TCP原理,Socket与网络编程入门
TCP原理,Socket与网络编程入门
开篇
从互联网的诞生以来,网络程序逐渐普及。计算机网络将各个计算机连接到一起使它们可以通信。在现代,网络已成为我们十分重要的一部分。这次不搞些费脑子的东西,就让我们用最通俗的方法理解【Socket与网络编程】我们首先应该要了解一些基本的概念…然后从原理开始下手到实践,到跨入网络编程的门槛。
顺便一提,文章内容可能会出现很多各种各样的缩写,或者是名称,各种各样的状态名,标志位什么的,这玩意实在是令人很烦躁,以我纯爱好学习这些东西的角度来看,我觉得比起浪费时间在背下它们的名称和对应的概念,我们更应该着重于理解,你能理解这些内容才是最重要的。
通俗的【网络体系】和一些概念
我们上学的时候都有计算机课吧,多少都有提到网络、TCP什么的吧,我的印象是从初一就开始有了,无论如何我们先来快速过一遍这些上学时的基础知识。
网络编程即是计算机之间交互数据的编程。通过网络交互数据是一项复杂的操作,一个数据从一台主机发到另一台主机,这个过程由计算机网络通信来完成。
网络通信因不同的方面被分成不同的层,它们之间通过接口对接。层次实现的功能由协议数据单元(Protocol Data Unit)来描述,通信的双方通过一样的层次进行通信。
OSI模型与TCP/IP四层模型
开放式互联OSI(Open System Interconnect)是对Internet工作方式描述的模型,将从Internet数据发送所涉及的功能分类为七层,每一层功能分明。
TCP/IP 模型是另一种Internet工作方式模型。它将流程分为四层。相比TCP/IP四层模型,人们在理解Internet时更多会参考OSI模型。但是,两者并没有绝对的好坏之分。
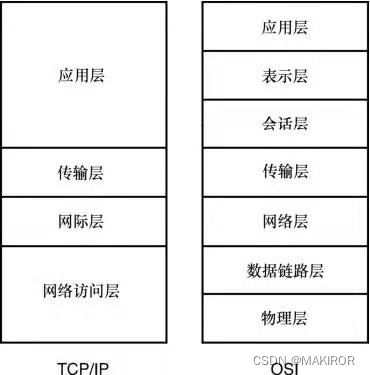
层与协议(protocol)
前面提到,模型将从Internet数据发送所涉及的功能分为数层,而它们为了实现某种功能,就必须有它们之间的规则存在,这种“规则”则叫做协议。
TCP,UDP
传输控制协议TCP(Transmission Control Protocol),用户数据报协议UDP(User Data Protocol)都属于TCP/IP协议簇,位于传输层。这两个协议对于今天的内容很重要。
TCP是面向连接的协议,必须经过三次“握手”,建立可靠的连接后才能开始传输数据,通过四次“挥手”断开连接;而UDP是面向无连接的协议,无需连接,发送端可直接发送数据,而接收端直接读取。从安全上来说,TCP拥有UDP所没有的拥塞控制、流量控制、重传机制、滑动窗口等,相比UDP更加安全可靠,但是TCP只能进行双向的通信,而UDP可以各种一对一一对多多对一多对多…再,很显然,相对于TCP,UDP的方式更有效率。这篇文章我们相对而言会着重TCP更多。
TCP详解
TCP的一些要点
可能多少有点啰嗦和与前面的重复,但在详细解释以前还是应该提及一下TCP的特点。
- TCP是面向连接的协议,进行数据传输前必须建立连接,完成后要释放连接。
- TCP要求连接是可靠的,因此连接需要三次握手来建立,完成后有四次挥手来断开连接,这样的机制虽然会占更多资源,但是都是为了【可靠】
- TCP仅支持双向传输
MTU和MSS
最大传输单元
我们来分开解释。
MTU(Maximum Transmission Unit),中文是最大传输单元,数据链路层传输的帧大小是有限制的,MTU是协议用来定义最大长度的,它被应用于OSI模型的数据链路层(由下往上第二层)。MTU限制了数据链路层可以传输的数据包的大小,同时也限制了更上一层(网络层)的数据包大小。我们以普遍的以太网接口为例,以太网MTU通常被设置为1500,是以太网接口对IP层的约束。如果在这种情况下IP层需要发送一个东西<=1500byte(包括IP协议头),那就可以只用一个IP包直接完成这个发送任务。如果这个数据>1500byte,则需要分片完成发送。
IP数据分片
前面提到,当数据超过MTU时,就需要将数据分片来完成发送。IP首部中有一个字段叫做【片偏移】,用来表示数据报在原来分组的相对位置,以8字节为一个单位。
我们以MTU为1500来举例。整个报文封装后有2020Byte。因为超过了1500Byte所以要进行分片处理。总共分为两片:
第一片:IP报文头固定占了20Byte,则数据载荷封装了1480Byte。另外,数据载荷的数字必须是8的倍数。
第二片:复制第一片占有20Byte的IP报文头,则数据载荷是520Byte。
当最后一片数据报文的长度不足46Byte时,会将它自动填充为46Byte。这些分片报文到达目标主机后会被重组,还原出完整的报文。而重组时会通过【IP标志位】的MF来判定这个分片是否是最后一个分片。
最大分节大小
MSS(Maximum Segment Size)最大分节大小,它相当于将MTU去掉IP头和TCP头后,剩余的大小。MSS限制了应用层最大的发送字节数量。MSS=MTU - IP Hrader - TCP Header。虽然通常情况下TCP头什么的是20Byte,但不能排除有些时候的一些其他可选项会额外占用了MSS的空间,如果你想知道具体的信息可以通过抓包软件来观察。另外,我们正在说的是TCP,UDP是没有MSS概念的,也就是传输层有可能会将数据一股脑的扔给网络层,然后数据被分片影响性能。
TCP头部
TCP提供的是一种面向连接的, 可靠的字节流服务,TCP提供可靠性的一种重要的方式就是MSS。 通过MSS,应用数据被分割成TCP认为最适合发送的数据块,由TCP传递给IP的信息单位称为报文段或段(segment)。
TCP首部有20个字节的固定首部部分和长度可变的其他选项。
TCP头部有16位端口号,进行通信时客户端通常会优先使用系统自动的临时端口号,服务器则使用对应服务的端口号。
32位序号,一次TCP通信全程中某个传输方向字节流的,每个字节的编号。
32位确认号,是对对方发送TCP报文的响应,值为收到的,TCP报文段的序号值+1
主机A和主机B要进行一次TCP通信,传输方向为A->B
A发给B的一个TCP报文段中,序号值被系统初始化为一个随机初始序号值(Initial Sequence Number)简称ISN。
那么在上述情况中,在后续的TCP报文段中序号值是被系统设置的ISN加报文段数据,第一个字节在整个字节流中的偏移。这很简单,若第一个字节为n,则报文段的序号值是 ISN + n。
- 源端口和目标端口:各占2字节,分别写入了源端口号和目的端口号。
- 序号:占4字节,序号的范围是[0, 232 - 1],在TCP连接时每一个字节流的每个字节都有编号(按照顺序)。
- 确认号:占4字节,是期望收到目标下一个报文段的,第一个数据字节的序号,表示序号n-1为止的数据以正确且完整的收到。
- 数据偏移:占4位,指出TCP报文段的数据起始处距离TCP报文段的出发点距离。
六位标志位分别是:
- URG: 表示紧急指针有效是否(Urgent Pointer)
- ACK: 表示确认号是否有效,包含ACK标志的TCP报文段被称为确认报文段
- PSH: 提示接收端应立即从缓冲区读数据来为后续的数据让出空间
- RST: 要求对方重新连接,包含RST的TCP报文段会被称为复位报文段
- SYN: 表示请求与对方建立一个连接,包含SYN的TCP报文段被称为同步报文段
- FIN: 告知对方本端将要关闭连接,包含FIN的TCP报文段被称为结束报文段
(图片来源于网络)

TCP三次握手
TCP建立连接需要通过三次握手(Three-Way Handshake),简单的说就是两个端要发送三个包确认连接的建立。Socket将TCP握手的具体操作抽象化了,这些我们往后会讲,先让我们知道TCP三次握手的步骤。我们这里的例子,A端向B端发起连接,A端和B端是客户端和服务器的关系。
- 第一次握手:A端向B端发送一个带有SYN标志的包,并且包含A端连接到B端的端口,初始序号,序列号等信息。
- 第二次握手:B端向A端发送ACK包应答,SYN和ACK标志位均为1,B端将确认序号设置为A端的ISN+1,完成发送后B端进入SYN_RCVD状态
- 第三次握手:A端再次发送ACK确认包,将B端的ACK序号字段+1,放在确定字段发给B端,ACK标志位为1,但是SYN标志位为0。
发送过程完成后,A端和B端都进入ESTABLISHED,TCP三次握手结束。
TCP四次挥手
TCP结束连接需要发送四个包,客户端和服务端都可以主动发起挥手,这个过程叫做四次挥手(Four-way handshake)。我们继续用上一段的AB端来表示,并且是A端主动发起挥手。
- 第一次挥手:A端向B端发送一个FIN标志位=1的包,发送后A端进入FIN_WAIT_1状态。此时的它在告诉B端,它已经没有数据要发送了,但是B端仍然可以向他发送数据,A端仍然可以接收数据。
- 第二次挥手:B端向A端发送一个确认包,ACK标志位=1,发送后B端进入CLOSE_WAIT状态,A端收到这个包后进入FIN_WAIT_2状态。B端已经知道并接受A端关闭连接的请求,但它并没有准备好,A端此时正在等待它关闭连接。
- 第三次挥手:B端已经准备好关闭连接了,然后向A端发送一个FIN标志位=1的包。发送完毕后B端将进入LAST_ACK状态,等待A端发来最后一个ACK。
- 第四次挥手:A端接收这个包后发送一个ACK标志位为1的确认包,进入TIME_WAIT状态,等待可能要求重新传输的ACK包。B端接收到后会关闭连接,进入CLOSED状态。当A端等待了超过2MSL(Maximum Segment Lifetime)的时间以后还没有接收到重传的ACK包,则会判定B端正常断链,A端也进入CLOSED状态。
TCP KeepAlive 探测包
首先,我们得清楚,建立TCP连接没有涉及到物理层面,仅仅是软件层面的概念。即便它们建立连接,数据交互也不是持续的,有些时候会在数据交互完成后立即释放连接,有一些不释放的,又长时间不交互数据的连接,两个端无法得知另一个端的紧急情况,例如关机死机断电。从软件层来看,它们两个又不交互又不释放,不知道对面的情况还得维护这个连接会相当浪费资源,一段时间后就会造成很多半打开的连接。在传输层我们可以使用TCP KeepAlive机制来解决这个问题,并且主流操作系统基本都支持这个特性,可谓是十分甚至九分的不错。
KeepAlive机制并不难理解,其实就是隔一段时间就给另一个端发一个包,若收到了对面回应的ACK包则判定连接存活,超过一定重试的次数,但没有收到回应时就会自动判定为连接没存活了,则自动放弃这个连接。这个模式又称【心跳】,它不仅限于这里,TCP KeepAlive仅仅是在内核层级来检测连接是否存活,此类【心跳】机制也可以在应用层来实现,并不是什么复杂的东西。我们常用的通信软件,例如Wechat和Discord都有这种机制。
安全问题
SYN洪泛攻击
前面提到,在三次握手的过程中,服务端发送SYN-ACK后,在得到客户端ACK确认包之前会处于SYN_RCVD状态,收到后则会转为ESTABLISHED 状态。
SYN攻击属于一种典型的DDOS攻击,发起攻击的客户端会中1短时间内伪造巨量不存在的IP,不断向服务端发SYN包,服务端回复确认包并开始等待客户端确认时,因为IP地址根本不存在,所以服务端就会不断地重发,直到超时为止。这些伪造的SYN包长时间占用队列,使得正常的SYN请求可能会被丢弃,导致网络堵塞甚至系统瘫痪。可怕的是,这种攻击实现的难度相当低,小学生也能搞的等级。
你可以轻而易举的发现服务器遭受SYN洪泛攻击,当你某一天看到服务器有巨量的半连接状态,并且源IP地址是随机的(尤其要注意这个)有很大概率就是此类攻击。我们当然有办法来防范,但是,安全永远都不是绝对的,或许以下措施可以一定程度上减少SYN攻击的可能,或者是遭受攻击的影响:
- 缩短SYN Timeout时间
- 过滤网关防护
- 增加最大的半连接数
我们了解这些东西的价值在于理解和防范,而不是用来做什么坏事,总有些急于表达自己的人想通过恶意攻击些什么来显得自己的能力,这一点也不酷。
“DDOS涉嫌破坏计算机信息系统罪,违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的,处五年以上有期徒刑。”
----来自百度百科
TCP重置攻击
攻击者通过向通信的一方或者双方伪造消息来使得连接中断,一般情况下客户端发现报文段不正确,就会发送一个重置报文段,导致TCP连接被拆卸。如果伪造的重置报文长的很逼真,那接收端就会认为它是有效的,并且关闭TCP连接防止继续交换信息,即便服务端再创建一个TCP连接尝试恢复通信,也有可能再次被重置连接。这种攻击方式一般对于长连接更有效,短时间内交换完数据并解除的连接相对而言风险会小很多。
MITM攻击理论
MITM攻击(Man-in-the-MiddleAttack),也可以叫做中间人攻击。攻击者则是【中间人】角色,我想听这个名字,大家也猜到是什么了吧。常见的MITM攻击有
- SMB会话劫持
- DNS欺骗
- HTTPS假证书
- ARP欺骗
一般情况下就是攻击者拦截正常的通信数据,在正常通信的双方不知情的情况下篡改或者嗅探。具体的实现我觉得不应该在这里浪费篇幅讲的,没那么多时间给我讲网络安全。
超时重传
Fast retransmit and recovery
TCP中有一种拥塞控制算法,快速重传与恢复(Fast retransmit and recovery )或缩写FRR【FRR另外和生物安全系统术语false rejection rate的缩写相同,别搞混了】。如名字的意思,它能快速地恢复丢失的数据包,如果接收端收到了一个不按顺序的数据段,会立刻给发送端一个重复确认,如果发送端收到了三个这样的重复确认则会判定数据丢失,并重新传输丢失的数据段。这样的机制在单个数据包丢失时优势是最显著的,但是一堆数据包同时丢失的话它的优势则不会那么明显。这种算法的特征在于是接受端主动告诉发送端。
被动等待的超时重传
这只是一种策略的类型,相比上一个Fast retransmit and recovery,被动等待的超市重传不同在于接收端并不会主动的发送重复确认,而是就这么等待发送端意识到不对然后重传。这除了等待超时浪费时间以外,发送端还不知道该重发哪个,就干脆都重发一遍,浪费宽带又浪费时间,TCP并没有采用这种方法。
SACK选项
SACK(selective acknowledgment)是TCP包头的两个选项,分别是开启选项(enabling option)和SACK选项(sack option)。开启选项负责制建立连接时通过SYN告诉对端之间是否支持SACK,而开启SACK选项后,接收端向发送端发送端ACK包会在SACK Option字段中携带一些确认信息,例如收到了一些什么包,没收到什么。
在早期的TCP拥塞控制中,采用的是FRR算法,前面有提到它在同时一堆数据包丢失的时候会失去很多优势,因为它每次只能重传一个包,在等待的过程中有可能会造成Timeout或者带宽利用率下降。Sack记录的是一个连续的包,则可以通过Sack段之间的断片来判断多个已经丢失的包,以便一次性重传。另外,如果丢包是因为网络本身已经非常拥塞的情况下不建议使用SACK选项,因为一次性重传多个包在网络本来就拥塞的情况下,只会弊大于利。
Socket套接字
Socket原意为【插座】,被翻译为【套接字】。Socket提供了tco/ip协议的接口(抽象),使开发者可以无需关注协议的细节,更方便的进行网络编程。网络通信不过是不同的主机某个应用程序进程之间的的交互,除了使用HTTP这样的应用层协议来包装数据外,也可以使用Socket直接在传输层通信。毕竟只是一个抽象,已经了解了TCP工作的你很容易就能理解。
建立连接
通过Socket建立通信的连接至少需要一对套接字,服务端和客户端各一个。建立一个连接很简单,服务器在监听状态时,客户端请求连接,服务器允许连接。
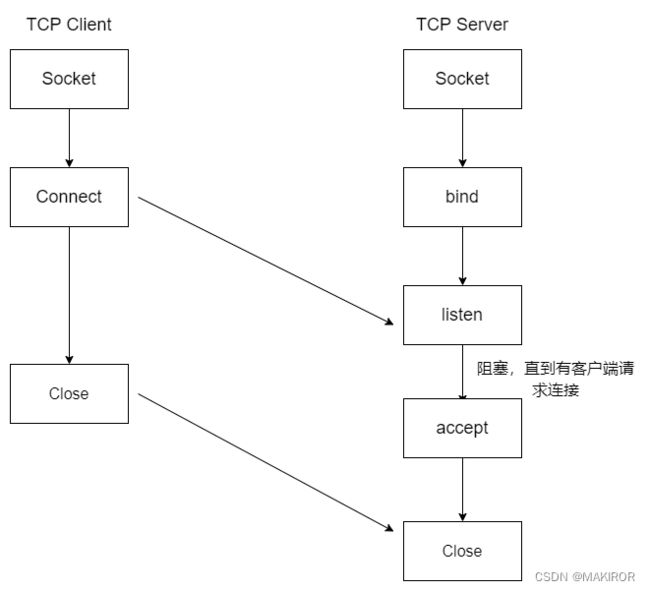
图例中服务端阻塞并开始监听,收到了客户端的连接请求并接受(accept),完成连接后再关闭连接(不含读写操作)。
网络中进程间的通信
如果你有阅读我的上一篇文章《你好,Linux内核架构和原理》,你一定记得里面有提到“进程间通信”,上次因为篇幅有限就没有扯太多,其实我们这里要提到的【网络中进程间通信】也是有地方一样的,首先我们得知道本地进程间通信的方式有很大,但都可以归类为这几类:
- 消息传递(Pipe,FIFO,消息队列)
- 同步(读写锁,信号量,互斥量,条件变量)
- 共享内存
- 远程的过程调用
本地通过PID来唯一标记进程,但是网络不可以,在网络层中我们使用IP地址来标记唯一网络中的主机,传输层的协议+端口来标记是主机中唯一的应用程序进程,三个东西(IP地址,协议,端口)就能标记唯一的网络进程来,网络的进程通信就是通过这个标志来和其他进程交互。
Socket基本的函数
我不喜欢把每一个函数详细的一一列出来告诉你它在干嘛,这很繁琐,林北又不是在写文档,但是为了更好的了解Socket操作,我在这里会比较详细的说几个常用的函数。
Socket()函数
Socket()函数用于创建一个socket描述符,一个socket描述符则对应一个唯一的socket,就像文件描述字一样,后面的操作会经常用到它。
int socket(int domain, int type, int protocol);
来让我们看看它的参数
- domain:协议族,它决定了Socket地址类型,在通信中采用对应的地址,就例如AF_INET决定了使用IPV4地址,16位的端口号组合。常见的协议族有AF_INET、AF_UNIX、AF_INET6等
- type:Socket的类型,例如Sock_stream是面向连接的Socket连接(也就是TCP的),Sock_dgram是无保障的面向消息Socket(UDP)
- protocol:协议,例如TCP,UDP,STCP,STPC等,但是它不能和type任意组合,你得根据实际情况选择。你也可以protocol为0,则会自动根据你的type选择对应的,默认的protocol
bind()函数
就是将地址族中的特定地址赋给Socket,例如赋Socket一个IPV4地址和端口号组合。
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- sockfd:Socket描述字,也就是上面通过socket()函数创建的东西。
- addr:指向绑定到Sockfd的协议地址,它的结构取决于Socket的地址协议族
- addrlen:地址的长度
listen()和connect()
服务端在bind后就会调用listen()来监听socket,客户端可以通过connect()向服务端发送请求
int listen(int sockfd, int backlog);
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
listen:
- sockfd:Socket描述字
- backlog:对应Socket的,最大连接数
connect:
- sockfd:客户端的socket描述字
- addr:服务器地址
- addrlen:地址的长度
accept()函数
服务端在收到连接后可以通过accept来接收请求,这样就能建立好连接了。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
- sockfd:Socket描述字
accept的返回值是对应客户端的,已连接的Socket描述字
最后
已经是国庆的最后一天了,我赶着将这篇文章草草收尾,主要都是提及网络编程的基础知识,并且是纯理论的。你可以通过阅读书籍来了解更多,那就这样,感谢你的阅读。