细品经典:LeNet-1, LeNet-4, LeNet-5, Boosted LeNet-4
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
LeNet是一种经典的图像分类深度学习卷积神经网络,已有大量的文献综述讨论。但大多数人只是回顾其中一个版本,即LeNet-5。LeNet-1、LeNet-4和boost LeNet-4通常被忽略。在这个故事中,我将对以下网络架构做一个简短的回顾:
Baseline Linear Classifier
One-Hidden-Layer Fully Connected Multilayer NN
Two-Hidden-Layer Fully Connected Multilayer NN
LeNet-1
LeNet-4
LeNet-5
Boosted LeNet-4
本文将讲述了架构和性能。
**这是IEEE杂志1998年的一篇文章在我写这篇文章的时候有14000个引用。**虽然是从1998年开始的,但它是神经网络基础的开始,这是一篇为学习深度学习开了个好头的论文。通过观察神经网络架构的发展和错误率的降低,我们可以很容易地知道在网络中添加深度学习组件的重要性或影响。
整理自:https://medium.com/@sh.tsang/paper-brief-review-of-lenet-1-lenet-4-lenet-5-boosted-lenet-4-image-classification-1f5f809dbf17
https://ieeexplore.ieee.org/xpl/RecentIssue.jsp?punumber=5
假设我们已经掌握了深度学习组件的基本知识,如卷积层、池化层、全连接层、激活函数等。
1
Baseline Linear Classifier
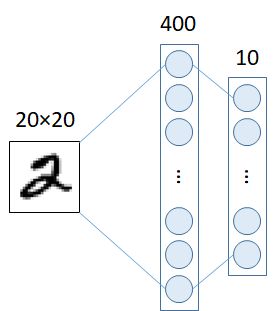
最简单的线性分类器。每个输入像素值构成每个输出单元的加权和。总和最高的输出单元表示输入字符的类别。因此,我们可以看到,图像被视为一维向量,并连接到一个10输出的向量。
也就是说,测试数据的错误率为8.4%。
2
One-Hidden-Layer Fully Connected Multilayer NN

One-Hidden-Layer Fully Connected Multilayer NN
在输入层和输出层之间增加一隐含层,隐含层神经元数量为300个,即20×20 - 300 - 10网络,测试数据的错误率为3.6%。隐含层有1000个神经元,即20×20 - 1000 - 10网络,测试数据的错误率为3.8%。
3
Two-Hidden-Layer Fully Connected Multilayer NN

在输入层和输出层之间增加两个隐藏层,28×28 - 300 - 100-10网络的,测试数据的错误率为3.05%。 28×28 - 1000 - 150 - 10网络,测试数据错误率为2.95%。
我们可以看到,通过添加隐藏层,错误率越来越小。但是,这种改善也在变得缓慢。
4
LeNet-1

在Lenet-1中, 28x28 的输入图像 --> 4个24×24 feature maps卷积层(5×5 size) -->平均池化层(2×2大小) -->8个12×12 feature maps 卷积层(5×5 size)--> 平均池化层(2×2大小)--> 直接全连接后输出
引入卷积和下采样/池化层后,LeNet-1对测试数据的错误率为1.7%
值得注意的是,在作者发明LeNet时,他们使用平均池化层,输出2×2特征图的平均值。目前很多LeNet实现使用max pooling只输出2×2 feature map的最大值,这有助于加快训练速度。当选择最强的特征时,反向传播可以得到较大的梯度。
5
LeNet-4

在 Lenet-4 中, **32×32 输入图片 ** -->4个 28×28 feature maps 卷积层 (5×5 size) --> Average Pooling layers (2×2 size) > 6个 10×10 feature maps卷积层r (5×5 size) --> Average Pooling layers (2×2 size) -->全连接到 120个神经元 -->全连接到 10 输出
有了更多的特征图和一个更完整的连接层,测试数据的错误率为1.1%。
6
LeNet-5
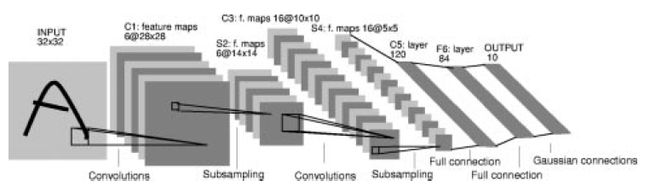
LeNet-5是最受欢迎的LeNet-5,与LeNet-4相比只有细微差别
32x32的输入图像 => 6个28×28 feature maps 卷积层(5×5 size) => 平均池化层(2×2大小)=>16个10×10 feature maps 卷积层(5×5 size) => 平均池化层(2×2大小)=>全连接到120个神经元 => 全连接84个神经元 => 全连接到10个输出
有了更多的feature map和多一个全连接层,测试数据的错误率为0.95%。
7
Boosted LeNet-4

Boosting是一种将几个或多个弱分类器的结果进行组合以获得更精确结果的技术。在LeNet-4中,将三个LeNet-4的输出简单相加,其中值最大的就是预测的分类类。当第一个网有一个很高的置信度答案,将会提升,其他网络不会被调用。
使用boosting,测试数据的错误率为0.7%,甚至比LeNet-5的错误率还要低。
这种boosting 技术已经使用了很多年,直到现在。
8
Summary on Error Rate
Baseline Linear Classifier: 8.4%
One-Hidden-Layer Fully Connected Multilayer NN: 3.6% to 3.8%
Two-Hidden-Layer Fully Connected Multilayer NN: 2.95% to 3.05%
LeNet-1: 1.7%
LeNet-4: 1.1%
LeNet-5: 0.95%
Boosted LeNet-4: 0.7%
我们可以看到,在增加深度学习组件或一些机器学习技术的同时,错误率正在降低。
9
Discussions
在这几篇文章[1-3]中,实际上有很多关于深度学习的基本技术都有详细的描述。此外,不同版本的LeNet甚至还与其他传统方法如PCA、k-NN、SVM进行了比较。
我们需要注意的是:
9.1. Activation Function
Tanh 用作激活函数,但输出部分除外。 Sigmoid作为在输出端的激活函数。 ReLU在那些年没有使用。
[如今]以及后来的研究发现,ReLU是一个在训练过程中加速收敛的较好的激活函数。
9.2. Pooling Layer
如前所述,LeNet使用平均池化而不是最大池化。
[现在]最大池化非常常见,甚至没有池化层。
9.3. Hidden Layers
在过去,隐藏层的数量很少,性能不可能通过增加更多的层来提高太多。
[现在]它可以是成百上千的隐藏层。
9.4. Training Time
在过去,训练需要几天时间。
[现在]但现在,它只是一个小的网络GPU加速。
10
10. Conclusions
总之,LeNet的论文确实值得一读,尤其是对于深度学习的初学者。
https://medium.com/@sh.tsang/very-quick-setup-for-style-recognition-using-pretrained-caffenet-alexnet-using-nvidia-docker-2-0-927a42634bb0
References
[1989 NIPS] [LeNet-1] Handwritten Digit Recognition with a Back-Propagation Network
http://yann.lecun.com/exdb/publis/pdf/lecun-90c.pdf
[1995 ICANN] [LeNet-1, LeNet-4, LeNet-5, Boosted LeNet-4] Comparison of Learning Algorithms for Handwritten Digit Recognition
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
[1998 Proc. IEEE] [LeNet-1, LeNet-4, LeNet-5, Boosted LeNet-4] Gradient-Based Learning Applied to Document Recognition
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
VERY QUICK SETUP of LeNet-5 for Handwritten Digit Classification Using Nvidia-Docker
https://medium.com/@sh.tsang/very-quick-setup-of-lenet-5-for-written-digit-classification-using-nvidia-docker-2-0-a4e7ba76c68a
下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
觉得有趣就点亮在看吧
