大数据常用的算法与数据结构
文章目录
-
- 1 布隆过滤器(Bloom Filter)
-
- 1.1 基本原理
- 1.2 误判率及相关计算
- 1.3 BF的改进:counting bloom filter
- 1.4 应用
- 2 跳跃表(SkipList)
-
-
- 2.1.1 跳跃表的结构
- 2.2.2 查找操作
- 2.2.3 插入操作
- 2.2.4 除操作
-
- 3 LSM树
1 布隆过滤器(Bloom Filter)
Bloom Filter(简称BF),是二进制向量数据结构,常被用来检测某个元素是否是巨量数据集合中的成员
优点
- 具有很好的空间和时间效率,尤其是空间效率极高:因为不需要存储集合数据本身内容
- 不会漏判(False Negative)
缺点:
查询某个成员是否属于集合时,会发生误判(False Positive):即如果某个成员不在集合中,有可能BF会得出其在集合中的结论:
因此只能适用于允许一定误判率的情况
1.1 基本原理
BF可以高效地表征集合数据:使用长度为m的位数组来存储集合信息,同时使用k个相互独立的哈希函数将数据映射到位数组空间。
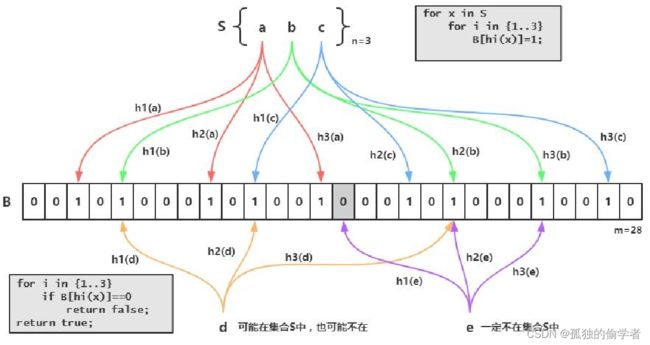
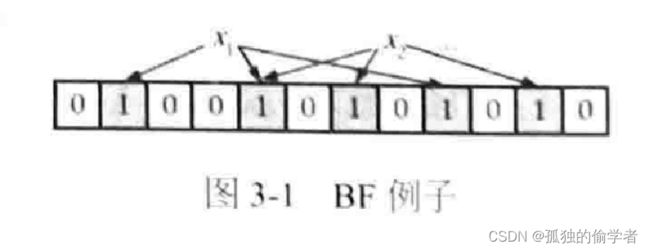
为什么会发生误判呢?
位数组长度为12,使用3个哈希函数,图中表示集合中两个成员x1和x2已经通过上文所述算法表现到位数组集合中了( 3个哈希函数值对应位置都设置为1 )。如果此时查询不属于集合的成员X3是否在集合中,而正好3个哈希函数对X3计算后对应的位置分别是2、7和11,那么根据判断规则,BF会认为x3属于集合,因为其对应位置都为1,此时就发生了误判现象。
【注】:尽管BF会产生误判,但是不会发生漏判(False Negative )的情况:即如果某个成员确实属于集合,那么BF一定能给出正确判断。实际中一般希望误判率低于1%。
1.2 误判率及相关计算
影响因素:
- 集合大小n、哈希函数的个数k和位数组大小m。
- 集合大小n越大,位数组中就会有更大比例的位置被设置为1。
- 位数组大小m越大,0比特位的比例就会越高,误判率就越小。
- 哈希函数个数对误判率的影响情况比较复杂,哈希函数越多,明显误判的可能就越小。
误判率:
经过数学分析,3个因素与误判率的关系如下:
![]()
那么假设n和m已知,即已知集合元素个数和位数组大小,经过分析,最优的哈希函数个数为:
![]()
在实际应用中,更常见的需求是假设已知集合大小n,并设定好误判率P,需要计算给BF分配多大内存合适,也就是需要确定m的大小。如下公式可以解决这个问题:
![]()
1.3 BF的改进:counting bloom filter
基本的BF在使用时有个缺点:无法删除集合成员,只能增加成员并对其査询。
计数BF ( Counting Bloom Filter )对此做岀了改进,使得BF可以删除集合成员,大大拓展了 BF的使用范围。
改进思路:基本BF无法实现删除的根本原因是其基本信息单元是1个比特位,所以只能表达两种状态,致使其表达能力非常有限。改进的思路很直接,将基本信息单元由1比特位拓展为多个比特位(例如采用3个比特位),这样就可以有更多表达能力,可以承载更多信息。
注:
- 计数BF拓展了 BF的应用场景,对应的代价是增加了位数组大小,如果采取3比特位作为基本单元的话,则位数组大小增加3倍。
- 另外,存在计数溢出的可能,因为比特位表达能力仍然有限, 这样当计数很大的时候存在计数溢出问题。
1.4 应用
- 因为BF的极高空间利用率,其在各个领域获得了非常广泛的使用,尤其是数据量极大且容忍一定误判率的场合。
- 比如Google Chrome浏览器使用它进行恶意URL的判断;
- 网络爬虫使用它对已经爬取过的URL进行判断;
- 缓存使用BF来对海量数据进行查找;
- 比特币使用BF对历史交易进行验证;
- 数据库领域使用BF来实现Bloom Join,即加速两个大小差异巨大的表的Join过程.
- 在BigTable中,BF对于读操作的效率提升有巨大帮助。BigTable将SSTable文件中包含的数据记录Key形成BF结构并将其放入内存或缓存,这样就能极高地提高查询速度,对于改善读操作有巨大的帮助作用。
注:
- 在这种场景下,BF的误判并不会造成严重影响。
- 并且BF的不会漏判则起了很大作用,因为如果发生漏判,则本来在某个SSTable文件中的记录会无法找到,这意味着读操作的失败,很明显这是不允许的。Cassandra在实现时也采取了类似思路。
2 跳跃表(SkipList)
于1990年由William Pugh提出,是一种可替代平衡树的数据结构,但是又不像平衡树那样需要强制保持树的平衡。实现和维护很简单,在很多大数据系统中用于维护有序列表 的读/写;例如LevelDB在实现其用于内存中暂存数据的结构MemTable就是使用SkipList实现的;Redis在实现Sorted Set数据结构时也采用Skiplist。
跳跃表的时空效率:
- 空间复杂度:O(n)
- 跳跃表高度:O(logn)
相关操作的时间复杂度:
- 查找: O(logn)
- 插入: O(logn)
- 删除: O(logn)
可近乎于替代平衡树,并且编程复杂度较同类的AVL树,红黑树等要低得多。
传统有序链表,查找数据只能顺序遍历;设想:如果链表中一般节点都能够多保留一个指向后续节点之后的指针,那么此时最多遍历[n/2]+1次即可找到任意节点(n为链表长度)如果增加3个、4个甚至更多脂针呢?这就是Skiplist的核心思路。

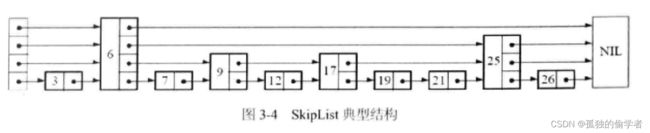
2.1.1 跳跃表的结构
跳跃表由多条链构成(S0,S1,S2…Sh),且满足如下两个条件:
-
S0包含所有的元素,并且所有链中的元素按照升序排列。
-
每条链中的元素集合必须包含于序数较小的链的元素集合,即:
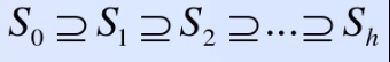
-
依赖随机数决定该节点有多少个指向后续节点的指针,有几个指针就是几层(叫做Level)。
2.2.2 查找操作
在跳跃表中查找一个元素×,按照如下几个步骤进行:
- 从最上层的链(Sh)的开头开始
- 假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。将y与×作比较
x=y 输出成功,输出相关信息
x>y 从p向右移动到q的位置
x- 如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
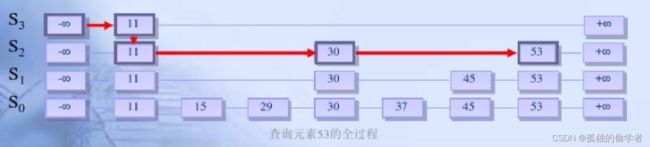
- 如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
2.2.3 插入操作
在跳跃表中插入一个元素x由两部分组成:查找插入的位置和插入对应元素。
为了确定插入的“列高”,我们引入一个随机决策模块:
产生一个0到1的随机数r,如果r小于一个概率因子p,则执行方案A,否则,执行方案B

具体步骤:
- 列的初始高度为1
- 插入元素时,不停地执行随机决策模块
- 如果要求被执行的是A操作,则将列的高度加1,并且继续反复执行随机决策模块
- 直到第i次,模块要求执行的是B操作,我们结束决策,并向跳跃表中插入一个高度为i的列
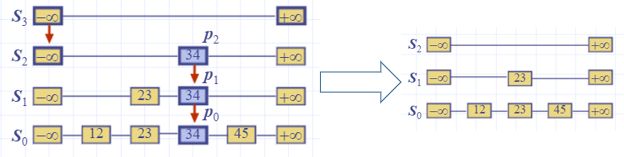
假设我们现在要插入一个元素40到已有的跳跃表中

随机化模块运行情况

2.2.4 除操作
目的:在跳跃表中删除一个元素x
删除操作分为以下三个步骤:
- 在跳跃表中找到这个元素的位置,如果未找到,则退出
- 将元素所在整列从表中删除
- 将多余的“空链”删除
3 LSM树
本质:LSM树(Log-structured Merge-tree )的本质是将大量的随机写操作转换成批量的序列写 ,这样可以极大地提升磁盘数据写入速度,所以LSM树非常适合对写操作效率有高要求的应用场景 。但是其付出的代价是读效率有所降低,这往往可以引入Bloom Filter或者缓存等优化措施来对读性能进行改善。
应用: LSM树在大数据存储系统中获得了极为广泛的使用,比如BigTable中的单机数据存储引擎本质上就是LSM树,基于Flash的海量存储系统SILT也采用了 LSM树,内存数据库RAMCloud同样采用了这个数据结构。除此之外还有很多系统都采用LSM树,比如Cassandra. LevelDB等。
下面以LevelDB的LSM树结构来大致介绍其一般实现原理,其他系统使用LSM树的方式与此类似。
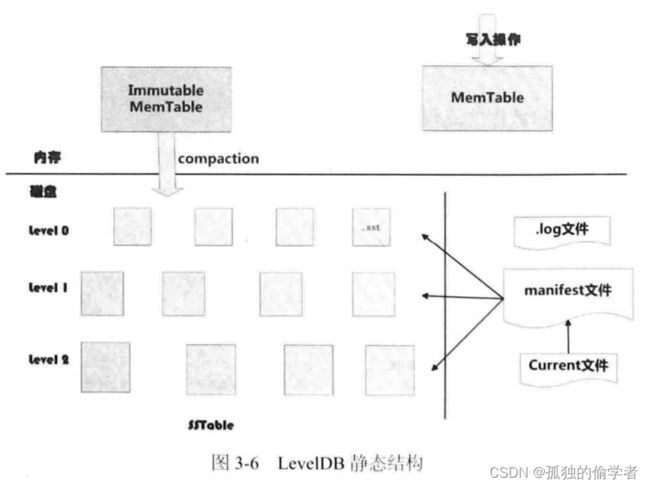
从图中可以看出,构成LevelDB静态结构的包括6部分:
- 内存中的MemTable和Immutable MemTable
- 磁盘上的Current文件,manifest文件、log文件以及SSTable 文件这几种主要文件。
LevelDB除了这6个主要部分外还有一些辅助的文件,但是以上6个文件和数据结构是LevelDB的主体构成元素。
-
写入操作:
当应用写入一条Key: Value记录的时候,LevelDB会先往log文件里写入,成功后将记录插进MemTable中,这样基本就算完成了写入操作。
因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,而且MemTable采用了维护有序记录快速插入查找的SkipList数据结构,所以说LSM树是一种高速写入数据结构的主要原因 -
log文件:主要是用于系统崩溃恢复而不丢失数据。
假如没有log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及保存到磁盘,所以会丢失数据。为了避免这种情况,LevelDB在写入内存前先将操作记录到log文件中,然后再记入内存中,这样即使系统崩溃,也可以从log文件恢复内存中的MemTable,不会造成数据的丢失。 -
Immutable MemTable:当MemTable插入的数据占用内存到了一个界限后,需要将内存的记录导出到外存文件中, LevelDB会生成新的log文件和MemTable,原先的MemTable就成为Immutable MemTable,即这个MemTable的内容是不可更改的,只能读不能写入或者删除。
新到来的数据被记入新的log文件和MemTable, LevelDB后台调度会将Immutable MemTable的数据导出到磁盘,形成一个新的SSTable文件。 -
SSTable:就是由内存中的数据不断导出并进行Compaction操作后形成的。并且SSTable的所有文件是一种层级结构,第1层为Level 0,第2层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDB的原因。SSTable中的文件是主键有序的,也就是说,在文件中小key记录排在大key记录之前,各个 Level的SSTable都是如此。
【注】:这里需要注意的一点是Level 0的SSTable文件(后缀为.sst)和其他Level的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠,比如有两个level 0的sst文件,文件A和文件B,文件A的key范围是{bar,car},文件B的key范围是{blue,same}, 那么很可能两个文件都存在key="blood"的记录。对于其他Level的SSTable文件来说,则不会出现同一层级内.sst文件的key重叠现象,也就是说Level L中的任意两个.sst文件,可以保证它们的key值是不会重叠的。
-
manifest文件:SSTable中的某个文件属于特定层级,而且其存储的记录是key有序的,那么必然有文件中的最小key和最大key,这是非常重要的信息,LevelDB应该记下这些信息。manifest就是记载这些信息的。它记载了SSTable各个文件的管理信息,比如属于哪个Level、文件名称、最小key和最大key各自是多少。
如图是manifest所存储内容的示意。
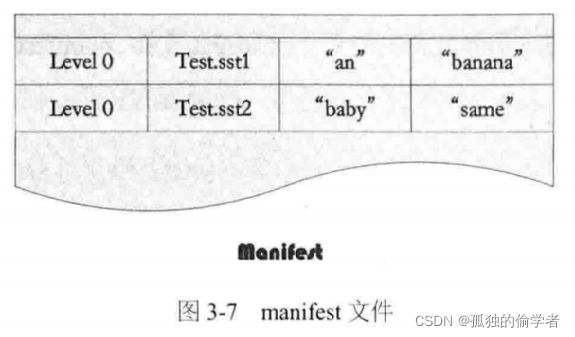
图中只显示了两个文件(而manifest会记载所有SSTable文件的这些信息),即Level 0的Test.sst1和Test.sst2文件,同时记载了这些文件各自对应的key范围,比如Test.sstl的key范围是“an"到 “banana“,而文件Test.sst2的key范围是“baby”到“same”,可以看岀两者的key范围是有重叠的。 -
Current文件:其内容只有一个信息,就是记载当前的manifest文件名。因为在LevleDB运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,manifest也会跟着反映这种变化,此时往往会生成新的manifest文件来记载这种变化,而Current则用来指出哪个manifest文件才是我们关心的那个manifest文件。
LSM树中很关键的一点就是Compaction操作,下面介绍 LevelDB中的Compaction是如何实现的。
LevelDB的Compaction机制和过程与BigTable是基本一致的。
BigTable中主要的3种类型的 Compaction:分别是 minor、major 和 full。
- minor Compaction:把 MemTable 中的数据导出到SSTable文件中。
- major Compaction:合并不同层级的SSTable文件。
- full Compaction:将所有SSTable进行合并。
LevelDB包含其中两种:minor和major。
minor Compaction的过程,图是其机理的示意图。

- 从图3-8可以看出,当MemTable中记录数量到了一定程度会转换为Immutable MemTable,此时只能从中读取KV内容。
- Immutable MemTable其实是一个SkipList多层级队列,其中的记录是根据key有序排列的。所以minor Compaction实现起来也很简单,就是按照Immutable MemTable中记录由小到大遍历,并依次写入一个Level 0的新建SSTable文件中,写完后建立文件的index数据,这样就完成了一次minor Compaction。
- 从图中也可以看岀,对于被删除的记录,在minor Compaction过程中并不真正删除这个记录。
- major Compaction的过程:当某个Level下的SSTable文件数目超过一定设置值后,LevelDB会从这个Level的SSTable中选择一个文件(Level>0 ),将其和高一层级的Level+1的SSTable文件合并。
【注】:我们知道在大于0的层级中,每个SSTable文件内的key都是由小到大有序存储的,而且不同文件之间的key范围(文件内最小key和最大key之间)不会有任何重叠。Level 0的SSTable文件有些特殊,尽管每个文件也是根据key由小到大排列的,但是因为Level 0的文件是通过minor Compaction直接生成的,所以任意两个Level 0 F的两个SSTable文件可能在key范围上有重叠。所以在做major Compaction的时候,对于大于Level 0的层级,选择其中一个文件就行,但是对于Level 0来说,指定某个文件后,本Level中很可能有其他SSTable文件的key范围和这个文件有重叠,这种情况下,要找岀所有有重叠的文件和Level 1的文件进行合并,即Level 0在进行文件选择的时候, 可能会有多个文件参与major Compaction

major Compaction的过程如下:
对多个文件采用多路归并排序的方式,依次找岀其中最小的key 记录,也就是对多个文件中的所有记录重新进行排序。
之后采取一定的标准判断这个key是否还需要保存,如果判断没有保存价值,那么直接抛掉;如果觉得还需要继续保存,那么就将其写入LevelL+1层中新生成的SSTable文件中。就这样对KV数据进行一一处理,形成了一系列新的L+1层数据文件,之前的L层文件和L+1层参与Compaction的文件数据此时已经没有意义了,所以全部删除。这样就完成了L层和L+1层文件记录的合并过程。