【MMU篇】一文总结ARMv8中的MMU架构
博主主页:MuggleZero
《ARMv8架构初学者笔记》专栏地址:《ARMv8架构初学者笔记》
MMU作为当代MPU不可缺少的部件,相信大家之前都有所耳闻。今天这一篇文章从MMU的架构角度总结了MMU中的相关知识点。
内存管理描述了如何控制对系统中内存的访问。每次操作系统或应用程序访问内存时,硬件都会执行内存管理。内存管理是一种为应用程序动态分配内存区域的方式。
为什么需要MMU?
应用处理器被设计用来运行丰富的操作系统,如Linux,并支持虚拟内存系统。在处理器上执行的软件只看到虚拟地址,处理器将其转化为物理地址。这些物理地址被呈现给内存系统,并指向内存中的实际物理位置。
什么是虚拟地址和物理地址?
虚拟地址
使用虚拟地址的好处是,它允许管理软件,如操作系统(OS),控制呈现给软件的内存视图。操作系统可以控制哪些内存是可见的,该内存的虚拟地址是可见的,以及允许对该内存进行哪些访问。这允许操作系统对应用程序进行沙盒处理(将一个应用程序的资源从另一个应用程序中隐藏起来),并提供对底层硬件的抽象。
使用虚拟地址的一个好处是,操作系统可以将多个零散的内存物理区域作为一个单一的、连续的虚拟地址空间呈现给应用程序。
虚拟地址也有利于软件开发人员,他们在编写应用程序时不会知道系统的确切内存地址。有了虚拟地址,软件开发者就不需要关心物理内存了。应用程序知道,要由操作系统和硬件共同完成地址转换。
在实践中,每个应用程序可以使用自己的虚拟地址集,这些地址将被映射到物理系统的不同位置。当操作系统在不同的应用程序之间切换时,它会重新编程映射。这意味着,当前应用程序的虚拟地址将映射到内存中的正确物理位置。
虚拟地址通过映射被转换为物理地址。如图所示,虚拟地址和物理地址之间的映射被存储在转换表(有时被称为页表)中。

翻译表在内存中,由软件管理,通常是操作系统或管理程序。翻译表不是静态的,随着软件需求的变化,翻译表可以被更新。这将改变虚拟和物理地址之间的映射。
MMU是什么?
内存管理单元(MMU)负责将软件使用的虚拟地址转换为内存系统中使用的物理地址。 MMU包含以下内容。
-
走表单元,它包含从内存中读取翻译表的逻辑。
-
翻译旁路缓冲器(TLB),用于缓存最近使用的翻译。 所有由软件发出的内存地址都是虚拟的。这些内存地址被传递给MMU,MMU检查TLB是否有最近使用的缓存翻译。如果MMU没有找到最近缓存的翻译,走表单元就会从内存中读取相应的表项,如图所示:

在进行内存访问之前,虚拟地址必须被翻译成物理地址(因为我们必须知道我们正在访问哪个物理内存位置)。这种翻译的需要也适用于缓存数据,因为在Armv6及以后的处理器上,数据缓存使用物理地址(有物理标记的地址)存储数据。因此,在完成缓存查找之前,必须对地址进行翻译。
表格条目
翻译表的工作方式是将虚拟地址空间划分为同等大小的块,并在表中为每个块提供一个条目。
表中的条目0提供了块0的映射,条目1提供了块1的映射,以此类推。每个条目都包含相应的物理内存块的地址和访问物理地址时要使用的属性。

表格查找
当发生转换时,就会发生查表。当翻译发生时,由软件发出的虚拟地址被分成两部分,如图所示。

图中标有 "哪个条目 "的高阶位,告诉你要看哪个块条目,它们被用作表的索引。这个条目块包含了虚拟地址的物理地址。
低阶位在图中标有 "块中的偏移",是该块中的偏移,不因翻译而改变。
多级翻译
在单层查询中,虚拟地址空间被分割成同等大小的块。在实践中,使用了一个分层的表。
第一个表(第1级表)将虚拟地址空间划分为大块。这个表中的每个条目可以指向一个同等大小的物理内存块,也可以指向另一个将该块细分为更小的块的表。我们称这种类型的表为 "多级表"。这里我们可以看到一个多级表的例子,它有三个级别。

在Armv8-A中,最大的级别数是四级,级别编号为0到3。 这种多级方法允许对较大的块和较小的块进行描述。大块和小块的特点如下。
-
与小块相比,大块需要更少的读数层次来进行翻译。另外,大块在TLB中的缓存效率更高。
-
小块给了软件对内存分配的细粒度控制。然而,小块在TLB中的缓存效率较低。缓存的效率较低,因为小块需要通过层次的多次读取来进行转换。 为了管理这种权衡,操作系统必须平衡使用大映射的效率和使用小映射的灵活性,以获得最佳性能。 注意:处理器在开始查表的时候并不知道翻译的大小。处理器通过执行表走动来计算出正在翻译的块的大小。
地址空间
在AArch64中,有几个独立的虚拟地址空间。这张图显示了这些虚拟地址空间。

图中显示了三个虚拟地址空间。
-
非安全的EL0和EL1。
-
非安全的EL2。
-
EL3。
这些虚拟地址空间中的每一个都是独立的,并有自己的设置和表格。我们通常称这些设置和表格为'转换制度'。还有安全EL0、安全EL1和安全EL2的虚拟地址空间,但它们没有在图中显示。
因为有多个虚拟地址空间,所以指定一个地址在哪个地址空间是很重要的。例如,NS.EL2:0x8000是指非安全EL2虚拟地址空间的地址0x8000。 该图还显示,来自非安全EL0和非安全EL1的虚拟地址要经过两套表。这些表支持虚拟化,并允许管理程序对虚拟机(VM)看到的物理内存视图进行虚拟化。
Armv9-A支持上述Armv8-A的所有虚拟地址空间。Armv9-A引入了可选的境界管理扩展(RME)。当RME被实施时,还出现了额外的转换制度。
-
Realm EL1和EL0
-
Realm EL2和EL0
-
Realm EL2
在虚拟化中,我们把由操作系统控制的翻译集称为阶段1。阶段1的表格将虚拟地址翻译成中间物理地址(IPA)。在第1阶段,操作系统认为IPA是物理地址空间。然而,管理程序控制着第二套翻译,我们称之为阶段2。这第二组翻译将IPA翻译成物理地址。这张图显示了这两组翻译是如何工作的。

在Arm,我们在许多例子中使用0x8000这个地址。0x8000也是用Arm链接器armlink进行链接的默认地址。这个地址来自早期的微型计算机,BBC Micro Model B,它的ROM(和侧向RAM)的地址是0x8000。BBC Micro Model B是由一家名为Acorn的公司制造的,该公司开发了Acorn RISC Machine(ARM),后来成为Arm。
物理地址
除了多个虚拟地址空间外,AArch64还拥有多个物理地址空间(PAS)。
-
非安全PAS
-
安全PAS
-
Realm PAS(仅Armv9-A)。
-
root PAS(仅Armv9-A)。
虚拟地址可以被映射到哪个物理地址空间,取决于处理器的当前安全状态。下面的列表显示了安全状态和其相应的虚拟地址映射目的地。
-
非安全状态:虚拟地址只能映射到非安全的物理地址。
-
安全状态:虚拟地址可以映射到安全或非安全的物理地址。
-
Realm状态:虚拟地址可以映射到Realm或非安全的物理地址。
-
Root状态:虚拟地址可以映射到任何物理地址空间。
当处于安全状态下的多个物理地址空间可见时,转换表项控制使用哪个输出物理地址空间。下图显示了多个物理地址空间的映射情况。

虚拟地址大小
虚拟地址是以64位格式存储的。因此,加载指令(LDR)和存储指令(STR)中的地址总是在一个X寄存器中指定。然而,并非所有X寄存器中的地址都是有效的。 这张图显示了AArch64中虚拟地址空间的布局。
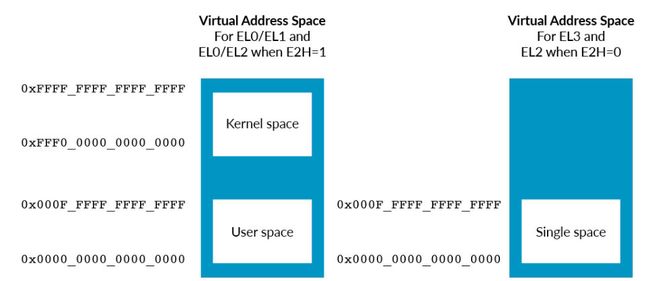
EL0/EL1的虚拟地址空间有两个区域:内核空间和应用空间。这两个区域显示在图的左侧,内核空间在顶部,而应用空间,也就是标记为 "用户空间",在地址空间的底部。内核空间和用户空间有独立的翻译表,这意味着它们的映射可以分开。
在地址空间的底部有一个单一的区域,用于所有其他的Exception级别。这个区域显示在图的右侧,是一个没有文字的盒子。
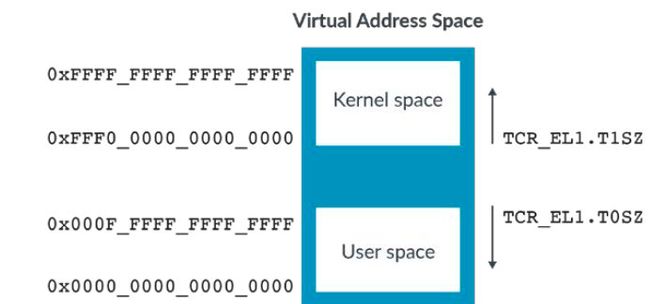
如果你把HCR_EL2.E2H设置为1,就可以实现主机操作系统在EL2中运行,而主机操作系统的应用程序在EL0中运行的配置。在这种情况下,EL2也有一个上部和一个下部区域。 每个区域的地址空间的大小最多为52位。然而,每个区域可以独立地缩减到更小的尺寸。TCR_ELx寄存器中的TnSZ字段控制虚拟地址空间的大小。例如,该图显示TCR_EL1控制EL0/EL1的虚拟地址空间。
虚拟地址的大小被编码为。
![]()
虚拟地址大小也可以用地址位数来表示。
![]()
因此,如果TCR_EL1.SZ1被设置为32,EL0/EL1虚拟地址空间中的内核区域大小为232字节(0xFFFF_FFFF_0000_0000到0xFFFF_FFFF_FFFF)。任何超出配置范围的地址,当它被访问时,将产生一个异常,作为一个转换故障。这种配置的好处是,我们只需要描述我们想要使用的地址空间,这就节省了时间和空间。例如,想象一下,操作系统内核需要1GB的地址空间(30位地址大小)作为其内核空间。如果操作系统将T1SZ设置为34,那么就只创建描述1GB的翻译表项,因为64-34=30。
所有Armv8-A的实现都支持48位虚拟地址。对52位虚拟地址的支持是可选的,由ID_AA64MMFR2_EL1报告。在撰写本文时,没有一个Arm Cortex-A处理器支持52位虚拟地址。
虚拟机标识符--用拥有的虚拟机来标记翻译
EL0/EL1翻译也可以用虚拟机标识符(VMID)进行标记。VMID允许来自不同虚拟机的翻译在高速缓存中共存。这类似于ASID对来自不同应用程序的翻译的工作方式。在实践中,这意味着一些翻译将被标记为VMID和ASID,并且两者必须匹配,才能使用TLB条目。
当安全状态支持虚拟化时,EL0/EL1翻译总是被标记为VMID - 即使阶段2翻译没有被启用。这意味着,如果你正在编写初始化代码,并且没有使用管理程序,在设置阶段1 MMU之前,必须设置一个已知的VMID值。
如果一个系统包括多个处理器,在一个处理器上使用的ASID和VMID在其他处理器上是否有相同的意义?
对于Armv8.0-A来说,答案是它们不一定意味着相同的东西。没有要求软件在多个处理器上以相同的方式使用一个特定的ASID。例如,ASID 5可能被一个处理器上的计算器使用,而被另一个处理器上的网络浏览器使用。这意味着,一个处理器创建的TLB条目不能被另一个处理器使用。
在实践中,软件不太可能在不同的处理器中以不同的方式使用ASIDs。更常见的是,软件在一个特定系统的所有处理器上以相同的方式使用ASIDs和VMIDs。因此,Armv8.2-A在转换表基础寄存器(TTBR)中引入了 "共而不私"(CnP)位。当CnP位被设置时,软件承诺在所有处理器上以相同的方式使用ASIDs和VMIDs,这允许一个处理器创建的TLB条目被另一个处理器使用。
我们一直在谈论处理器,然而,在技术上,我们应该使用术语,处理元素(PE)。PE是实现Arm架构的任何机器的通用术语。它在这里很重要,因为有一些微架构的原因,在处理器之间共享TLB会很困难。但是在一个多线程处理器中,每个硬件线程都是一个PE,共享TLB条目是更理想的。
映射颗粒
一个翻译颗粒是可以被描述的最小的内存块。没有更小的可以被描述,只有更大的块,它是颗粒的倍数。AArch64支持三种不同的颗粒大小:4KB、16KB和64KB。
一个处理器所支持的颗粒大小是由实现定义的,由ID_AA64MMFR0_EL1报告。所有Arm Cortex-A处理器都支持4KB和64KB。选定的颗粒是可以在最新级别表中描述的最小块。更大的块也可以被描述。该表显示了基于所选颗粒的每一级表的不同块大小。

在Armv9.2-A和Armv8.7-A推出之前,对使用52位地址有限制。当选择的颗粒为4KB或16KB时,最大的虚拟地址区域大小为48位。同样,输出物理地址也被限制在48位。只有当使用64KB颗粒时,才可以使用完整的52位。
TCR_EL1有两个独立的字段,控制内核空间和用户空间虚拟地址范围的颗粒大小。这些字段在内核空间称为TG1,在用户空间称为TG0。对于程序员来说,一个潜在的问题是,这两个字段有不同的编码方式。
TLB
翻译查询缓冲区(TLB)对最近使用过的翻译进行缓存。这种缓存允许随后的查找重复使用翻译,而不需要重新读取表。
注意:TLB是翻译的缓存,而不是翻译表的缓存。这其中的区别是微妙的。有几个寄存器字段控制翻译表项的解释方式。在TLB条目中的内容是对翻译表条目的解释,考虑到表被走过时的配置。在Arm架构参考手册(Arm ARM)中,此类寄存器字段被描述为 "允许在TLB中缓存"。
如果你改变了翻译表项,或者影响项如何解释的控制,那么你需要在TLB中使受影响的项无效。如果你不使这些条目失效,那么处理器可能继续使用旧的翻译。 处理器不允许将翻译缓存到TLB中,导致以下任何故障。
-
翻译故障(未映射的地址)。
-
地址大小故障(地址超出范围)。
-
访问标志故障。 因此,在第一次映射一个地址时,你不需要发出TLB invalidate命令。然而,如果你想做以下任何事情,你需要发出TLB invalidate。
-
取消地址的映射 - 把一个以前有效或已映射的地址标记为故障。
-
改变一个地址的映射 - 改变一个地址的输出或任何属性。例如 例如,将一个地址从只读权限改为读写权限。
-
改变表的解释方式 - 这不太常见。但是,例如,如果颗粒大小被改变,那么表的解释也会改变。因此,有必要进行TLB无效化。
TLB的格式:
TLBI {IS|OS} {, }
{IS/OS}:操作是内部可共享还是外部可共享。
地址转换指令
地址转换(AT)指令让软件查询特定地址的转换。转换的结果,包括属性,被写入物理地址寄存器PAR_EL1。
AT指令的语法可以让你指定使用哪种翻译机制。例如,EL2可以查询EL0/EL1的转换机制。然而,EL1不能使用AT指令来查询EL2的翻译制度,因为这违反了特权。 如果请求的翻译会引起故障,则不会产生异常。相反,本来会产生的故障类型被记录在PAR_EL1中。
欢迎关注我的个人微信公众号,一起交流学习嵌入式开发知识!
关注「求密勒实验室」