爬梯:ElasticSearch分布式搜索引擎
学习资料:狂神说
ElactisSearch 7.6.2
ElasticSearch
分布式搜索引擎
1. 概述
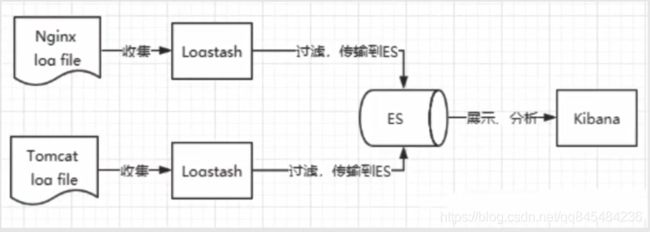
1.1 ELK
ELK是ElasticSearch、Logstash、Kibana三大开源架构首字母大写简称,市面上也被称为Elastic Etack。
-
ElasticSearch是以RESTful方式进行近实时地搜索平台框架,提供存储和搜索;
-
Logstash是ELK的中央数据流引擎,用于从不同目标(文件、数据存储、mq)收集不同格式的数据,经过过滤然后输出到不同的目的地(文件、mq、redis、ElasticSearch、kafka等);
-
Kibana可以将ElasticSearch的数据通过友好的页面展示出来,实现实时分析功能。
1.2 ElasticSearch 简介
elasticsearch 作者:Shay Banon,简称es
es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据。本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
es是使用java开发,基于lucene来实现素有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文检索变得更简单。
根据国际权威的数据库产品测评机构DB Engines的统计,在2016年1月,ElasticSearch一超过Solr等,成为排名第一的搜索引擎类应用。
1.3 Solr简介
Solr是Apache的一个顶级开源项目,采用Java开发,基于Lucene的一个全文搜索服务器。Solr提供了比Lucene更丰富的查询语言,同时实现可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行在Jetty、Tomcat等Servlet容器中。
- 通过Post请求向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据xml文档进行添加、删除、修改操作。
- 通过Get请求对Solr发起搜索,返回Xml、Json等格式的查询结果进行解析,组织页面布局。
1.4 Lucene简介
Lucene是一套信息检索工具包,索引结构,读写索引的工具、排序,搜索规则。不包含搜索引擎。
在java开发环境中,Lucene是一个成熟的免费开源工具。
1.5 ElasticSearch VS Solr
- 对已存在的数据进行检索:es < solr
- 对数据添加索引:es > solr
- 随着数据量增大,查询性能:es > solr
- es自带分布式协调管理功能,solr需要zookeeper进行分布式管理;
- es仅支持json,solr支持json、xml、csv等;
1.6 Kibana简介
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。 使用Kibana ,
可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪
表板( dashboard )实时显示ElasticSearch查询动态。
官网:http://www.elastic.co/cn/kibana
2. ElasticSearch环境
官网地址:https://www.elastic.co/products/elasticsearch
2.1 ElasticSearch 下载、解压、运行
es windows版 7.6.2 下载链接
ps:es需要jdk1.8以上版本
下载解压后目录结构:
bin #启动关闭等批处理
config #配置文件
elasticsearch.yml #ed的配置文件,默认9200端口,跨域等配置
log4j2 #日志配置文件
jvm.options #java虚拟机相关配置
jdk #运行环境
lib #相关jar包
modules #功能模块
plugins #插件
启动:
启动bin目录下的 elasticsearch.bat
启动完成:

2.2 ElasticSearch head 下载、安装、运行
es head 是一个es的可视化工具
elasticsearch-head地址:https://github.com/mobz/elasticsearch-head/
下载解压后,在elasticsearch-head-master目录下运行cmd,下载相关依赖
npm install
因为外网下载很慢,这里附加安装cnpm的方法:
- 先安装cpnm
npm install -g cnpm -registry=https://registry.npm.taobao.org
- 安装自动配置好环境变量,直接使用cnpm -v版本。如果没有配置环境变脸可以百度跟着修改环境变量即可。
安装完依赖后,在head目录启动
npm run start
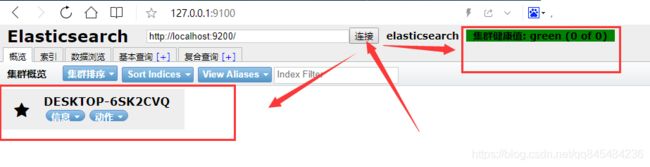
配置es可跨域访问:
找到es/config/elasticsearch.yml。在末尾添加一下配置,表示开启跨域访问,匹配任何地址
http.cors.enabled: true
http.cors.allow-origin: '*'
改完,重新启动es
es启动完成后,回到es head点击[链接]按钮
新建索引:
可以把“索引”当作数据库来理解。
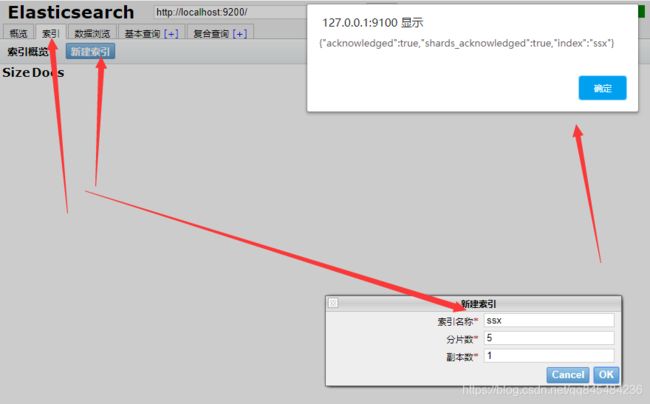
创建了一个 ssx 的索引,在 “ 数据浏览” 可以查看该索引的数据。
2.3 Kibana下载、安装、运行
kibana windows版 7.6.2 下载地址
-
下载解压
-
下载依赖
在kibana目录下执行
cnpm install -
启动
启动bin目录下 kibana.bat

-
使用kibana国际化语言包汉化
...kibana目录\x-pack\plugins\translations\translations\zh-CN.json这里可以看到有中文翻译
打开kibana配置文件 \config\kibana.yml
在最后面加上:
i18n.locale: "zh-CN"修改配置后需要重启kibana
3. ES 核心概念
初步认识后,搭建好es环境,就开始深入了解es的核心概念了。
elasticSearch是面向文档的数据库。
一切都是JSON!
| Relational DataBase | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types:用的比较少,将来可能会淘汰。 |
| 行(rows):数据 | documents |
| 字段(columns) | fields |
3.1 物理设计:
ES在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器之间迁移。
es一个服务就是一个集群,默认集群名称:easticsearch。
3.2 逻辑设计:
一个索引中包含多个文档。
3.2.1 文档
文档就好比关系型数据库中的一条一条记录
tb_user
1 ssx 18
2 jaychow 23
es是面向文档的,也就是搜索的最小单位是文档。
es中的文档的重要属性:
- 自我包含:一片文档同事包含字段和对应的值,也就是同时包含key:value;
- 层次型:一个文档中包含自文档,可以形成复杂的逻辑实体;
- 灵活的结构:文档不依赖预先定义的模式,意思是不需要提前确定好字段信息,动态的添加字段。
尽管可以随意新增或忽略某个字段,但每个字段的类型非常重要,比如年龄字段可以是整型也可以是字符。es会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的各种类型,所以es中类型有时候又叫映射类型。
3.2.2 类型
数据类型
类型是文档的逻辑容器,就像表格是行的容器一样。类型中对于字段的定义称为映射,比如name映射为字符串类型。
文档是无模式的,新增一个字段时,es会自动匹配一个类型,但这种匹配是不准确的。所以一般都会定义好这个字段的类型,以杜绝不必要的麻烦。
3.2.3 索引
数据库
索引是映射类型的容器,es中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其它设置。然后它们被存储在各个分片上。
节点和分片:
一个集群至少有一个节点,而一个节点就是一个es进程。如果创建索引,那么索引将会默认有5个分片(primary shard,又称主分片)构成,每一个主分片会有一个副本(replica shard,又称复制分片)。
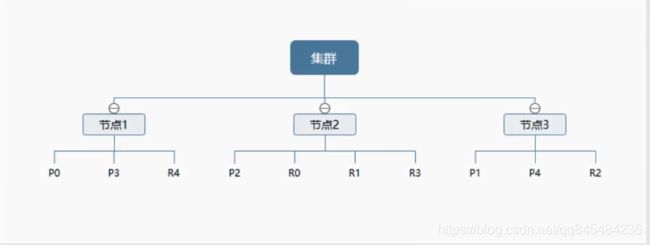
上图是一个es集群,有3个节点。
以P为例,P0为主分片,其它P1、P2都不在同一个节点上。实现了es高可用集群。
实际上一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得es在不扫面全部文档的情况下,就能实现关键字搜索。
倒排索引:
es使用的是一种成为倒排索引的结构,采用Lucene倒排索引作为底层支持。这种结构适用于快速的全文搜索。
一个索引由文档中所有不重复的列构成,对于每一个词都有一个包含它的文档列表。
需要创建倒排索引,首先将每个文档拆分成独立的词(词条、tokens),然后创建一个不重复的的排序的词条列表,里面列出每个词条出现在哪个文档。
个人理解:这种倒排索引的意思,不是将123=>321的顺序倒排,而是逻辑的反转。普通索引就是ID做一个主键索引,然后根据这个创建好B+Tree索引,而这个倒排索引是将内容(词)抽出来,反向地将记录再排一遍构成倒排索引!
示例:
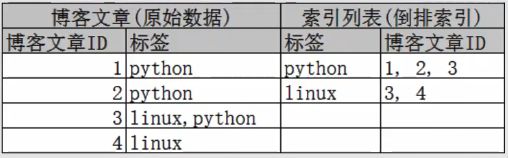
那么这么做的好处是,当来一个关键字的时候,先在倒排索引中,找到哪些文档有这个关键字,直接去对应文档中再找,规避了全库全文档的索引,是一种优化手段。
在es中,索引被分成了多个分片,每份分片是一个Lucene的索引。所以说es索引是由多个Lucene索引组成。所以一般说索引指的是es的索引。只是es索引的底层聚合了Lucene的索引。
4. IK 分词器
分词就是把一段词,分开成多个字。
而中文的分词,一般是把一段词分称一个一个词语:美丽的一天 -> 美丽、的、一天。
然后针对中文分词的插件:ik分词器。
ik分词器提供了两个分词算法:
- ik_smart:最少切分
- ik_max_word:最细粒度切分
4.1 安装
github
7.6.2 下载地址
下载、解压、放入es的plugins目录中,重启es

使用elasticsearch-plugin查看加载的插件

4.2 测试
使用kibana测试两种分词算法
4.2.1 ik_smart
最少切分算法
进行最简短的拆分并且没有重复的词
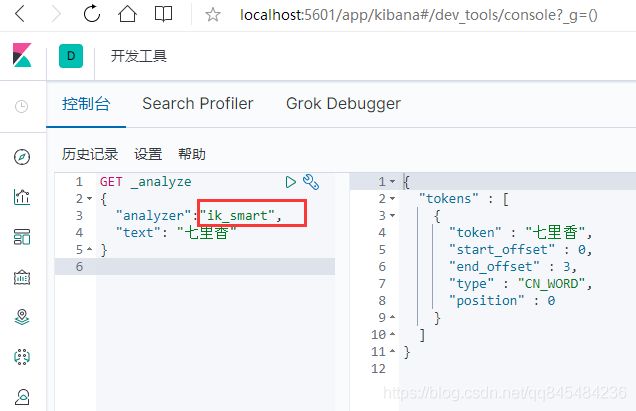
如果对:“石似心”进行拆分,会被拆成三个字,属于自造词,原本并不存在。这种自造词需要加入词库。
4.2.2 ik_max_word
最细粒算法
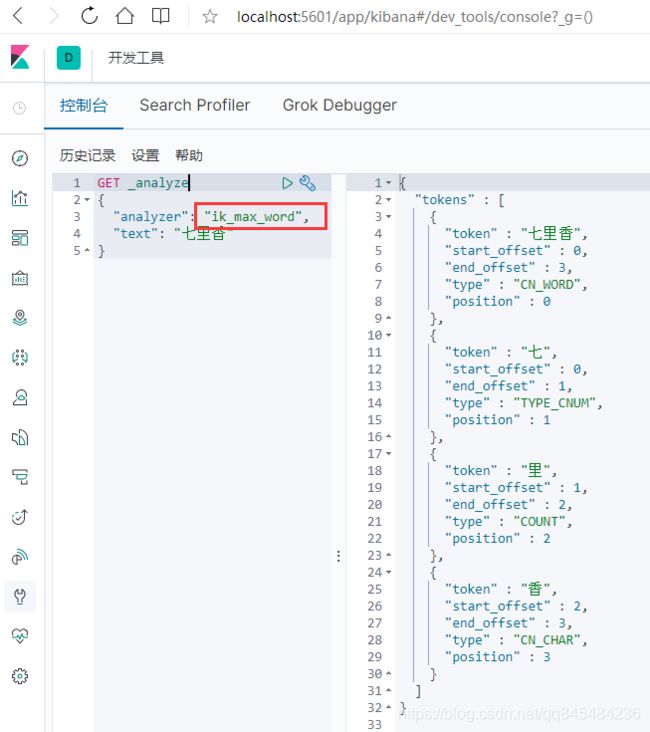
4.3 配置自定义词库
来到ik分词器的配置文件夹 config
里面有很多dic格式的文件,这些都是默认的词库。
-
创建一个文件:ssx.dic
-
里面写入:石似心
-
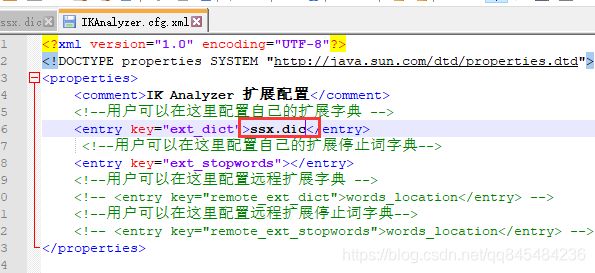
找到ik分词器的配置文件
...\plugins\elasticsearch-analysis-ik-7.6.2\config\IKAnalyzer.cfg.xml
- 将自定义的词库文件引入
-
重启es
-
再次使用ik_smart拆分“石似心”
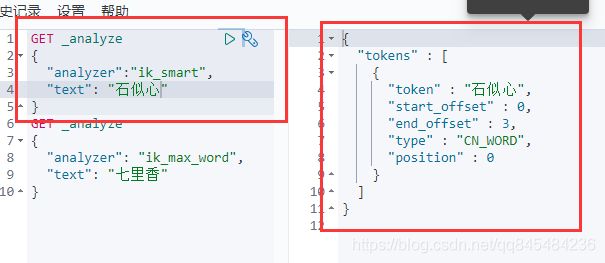
被判定为一个词
5. Rest风格操作ES
发送请求操作es的数据
| Method | url | 说明 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档ID | 创建文档,指定文档ID |
| POST | localhost:9200/索引名称/类型名称 | 创建文档,随机文档ID |
| POST | /索引名称/类型名称/文档ID/_update | 修改文档 |
| DELETE | /索引名称/类型名称/文档ID | 删除文档 |
| GET | /索引名称/类型名称/文档ID | 通过文档ID查询文档 |
| POST | /索引名称/类型名称/_search | 查询所有数据 |
在kibana上使用Rest风格的语句操作es
5.1 PUT
5.1.1 PUT /索引名称/类型名称/文档ID
指定索引、类型、文档
PUT /test01/type01/doc01
{
"name":"石似心",
"money":100
}
返回值:
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "test01", //索引名称
"_type" : "type01", //类型名称
"_id" : "doc01", //文档id
"_version" : 1, //版本1
"result" : "created", //索引状态
"_shards" : { //分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
5.1.2 创建索引规则
创建索引规则(指定属性对应的类型)
PUT /索引名称
PUT /test02
{
"mappings": {
"properties": {
"name": { //属性
"type": "text" //类型
},
"age": { //属性
"type": "long" //类型
},
"birthday": { //属性
"type": "date" //类型
}
}
}
}
返回值:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test02"
}
查看test02:
GET test02
查看索引:test02的属性
{
"test02" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"birthday" : {
"type" : "date"
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1602658651489",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "nn-fPvRGSfqqqXVsNQGglw",
"version" : {
"created" : "7060299"
},
"provided_name" : "test02"
}
}
}
}
5.1.3 PUT /索引/_doc/文档
不指定类型创建索引和文档
PUT /test03/_doc/001
{
"name":"高山低谷"
}
返回值:
{
"_index" : "test03",
"_type" : "_doc",
"_id" : "001",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
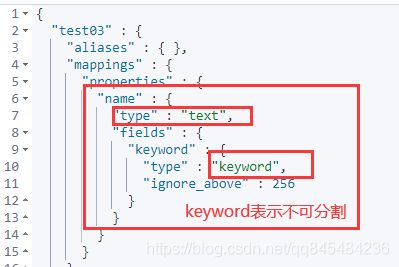
查看test03中的name的数据类型:
GET test03
返回值:(es自动配置的类型)
5.1.4 PUT 实现修改
覆盖式的修改,会将原来的001中的属性直接全部替换为新的值
PUT /test03/_doc/001
{
"age":"2"
}
返回值:
{
"_index" : "test03",
"_type" : "_doc",
"_id" : "001",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : { //已经没有name属性
"age" : "2"
}
}
5.2 POST
5.2.1 _update实现指定属性修改
当一个文档中有多个属性时,一般只是需要修改某个属性,而不影响其它属性。
POST /test03/_doc/001/_update
{
"doc": {
"name": "晴天"
}
}
查看test03:
{
"_index" : "test03",
"_type" : "_doc",
"_id" : "001",
"_version" : 10,
"_seq_no" : 9,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "晴天",
"age" : "3"
}
}
只有name属性修改了。
5.3 DELETE 删除索引
DELETE test01
返回值:
{
"acknowledged" : true
}
5.4 GET 时间简单查询
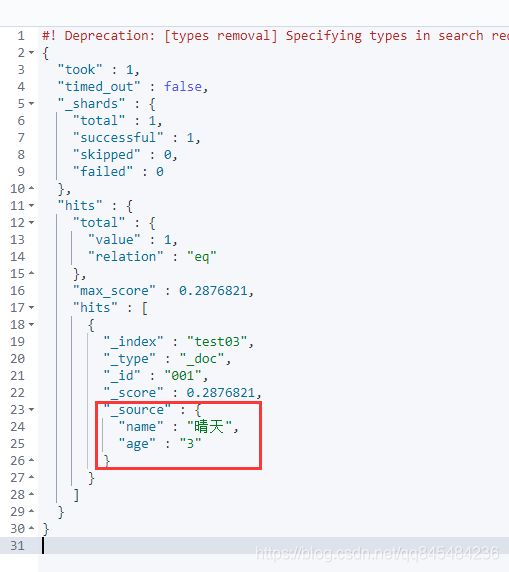
GET test03/_doc/_search?q=name:晴天
返回结果:
- 5 _cat 命令
5.5.1 查看ES健康状态
GET _cat/health
返回值:
1602660039 07:20:39 elasticsearch yellow 1 1 11 11 0 0 8 0 - 57.9%
5.5.2 查看索引的状态
GET _cat/indices
返回值:
yellow open test03 DvMoFyzxRi60IgrqaGGowA 1 1 1 2 11.7kb 11.7kb
yellow open test02 nn-fPvRGSfqqqXVsNQGglw 1 1 0 0 283b 283b
yellow open test01 mYAGuQCqRLe9TeJpZDl_LA 1 1 1 0 3.7kb 3.7kb
green open .kibana_task_manager_1 N-2MnNffTp6L3uweAK-GZw 1 0 2 0 12.3kb 12.3kb
green open .apm-agent-configuration fz-TKC2tQ82UJ3z6NX8BEg 1 0 0 0 283b 283b
yellow open ssx sBLSKchzSROHqEnOXuC94g 5 1 0 0 1.3kb 1.3kb
green open .kibana_1 -HhBXxQtRMqLdYSzKzIvqA 1 0 14 5 58.4kb 58.4kb
6. 复杂查询语法
排序、分页、高亮、模糊…
准备了一些数据:
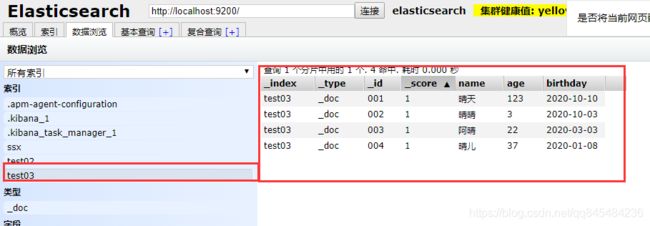
6.1 基础查询
GET test03/_search
{
"query":{
"match":{
"name":"晴天"
}
}
}
返回结果:

6.2 结果过滤
“_source”: [“name”]
限制返回值只有name
GET test03/_doc/_search
{
"query":{
"match":{
"name":"晴天"
}
},
"_source": ["name"]
}
6.3 排序
sort
我测试的时候排text类型的属性会报错,估计只能排一些有排序逻辑的类型:long、date…
GET test03/_search
{
"query":{
"match":{
"name":"晴天"
}
},
"_source": ["name","birthday"],
"sort": [
{
"birthday": {
"order": "asc"
}
}
]
}
返回结果:
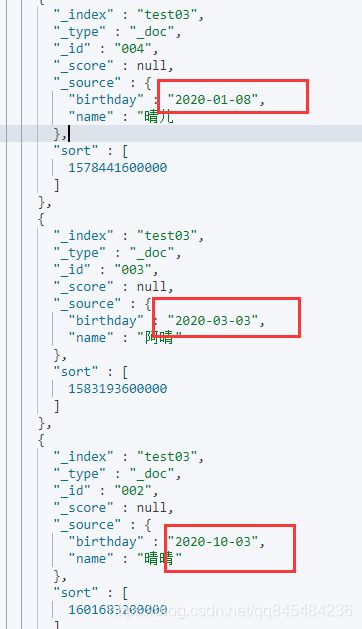
可以看到,排序之后的_score 分值直接返回null。
6.4 分页
from:从第几条数据开始
size:获取多少条数据
GET test03/_search
{
"query":{
"match":{
"name":"晴天"
}
},
"_source": ["name","birthday"],
"sort": [
{
"birthday": {
"order": "asc"
}
}
],
"from":0,
"size":1
}
返回结果:

6.5 布尔查询
多条件筛选、匹配或不匹配筛选:
must、must_not......
must:全部匹配(and)
should:可能 (or)
must_not:不匹配(not、不等于)
GET test03/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "晴天"
}
},
{
"match": {
"age": "3"
}
}
]
}
}
}
6.6 过滤器
filter
区间过滤
- gt >
- gte >=
- lt <
- lte <=
需求生日在:2020-01-08~2020-03-03之间
GET test03/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "晴天"
}
}
],
"filter": [
{
"range": {
"birthday": {
"gte": "2020-01-08",
"lte": "2020-03-03"
}
}
}
]
}
}
}
6.7 精确查询
match:使用分词器进行解析
term:查询直接通过倒排索引指定的词条进行精确查找。
验证:
创建test4索引,配置索引映射类型。
keyword是不可拆分的类型。
PUT test04
{
"mappings": {
"properties": {
"name_k": {
"type": "keyword"
},
"name_t": {
"type": "text"
}
}
}
}
数据
PUT test04/_doc/1
{
"name_k": "石似心",
"name_t": "石似心"
}
PUT test04/_doc/2
{
"name_k": "石似心2",
"name_t": "石似心2"
}
使用分词器查询:
GET _analyze
{
"analyzer": "keyword",
"text": "石似心"
}
使用分词器返回值:
{
"tokens" : [
{
"token" : "石似心",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
}
]
}
使用默认的分词查询:
GET _analyze
{
"analyzer": "standard",
"text": "石似心"
}
使用默认的分词返回值:(被解析为单个词)
{
"tokens" : [
{
"token" : "石",
"start_offset" : 0,
"end_offset" : 1,
"type" : "" ,
"position" : 0
},
{
"token" : "似",
"start_offset" : 1,
"end_offset" : 2,
"type" : "" ,
"position" : 1
},
{
"token" : "心",
"start_offset" : 2,
"end_offset" : 3,
"type" : "" ,
"position" : 2
}
]
}
多个值的精确查询:
精确查询“name_k”等于“石似心2”或者“石似心”
GET test04/_search
{
"query":{
"bool": {
"should": [
{
"term": {
"name_k": "石似心2"
}
},
{
"term": {
"name_k": "石似心"
}
}
]
}
}
}
6.9 高亮
指定属性进行高亮
GET test04/_search
{
"query":{
"bool": {
"should": [
{
"term": {
"name_k": "石似心2"
}
}
]
}
},
"highlight": {
"pre_tags": "",
"post_tags": "
",
"fields": {
"name_k": {}
}
}
}
返回值:
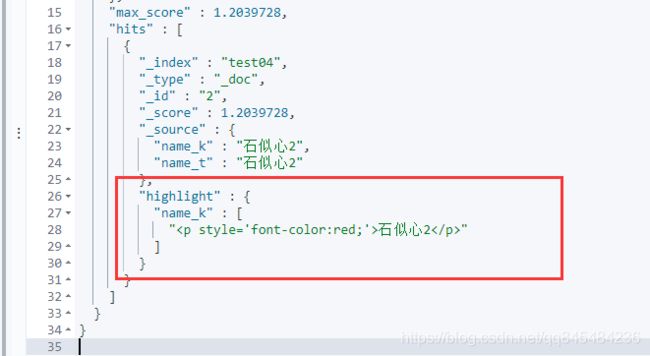
7. 集成SpringBoot
7.1 springboot与es
-
引入依赖
<properties> <elasticsearch.version>7.6.2elasticsearch.version> properties> <dependencies> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-elasticsearchartifactId> dependency> ...... -
配置客户端bean
import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.beans.factory.annotation.Configurable; import org.springframework.context.annotation.Bean; /** * es配置类,注入客户端bean */ @Configurable public class ElasticSearchConfig { @Bean public RestHighLevelClient restHighLevelClient(){ /** * 配置集群地址 */ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("127.0.0.1",9200,"http") ) ); return client; } }
es的配置还有一些,官网好像也没看到有完整的配置信息说明,但是根据狂神的介绍找到springboot的自动配置类,可以了解到比较完整的es配置。
自动配置源码:
package org.springframework.boot.autoconfigure.elasticsearch;
import org.elasticsearch.client.RestClient;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
/**
* {@link EnableAutoConfiguration Auto-configuration} for Elasticsearch REST clients.
*
* @author Brian Clozel
* @author Stephane Nicoll
* @since 2.1.0
*/
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RestClient.class)
@EnableConfigurationProperties(ElasticsearchRestClientProperties.class)
@Import({ ElasticsearchRestClientConfigurations.RestClientBuilderConfiguration.class,
ElasticsearchRestClientConfigurations.RestHighLevelClientConfiguration.class,
ElasticsearchRestClientConfigurations.RestClientFallbackConfiguration.class })
public class ElasticsearchRestClientAutoConfiguration {
}
里面主要是引入三个内部类进行了一些配置:
@Import({ ElasticsearchRestClientConfigurations.RestClientBuilderConfiguration.class,
ElasticsearchRestClientConfigurations.RestHighLevelClientConfiguration.class,
ElasticsearchRestClientConfigurations.RestClientFallbackConfiguration.class })
以后再去深入研究,循序渐进,现在先把es全面认识完。
7.2 api操作es索引
测试三条api
@SpringBootTest
class AEsApiApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 测试创建索引
*/
@Test
void testCreateIndex() throws IOException {
//创建 “创建索引”的 http 请求
CreateIndexRequest testCreateIndex = new CreateIndexRequest("test_api_index");
// 使用客户端.索引操作.创建,传入“创建索引”的请求,使用默认参数
CreateIndexResponse createIndexResponse =
restHighLevelClient.indices().create(testCreateIndex, RequestOptions.DEFAULT);
//返回创建的索引名称
System.out.println(createIndexResponse.index());
}
/**
* 测试获取索引
*/
@Test
void testGetIndex() throws IOException {
//创建 “获取索引”的 http 请求
GetIndexRequest getIndexRequest = new GetIndexRequest("test_api_index");
// 使用客户端.索引操作.获取,传入“获取索引”的请求,使用默认参数
GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
Arrays.stream(getIndexResponse.getIndices()).forEach(System.out::println);
}
/**
* 测试删除索引
*/
@Test
void testDeleteIndex() throws IOException {
//创建 “获取索引”的 http 请求
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("test_api_index");
// 使用客户端.索引操作.获取,传入“获取索引”的请求,使用默认参数
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
}
7.3 api操作es文档
7.3.1 创建文档
/**
* 测试创建文档
*/
@Test
void testAddDocument() throws IOException{
//实体类
User user = new User("石似心",18);
//创建请求,指定关联的索引
IndexRequest indexRequest = new IndexRequest("test_api_index");
//设置相关配置
//PUT /test_api_index/_doc/001
indexRequest.id("001");
indexRequest.timeout("1s");
//实体类数据放入请求
indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
//使用es客户端将请求发送出去,返回响应
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
console
IndexResponse[index=test_api_index,type=_doc,id=001,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
CREATED
7.3.2 获取文档
/**
* 测试判断指定文档是否存在
*/
@Test
void testExistsDocument() throws IOException{
//创建GET请求
GetRequest getRequest = new GetRequest("test_api_index","001");
//不获取返回的 _source
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
/**
* 测试获取对应文档
*/
@Test
void testGetDocument() throws IOException{
//创建GET请求
GetRequest getRequest = new GetRequest("test_api_index","001");
//访问
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
System.out.println(getResponse);
}
console
{"age":18,"name":"石似心"}
{"_index":"test_api_index","_type":"_doc","_id":"001","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"age":18,"name":"石似心"}}
7.3.3 修改文档
/**
* 测试修改对应文档
*/
@Test
void testUpdateDocument() throws IOException{
UpdateRequest updateRequest = new UpdateRequest("test_api_index", "001");
updateRequest.timeout(TimeValue.timeValueSeconds(1));
//新的user,填入更新请求,说明传入的是JSON类型的数据
User user = new User("给未来的自己",30);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
//提交请求
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(update.status());
}
7.3.4 批量增加文档
bulk
/**
* 测试批量添加文档
*/
@Test
void testBulkAddDocument() throws IOException{
//批量处理请求
BulkRequest bulkRequest = new BulkRequest();
List<User> userList = new ArrayList<User>(){{
add(new User("多想爱这个世界啊",12));
add(new User("如果有一天",22));
add(new User("我不曾爱过你",32));
add(new User("你是否知道",42));
add(new User("我自己骗自己",52));
}};
//将用户填入IndexRequest,在填入BulkRequest
AtomicInteger i = new AtomicInteger(0);
userList.forEach(u->{
i.incrementAndGet();
bulkRequest.add(
// 批量新增、批量删除、批量修改.....
new IndexRequest("ssx")
.id(i.toString())
.source(JSON.toJSONString(u), XContentType.JSON)
);
});
//发送请求
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk.status());
System.out.println(bulk.hasFailures());//失败数
}

7.3.5 查询
查询中使用了很多各种各样的builder。
/**
* 测试查询
*/
@Test
void testSearch() throws IOException{
//查询请求
SearchRequest searchRequest = new SearchRequest("ssx");
//构建查询的内容
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(1, TimeUnit.SECONDS));
/*
* 使用QueryBuilders组装查询条件
* QueryBuilders.matchQuery()
* QueryBuilders.termQuery() //精确查找
*/
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("age", 12);
sourceBuilder.query(termQueryBuilder);
//将拼装好的查询条件放入查询请求
searchRequest.source(sourceBuilder);
//发送查询请求
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(search.getHits()));
//打印结果
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
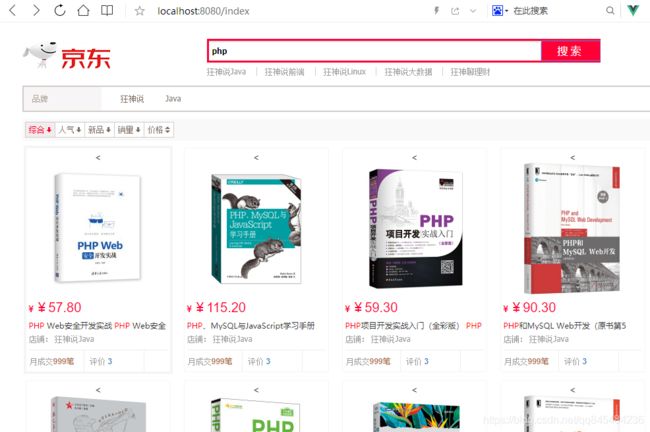
8. 实战
创建一个新项目,导入狂神整理的静态页面。
模拟京东的搜索,仅做学习用。

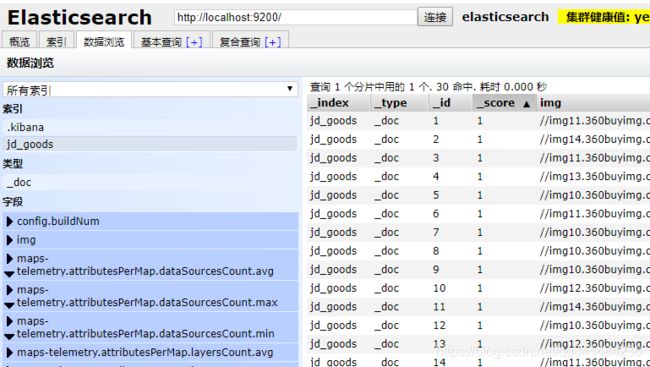
8.1 准备数据
jsoup爬取30条京东搜索页的数据做学习用。
8.2 实现查询逻辑
/**
* 查询数据
*/
public List<Map<String,Object>> searchData(String keywords,int page,int pageSize) throws IOException {
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("name", keywords);
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("name", keywords);
sourceBuilder.query(queryBuilder);
sourceBuilder.timeout(TimeValue.timeValueSeconds(10));
sourceBuilder.from(page);
sourceBuilder.size(pageSize);
searchRequest.source(sourceBuilder);
//高亮设置
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("");
highlightBuilder.postTags("");
highlightBuilder.field("name");
sourceBuilder.highlighter(highlightBuilder);//应用高亮设置
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchRequest.toString());
List<Map<String,Object>> goodsList = new ArrayList<>();
Arrays.stream(search.getHits().getHits()).forEach(g->{
Map<String, Object> sourceAsMap = g.getSourceAsMap();
goodsList.add(sourceAsMap);
//处理高亮字段
HighlightField highlightField = g.getHighlightFields().get("name");
if(highlightField!=null){
StringBuffer highlightName = new StringBuffer();
Arrays.stream(highlightField.fragments()).forEach(f->{highlightName.append(f.toString());});
sourceAsMap.put("name",highlightName);
}
});
return goodsList;
}
效果: