GPU架构和Compute Shader线程规划
文章目录
- 关于
- GPU架构简介
-
- GPC, TPC, SM, CUDA Core
- 流多处理器 SM 的架构
- 线程组的分派
-
- SM和线程组
- 线程组的数量选择
- 线程组的分派和线程数量规划
- 线程组的执行单位:warp
关于
本文从GPU架构去理解Computer Shader的线程组概念,分析了线程组和线程的数量如何规划,以及Dispatch函数和numthreads的参数的含义。(目前还是初步的理解,有可能存在错误,此文会进行迭代)
GPU架构简介
以nvidia为例, nvidia的GPU架构从老到新有Tesla, Fermi, Kepler, Maxwell, Pascal, Volta, Turing, Ampere等。本文以Pascal架构作为例子,GTX1060就是Pascal架构的。另外Nintedo Switch使用的是Maxwell架构的Tegra X1芯片。
参考:Pascal架构白皮书
GPC, TPC, SM, CUDA Core
- GPU包含若干GPC (Graphics Processing Cluster, 图形处理簇)组成的阵列。
- GPC又包含若干TPC (Texture Processing Cluster)
- TPC中包含若干SM (Stream Multiprocessor,流多处理器)
- SM中包含若干CUDA Core
下图是Pascal架构的GP100图,可以看到它有6个GPC,每个GPC中有5个TPC,每个TPC中有2个SM,因此每个GPC有10个SM。GP100一共有30个 TPC, 60个SM。而每个SM包含64个CUDA Core(32位)和4个纹理单元。因此GP100的60个SM,一共有3840个CUDA核心和240个纹理单元。
流多处理器 SM 的架构

Pascal架构的SM中的核心被分为两组processing blocks,每组各有一个Instructoin Buffer, 一个Warp Scheduler,两个Dispatch Unit,一个Register File(寄存器堆) 以及32个Core。SM内部共享指令缓存,Texture/L1缓存,纹理单元(4个)以及64KB共享内存。
线程组的分派
SM和线程组
我们知道GPU有很多很多的核心,这种架构可以同时执行大量的操作,但是这些操作是如何组织的呢?从前面的GPU架构简介中我们已经知道,这些核心被组织成一个个的流多处理器SM(当然SM上层还有TPC和GPC,先忽略这些细节)。既然一个SM有若干core,那么SM当然是用来并行执行若干操作用的。所谓的操作就是线程,而这若干线程组成一个线程组,因此一个线程组运行在一个SM上。
线程组的数量选择
既然一个线程组运行在一个SM上,那么GPU有很多SM,所以我们可以同时执行很多的线程组。那么我们应该使用多少个线程组呢?根据DX12龙书的描述,每个SM至少应该拥有两个线程组,即线程组的数量应该为SM数量的2倍,比如如果GPU有16个SM,那么我们就应该至少将任务分解为32个线程组。使用2倍是因为为了保证处理的并行性,至少为每个SM分派两个线程组,当SM正在执行的一个线程组处于等待的状态时(比如等待纹理的处理结果),SM可以切换到另一个线程组执行。
线程组的分派和线程数量规划
DX12的Compute Shader使用Dispatch(x,y,z)函数分派一个线程组网格。参数x,y,z相乘就是线程组的数量,比如我们要分派32个线程组,可以使用Dispatch(8,4,1)进行分配。那么是否也可以使用Dispatch(4,8,1)呢?当然也可以了。那么这儿x,y,z的选择究竟有什么讲究呢?我理解这是为了方便线程的规划和使用。如果我们使用Compute shader对输入的贴图进行处理,由于贴图是2维的,思考一下如何让若干核心并行操作贴图的每个像素?肯定最好是每个像素分配一个核心,也就是一个线程进行处理,当然实际上核心数量可能没那么多,但是不要紧,我们分配的是线程嘛,一个核心可以轮着执行不同的多个线程。所以假设我们的贴图分辨率是512512,那么我们使用8列4行(x=8,y=4)的布局来规划这32个线程组,那么对于每个线程组中,我们在x方向需要512/8=64个线程,y方向需要512/4=128,即compute shader中使用[numthreads(64,128,1)]定义线程数量。这样在compute shader中,就可以使用SV_DispatchThreadID.xy来直接访问一个像素了,含义就是当前总体线程网格的(x,y)位置处理的那个像素,我们可以这么使用就是因为我们按照贴图的分辨率定义了x,y,z方向线程组和线程的数量。线程组相当于在贴图上划分了(a,b)个大格子,线程相当于在每个大格子里面再细分(c,d)个小格子,每个小格子就是一个像素,那么最终我们就有(ac, bd)个像素,而DispatchThreadID就是所有格子(像素)的x,y,z坐标。当然这儿的线程数还是有一个限制,对于nvidia显卡来说,线程组中的总线程数(即cd)应该为warp大小(32)的倍数,而AMD的显卡应该为wavefront尺寸(64)的整数倍,所以我们应该让线程组中的线程总数为64的整数倍。使用compute shader基本理解到这儿就可以了,可以按照需要规划线程组和线程数量了。但是为了研究执行时的效率问题,还要再看一下线程组具体如何调度执行的。
线程组的执行单位:warp
一个线程组包含n个线程,这是我们的静态设定。但是运行时,这n个线程不大可能同时并行执行,当然核心数往往也没那么多。SM在执行线程组时,会进一步将这n个线程分成多个warp(线程簇)来执行,每个warp会同时运行32个线程。比如我们上面定义的64*128=8192个线程,会被分为8192/32=256个warp。插一句,是不是感觉warp有点多啊,确实,因为上面假定的GPU只有16个SM,因此我们只规划了32个线程组,所以造成每个线程组的线程数超级多,正常一个SM才32个核心,warp太多了肯定性能不行啊,得来回切换。看上面的pascal架构,有60个SM,这样就可以规划至少120个线程组,这样每个线程组的线程数量就大大减少了。
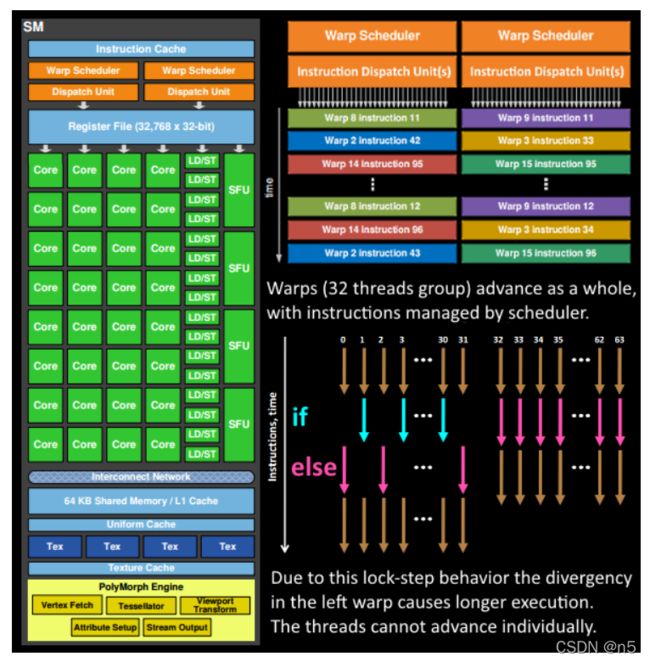
总之,线程组按照warp为单位进行执行。下图中我们可以看到warp是被Warp Scheduler调度管理的,Warp调度器其实就是在不停的切换Warp执行不同的指令,而指令是由指令调度单元去分配给每个核心,每个warp调度器可以有一或多个指令调度单元,下图是一对一,上面的pascal架构是一对二,因此指令分配的更快。
指令调度单元(Dispatch Unit)从指令缓存中取出shader中的操作指令,分配给每个Core去执行,调度单元分配给每一个Core的指令都是相同的,因此一个Warp中同一时刻所有线程执行的是相同的指令。不过虽然指令相同,每个Core操作的数据是不同的,这就是所谓的SIMT(单指令多线程)。一个Warp中,所有的32个线程是同步执行的,这种方式叫做lock-step,所有线程执行相同指令,执行完当前指令后,Dispatch Unit再发送下一条指令给大家执行,所有线程齐头并进。
下图右边,是两个warp执行线程的情况,warp1是0到31号线程,由于shader程序中存在分支,部分线程执行if分支,另外一部分执行else分支,由于warp需要同步执行指令,因此结果是先执行完if再执行else,这就造成了性能的损失。而第2个warp中执行的函数没有分支,因此所有线程可以同步执行。另外第2个warp的shader代码中有可能也有if/else语句,但是所有的线程都只执行if或else,那么也不需要等待了,因为另外一个分支没有线程执行。看下图中箭头的颜色,貌似warp2所有线程执行的都是else。