Pandas替代框架性能测评——Polars|Modin|Pandarallel|pySpark
Pandas在大数据处理上的不足,制约了其在数据科学领域的进一步发展,尽管它在小数据集上处理非常灵活方便;探究Pandas在大数据时代的替代品,是算法工程师面临的重要问题。
当然,现在各类公有云和分析型数据库大行其道,大数据对于它们来说不是问题,但这往往需要付出一定的成本才能获得商用版本带来的便捷与高效。那么,有没有低成本的方案可供选择呢?
反思Pandas面对大数据时羸弱的表现:由于Pandas在设计时只能单核运行,因此无法用到计算机的多核CPU,针对这个弱点的改善,业界实现了很多替代方案。
下面分别测试Pandas、Polars、Modin和Pandarallel框架,以及大数据的常客——Spark的python版本pySpark,在较小的数据集上,运行UDF函数的性能表现,给我们今后选择框架带来参考。
这里选用的数据集shape为(45, 500000),数据经处理后需要将每列值进行md5哈希并截取后段(apply 函数),本地电脑环境为:Macbook Pro i5/16G/512G。
太长不看版:为节约时间,这里直接放出各个框架的测试结果,采取三次平均值。
| 序号 | 框架 | 版本 | 操作 | 操作时长 |
| 1 | Pandas | 1.3.5 | 读取数据 | 0:00:01.208665 |
| apply函数 | 0:05:14.027412 | |||
| 2 | Polars | 0.13.34 | 读取数据 | 0:00:00.280509 |
| apply函数 | 0:00:50.164057 | |||
| 3 | Modin | 0.12.1 | 读取数据 | 0:00:03.598980 |
| apply函数 | 0:04:08.191504 | |||
| 4 | Pandarallel | 1.6.1 | 读取数据 | 0:00:01.165021 |
| apply函数 | 0:01:51.759348 | |||
| 5 | pySpark | 3.2.1 | 读取数据 | 0:00:00.378601 |
| apply函数 | 0:00:22.682952 |
简单结论:
a. 读取数据速度排名:Polars > pySpark >> Pandarallel > Pandas > Modin
b. Apply函数处理速度排名: pySpark > Polars > Pandarallel >> Modin > Pandas
c. 在处理Apply函数上,Modin和Pandarallel并不如其所宣扬的那样带来很大的性能提升,尤其是Pandarallel运行时,明显感受到电脑风扇启动;
d. Polars表现令人惊艳;
e. Spark表现出其在大数据处理上的强劲实力;
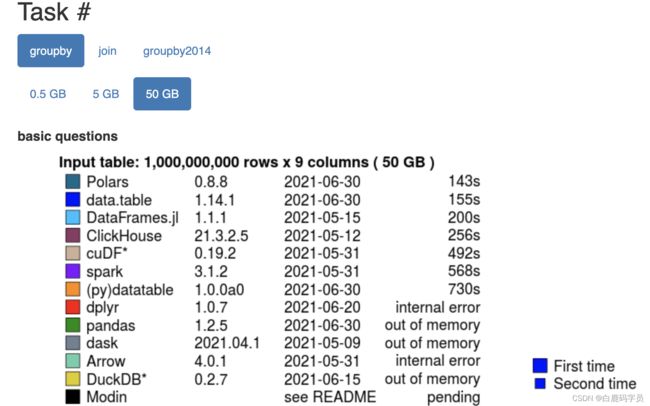
备注:H2O.ai公司已经做过这些框架的性能测评,我这里补充了另一个常见操作——Apply函数的性能测试,供参考。
Database-like ops benchmark https://h2oai.github.io/db-benchmark/
https://h2oai.github.io/db-benchmark/
~~~~~~~~~~~~~~下面进入PK环节 ~~~~~~~~~~~~~
apply 函数为:
from hashlib import md5
def apply_md5(item):
encoder = md5()
encoder.update(str(item).encode('utf-8'))
k = int(encoder.hexdigest(), 16)
h = k % 2147483648
return h1. Pandas测试
读取数据集,记录该操作耗时:
import pandas as pd
df_data = pd.read_csv(data_file, names=col_list)显示原始数据,df_data.head()
| col_0 | col_1 | col_2 | col_3 | col_4 | col_5 | col_6 | col_7 | col_8 | col_9 | col_10 | col_34 | col_35 | col_36 | col_37 | col_38 | col_39 | col_40 | col_41 | col_42 | col_43 | col_44 | |
| 0 | 546075 | 1 | 3 | 108 | 104 | 44 | 14491 | 10 | 1 | 1 | 278686 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 99363 |
| 1 | 737831 | 0 | 0 | 97 | 78 | 109 | 8290 | 10 | 5 | 7 | 144807 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 857989 |
| 2 | 758475 | 0 | 0 | 37 | 37 | 37 | 5925 | 10 | 1 | 1 | 183451 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 819748 |
| 3 | 936379 | 0 | 0 | 37 | 37 | 37 | 5925 | 10 | 1 | 1 | 409147 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 819748 |
| 4 | 790741 | 0 | 0 | 37 | 37 | 37 | 5925 | 10 | 1 | 1 | 372559 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 819748 |
运行apply函数,并记录该操作耗时:
for col in df_data.columns:
df_data[col] = df_data.apply(lambda x: apply_md5(x[col]), axis=1)显示结果数据,df_data.head()
| col_0 | col_1 | col_2 | col_3 | col_4 | col_5 | col_6 | col_7 | ... | col_37 | col_38 | col_39 | col_40 | col_41 | col_42 | col_43 | col_44 | |
| 0 | 613570340 | 1869972635 | 1923594995 | 2024701195 | 768635540 | 120528582 | 659016270 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 190489033 |
| 1 | 746716728 | 2038916314 | 2038916314 | 267377820 | 911787345 | 8293277 | 1008812386 | 1365501984 | ... | 1869972635 | 1869972635 | 1276413484 | 1869972635 | 1276413484 | 1869972635 | 1869972635 | 1468256769 |
| 2 | 1668942466 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1920310884 |
| 3 | 1301686701 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 2038916314 | 1920310884 |
| 4 | 725939270 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1920310884 |
2. Polars测试
Polars特点:
- Polars库在io上优势明显,非常快;
- Polars是Rust编写的,内存模型是基于Apache Arrow,python只是一个前端的封装;
- Polars存在两种API,一种是Eager API,另一种则是Lazy API;
- Eager API和Pandas的使用类似,语法差不太多,立即执行就能产生结果。
- Lazy API像Spark,首先将查询转换为逻辑计划,然后对计划进行重组优化,以减少执行时间和内存使用。
用户文档:
List context and row-wise compute - Polars - User Guidehttps://pola-rs.github.io/polars-book/user-guide/dsl/list_context.html
安装:pip3 install polars -i https://pypi.mirrors.ustc.edu.cn/simple/
读取数据集,记录耗时:
import polars as pl
pl_data = pl.read_csv(data_file, has_header=False, new_columns=col_list)运行apply函数,记录耗时:
pl_data = pl_data.select([
pl.col(col).apply(lambda s: apply_md5(s)) for col in pl_data.columns
])查看运行结果:
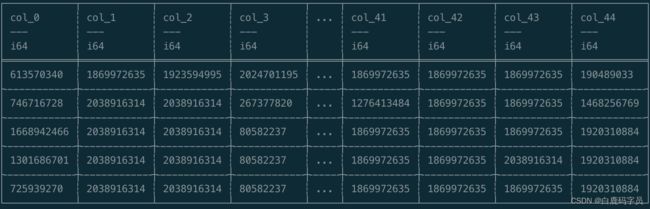
3. Modin测试
Modin特点:
- 使用DataFrame作为基本数据类型;
- Modin具有与 Pandas 相同的应用程序接口(API);
- Pandas 仍然只会利用一个内核,而 Modin 会使用所有的内核;
- 能处理1MB到1TB+的数据;
- Modin 利用 Ray 使用同样的代码跑单台机器,也可以用于集群;
- 使用者不需要知道系统有多少内核,也不需要指定如何分配数据;
用户文档:
Scale your pandas workflow by changing a single line of code — Modin 0.14.1+0.gd7eb019b.dirty documentationhttps://modin.readthedocs.io/en/stable/
安装:pip3 install "modin[ray]" -i https://pypi.mirrors.ustc.edu.cn/simple/
为防止报错“ModuleNotFoundError: No module named 'aiohttp.signals'”,可以这样来解决:pip3 install aiohttp==3.7 -i https://pypi.mirrors.ustc.edu.cn/simple/
读取数据集,记录耗时:
import modin.pandas as pd
md_data = pd.read_csv(data_file, names=col_list)运行apply函数,记录耗时:
for col in md_data.columns:
md_data[col] = md_data.apply(lambda x: apply_md5(x[col]), axis=1)查看运行结果:
| col_0 | col_1 | col_2 | col_3 | col_4 | col_5 | col_6 | col_7 | ... | col_37 | col_38 | col_39 | col_40 | col_41 | col_42 | col_43 | col_44 | |
| 0 | 613570340 | 1869972635 | 1923594995 | 2024701195 | 768635540 | 120528582 | 659016270 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 190489033 |
| 1 | 746716728 | 2038916314 | 2038916314 | 267377820 | 911787345 | 8293277 | 1008812386 | 1365501984 | ... | 1869972635 | 1869972635 | 1276413484 | 1869972635 | 1276413484 | 1869972635 | 1869972635 | 1468256769 |
| 2 | 1668942466 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1920310884 |
| 3 | 1301686701 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 2038916314 | 1920310884 |
| 4 | 725939270 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1920310884 |
4. Pandarallel测试
Pandarallel特点:
- 非常简单实现Pandas并行;
- 没有自己的读取文件方式,依赖Pandas读取文件;
用户文档:
pandarallel · PyPIAn easy to use library to speed up computation (by parallelizing on multi CPUs) with pandas.https://pypi.org/project/pandarallel/
读取数据集,记录耗时:
import pandas as pd
from pandarallel import pandarallel
pandarallel.initialize()
dp_data = pd.read_csv(data_file, names=col_list)运行apply函数,记录耗时:
for col in dp_data.columns:
dp_data[col] = dp_data.parallel_apply(lambda x: apply_md5(x[col]), axis=1)查看运行结果:
| col_0 | col_1 | col_2 | col_3 | col_4 | col_5 | col_6 | col_7 | ... | col_37 | col_38 | col_39 | col_40 | col_41 | col_42 | col_43 | col_44 | |
| 0 | 613570340 | 1869972635 | 1923594995 | 2024701195 | 768635540 | 120528582 | 659016270 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 190489033 |
| 1 | 746716728 | 2038916314 | 2038916314 | 267377820 | 911787345 | 8293277 | 1008812386 | 1365501984 | ... | 1869972635 | 1869972635 | 1276413484 | 1869972635 | 1276413484 | 1869972635 | 1869972635 | 1468256769 |
| 2 | 1668942466 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1920310884 |
| 3 | 1301686701 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 2038916314 | 1920310884 |
| 4 | 725939270 | 2038916314 | 2038916314 | 80582237 | 80582237 | 80582237 | 549795305 | 1365501984 | ... | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1920310884 |
5. pySpark测试
Spark资料很多了,可以参考:pyspark系列--pandas和pyspark对比_振裕的博客-CSDN博客_pyspark与pandas区别目录 1. pandas和pyspark对比 1.1. 工作方式1.2. 延迟机制1.3. 内存缓存1.4. DataFrame可变性1.5. 创建1.6. index索引1.7. 行结构1.8. 列结构1.9. 列名称1.10. 列添加1.11. 列修改1.12. 显示1.13. 排序1.14. 选择或切片1.15. 过滤1.16. 整合1.17. 统计...https://blog.csdn.net/suzyu12345/article/details/79673483
安装:pip3 install pyspark -i https://pypi.mirrors.ustc.edu.cn/simple/
读取数据集,记录耗时:
from pyspark.sql import SparkSession
import pyspark.pandas as ps
spark = SparkSession.builder.appName('testpyspark').getOrCreate()
ps_data = ps.read_csv(data_file, names=header_name)运行apply函数,记录耗时:
for col in ps_data.columns:
ps_data[col] = ps_data[col].apply(apply_md5)查看运行结果:
| col_0 | col_1 | col_2 | col_3 | col_4 | col_5 | col_6 | col_7 | col_8 | col_9 | col_10 | col_11 | col_12 | col_13 | col_14 | col_15 | col_16 | col_17 | col_18 | col_19 | col_20 | col_21 | col_22 | col_23 | col_24 | col_25 | col_26 | col_27 | col_28 | col_29 | col_30 | col_31 | col_32 | col_33 | col_34 | col_35 | col_36 | col_37 | col_38 | col_39 | col_40 | col_41 | col_42 | col_43 | col_44 | |
| 0 | 613570340 | 1869972635 | 1923594995 | 2024701195 | 768635540 | 120528582 | 659016270 | 1365501984 | 1869972635 | 1869972635 | 528126110 | 2038916314 | 1869972635 | 1869972635 | 40185290 | 1967264300 | 2038916314 | 1869972635 | 1365501984 | 1923594995 | 1276413484 | 1967264300 | 1956845781 | 1273636163 | 1956845781 | 1365501984 | 1956845781 | 2125574876 | 2125574876 | 2125574876 | 2125574876 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 190489033 |
| 1 | 746716728 | 2038916314 | 2038916314 | 267377820 | 911787345 | 8293277 | 1008812386 | 1365501984 | 1956845781 | 1273636163 | 1434204725 | 696132461 | 1923594995 | 1276413484 | 1869972635 | 1365501984 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1923594995 | 1365501984 | 1365501984 | 1365501984 | 1365501984 | 1869972635 | 2125574876 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1869972635 | 1276413484 | 1869972635 | 1276413484 | 1869972635 | 1869972635 | 1468256769 |
总结
| 序号 | 框架 | 版本 | 操作 | 操作时长 | 读取数据速度排名 | Apply函数运行速度排名 |
| 1 | Pandas | 1.3.5 | 读取数据 | 0:00:01.208665 | 4 | 5 |
| apply函数 | 0:05:14.027412 | |||||
| 2 | Polars | 0.13.34 | 读取数据 | 0:00:00.280509 | 1 | 2 |
| apply函数 | 0:00:50.164057 | |||||
| 3 | Modin | 0.12.1 | 读取数据 | 0:00:03.598980 | 5 | 4 |
| apply函数 | 0:04:08.191504 | |||||
| 4 | Pandarallel | 1.6.1 | 读取数据 | 0:00:01.165021 | 3 | 3 |
| apply函数 | 0:01:51.759348 | |||||
| 5 | pySpark | 3.2.1 | 读取数据 | 0:00:00.378601 | 2 | 1 |
| apply函数 | 0:00:22.682952 |
a. 读取数据速度排名:Polars > pySpark >> Pandarallel > Pandas > Modin
b. Apply函数处理速度排名: pySpark > Polars > Pandarallel >> Modin > Pandas
c. 在处理Apply函数上,Modin和Pandarallel并不如其所宣扬的那样带来很大的性能提升,尤其是Pandarallel运行时,明显感受到电脑风扇启动;
d. Polars表现令人惊艳,加上其对各类图表的支持,不失为Pandas的平替,不过,Polars虽与Pandas有一定的相似性,但很多API使用方法不同,有一定的学习成本;
e. pySpark表现出其在大数据处理上的强劲实力,与Pandas和Polars相比,在数据分析方面较弱,但集成了一定的机器学习能力;
参考资料:
List context and row-wise compute - Polars - User Guide
Scale your pandas workflow by changing a single line of code — Modin 0.14.1+0.gd7eb019b.dirty documentation
Python/Pandas如何处理百亿行,数十列的数据? - 知乎
Why Python is Slow: Looking Under the Hood | Pythonic Perambulations
Scaling Pandas: Dask vs Ray vs Modin vs Vaex vs RAPIDS
Database-like ops benchmark
pyspark系列--pandas和pyspark对比_振裕的博客-CSDN博客_pyspark与pandas区别