大模型时代下做科研的四个思路
背景
在模型越来越大的时代背景下,如何利用有限的资源做出一些科研工作。
四个方向
1、Efficient(PEFT)
提升训练效率,这里以PEFT(parameter efficient fine tuning)为例
2、Existing stuff(pretrained model)、New directions
使用别人的预训练模型,新的研究方向
3、plug-and-play
做一些即插即用的模块,例如模型的模块、目标函数、新损失函数、数据增强方法等等。
4、Dataset,evaluation and survey
构建数据集、发表分析为主的文章或者综述论文
一、Efficient(PEFT)-第一个方向
通过论文AIM为例讲述如何进行PEFT,即在硬件资源有限时对大模型进行高效微调
- 论文地址:https://arxiv.org/abs/2302.03024
- 论文标题:AIM: Adapting Image Models for Efficient Video Action Recognition
- 标题翻译:调整图像模型以实现高效的视频动作识别
思考:已经训练好的图像模型是否需要继续微调?
1、clip已经证明了即使ZeroShot(模型不变,直接在各个数据集上进行推理),它的效果也很好。即一个训练很好的图片模型从中提取视觉特征是有泛化性、有效的。
2、继续微调会导致灾难性遗忘。如果使用少量数据在大模型上微调,可能会直接过拟合,或者大模型的很多特征丢失。
结论:预训练的图像模型不需要继续微调。
传统模型和论文改进的微调方法对比图:

因此,论文的做法是,尝试将模型参数锁住,在上面加一些时序处理模块、目标函数等修改周边的方式(即PEFT)让图片模型能够做视频理解的任务,不需要重新训练视频模型,省时省力。
两种PEFT方法
1、adapter
最早来自于这篇论文:
- 论文地址:https://arxiv.org/abs/1902.00751
- 论文标题:Parameter-Efficient Transfer Learning for NLP
- 标题翻译:用于NLP的参数高效转移学习
Adapter层的结构,如下图右边所示:下采样FC层+非线性激活层+上采样FC层,加上残差连接。
这里PEFT的方法是指,如下图左边所示,在Transformer中加入了两个adapter,进行微调时,原来的Transformer的参数都是锁住的,只有adapter层的参数在学习。

adapter层参数量和大模型相比非常少,例如在175B的GPT3中使用LoRa,需要训练的参数只要万分之一。因此训练成本大幅降低。
2、prompt tuning
- 论文地址:https://arxiv.org/abs/2109.01134
- 论文标题:Learning to Prompt for Vision-Language Models
prompt tuning是指可以任意调整提示词,这样的调整对最后的性能会有很大的影响,能否得到想要的结果,取决于有没有选择一个好的提示词。例如下图所示,不同的提示词对准确率的影响很大。

上图是如何通过提示给图片分类的?将类别名称CLASS给模型,看哪个文字和图片的相似度最高。
Prompt分为两种:
Hard Prompt:人工设置的提示词,不能修改也无法学习。设置这些需要一定的先验知识,但我们并不会总有这样的先验知识。
Soft Prompt:将提示词设置为一个可学习的向量。如下图所示 ,将文本端(text encoder)的输入CLASS设置为learnable context,模型优化的是这个context部分。这样既可以节省很多计算量 ,也可以避免在下游任务时手动设置提示词。

VPT
将可学习的Prompt方法用到纯视觉任务中,做法如下图所示。
- 论文地址:https://arxiv.org/abs/2203.12119
- 论文标题:Visual Prompt Tuning

图中蓝色部分是原来训练好的模型,红色是需要微调的prompt,加入Prompt tuning有两种方式:
1、VPT: Deep,在每一层的输入输出都加入prompt。
2、VPT: Shallow,在输入端加入prompt。
近期PEFT方法总结,从统一的观点进行归纳:
- 论文地址:https://arxiv.org/abs/2110.04366
AIM模型设计
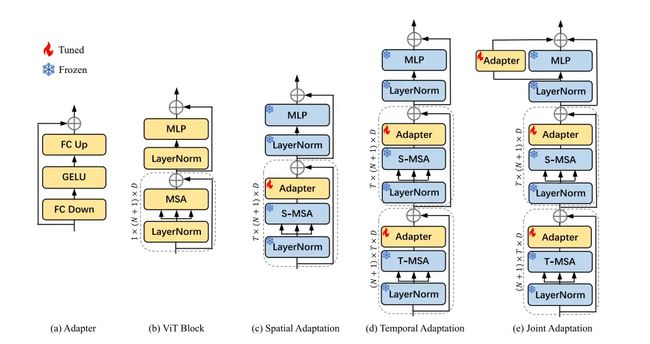
如上图所示,AIM模型就是在图b的ViT模型中加入图a的Adapter,共有图c、d、e三种方式:
1、Spatial Adaptation,只在S-MSA层后面加入Adapter,即不增加视频理解能力,只加一些学习的参数。
2、Temporal Adaptation,复用一个MSA层,在两个MSA层后面都加入Adapter,即让模型从Spatial和Temporal两个方向上进行学习,从而有时序建模的能力。
3、Joint Adaptation,在Temporal Adaptation的基础上,在MLP边上也加入Adapter,即让三个Adapter各司其职,使得优化问题更简单一些。
注:MSA是多头自注意力(MultiHead Self-Attention,S-MSA和T-MSA共享权重,但维度不同。
效果如下图所示,只用14M参数的AIM模型效果已经高过之前121M的模型。

二、Existing stuff(pretrained model)-第二个方向
有两点:
1、巧妙使用别人的预训练模型,从而达到去做FewShot,ZeroShot,或者最多Fine Tuning的实验。
2、新的研究方向。
通过这篇论文讲述这两点是如何运用的:
- 论文地址:https://arxiv.org/abs/2207.05027
- 论文标题:Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
从标题就可以看出这两点技巧:
1、这里的Self-supervised是指使用了预训练好的DINO、DeepUSPS、BASNet等网络
2、这里做的方向是Object-centric Learning,属于蓬勃发展的题目,玩家不多、数据集不大
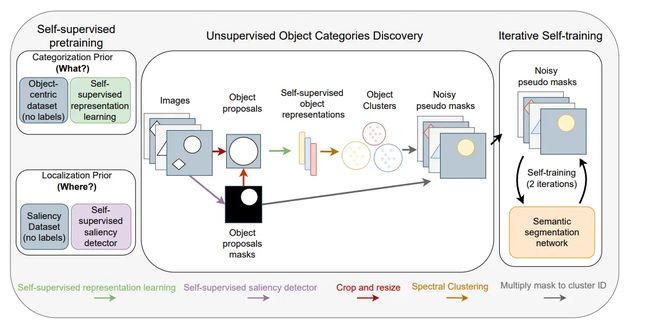
上图展示了如何使用几个预训练好的模型,在无监督的情况下找到新的物体,步骤如下:
1、通过预训练模型DeepUSPS找到一些显著性物体的Mask。
例如,图片中的篮球可以得到一个圆形的Mask
2、根据Mask将图片中的对应物体抠出来,并调整大小为224*224。
例如,将图片中的篮球抠出来并放大
3、然后将步骤2得到的图片通过预训练模型DINO返回一个1024*1024的特征(global representation)。
4、将所有的特征进行聚类Clustering,这样就可以通过无监督学习得到这些物体的分类ID。
注:聚类只能将相同的物体分类到一起,但并不知道具体是什么物体。
5、将图片和对应的分类ID去训练一个语义分割网络(Semantic segmentation network)。
注:这里相当于一个有监督的学习,标签来自于步骤4
6、一张图片可能有多个物体,所以加一个Self-training,多做几个轮回。
这样就可以从图片中找到物体了。
三、plug-and-play-第三个方向
做一些通用的、即插即用的模块,在一个设定的范围内,加入了这样的模块后,能够有一个统一的涨点,并且能给出合适的分析,就非常有说服力了。通过MixGen论文讲述如何加入模块:
- 论文地址:https://arxiv.org/abs/2206.08358
- 论文标题:MixGen: A New Multi-Modal Data Augmentation
文本的模型都很大,图片的模型相对来说小一些,但是自注意力的参数是可以共享的,所以尝试用文本大模型来蒸馏图片小模型
注:模型蒸馏:使用训练集训练出来一个完整复杂的teacher模型,然后设计一个小规模的student模型,再固定teacher模型的权重参数,然后使用训练集和teacher模型的输出同时对student模型进行训练,此时就需要设计一系列loss,让student模型在蒸馏学习的过程中逐渐向teacher模型的表现特性靠拢,使得student模型的预测精度逐渐逼近teacher模型。
为什么之前图片模型不做数据增强?
1、图片模型训练时已经用了很多图片了,不需要再做数据增强。
’2、或者做了数据增强,但是将其中的Color Jittering和Random Filp去掉了,因为这两个对图片的变化会导致图片和文本不匹配。
例如:图片有白色的狗和绿色的树,只对图片做Color Jittering会导致颜色变化,图片中不再是白色的狗,但是文本依然是白色的狗,这样文本和图片就不匹配了。
论文的做法:既然目标是尽可能保留更多信息,这里的做法很简单粗暴,就是直接将两个句子拼接在一起,这样就可以做到不丢失信息的情况下得到新的训练样本。
例如下图,将两个图片通过数据增强得到第三个图片,同时将两个图片的文本进行拼接得到第三个图片的文本。

审稿人的建设性提议:在下游任务只有少量数据时进行数据增强。
四、Dataset,evaluation and survey-第四个方向
构建数据集、发表分析为主的文章或者综述论文,这里举了两篇论文为例。
以数据集为主的big detection,将三个数据集整合到一起:
- 论文地址:https://arxiv.org/abs/2203.13249
视频动作检测的综述论文:
- 论文地址:https://arxiv.org/abs/2012.06567