∑lnσ(x^uij)−λΘ∥Θ∥2
其中, λ Θ ∥ Θ ∥ 2 \lambda_\Theta\|\Theta\|^2 λΘ∥Θ∥2 就是正则化项。为什么BPR-OPT和AUC指标类似?
首先来看些AUC指标:
通常定义AUC是ROC曲线下的面积,用来衡量模型能不能将用户喜欢的和不喜欢的分辨出来。但是在推荐系统中ROC曲线绘制比较繁琐,一般采用如下近似:
A U C ( u ) : = 1 ∣ I u + ∣ ∣ I \ I u + ∣ ∑ i ∈ I u + ∑ j ∈ I \ I u + δ ( x ^ i j > 0 ) AUC(u) := \frac{1}{|I_u^+| |I\backslash I_u^+|}\sum_{i\in I_u^+}\sum_{j\in I\backslash I_u^+}\delta(\hat x_{ij} >0) AUC(u):=∣Iu+∣∣I\Iu+∣1i∈Iu+∑j∈I\Iu+∑δ(x^ij>0)(该公式论文中也写错了,在第二个求和号下标多加了一个集合的势的符号)AUC指标对所有用户平均有:
A U C = 1 ∣ U ∣ ∑ u ∈ U A U C ( u ) AUC = \frac{1}{|U|}\sum_{u\in U}AUC(u) AUC=∣U∣1u∈U∑AUC(u)利用前面提出的 D S D_S DS 的定义,可以改写成:
A U C ( u ) = ∑ ( u , i , j ) ∈ D S z u δ ( x ^ i j > 0 ) , z u = 1 ∣ U ∣ ∣ I u + ∣ ∣ I \ I u + ∣ AUC(u) = \sum_{(u,i,j)\in D_S}z_u\delta(\hat x_{ij}>0),\quad z_u=\frac{1}{|U||I_u^+||I\backslash I_u^+|} AUC(u)=(u,i,j)∈DS∑zuδ(x^ij>0),zu=∣U∣∣Iu+∣∣I\Iu+∣1BPR-OPT和AUC的相似性显然可以看出来,区别在于AUC指标里面用的 δ \delta δ 函数通常是阶跃函数,不可导;而在BPR-OPT中改用 σ \sigma σ 函数,是通常用来代替阶跃函数的一种可导的函数。
-
BPR算法
根据上面提出的BPR-OPT指标,我们采用梯度下降的算法。对BPR-OPT指标求导:
∂ B P R − O P T ∂ Θ = ∑ ( u , i , j ) ∈ D S ∂ ∂ Θ ln σ ( x ^ u i j ) − λ Θ ∂ ∂ Θ ∥ Θ ∥ 2 ∝ ∑ ( u , i , j ) ∈ D S − e − x ^ u i j 1 + e − x ^ u i j ⋅ ∂ ∂ Θ x ^ u i j − λ Θ Θ \begin{aligned} \frac{\partial \mathrm{BPR}-\mathrm{OPT}}{\partial \Theta} &=\sum_{(u, i, j) \in D_{S}} \frac{\partial}{\partial \Theta} \ln \sigma\left(\hat{x}_{u i j}\right)-\lambda_{\Theta} \frac{\partial}{\partial \Theta}\|\Theta\|^{2} \\ & \propto \sum_{(u, i, j) \in D_{S}} \frac{-e^{-\hat{x}_{u i j}}}{1+e^{-\hat{x}_{u i j}}} \cdot \frac{\partial}{\partial \Theta} \hat{x}_{u i j}-\lambda_{\Theta} \Theta \end{aligned} ∂Θ∂BPR−OPT=(u,i,j)∈DS∑∂Θ∂lnσ(x^uij)−λΘ∂Θ∂∥Θ∥2∝(u,i,j)∈DS∑1+e−x^uij−e−x^uij⋅∂Θ∂x^uij−λΘΘ
算法流程如下:1: LearnBPR 算法 2: 初始化 Θ 3: 循环直至收敛: 4: 从 Ds 中取出 (u,i,j) 5: 利用梯度下降更新 Θ 6: 返回模型参数 Θ针对该算法还需要考虑的一个问题是使用哪种梯度下降算法,完全梯度下降还是随机梯度下降。
- 完全梯度下降
完全梯度下降每次需要对所有的(u,i,j)三元组进行计算梯度,带来的问题其一是每次计算量太大,在推荐任务中用户数和商品数望望都是十分大的,一次性计算所有三元组的梯度不太现实;其二是对于每一个用户,通常只有少部分交互过的商品,大部分商品都是没有交互的,因此对于每一个i,会有很多j 来组成pair,商品 i 在梯度中就占了主导地位,这种倾斜也会带来收敛速度慢。 - 随机梯度下降
随机梯度下降是每次计算梯度只选择一个(u,i,j)三元组进行计算,但是需要考虑的问题是以什么顺序遍历所有的三元组,如何选择。常见的顺序都是 item-wise或者 user-wise,但是由于推荐中数据的稀疏性,都会带来倾斜,和上面完全梯度下降有同样的问题。在本文中,提出了的解决方法也很简单,使用随机选择的策略选择用于计算的三元组。
文中给出了user-wise的随机梯度下降和本文随机选择策略的随机梯度下降算法收敛性的差别:
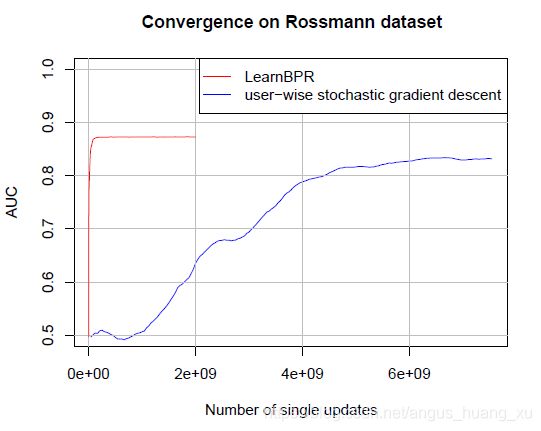
- 完全梯度下降
4. 算法中的应用
本文给出了LearnBPR算法在两个常见的推荐的模型MF(Matrix Factorization)和kNN(k Nearest Neighbor)中的应用。由于在这两种模型中,输出的都是用户u对商品i的打分 x ^ u i \hat x_{ui} x^ui,和BPR算法需要的item pair不一样,所以定义:
x ^ u i j = x ^ u i − x ^ u j \hat x_{uij}=\hat x_{ui}-\hat x_{uj} x^uij=x^ui−x^uj
-
MF(Matrix Factorization)
矩阵分解的思想就是将数据中得到的 rating矩阵 X ∈ { 0 , 1 } ∣ U ∣ × ∣ I ∣ X\in \{0,1\}^{|U|\times |I|} X∈{0,1}∣U∣×∣I∣ 拆解成两个矩阵 W : ∣ U ∣ × k W:|U|\times k W:∣U∣×k和 H : ∣ I ∣ × k H:|I|\times k H:∣I∣×k,分别代表user矩阵和item矩阵,将模型的预测定义为:
X ^ : = W H T x ^ u i = ⟨ w u , h i ⟩ = ∑ f = 1 k w u f ⋅ h i f \hat X:= WH^T\\ \hat x_{ui} =\langle w_u ,h_i\rangle=\sum_{f=1}^kw_{uf}\cdot h_{if} X^:=WHTx^ui=⟨wu,hi⟩=f=1∑kwuf⋅hif
那么目标就变成了优化 X X X 和 X ^ \hat X X^ 之间的距离,常用的MF方法有 SVD-MF, WR-MF.- SVD-MF:
基本思想是利用奇异值分解将X矩阵分解为W和H矩阵,详见博客 【SVD在推荐系统中的应用详解以及算法推导】 - WR-MF(Weighted Regularized Matrix Factorization):
本质上也是基于SVD,但是对loss函数进行优化,形式为:
∑ u ∈ U ∑ i ∈ I c u i ( ⟨ w u , h i ⟩ − 1 ) 2 + λ ∥ W ∥ f 2 + λ ∥ H ∥ f 2 \sum_{u \in U} \sum_{i \in I} c_{u i}\left(\left\langle w_{u}, h_{i}\right\rangle-1\right)^{2}+\lambda\|W\|_{f}^{2}+\lambda\|H\|_{f}^{2} u∈U∑i∈I∑cui(⟨wu,hi⟩−1)2+λ∥W∥f2+λ∥H∥f2
其中, c u i c_{ui} cui 不是模型参数,是相关权重,基于人为预先设定的。
在BPR-OPT指标中,我们需要的导数关系:
∂ ∂ θ x ^ u i j = { ( h i f − h j f ) if θ = w u f , w u f if θ = h i f − w u f if θ = h j f 0 else \frac{\partial}{\partial \theta} \hat{x}_{u i j}=\left\{\begin{array}{ll} \left(h_{i f}-h_{j f}\right) & \text { if } \theta=w_{u f}, \\ w_{u f} & \text { if } \theta=h_{i f} \\ -w_{u f} & \text { if } \theta=h_{j f} \\ 0 & \text { else } \end{array}\right. ∂θ∂x^uij=⎩⎪⎪⎨⎪⎪⎧(hif−hjf)wuf−wuf0 if θ=wuf, if θ=hif if θ=hjf else
对于正则化系数,设置有3个: λ W , λ H + , λ H − \lambda_W,\lambda_{H^+},\lambda_{H^-} λW,λH+,λH−,分别用于对W和正负样本的H做正则。 - SVD-MF:
-
Adaptive k-Nearest-Neighbor
k近邻搜索是传统协同过滤算法中最常用的一种,它是一种基于用户相似度或者物品相似度度量后选择k个最近邻的物品进行推荐的。简单的以基于物品的来说,对于一个用户,以他的历史记录作为参考,选择k个距离其历史记录中的商品最近的商品作为其推荐。其中,有:
x ^ u i = ∑ l ∈ I u + ∧ l ≠ i c i l \hat x_{ui}=\sum_{l\in I_u^+\land l\neq i}c_{il} x^ui=l∈Iu+∧l=i∑cil
其中, c i l c_{il} cil是商品与商品之间的距离度量矩阵,也就是模型的参数。导数关系如下:
∂ ∂ θ x ^ u i j = { + 1 if θ ∈ { c i l , c l i } ∧ l ∈ I u + ∧ l ≠ i − 1 if θ ∈ { c j l , c l j } ∧ l ∈ I u + ∧ l ≠ j 0 else \frac{\partial}{\partial \theta} \hat{x}_{u i j}=\left\{\begin{array}{ll} +1 & \text { if } \theta \in\left\{c_{i l}, c_{l i}\right\} \wedge l \in I_{u}^{+} \wedge l \neq i \\ -1 & \text { if } \theta \in\left\{c_{j l}, c_{l j}\right\} \wedge l \in I_{u}^{+} \wedge l \neq j \\ 0 & \text { else } \end{array}\right. ∂θ∂x^uij=⎩⎨⎧+1−10 if θ∈{cil,cli}∧l∈Iu+∧l=i if θ∈{cjl,clj}∧l∈Iu+∧l=j else
5. 实验结果
文章在两个数据集上进行AUC指标的评估,结果如下图:
