Vision Transformer学习笔记
Vison Transformer学习笔记
- 1. 前言
- 2. 网络结构&设计原理
-
- 2.1 Linear Projection of Flattened Patches
- 2.2 Transformer Encoder
-
- 2.2.1 Layer Normalization
- 2.2.2 Multi-Head Attention
- 2.2.3 Dropout/DropPath
-
- 2.2.3.1 Dropout
- 2.2.3.2 DropPath
- 2.2.4 MLP Block
- 2.3 MLP Head
- 3. 相关问题总结
参考链接:
1. Vision Transformer详解
2. Transformer模型详解
1. 前言
Transformer最初提出是针对NLP领域,并且在NLP领域大获成功。这篇论文也是受到其启发,尝试将Transformer应用到CV领域。
2. 网络结构&设计原理

上图是Vision Transformer的整体模型框架,它主要由Linear Projection of Flattened Patches、Transformer Encoder和MLP Head三个部分组成。原论文中设计了三种不同规模大小的Vision Transformer模型,如下表所示。

2.1 Linear Projection of Flattened Patches
对于标准的Transformer模块,要求输入的是向量序列(tokens),即维度为(num_token, token_dim)的二维矩阵。而图像数据是三维矩阵,其数据格式为(height, width, channel),因此需要通过一个Embedding层将其转换为二维矩阵。

以ViT-B/16为例,假设输入图片的维度为(224, 224, 3),将一张图片按照 16 16 16× 16 16 16的大小进行划分,划分后得到 ( 224 / 16 ) 2 = 14 × 14 = 196 (224/16)^2=14×14=196 (224/16)2=14×14=196个patch,每个patch的尺寸为 16 16 16× 16 16 16。

在实际代码中,Vision Transformer使用了大小为 16 16 16× 16 16 16,步长为 16 16 16,卷积核个数为 768 768 768的二维卷积,将维度为(224, 224, 3)的输入图片分割成 196 196 196个大小为 16 16 16× 16 16 16的patch,每个patch的通道维度为 768 768 768,同时将这 196 196 196个patch映射到一维向量中,最终得到一个(196, 768)的二维向量。

作者借鉴了BERT,在上面生成的一系列tokens前面插入了一个用于分类的class token。这个class token是一个可训练的参数,与其他token一样都是一个向量,在上述例子中,其维度为(1, 768),因此将class token与其他token拼接后得到一个(197, 768)的二维向量。
最后引入了一个Positional Encoding来加入序列的位置信息,它是一个可训练的参数,通常直接与上面的tokens相加,因此其维度也与上面的tokens相同,均为(197, 768)。
2.2 Transformer Encoder
Vision Transformer只使用了Transformer中的Encoder部分,而没有使用Decoder部分。Transformer Encoder由多个Encoder Block串联构成,主要包含了Layer Nomalization、Multi-Head Attention、Dropout/DropPath和MLP Block。

2.2.1 Layer Normalization
论文链接:https://arxiv.org/pdf/1607.06450.pdf
在图像处理领域,卷积神经网络(CNNs)中通常会使用Batch Normalization,根据mini-batch的均值和标准差对深度神经网络的隐藏层输入进行标准化,可以有效地提升训练速度。但是Batch Normalization的效果受制于batch的大小,小batch未必能取得预期效果。其次,对于前向神经网络可以直接应用Batch Normalization,因为其每一层具有固定的神经元数量,可直接计算和存储每层网络中各神经元的均值、方差统计信息以应用于模型预测,但在循环神经网络(RNNs)中,不同的mini-batch可能具有不同的输入序列长度,计算统计信息比较困难,而且测试序列长度不能大于最大训练序列长度。因此循环神经网络(RNNs)使用Layer Normalization对不同时间步进行标准化,从而可以处理单一样本、变长序列,而且训练和测试处理方式一致。Vision Transformer将NLP领域中的模型应用在CV领域,但是作者仍然使用Layer Normalization对数据进行标准化。
以ViT-B/16为例,假设输入序列的数据格式为(batch_size, seq_len, seq_dim), 即(1, 197, 768),Layer Normalization是对输入序列的最后一个维度,即在每个token的特征通道(seq_dim)上计算均值 E ( x ) E(x) E(x)和方差 V a r ( x ) Var(x) Var(x),然后根据如下公式,对输入数据进行标准化。 y = x − E ( x ) V a r ( x ) + ϵ ∗ γ + β y=\frac{x-E(x)}{\sqrt{Var(x)+\epsilon}}*\gamma+\beta y=Var(x)+ϵx−E(x)∗γ+β其中 ϵ \epsilon ϵ表示一个极小的数,防止分母为零, γ \gamma γ表示缩放因子, β \beta β表示偏移因子。
2.2.2 Multi-Head Attention
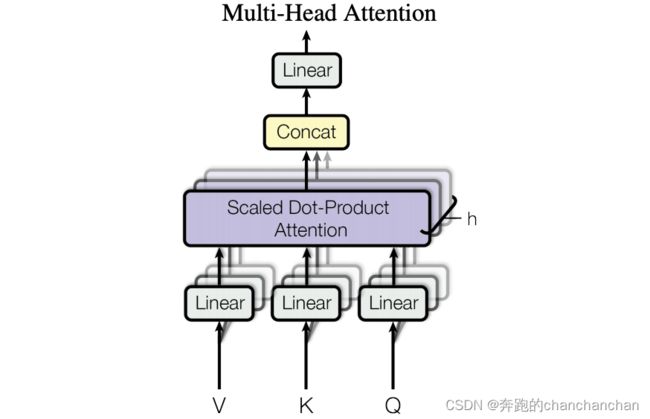
如上图所示,Multi-Head Attention联合来自不同self-attention模块学习到的信息,从而使模型可以从不同角度理解输入的序列。它的具体实现流程如下:
- 假设Head的数目为 h h h,将输入序列均分成 h h h份,得到 h h h个不同的序列;
- 新的序列中的每一个token通过 3 3 3个全连接层分别映射到三个矩阵 Q Q Q, K K K, V V V,其中 Q Q Q指query,表示查询到与该token相关的属性, K K K指key,表示该token自身的属性, V V V指value,表示该token自身所包含的信息;

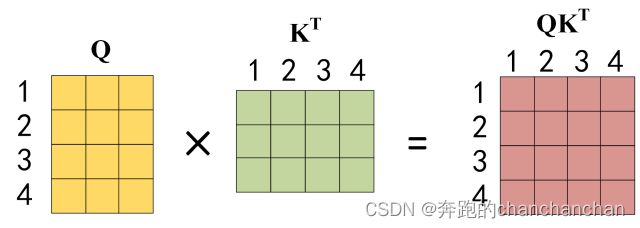
- 对向量 Q Q Q与向量 K K K的转置矩阵进行点积运算,并且根据公式 α = s o f t m a x ( Q K T d k ) \alpha=softmax(\frac{QK^T}{\sqrt{d_k}}) α=softmax(dkQKT),计算不同token之间的相关性。Softmax矩阵包含了不同token之间的相关性系数,例如第1行表示第一个token与自身以及其他token之间的相关性系数;

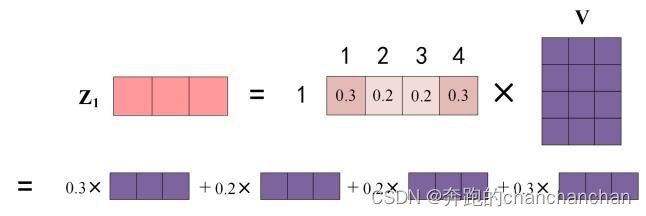
- 根据不同token之间的相关性系数,对不同token进行加权求和,即 A t t e n t i o n ( Q , K , V ) = α × V Attention(Q,K,V)=\alpha×V Attention(Q,K,V)=α×V,从而使模型有重点地关注输入特征;

- 最后将每一个Head中的输出拼接起来,并且通过一个全连接层对不同Head中的结果进行加权。
2.2.3 Dropout/DropPath
2.2.3.1 Dropout
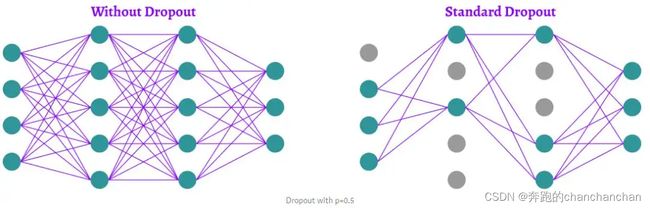
Dropout一般用于全连接层,其作用是提高网络的泛化能力,防止过拟合。它的具体步骤是在模型的训练过程中,根据一定的随机概率删除隐藏层中的一部分神经元,同时输入输出神经元数量保持不变。
2.2.3.2 DropPath
DropPath也是一种正则化手段,其思想与Dropout类似,根据一定的概率随机删除深度学习模型中的多分支结构子路径,防止过拟合,提升模型表现,而且克服了网络退化问题。其在数学上等价于,在样本维度随机丢弃某些样本的输出。
2.2.4 MLP Block
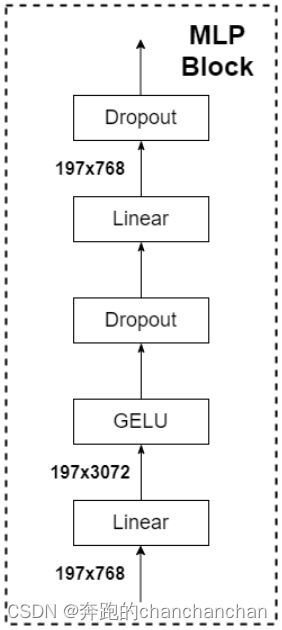
MLP Block由两层全连接层、GELU激活函数和Dropout组成,它的作用是建模全局信息,实现全局特征交互。其中第一个全连接层的节点个数为输入序列的 4 4 4倍,即序列的维度从(197, 768)转换到(197, 3072),第二个全连接层又转换回原来的维度,即(197, 768)。Dropout的概率通常取0.1,如果取值过大,会导致模型很难收敛。
2.3 MLP Head
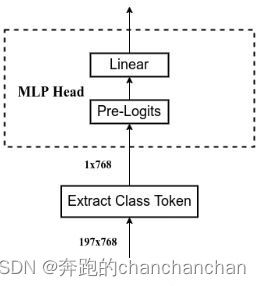
以ViT-B/16为例,经过Transformer Encoder的特征提取之后,输出维度为(197, 768)的特征序列(tokens)。在MLP Head之前,首先从特征序列(tokens)中提取出用于分类的class token,然后由MLP Head输出最终的预测结果。其中Pre-Logits模块是由一个Linear层和tanh激活函数组成,原论文中只在训练ImageNet-21K数据集时使用,而迁移到ImageNet-1K或自己的数据集上时可以不使用。
3. 相关问题总结
- Transformer为何使用多头注意力机制?
答:类似于卷积神经网络(CNN)中多个卷积核的作用,多头注意力机制保证了transformer可以注意到不同子空间的信息,从不同角度捕捉到更加丰富的特征信息,提高信息提取的全面性。 - Transformer中为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
答:将Q和K映射到在不同子空间,能够增强表达能力,提高泛化能力。假如使用相同的Q、K,得到的attention score矩阵就是一个对称矩阵,相当于加了一个约束,表达能力有所下降。 - Transformer中计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
答:两者的效果与序列长度 d k d_k dk相关, d k d_k dk越大,加法的效果越显著。虽然这两种方法的复杂度在理论上是相似的,但是在实践中借助高度优化的矩阵乘法代码实现的点积注意力更快,且更节省空间。 - 为什么在进行softmax之前需要对attention进行scaled(为什么除以 d k d_k dk的平方根)?
答:当 d k d_k dk较大时,Q和K向量内积的值也会容易变得很大, Q K T QK^T QKT的方差较大,这时softmax函数的梯度会非常的小。为了让 Q K T QK^T QKT矩阵的值满足期望为0,方差为1的分布,相当于归一化,因此乘以一个缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1。 - Vision Transformer中cls token作用?
答:(1)class token随机初始化,并随着网络的训练不断更新,它能够编码整个数据集的统计特性;(2)class token融合了其他token中的特征信息,并且随机生成,本身不基于图像内容,因此可以避免对sequence中某个特定token产生偏向性;(3)class token使用固定的位置编码能够避免输出受到位置编码的干扰。但是原论文中作者对所有token取平均与引入class token的方法进行了比较,实验效果基本相似。 - 如何理解Transformer中的Positional Encoding?
答:序列中每个token只包含了特征信息,而缺少了位置信息,因此引入了positional encoding来表示token在句子中的绝对位置信息,而与原始Transformer中固定的positional encoding所不同的是,Vision Transformer采用了可学习的positional encoding参数。