猿人学第二题,手撕OB混淆给你看(step4-对象调用还原)
前情回顾:
猿人学第二题,手撕OB混淆给你看(Step1-开篇)
猿人学第二题,手撕OB混淆给你看(step2-字符串数字回填)
猿人学第二题,手撕OB混淆给你看(step3-函数调用还原)
对象调用还原
这一章会使用上一章生成的 02_ob_call_function_reload.json文件
最终生成一份02_ob_obj_property_reload.js文件和一份 02_ob_obj_property_reload.json 文件
上一章,我们已经把
_0x434ddb[$dbsm_0x42c3('0x1db', '30Py') + 'EU'] = $dbsm_0x42c3('0x1a5', 'Xgak') + 'Yu',
还原成了
_0x434ddb['Swi' + 'EU'] = 'pLE' + 'Yu',
我们发现现在有很多的字符串拼接处于待完成状态,
在进行对象调用还原之前,需要将这些字符串都拼接好.
拼接字符串
随便找一个字符串拼接的地方,观察一下结构
可以发现,他们分别是 一个类型为 BinaryExpression 的节点的 左右子节点,
且 类型都是 Literal
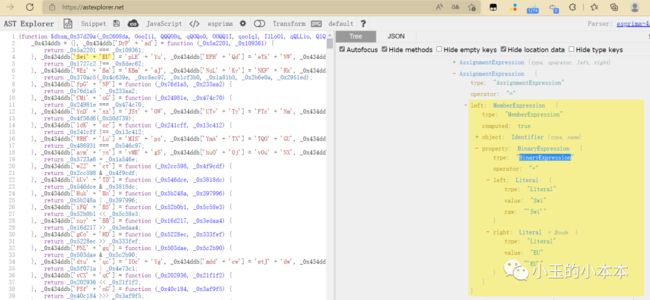
于是可以编写代码:
# test.py
# 将拆分开的对象属性名称合并
def concat_obj_property_name(node):
if type(node) == list:
for item in node:
concat_obj_property_name(item)
return
elif type(node) != dict:
return
# 捕获一个二元运算节点
if node['type'] == 'BinaryExpression':
if not (node['left']['type'] == 'Literal' and node['right']['type'] == 'Literal'):
# 如果 其中有参数不是 字符 类型,则将两个参数都继续递归
concat_obj_property_name(node['left'])
concat_obj_property_name(node['right'])
# 当两个参数分别的递归都完成, 参数类型最终都变为了 字符 类型,则可以合并,这样就实现了一连串的字符相加
if node['left']['type'] == 'Literal' and node['right']['type'] == 'Literal':
new_node = {'type': 'Literal', 'value': node['left']['value'] + node['right']['value']}
node.clear()
node.update(new_node)
return
for key in node.keys():
concat_obj_property_name(node[key])
if __name__ == '__main__':
# 生成基础文件
...
""" 字符串与数字回填[ok] """
...
""" 函数调用还原[ok] """
...
""" 对象调用还原[ok] """
with open('02_ob_call_function_reload.json', 'r', encoding='utf8') as f:
data = json.loads(f.read())
concat_obj_property_name(data)
with open('02_ob_concat_str.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data))
os.system('node JsonToJs 02_ob_concat_str.json 02_ob_concat_str.js')
# 会生成一份用于观察分析下一步的临时文件 02_ob_concat_str.js/json
这样,就将
_0x434ddb['Swi' + 'EU'] = 'pLE' + 'Yu',
还原成了
_0x434ddb['SwiEU'] = 'pLEYu',
获取对象的属性字典
我们用刚生成的 02_ob_concat_str.js来分析,
可以看到,先是声明了一个对象,然后不断的向这个对象添加新的属性,
(这些属性值的类型很杂,有字符串,有函数定义,有其它对象的属性调用…)
然后又在其它地方,调用了这个对象的大量属性
这一章要完成的事情就是将调用这些属性的地方,替换成这些属性的值
下图是定义属性的地方:
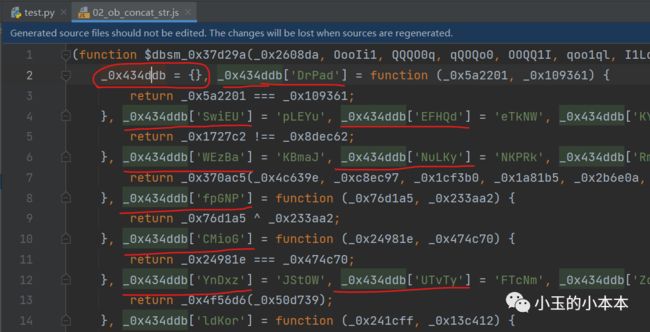
下图是调用属性的地方:
可以发现,它先将属性定义全部完成的对象(_0x434ddb),赋值给了另一个对象(_0x5500bb),画圈的地方,
然后大量调用新的对象
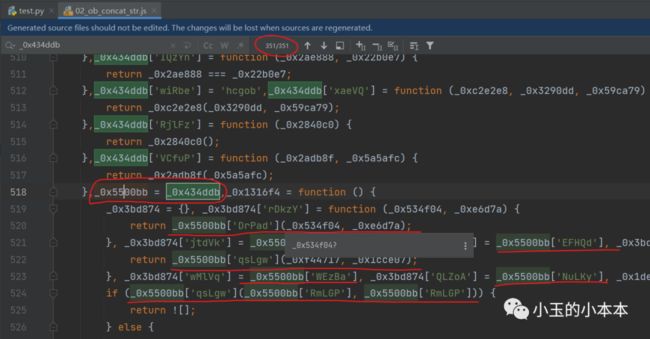
我们需要构造一个这样的字典,来保存 对象->属性->值 的映射关系,以便在还原时使用
# 对象属性字典结构示例
obj_property_dict = {
'对象名称1':{
'属性名称1': '属性值节点',
'属性名称2': '属性值节点',
...
},
'对象名称2':{
'属性名称1': '属性值节点',
'属性名称2': '属性值节点',
...
},
...
}
找到了他们之间的关系,接下来就需要分析他们的结构:
先分析属性赋值的部分
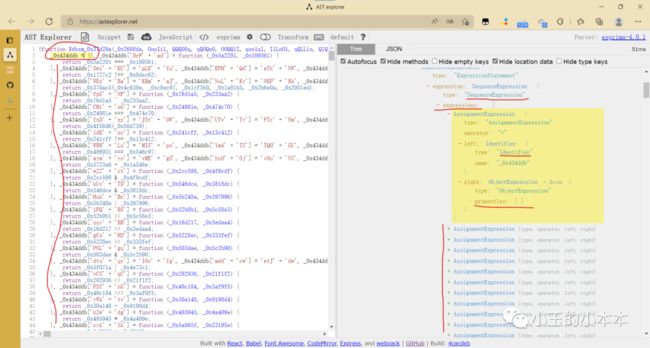
可以看到,对象声明,和属性添加所有的节点,都包含在一个类型为 SequenceExpression (表达式序列)节点的 expressions属性列表里面,
于是我们可以遍历这个列表,获取 对象->属性->值 的映射
# test.py
# 构造对象属性字典
obj_property_dict = {}
def get_property_dicet(node):
# 所有对象申明时都是: XXXX = {}, 然后使用 XXXX['xxxx'] = XXXXXXX 来添加属性
if type(node) == list:
for item in node:
get_property_dicet(item)
return
elif type(node) != dict:
return
# 捕获一个表达式序列
if node['type'] == 'SequenceExpression':
for i in range(- len(node['expressions']), 0, 1): # 这是一边正向遍历列表,并且可以一边删除元素的方式
item = node['expressions'][i]
# 捕获一个(变量/属性)声明节点
if item['type'] == 'AssignmentExpression':
# 是一个变量申明
if item['left']['type'] == 'Identifier':
# 声明的是一个空对象
if item['right']['type'] == 'ObjectExpression' and item['right']['properties'] == []:
obj_property_dict[item['left']['name']] = {}
obj_name_list.append(item['left']['name'])
del node['expressions'][i]
continue
# 声明 一个变量指向另一个变量 例: _0x5500bb = _0x434ddb,
elif item['right']['type'] == 'Identifier':
if item['right']['name'] in obj_property_dict:
obj_property_dict[item['left']['name']] = obj_property_dict[item['right']['name']]
obj_name_list.append(item['left']['name'])
del node['expressions'][i]
continue
# 是一个属性声明
elif item['left']['type'] == 'MemberExpression':
obj_name = item['left']['object']['name']
try:
obj_property_name = item['left']['property']['value']
obj_property_dict[obj_name][obj_property_name] = item['right']
del node['expressions'][i]
continue
except KeyError:
pass
# 处理完一个子节点后,将子节点的所有属性加入递归,以免漏网之鱼
for key in item.keys():
get_property_dicet(item[key])
for key in node.keys():
get_property_dicet(node[key])
if __name__ == '__main__':
# 生成基础文件
...
""" 字符串与数字回填[ok] """
...
""" 函数调用还原[ok] """
...
""" 对象调用还原[ok] """
# 拼接字符串
...
# 获取对象属性字典
get_property_dicet(data)
with open('02_ob_del_obj_property.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data))
os.system('node JsonToJs 02_ob_del_obj_property.json 02_ob_del_obj_property.js')
代码中可以看到,我在找到这些节点,将其存入字典中后,顺带就将其删除了,
因为这些节点在该章结束之后就不再有意义,现在留着,之后也会再次查找这些节点来删除.
此步骤会生成一个临时文件02_ob_del_obj_property.js,用于下一步的观察分析
对象调用还原
在获取了 对象->属性->值 的映射字典后,就可以查找调用这些属性的地方,将其还原
现在分析一下 02_ob_del_obj_property.js文件,对象调用的地方
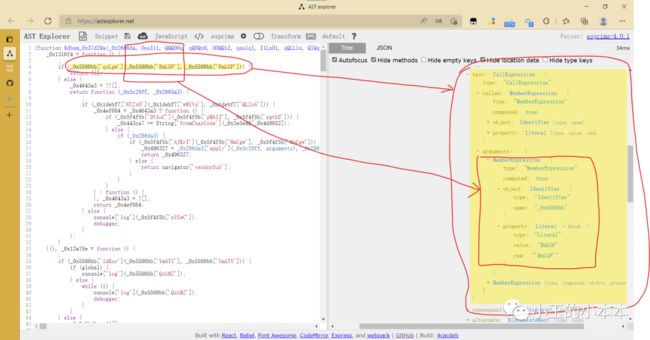
对象调用有两种方式:
函数式调用 CallExpression 类型的节点
直接调用属性 MemberExpression 类型的节点
MemberExpression 节点比较简单,直接就是返回字符串.
但是函数是调用的返回值有多种类型,需要做不同的应对
查看返回值类型要去上上一步生成的02_ob_concat_str.js文件,在上一个文件里,这些节点都被我删掉了,哈哈
具体有(这里我懒得截图,直接上大佬的图):
1.返回字符串(类型:Literal)
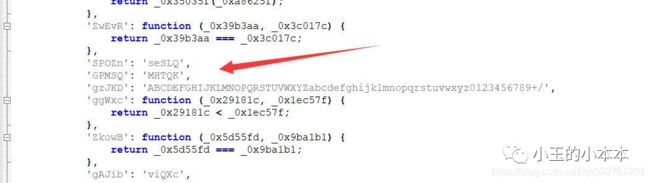
2.返回对象调用(类型:MemberExpression)
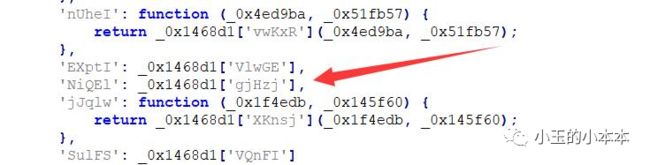
3.返回二元表达式(类型:BinaryExpression)
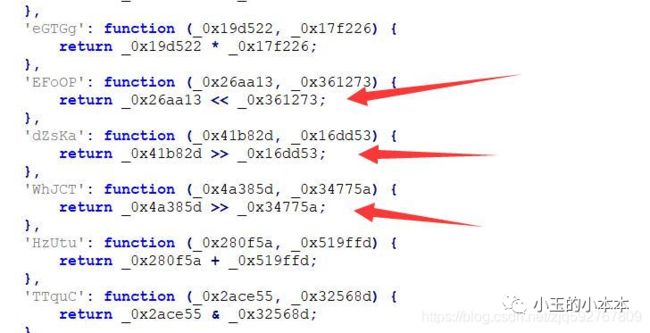
4.返回逻辑计算(类型:LogicalExpression)
因为这个文件没有,我就从其他地方截图

5.返回函数调用(类型:CallExpression)
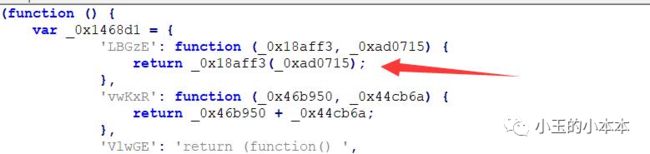
对于1和2,比较简单,调用什么就直接将节点替换为调用的内容即可。
就1,2的图示来看, 这并非是CallExpression 节点返回值的样式,而属于上一种 MemberExpression 型节点,
但是如果将图示的区域,包裹在一个函数定义节点里,就会形成1,2的实际情形,所以下面的代码,依然考虑到了这样的情形.
对于3和4是类似的,都是由中间的符号和左右的标识组成,只要将调用时的第一个参数替换到符号的左边,第二个参数替换到符号的右边,然后将整个节点替换掉就可以。
对于5,我这里的做法是 同时提取形参名和实参节点,以调用对象时传参的顺序为标准,构建临时字典dict = {'形参名': 实参节点, ... },
在替换return语句中的形参时,以此字典为标准,进行替换,这样不必在意return语句中的参数,与形参是否位置上对应.
这一步代码:
# 对象调用还原
def obj_property_reload(node):
if type(node) == list:
for item in node:
obj_property_reload(item)
return
elif type(node) != dict:
return
# 捕获一个属性调用节点
if node['type'] == 'MemberExpression':
try:
obj_name = node['object']['name']
obj_property = node['property']['value']
new_node = obj_property_dict[obj_name][obj_property]
if new_node['type'] != 'FunctionExpression':
# 属性值不是一个函数定义节点,就直接替换
node.clear()
node.update(new_node)
obj_property_reload(node)
except KeyError:
pass
try:
# 捕获一个函数调用节点,且子节点callee的类型是一个MemberExpression
if node['type'] != 'CallExpression' or node['callee']['type'] != 'MemberExpression':
raise KeyError
obj_name = node['callee']['object']['name'] # 获取对象名称
obj_property_name = node['callee']['property']['value'] # 获取需要调用的对象属性名称
function_node = obj_property_dict[obj_name][obj_property_name] # 获取函数定义节点,即对象的属性值(该属性值是一个函数定义)
except KeyError:
for key in node.keys():
obj_property_reload(node[key])
return
# 获取形参
param_list = [item['name'] for item in function_node['params']]
# 获取实参
argument_list = node['arguments']
# 形成 形参与实参的对应关系,如此,可以适应形参位置发生变化
param_argument_dict = dict(zip(param_list, argument_list))
# 拷贝一份函数节点的返回值子节点
return_node = copy.deepcopy(function_node['body']['body'][0])
if return_node['type'] != 'ReturnStatement':
print(f'意料之外的函数节点,拥有超过一行的函数体: {function_node}')
sys.exit()
# 使用实参替换返回值节点中的形参,然后用返回值节点,替换掉整个函数调用node节点
if return_node['argument']['type'] == 'Literal' or return_node['argument']['type'] == 'MemberExpression':
# 这里所对应的其实也不是1,2点情况,而是把1,2点的区域包裹在一个函数中的情形
# 直接替换
node.clear()
node.update(return_node['argument'])
elif return_node['argument']['type'] == 'BinaryExpression' or return_node['argument'][
'type'] == 'LogicalExpression':
# 对应3,4点情况
if return_node['argument']['left']['type'] == 'Identifier':
return_node['argument']['left'] = param_argument_dict[return_node['argument']['left']['name']]
if return_node['argument']['right']['type'] == 'Identifier':
return_node['argument']['right'] = param_argument_dict[return_node['argument']['right']['name']]
node.clear()
node.update(return_node['argument'])
elif return_node['argument']['type'] == 'CallExpression':
# 对应第5点情况
if return_node['argument']['callee']['type'] != 'MemberExpression':
function_name = return_node['argument']['callee']['name']
if function_name in param_argument_dict:
return_node['argument']['callee'] = param_argument_dict[function_name]
for i in range(len(return_node['argument']['arguments'])):
if return_node['argument']['arguments'][i]['type'] == 'Identifier':
argument_name = return_node['argument']['arguments'][i]['name']
return_node['argument']['arguments'][i] = param_argument_dict[argument_name]
node.clear()
node.update(return_node['argument'])
else:
print(f'意料之外的函数返回值类型: {return_node}')
sys.exit()
# 替换完成后,将自身继续递归以免漏网之鱼
obj_property_reload(node)
return
if __name__ == '__main__':
# 生成基础文件
...
""" 字符串与数字回填[ok] """
...
""" 函数调用还原[ok] """
...
""" 对象调用还原[ok] """
# 拼接字符串
...
# 获取对象属性字典
...
# 对象调用还原
obj_property_reload(data)
with open('02_ob_obj_property_reload.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data))
os.system('node JsonToJs 02_ob_obj_property_reload.json 02_ob_obj_property_reload.js')
最后生成了 02_ob_obj_property_reload.js
至此,对象调用还原步骤完成
我们将
if (_0x5500bb['qsLgw'](_0x5500bb['RmLGP'], _0x5500bb['RmLGP']))
还原成了
if ('QcUHF' !== 'QcUHF')
附件: 第三步整体代码
# test.py
""" 对象调用还原 """
# 将拆分开的对象属性名称合并
def concat_obj_property_name(node):
if type(node) == list:
for item in node:
concat_obj_property_name(item)
return
elif type(node) != dict:
return
# 捕获一个二元运算节点
if node['type'] == 'BinaryExpression':
if not (node['left']['type'] == 'Literal' and node['right']['type'] == 'Literal'):
# 如果 其中有参数不是 字符 类型,则将两个参数都继续递归
concat_obj_property_name(node['left'])
concat_obj_property_name(node['right'])
# 当两个参数的递归都完成, 参数类型最终都变为了 字符 类型,则可以合并,这样就实现了一连串的字符相加
if node['left']['type'] == 'Literal' and node['right']['type'] == 'Literal':
new_node = {'type': 'Literal', 'value': node['left']['value'] + node['right']['value']}
node.clear()
node.update(new_node)
return
for key in node.keys():
concat_obj_property_name(node[key])
# 构造对象属性字典
obj_property_dict = {}
obj_name_list = []
def get_property_dicet(node):
# 所有对象申明时都是: XXXX = {}, 然后使用 XXXX['xxxx'] = XXXXXXX 来添加属性
if type(node) == list:
for item in node:
get_property_dicet(item)
return
elif type(node) != dict:
return
# 捕获一个表达式序列
if node['type'] == 'SequenceExpression':
for i in range(- len(node['expressions']), 0, 1): # 正向遍历列表,并且可以删除元素的方式
item = node['expressions'][i]
# 捕获一个(变量/属性)申明节点
if item['type'] == 'AssignmentExpression':
# 是一个变量申明
if item['left']['type'] == 'Identifier':
# 申明的是一个空对象
if item['right']['type'] == 'ObjectExpression' and item['right']['properties'] == []:
obj_property_dict[item['left']['name']] = {}
obj_name_list.append(item['left']['name'])
del node['expressions'][i]
continue
# 申明 一个变量指向另一个变量 例: _0x5500bb = _0x434ddb,
elif item['right']['type'] == 'Identifier':
if item['right']['name'] in obj_property_dict:
obj_property_dict[item['left']['name']] = obj_property_dict[item['right']['name']]
obj_name_list.append(item['left']['name'])
del node['expressions'][i]
continue
# 是一个属性申明
elif item['left']['type'] == 'MemberExpression':
obj_name = item['left']['object']['name']
try:
obj_property_name = item['left']['property']['value']
obj_property_dict[obj_name][obj_property_name] = item['right']
del node['expressions'][i]
continue
except KeyError:
pass
for key in item.keys():
get_property_dicet(item[key])
for key in node.keys():
get_property_dicet(node[key])
# 对象调用还原
def obj_property_reload(node):
if type(node) == list:
for item in node:
obj_property_reload(item)
return
elif type(node) != dict:
return
# 捕获一个属性调用节点
if node['type'] == 'MemberExpression':
try:
obj_name = node['object']['name']
obj_property = node['property']['value']
new_node = obj_property_dict[obj_name][obj_property]
if new_node['type'] != 'FunctionExpression':
node.clear()
node.update(new_node)
obj_property_reload(node)
except KeyError:
pass
try:
# 捕获一个函数调用节点,且子节点callee的类型是一个MemberExpression
if node['type'] != 'CallExpression' or node['callee']['type'] != 'MemberExpression':
raise KeyError
obj_name = node['callee']['object']['name'] # 获取对象名称
obj_property_name = node['callee']['property']['value'] # 获取需要调用的对象属性名称
function_node = obj_property_dict[obj_name][obj_property_name] # 获取函数定义节点,即对象的属性值(该属性值是一个函数定义)
except KeyError:
for key in node.keys():
obj_property_reload(node[key])
return
# 获取形参
param_list = [item['name'] for item in function_node['params']]
# 获取实参
argument_list = node['arguments']
# 形成形参与实参的对比关系,如此,可以适应形参位置发生变化
param_argument_dict = dict(zip(param_list, argument_list))
# 拷贝一份函数节点的返回值子节点
return_node = copy.deepcopy(function_node['body']['body'][0])
if return_node['type'] != 'ReturnStatement':
print(f'意料之外的函数节点,拥有超过一行的函数体: {function_node}')
sys.exit()
# 使用实参替换返回值节点中的形参,然后用返回值节点,替换掉整个函数调用node节点
if return_node['argument']['type'] == 'Literal' or return_node['argument']['type'] == 'MemberExpression':
# 直接替换
node.clear()
node.update(return_node['argument'])
elif return_node['argument']['type'] == 'BinaryExpression' or return_node['argument'][
'type'] == 'LogicalExpression':
if return_node['argument']['left']['type'] == 'Identifier':
return_node['argument']['left'] = param_argument_dict[return_node['argument']['left']['name']]
if return_node['argument']['right']['type'] == 'Identifier':
return_node['argument']['right'] = param_argument_dict[return_node['argument']['right']['name']]
node.clear()
node.update(return_node['argument'])
elif return_node['argument']['type'] == 'CallExpression':
if return_node['argument']['callee']['type'] != 'MemberExpression':
function_name = return_node['argument']['callee']['name']
if function_name in param_argument_dict:
return_node['argument']['callee'] = param_argument_dict[function_name]
for i in range(len(return_node['argument']['arguments'])):
if return_node['argument']['arguments'][i]['type'] == 'Identifier':
argument_name = return_node['argument']['arguments'][i]['name']
return_node['argument']['arguments'][i] = param_argument_dict[argument_name]
node.clear()
node.update(return_node['argument'])
else:
print(f'意料之外的函数返回值类型: {return_node}')
sys.exit()
# 替换完成后,将自身继续递归
obj_property_reload(node)
return
""" ********************************************************* """
if __name__ == '__main__':
# 生成基础文件
...
""" 字符串与数字回填[ok] """
...
""" 函数调用还原[ok] """
...
""" 对象调用还原[ok] """
with open('02_ob_call_function_reload.json', 'r', encoding='utf8') as f:
data = json.loads(f.read())
concat_obj_property_name(data)
with open('02_ob_concat_str.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data))
os.system('node JsonToJs 02_ob_concat_str.json 02_ob_concat_str.js')
get_property_dicet(data)
with open('02_ob_del_obj_property.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data))
os.system('node JsonToJs 02_ob_del_obj_property.json 02_ob_del_obj_property.js')
# 验证对象名称是否有重复,如果有,就只能将JS分成单个部分传入还原
# print(len(obj_property_dict))
# print(len(obj_name_list))
obj_property_reload(data)
with open('02_ob_obj_property_reload.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data))
os.system('node JsonToJs 02_ob_obj_property_reload.json 02_ob_obj_property_reload.js')
