Attention Is All You Need
论文: Attention Is All You Need
Github: GitHub - tensorflow/tensor2tensor: Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
打破传统基于cnn,lstm等的序列翻译模型,论文提出了一个新的网络结构Transformer,该网络结构基于attention机制设计,完全没有使用cnn,lstm。
最终该模型在WMT 2014 Englishto-German翻译任务上取得了28.4 BLEU,WMT 2014 English-to-French翻译任务上取得了41.8 BLEU。
网络结构:
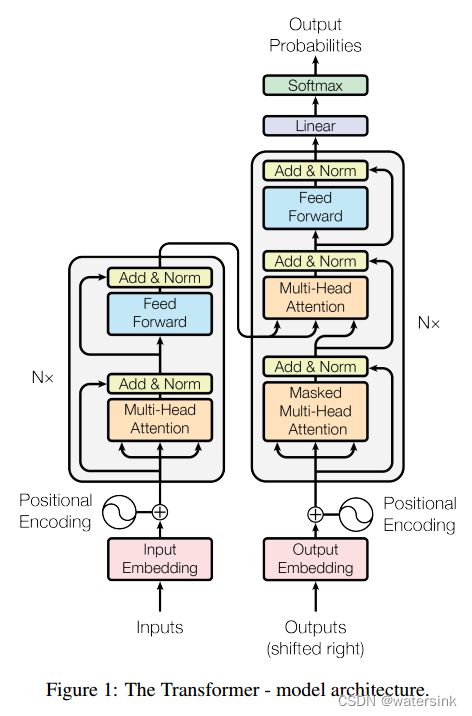
整个的网络结构由Encoder和Decoder两部分组成。
模型的输入序列定义为x=(x1; :::; xn),经过Encoder编码后得到中间序列z = (z1; :::; zn),将Z输入解码器Decoder后得到最终输出y= (y1; :::; ym)
Encoder:
编码器部分由N个同样的模块堆叠而成,这里N=6。每个模块内部由2个小模块组成,分别为多头注意力模块(Multi-Head Attention)和前向网络模块(Feed Forward)组成。这里的注意力模块属于Self-Attention性质。
输入的序列x会首先和位置编码(Positional Encoding)序列进行相加,输出后经过多头注意力编码,然后通过残差网络的方式,将多头注意力的输出和原始输入进行相加和LayerNorm处理。然后经过前向网络FFN处理,同样适用残差方式进行特征相加和LayerNorm处理,得到编码器的输出512维度的特征序列,将其定义为dmodel = 512。
Decoder:
解码器部分也是由N个同样的模块堆叠而成,这里N=6。该模块可以分成三块来看,第一块也是Attention层,第二块是cross Attention,不是Self-Attention,第三块是全连接层。也用了跳跃连接和Normalization。与编码器的区别在于解码器部分增加了Masked Multi-Head Attention模块。该模块会对位置信息进行mask编码,使得模型在t时刻预测的时候,只能看到t时刻之前的特征,这样预测就只会依赖t时刻之前的信息,而不会提前看到t时刻之后的答案,从而使得模型更加泛化。
解码器模块第一次输入是前缀信息,之后的就是上一次产出的Embedding,加入位置编码,然后进入一个可以重复很多次的模块。最后的输出要通过Linear层(全连接层),再通过softmax做预测。
Scaled Dot-Product Attention:
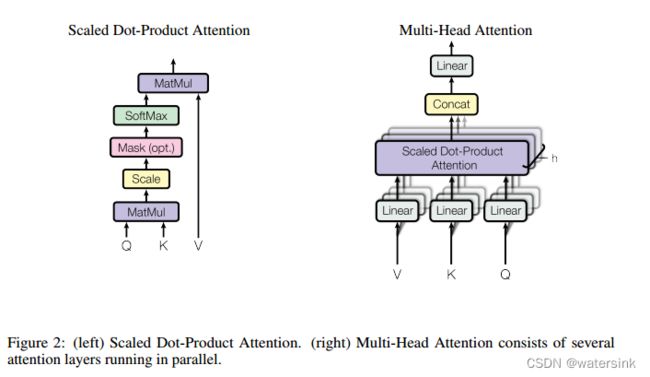
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
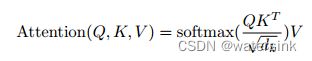
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此使用了QK进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。QK计算完点积之后,先进行Scale操作,也就是除去根号dk,这么做的目的因为为了防止维数过高时QK的值过大导致softmax函数反向传播时发生梯度消失。
然后经过padding mask操作,也就是对较短的输入特征进行负无穷补齐操作后,经过softmax处理,特征值都归一化到0-1之间,负无穷的补齐值就接近于0,然后和V做点积就得到最终的输出特征。这样一个self-attention模块就完成了。
Multi-Head Attention:
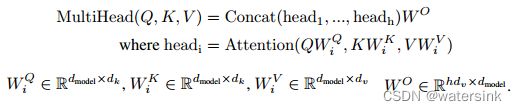
多头attention本质就是集成了多个的self-attention模块,将每一个self-attention模块定义为head,集成h个head模块,然后对特征进行concat拼接操作,然后经过一个全连接层得到多头注意力模块的输出特征。
这里h=8,也就是集成8个并行的attention模块,dk = dv = dmodel/h = 64。
也就是说d(WQ)=512*64,d(WK)=512*64,d(WV)=512*64,d(WO)=512*512。
LayerNorm:
LayerNorm(x + Sublayer(x))
Position-wise Feed-Forward Networks(FFN):
![]()
FFN一共经过2个全连接层和一个Relu激活层。首先经过一个全连接层,输出经过Relu激活后经过第二个全连接层,得到最终输出。其中FFN输入和输出的维度都是512维(dmodel = 512),第一个全连接层对特征进行了升维到2048维操作(dff = 2048)。
Positional Encoding:
为了使得网络在做self-attention的时候知道每个词向量之间相互位置或者绝对位置关系,使得注意力聚焦在需要的单词上,这里引入了位置编码。位置编码的方式有很多种,比如可以通过训练得到,但是训练得到的位置编码鲁棒性较差。论文采用了sincos方式的位置编码,sincos方式的位置编码可以使模型再推理阶段得到比训练过程中遇到的序列更长的序列长度。
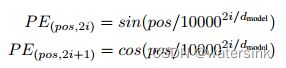
其中pos表示位置,i表示维度。
Positional Encoding的物理意义是:把50个Positional Encoding两两互相做点击,看相关性。其特点是Encoding向量的点积值对称,随着距离增大而减小。

Why Self-Attention:

通过self-Attention,rnn,conv的对比,可以得到下面结论,
(1)self-Attention每一层的计算复杂度最低
(2)self-Attention和conv都能够并行计算,而rnn不支持
(3)网络中long-range dependencies的path length,在处理序列信息的任务中很重要的在于学习long-range dependencies。影响学习长距离依赖的关键点在于前向/后向信息需要传播的步长,输入和输出序列中路径越短,那么就越容易学习long-range dependencies。通过比较三种网络中任何输入和输出之间的最长path length,得self-Attention中任意单词之间的距离都为1,是最小的。
The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies
Optimizer:
![]()
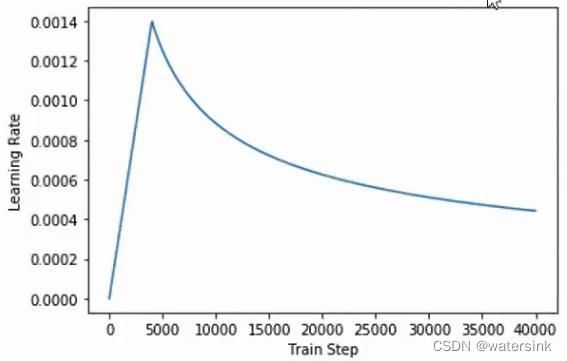
训练过程中,先进行warmup操作,学习率先升高然,warmup_steps = 4000,4000轮后随着训练轮数增加学习率慢慢降低。
Residual Dropout:
在模型中的每一个层之后都加入dropout层,Pdrop = 0.1。
Label Smoothing:
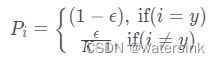
其中ε = 0.1
虽然经过label smooth训练会导致模型学习的比较模糊,但是测试的时候却可以提升模型的准确性和BLEU得分。
实验结果:

总结:
优点
(1)每层计算复杂度比RNN要低,同时可以进行并行计算。
(2)从计算一个序列长度为n的信息要经过的路径长度来看, CNN需要增加卷积层数来扩大视野,RNN需要从1到n逐个进行计算,而Self-attention只需要一步矩阵计算就可以。Self-Attention可以比RNN更好地解决长时依赖问题。当然如果计算量太大,比如序列长度N大于序列维度D这种情况,也可以用窗口限制Self-Attention的计算数量。
(3)从作者在附录中给出的栗子可以看出,Self-Attention模型更可解释,Attention结果的分布表明了该模型学习到了一些语法和语义信息。
缺点,在原文中没有提到缺点,是后来在Universal Transformers中指出的,主要是两点:
(1)有些RNN轻易可以解决的问题Transformer没做到,比如复制String,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
(2)理论上:transformers不是computationally universal(图灵完备),而RNN图灵。完备,这种非RNN式的模型是非图灵完备的的,无法单独完成NLP中推理、决策等计算问题(包括使用transformer的bert模型等等)。