学习笔记:ComputerShader
本文主要记录自己学习的简单总结:主要是绘制数字表面。
作者把这篇归类为Unity基础,看来我连Unity基础都不会!!!
效果图:作者代码不是彩色,我没有把ShaderGraph图里Z值设置0,所以是彩色的
下面代码作者已修改!!!:如果三个轴向非统一缩放可以不改

中文学习链接
原文链接
链接中的这一节主要在上一节的基础上,利用ComputerShader把绘制Mesh的任务放到GPU上。
ComputerShader和传统说的VS和FS不一样,ComputerShader具有通用性,把在CPU端的耗时任务放到GPU处理。
源代码:
using UnityEngine;
public class GPUGraph : MonoBehaviour
{
const int maxResolution = 1000;
static readonly int
positionsId = Shader.PropertyToID("_Positions"),
resolutionId = Shader.PropertyToID("_Resolution"),
scaleId = Shader.PropertyToID("_Scale"),
stepId = Shader.PropertyToID("_Step"),
timeId = Shader.PropertyToID("_Time"),
transitionProgressId = Shader.PropertyToID("_TransitionProgress");
[SerializeField]
ComputeShader computeShader = default;
[SerializeField]
Material material = default;
[SerializeField]
Mesh mesh = default;
[SerializeField, Range(1, maxResolution)]
int resolution = 10;
[SerializeField]
FunctionLibrary.FunctionName function = default;
public enum TransitionMode { Cycle, Random }
[SerializeField]
TransitionMode transitionMode = TransitionMode.Cycle;
[SerializeField, Min(0f)]
float functionDuration = 1f, transitionDuration = 1f;
float duration;
bool transitioning;
FunctionLibrary.FunctionName transitionFunction;
ComputeBuffer positionsBuffer;
void OnEnable()
{
positionsBuffer = new ComputeBuffer(maxResolution * maxResolution, 3 * 4);
}
void OnDisable()
{
positionsBuffer.Release();
positionsBuffer = null;
}
void Update()
{
duration += Time.deltaTime;
if (transitioning)
{
if (duration >= transitionDuration)
{
duration -= transitionDuration;
transitioning = false;
}
}
else if (duration >= functionDuration)
{
duration -= functionDuration;
transitioning = true;
transitionFunction = function;
PickNextFunction();
}
UpdateFunctionOnGPU();
}
void PickNextFunction()
{
function = transitionMode == TransitionMode.Cycle ?
FunctionLibrary.GetNextFunctionName(function) :
FunctionLibrary.GetRandomFunctionNameOtherThan(function);
}
void UpdateFunctionOnGPU()
{
//ComputerShader:把需要的数据传进去
float step = 2f / resolution;
computeShader.SetInt(resolutionId, resolution);
computeShader.SetFloat(stepId, step);
computeShader.SetFloat(timeId, Time.time);
if (transitioning)
{
computeShader.SetFloat(
transitionProgressId,
Mathf.SmoothStep(0f, 1f, duration / transitionDuration)
);
}
//获取核心索引
var kernelIndex = (int)function +
(int)(transitioning ? transitionFunction : function) * FunctionLibrary.FunctionCount;
computeShader.SetBuffer(kernelIndex, positionsId, positionsBuffer);
int groups = Mathf.CeilToInt(resolution / 8f);
//执行:获取位置
computeShader.Dispatch(kernelIndex, groups, groups, 1);
//把Shader需要的数据传进去
material.SetBuffer(positionsId, positionsBuffer);
material.SetVector(scaleId, new Vector4(step, 1f / step));
//开始画
var bounds = new Bounds(Vector3.zero, Vector3.one * (2f + 2f / resolution));
Graphics.DrawMeshInstancedProcedural(
mesh, 0, material, bounds, resolution * resolution
);
}
}
FunctionLibrary.computer:同一行代码后面加注释会报错:\\,需要在新的一行添加。
这里就是原来在C#端写的一些动画函数,这里核心排列使用规律的,方便在C#端计算索引。
#pragma kernel WaveKernel
#pragma kernel WaveToMultiWaveKernel
#pragma kernel WaveToRippleKernel
#pragma kernel WaveToSphereKernel
#pragma kernel WaveToTorusKernel
#pragma kernel MultiWaveToWaveKernel
#pragma kernel MultiWaveKernel
#pragma kernel MultiWaveToRippleKernel
#pragma kernel MultiWaveToSphereKernel
#pragma kernel MultiWaveToTorusKernel
#pragma kernel RippleToWaveKernel
#pragma kernel RippleToMultiWaveKernel
#pragma kernel RippleKernel
#pragma kernel RippleToSphereKernel
#pragma kernel RippleToTorusKernel
#pragma kernel SphereToWaveKernel
#pragma kernel SphereToMultiWaveKernel
#pragma kernel SphereToRippleKernel
#pragma kernel SphereKernel
#pragma kernel SphereToTorusKernel
#pragma kernel TorusToWaveKernel
#pragma kernel TorusToMultiWaveKernel
#pragma kernel TorusToRippleKernel
#pragma kernel TorusToSphereKernel
#pragma kernel TorusKernel
RWStructuredBuffer<float3> _Positions;
uint _Resolution;
float _Step, _Time, _TransitionProgress;
float2 GetUV(uint3 id) {
return (id.xy + 0.5) * _Step - 1.0;
}
void SetPosition(uint3 id, float3 position) {
if (id.x < _Resolution && id.y < _Resolution) {
_Positions[id.x + id.y * _Resolution] = position;
}
}
#define PI 3.14159265358979323846
float3 Wave(float u, float v, float t) {
float3 p;
p.x = u;
p.y = sin(PI * (u + v + t));
p.z = v;
return p;
}
float3 MultiWave(float u, float v, float t) {
float3 p;
p.x = u;
p.y = sin(PI * (u + 0.5 * t));
p.y += 0.5 * sin(2.0 * PI * (v + t));
p.y += sin(PI * (u + v + 0.25 * t));
p.y *= 1.0 / 2.5;
p.z = v;
return p;
}
float3 Ripple(float u, float v, float t) {
float d = sqrt(u * u + v * v);
float3 p;
p.x = u;
p.y = sin(PI * (4.0 * d - t));
p.y /= 1.0 + 10.0 * d;
p.z = v;
return p;
}
float3 Sphere(float u, float v, float t) {
float r = 0.9 + 0.1 * sin(PI * (12.0 * u + 8.0 * v + t));
float s = r * cos(0.5 * PI * v);
float3 p;
p.x = s * sin(PI * u);
p.y = r * sin(0.5 * PI * v);
p.z = s * cos(PI * u);
return p;
}
float3 Torus(float u, float v, float t) {
float r1 = 0.7 + 0.1 * sin(PI * (8.0 * u + 0.5 * t));
float r2 = 0.15 + 0.05 * sin(PI * (16.0 * u + 8.0 * v + 3.0 * t));
float s = r2 * cos(PI * v) + r1;
float3 p;
p.x = s * sin(PI * u);
p.y = r2 * sin(PI * v);
p.z = s * cos(PI * u);
return p;
}
#define KERNEL_FUNCTION(function) \
[numthreads(8, 8, 1)] \
void function##Kernel (uint3 id: SV_DispatchThreadID) { \
float2 uv = GetUV(id); \
SetPosition(id, function(uv.x, uv.y, _Time)); \
}
#define KERNEL_MOPH_FUNCTION(functionA, functionB) \
[numthreads(8, 8, 1)] \
void functionA##To##functionB##Kernel (uint3 id: SV_DispatchThreadID) { \
float2 uv = GetUV(id); \
float3 position = lerp( \
functionA(uv.x, uv.y, _Time), functionB(uv.x, uv.y, _Time), \
_TransitionProgress \
); \
SetPosition(id, position); \
}
KERNEL_FUNCTION(Wave)
KERNEL_FUNCTION(MultiWave)
KERNEL_FUNCTION(Ripple)
KERNEL_FUNCTION(Sphere)
KERNEL_FUNCTION(Torus)
KERNEL_MOPH_FUNCTION(Wave, MultiWave);
KERNEL_MOPH_FUNCTION(Wave, Ripple);
KERNEL_MOPH_FUNCTION(Wave, Sphere);
KERNEL_MOPH_FUNCTION(Wave, Torus);
KERNEL_MOPH_FUNCTION(MultiWave, Wave);
KERNEL_MOPH_FUNCTION(MultiWave, Ripple);
KERNEL_MOPH_FUNCTION(MultiWave, Sphere);
KERNEL_MOPH_FUNCTION(MultiWave, Torus);
KERNEL_MOPH_FUNCTION(Ripple, Wave);
KERNEL_MOPH_FUNCTION(Ripple, MultiWave);
KERNEL_MOPH_FUNCTION(Ripple, Sphere);
KERNEL_MOPH_FUNCTION(Ripple, Torus);
KERNEL_MOPH_FUNCTION(Sphere, Wave);
KERNEL_MOPH_FUNCTION(Sphere, MultiWave);
KERNEL_MOPH_FUNCTION(Sphere, Ripple);
KERNEL_MOPH_FUNCTION(Sphere, Torus);
KERNEL_MOPH_FUNCTION(Torus, Wave);
KERNEL_MOPH_FUNCTION(Torus, MultiWave);
KERNEL_MOPH_FUNCTION(Torus, Ripple);
KERNEL_MOPH_FUNCTION(Torus, Sphere);
Point GPU.hlsl:这里是把C#端传进来的数据设置好转换矩阵
会把这段代码插入到ShaderGraph里面用
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
StructuredBuffer<float3> _Positions;
#endif
float2 _Scale;
void ConfigureProcedural() {
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
float3 position = _Positions[unity_InstanceID];
unity_ObjectToWorld = 0.0;
unity_ObjectToWorld._m03_m13_m23_m33 = float4(position, 1.0);
unity_ObjectToWorld._m00_m11_m22 = _Scale.x;
//逆矩阵:法线要用
unity_WorldToObject = 0.0;
unity_WorldToObject._m03_m13_m23_m33 = float4(-position, 1.0);
unity_WorldToObject._m00_m11_m22 = _Scale.y;
#endif
}
//对输入未做修改,直接输出
void ShaderGraphFunction_float(float3 In, out float3 Out) {
Out = In;
}
//函数重载
void ShaderGraphFunction_half(half3 In, out half3 Out) {
Out = In;
}
ShaderGraph图:
作者这里设置的是0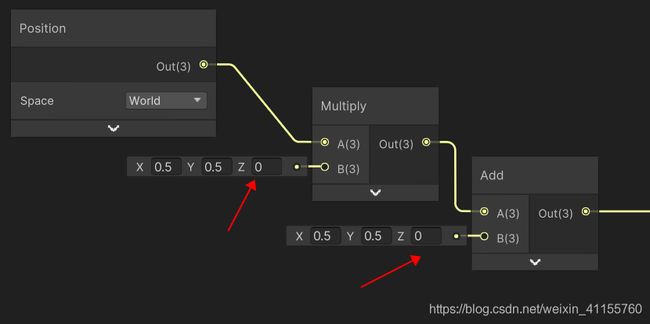
添加CustomFunction节点,设置右边的类型和源文件:就是上面的Point GPU.hlsl
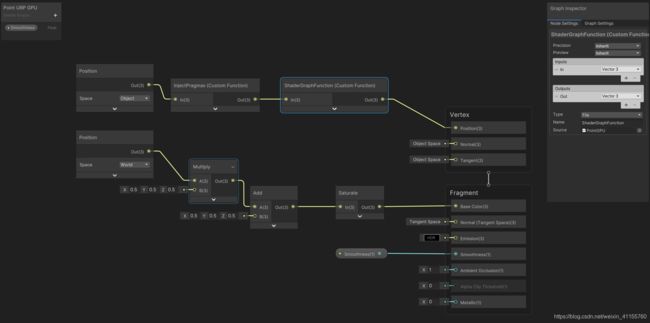
下面这张图:再添加一个CustomFunction节点,编译指令#pragma…这些必须直接写入源文件,不能用上面的方式,从文件读取,所以节点右边的类型设置为string,Body里直接添加如下:
这段主要是添加两个编译指令,对输入未做修改直接输出
//实例化时配置选项:procedural:设置自己的程序片段,会在VS,FS开始时调用
#pragma instancing_options procedural:ConfigureProcedural
//禁用编辑器异步编译着色器:采用同步方式
#pragma editor_sync_compilation
Out = In;
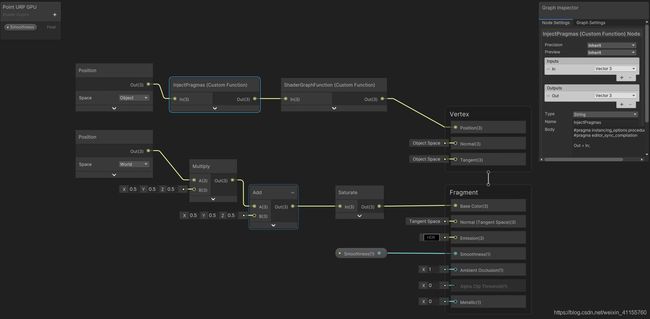
CustomFunction用法:查看ShaderGraph文档:链接
总结:
1.C#端设置ComputerShader需要的数据。
2.ComputerShader计算好保存在CommandBuffer里。
3.把CommandBuffer的数据设置到要用的Shader里。
4.最后开始画。