DBF文件格式及读写实践
DBF文件格式:

文件头格式:
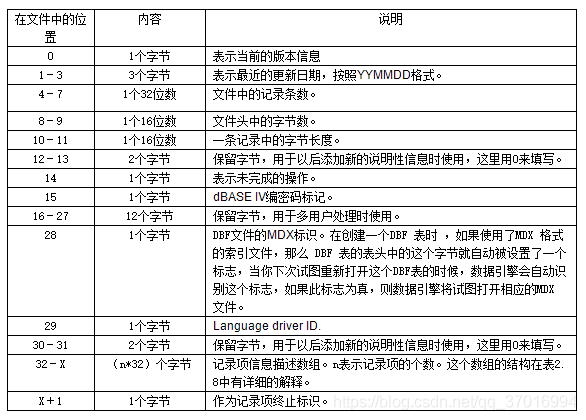
记录项信息描述数组结构(每个记录项都是32个字节):
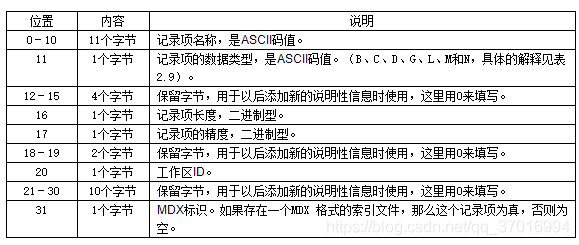
例如下方的ZJSXK.DBF就有24个记录项。
每次写入新数据到DBF中时,要注意同时更新文件头的时间和记录条数。其余不需要改变,因为文件的格式没有发生改变。
在python编码中,使用struct模块实现二进制字符串和string字符串的转换。主要使用其中的unpack方法和pack方法。
首先看看DBF各个字符的格式如果对应起python中的格式:
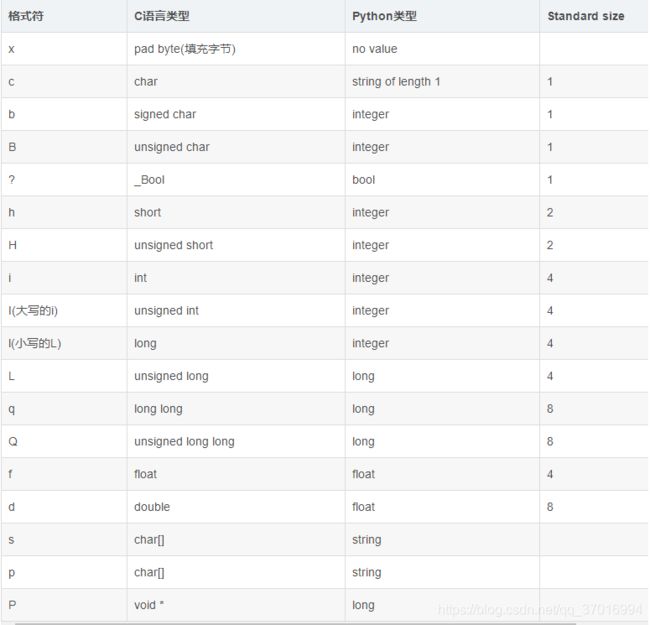
举个例子:
文件头中的文件记录条数是1个32位数,32位数即32/8=4字节,且该记录条数一定>=0,那么对应的格式符可以是 : I(大写i)和L。以此类推,1个16位数,对应的格式符可以是: H 。
读写DBF文件,其中DBF文件已经存在,不需要自行创建DBF:
DBF文件记录的格式文档:

其中不管是啥类型,最简单的都可以直接使用s格式符。所以该DBF记录的格式为:<10s4s8x20s219x15s30s15s30s40s296x(非必要的数据,直接用x占位符),读取到机构标知,交易代码,资金账户,收款银行行号,收款银行账号,付款银行行号,付款银行账号,付款银行名称。
而文件头则根据表2、表3拿取出需要的信息:<4BIHH,拿到版本号,日期(年,月,日),记录数,头字节数,记录字节数。
程序如下:
#coding:utf-8
import struct
import datetime
file_path = "C:\Program Files (x86)\SSCC\D-COM\data00\ZJSXK.dbf"
#尾部写入10条新的数据
with open(file_path,"rb+") as f:
var,year,month,day,num,headbyte,recodebyte = struct.unpack("<4BIHH",f.read(12))
print(var,year,month,day,num,headbyte,recodebyte)
end_index = headbyte + 1 + recodebyte * num #定位到最后的位置的下一行记录的首地址
f.seek(end_index)
r2,r3,r4,r5,r6,r7,r8 = "4020".encode("utf-8"),"B10100001".encode("utf-8"),"shenzhen".encode("utf-8"),"shenzhen".encode("utf-8"),"shanghai".encode("utf-8"),"shanghai".encode("utf-8"),"we".encode("utf-8")
for i in range(10):#写入十条记录
f.write(struct.pack("<10s4s8x20s219x15s30s15s30s40s296xc",("JGDMGH"+str(i)).encode("utf-8"),r2,r3,r4,r5,r6,r7,r8," ".encode("utf-8")))#其中格式符都是使用s
f.seek(0)
now = datetime.datetime.now()
year,month,day = now.year - 1900,now.month,now.day#必须对应更新头记录的信息
f.write(struct.pack("<4BIHH",var,year,month,day,num+10,headbyte,recodebyte))
#读取第recode个记录
with open(file_path,"rb") as f :
var, year, month, day, num, headbyte, recodebyte = struct.unpack("<4BIHH", f.read(12))
print(var, year, month, day, num, headbyte, recodebyte)
recode = 5#第5个记录
first_index = headbyte + recodebyte * (recode - 1) + 1 #第五个记录的首地址
f.seek(first_index)
r1,r2, r3, r4, r5, r6, r7, r8,r9 = struct.unpack("<10s4s8x20s219x15s30s15s30s40s296xc",f.read(recodebyte))
print(r1.decode("utf-8").strip(),r2.decode("utf-8").strip(),r3.decode("utf-8").strip(),r4.decode("utf-8").strip(),r5.decode("utf-8").strip(),r6.decode("utf-8").strip(),r7.decode("utf-8").strip(),r8.decode("utf-8").strip(),r9.decode("utf-8"))
也可以将8x替换成q或Q或8s,这样子就可以将SXSQLS (N 8 )字段给取出来。
#读取第recode个记录
with open(file_path,"rb") as f :
var, year, month, day, num, headbyte, recodebyte = struct.unpack("<4BIHH", f.read(12))
print(var, year, month, day, num, headbyte, recodebyte)
recode = num - 5#倒数第5个记录
first_index = headbyte + recodebyte * (recode - 1) + 1 #倒数第五个记录的首地址
f.seek(first_index)
r1,r2, r3, r4, r5, r6, r7, r8,r9,r10 = struct.unpack("<10s4sq20s219x15s30s15s30s40s296xc",f.read(recodebyte))
print(r1.decode("utf-8").strip(),r2.decode("utf-8").strip(),r3,r4.decode("utf-8").strip(),r5.decode("utf-8").strip(),r6.decode("utf-8").strip(),r7.decode("utf-8").strip(),r8.decode("utf-8").strip(),r9.decode("utf-8"),r10.decode("utf-8"))
以此类推。格式符可以全都选择s,前面的数字代表长度。或者比较文件格式要求和python格式符的字节长度,选择合适的格式符即可。