Python深度学习实例--使用预训练的卷积神经网络进行图像数据处理(猫狗分类)
1.预训练的卷积神经网络
想要将卷积神经网络应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络。预训练网络(pretrained network)是一个保存好的网络,之前已在大型数据集(通常是大规模图像分类任务)上训练好。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型,因此这些特征可用于各种不同的计算机视觉问题,即使这些新问题涉及的类别和原始任务完全不同。
举个例子,你在 ImageNet(一个包含140万张图像的数据集) 上训练了一个网络(其类别主要是动物和日常用品),然后将这个训练好的网络应用于某个不相干的任务,比如在图像中识别家具。这种学到的特征在不同问题之间的可移植性,是深度学习与许多早期浅层学习方法相比的重要优势,它使得深度学习对小数据问题非常有效。
在此例中我们将使用 VGG16 架构,它由 Karen Simonyan 和 Andrew Zisserman 在 2014 年开发 。对于ImageNet,它是一种简单而又广泛使用的卷积神经网络架构。虽然 VGG16 是一个比较旧的模型,性能远比不了当前最先进的模型,而且还比许多新模型更为复杂,但是由于它的架构非常简单,无须引入新概念就可以很好地理解。
2.使用预训练网络的方法之一:特征提取(feature extraction)
2.1特征提取
特征提取是使用之前网络学到的表示来从新样本中提取出有趣的特征。然后将这些特征输入一个新的分类器,从头开始训练。
我们都知道,用于图像分类的卷积神经网络包含两部分:首先是一系列池化层和卷积层,最后是一个密集连接分类器。第一部分叫作模型的卷积基(convolutional base)。对于卷积神经网络而言,特征提取就是取出之前训练好的网络的卷积基,在上面运行新数据,然后在输出上面训练一个新的分类器,见下图 。
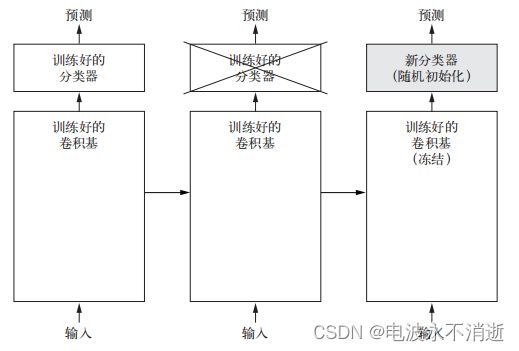
这里我们需要注意两点,第一:我们能否也重复使用密集连接分类器?一般来说,应该避免这么做。原因在于卷积基学到的表示可能更加通用,因此更适合重复使用。卷积神经网络的特征图表示通用概念在图像中是否存在,无论面对什么样的计算机视觉问题,这种特征图都可能很有用。但是,分类器学到的表示必然是针对于模型训练的类别,其中仅包含某个类别出现在整张图像中的概率信息。此外,密集连接层的表示不再包含物体在输入图像中的位置信息。密集连接层舍弃了空间的概念,而物体位置信息仍然由卷积特征图所描述。如果物体位置对于问题很重要,那么密集连接层的特征在很大程度上是无用的。第二:某个卷积层提取的表示的通用性(以及可复用性)取决于该层在模型中的深度。模型中更靠近底部的层提取的是局部的、高度通用的特征图(比如视觉边缘、颜色和纹理),而更靠近顶部的层提取的是更加抽象的概念(比如“猫耳朵”或“狗眼睛”)。因此,如果你的新数据集与原始模型训练的数据集有很大差异,那么最好只使用模型的前几层来做特征提取,而不是使用整个卷积基。
2.2 实例化VGG16卷积网络
VGG16 等模型内置于 Keras 中。你可以从 keras.applications 模块中导入。
代码实现:
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
这里向构造函数传入了三个参数:
weights :指定模型初始化的权重检查点。
include_top :指定模型最后是否包含密集连接分类器。默认情况下,这个密集连接分类器对应于 ImageNet 的 1000 个类别。因为我们打算使用自己的密集连接分类器(只有两个类别:cat 和 dog),所以不需要包含它。
input_shape :是输入到网络中的图像张量的形状。这个参数完全是可选的,如果不传入这个参数,那么网络能够处理任意形状的输入。
下图是VGG16卷积卷积基的详细架构。

由上图可以看出,最后提取到的特征图形状为(4,4,512),我们在VGG16框架后面添加一个密集分类器就完成了整个网络的搭建,这个步骤一共有两种方法。
- 在数据集上运行卷积基,将输出保存成硬盘中的 Numpy 数组,然后用这个数据作为输入,输入到独立的密集连接分类器中(与本书第一部分介绍的分类器类似)。这种方法速度快,计算代价低,因为对于每个输入图像只需运行一次卷积基,而卷积基是目前流程中计算代价最高的。但出于同样的原因,这种方法不允许你使用数据增强。
- 在顶部添加 Dense 层来扩展已有模型(即 conv_base),并在输入数据上端到端地运行整个模型。这样你可以使用数据增强,因为每个输入图像进入模型时都会经过卷积基。但出于同样的原因,这种方法的计算代价比第一种要高很多。
首先来看第一种方法的代码,运行 ImageDataGenerator 实例,将图像及其标签提取为 Numpy 数组。然后调用 conv_base 模型的 predict 方法来从这些图像中提取特征。
代码实现:
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = 'D:\cats_and_dogs' #这是我自己存放数据的地方,有疑问请看我的上一篇博客。
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512)) # 特征
labels = np.zeros(shape=(sample_count)) # 标签
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break # 注意,这些生成器在循环中不断生成数据,所以必须在读完所有图像后终止循环
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000) # 训练 验证 测试数据均要进行特征提取
输出:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
由VGG16卷积基的架构图可知,提取的特征形状为 (samples, 4, 4, 512)。我们要将其输入到密集连接分类器中,所以首先必须将其形状展平为 (samples, 8192)。
代码实现:
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
最后定义一个密集连接分类器(注意要使用 dropout 正则化),并在刚刚保存的数据和标签上训练这个分类。
代码实现:
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))
绘制训练过程中的损失与精度曲线。
代码实现:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
输出:


下面我们来看一下特征提取的第二种方法,它的速度更慢,计算代价更高,但在训练期间可以使用数据增强。这种方法就是:扩展 conv_base 模型,然后在输入数据上端到端地运行模型。(这种方法代码很高,只有在GPU的情况下才能尝试运行。)模型的行为和层类似,所以可以Sequential模型中添加一个模型(比如conv_base),就像添加一个层一样。
代码实现:
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
现在的模型架构如下图所示。

如上图所示,VGG16 的卷积基有 14 714 688 个参数。在其上添加的分类器有 200 万个参数。
值得注意的是,在编译和训练模型之前,一定要“冻结”卷积基。冻结(freeze)一个或多个层是指在训练过程中保持其权重不变。如果不这么做,那么卷积基之前学到的表示将会在训练过程中被修改。因为其上添加的 Dense 层是随机初始化的,所以非常大的权重更新将会在网络中传播,对之前学到的表示造成很大破坏。在 Keras 中,冻结网络的方法是将其 trainable 属性设为 False。 为了让这些修改生效,必须重新编译模型。
代码实现:
onv_base.trainable = False
训练模型:
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
绘制训练过程中的损失与精度曲线。


如上图所示,验证精度约为96%,这比自己训练一个小型神经网络要好的多。