浅析分布式系统之体系结构 技术基本目标----一致性(单对象、单操作)
一致性的本质
一致性定义:逻辑层面,一致性(consistency)是指一個形式系統中不蕴含矛盾(wiki)。在计算机系统的范畴之内,一致性其实是一种人们对于系统的综合需求,人们往往需要计算机的运行结果或状态是确定的、正确的且与系统的需求不蕴含矛盾,而不蕴含矛盾本身是一种随着不同的系统环境以及业务需求而变化而变化的要求。也就是说,对所有的计算机系统来说,只要它们的运行状态或结果与某种业务需求所定义的状态或结果一致不矛盾都可以认为达到了满足了一致性需求。因此针对不同的业务需求以及不同分布式系统的「一致」的定义就会不同,例如:数据库的数据一致性定义为任何给定数据库交易必须仅以允许的方式更改受影响的数据的要求(在维基百科)其与分布式系统的数据一致性一般要求并不相同。
当不考虑业务需求而只考虑计算机系统本身非功能性需求范围之内,如果系统能实现任意单一对象的单一读操作都返回最近写操作的值(A Read returns the most recently value written),则代表了这个系统实现了在技术层面对于单一对象单一操作的的最强的一致性需求。满足这个最强一致性需求在单机器单CPU的情况下相对是最简单的,由于只有一个CPU,所有的读写操作都可以按照全局的时间顺序执行。在单机器多CPU的情况下,由于多CPU并发执行,并共用一个内存,孤儿需要较为复杂的内存模型来解决内存一致性问题(Memory Consistency)。分布式系统是由多CPU,多进程组成的系统,其故障、可用性、系统架构、通信模型等也比前述的系统更为复杂多变,这些因素的存在使分布式满足某些一致性需求而显得十分困难甚至不可能。因此,随着系统的使用对象、通信模型,故障类型、业务需求相关场景的不同,不同分布式系统需要实现的一致性要求有着各种不同的定义。
除此以外一致性还涉及计算机系统的动态运行的概念,随着系统的运行,系统的状态会不停变化的。一般将分布式系统、数据库系统以及其他现代计算机系统等同于某种有限状态机,可以认为只要系统的起始状态是「一致」的,并且每次操作都能满足相应的「一致性」需求,那么系统就能始终保持在「一致」的状态上 (Consistency Preservation)。正由于系统在运行是状态是不停的变化的,判断系统是否符合一致性需求则成为了一个静态概念。一般需要在某个时间点对于进行系统状态快照获得系统在某一时刻的状态信息,通过比对这一时刻的状态信息是否符合系统所需满足的一致性需求进行相应判断。
满足一致性需求对于分布式系统非常重要,当系统无法满足一致性,系统则会出现运行停止、脑裂、唯一值不唯一、系统行为出现随机错误与业务执行错误等种种问题,因此一致性是分布式系统的最基本核心问题之一。
一致性定义描述相关概念
历史记录(log):是对操作的记录的集合。
时间(Time):假设整体系统存在一个进程执行时无法访问的理想和全局物理实时时间(real time),并且用这个全局物理实时时间来推理系统中事件或操作发生的历史。
可见性 (visibility) :可见性一般指操作a产生的效果可以被操作b观察到这样的场景(例如:写操作b基于之前读取的写操作a写入的值,则操作b观察了操作a写入)。两个操作之间也会相互不可见,(例如,操作a以及操作b只写入各自的值,且操作b没有读取操作a写入的值,也就是操作b没有对外进行观察并基于观察的结果进行操作也就不会产生前后顺序)。
仲裁(arbitration):仲裁(arbitration)是操作的历史记录总顺序,它指定系统如何解决由于并发和不可见操作而导致的冲突(向某一个确定的值收敛是其中一种方式)。
抽象执行(Abstract executions):将系统的某一次操作的执行抽象为抽象执行(Abstract executions)。抽象执行的信息可以由这次执行的操作的记录集合、可见性以及仲裁(arbitration)组成的一张图进行描述。log历史记录描述了可观察的执行的结果,可见性 (visibility) 主要用捕捉(例如:客户端读写操作不必等副本数据同步完毕)下的非确定性(例如,消息传递顺序),仲裁(arbitration)则用于特殊情况下的处理应遵循的约束(例如,并发冲突解决策略)。
一致性模型读写操作抽象执行的描述:
ops = (write,procId, objId, value,(可选)startTime, (可选)endTime)
ops = (read,procId, objId, writeList, startTime, endTime)
procId:进行操作的进程的唯一标识
objId:进行操作的某个对象的唯一标识
value: 操作写入的值
writeList:读操作读取的值的list(允许读取操作返回多个结果,这里用这种方式处理多进程下的的并发更新,而不用对并发冲突解决给出限制性约束。)
startTime:操作开始时间(可选,假设系统有统一的时钟)
endTime:操作结束时间(可选,假设系统有统一的时钟)
例子: a进程对对象x进行的写(write)操作 (write,a, x, value, 10809920, 12809921)
非事务操作一致性与事务操作一致性:
非事务操作与事务操作涉及的一致性要求并不一致。这里主要对于单一对象的单一操作作为系统主要操作的一致性模型分类进行讨论。
单一对象的单一操作一致性模型分类:
分布式系统中的单操作操作一致随着不同场景而出现不同的定义。分布式系统从客户端以及分布式系统自身数据的角度,分为数据一致性和客户端一致性两大类。
在这两大类下又依据一致性视角,共享数据类型的不同:同步/异步,以及错误环境(拜占庭/非拜占庭等)分成了各个类型。
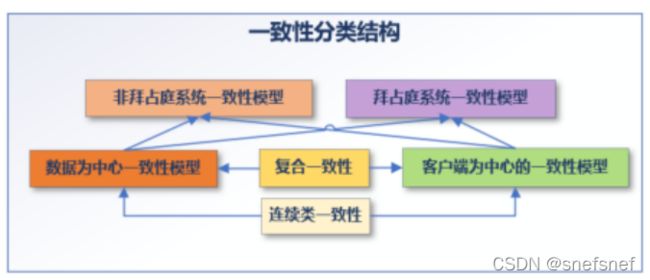
图1 非事务一致性主要分类
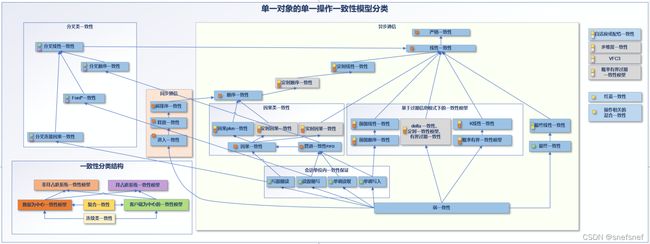
图2:非事务一致性模型的层次结构。 从一致性 A 到一致性 B 的箭头意味着符合一致性B 的系统必然也符合 A的一致性要求。 灰色方框是具有对于时间相关的顺序有限制的一类一致性。
非拜占庭系统下的一致性模型:
非拜占庭系统下能够实现的符合一致性模型定义的系统,这个系统会出现的错误局限于Crash Failure以及failure stop错误分类之中。如果系统采用异步通信,则假设系统里面的进程都不会失败(FLP)。
数据一致性模型(Data-Centric Consistency Models):
数据一致性是一种(分布式)数据存储和进程之间的约定。基于这个约定,数据共享存储系统(数据)会确实的保证:当客户端对于数据共享存储系统进行并发读取和写入操作时,数据共享存储系统返回的结果会符合某一类或几类数据一致性模型定义的要求。即:存在客户端并发读/写操作的情况下,设计一个符合某种数据一致性的(全局可访问的)数据共享存储系统应满足的基本需求。
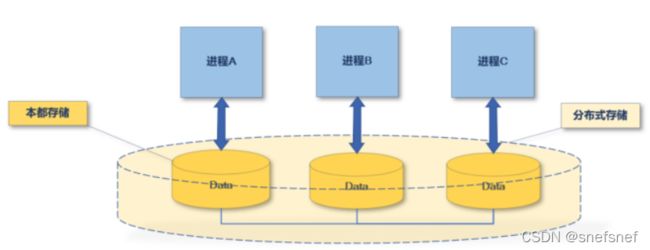
图3 分布式存储系统
在分布式数据储存的以及多进程的环境下,可以采用(操作)上下文,对于某个抽象执行(Abstract executions)中某个给定操作x基于可见性 (visibility)的信息进行描述。此外,我们采用复制数据类型的概念 [Burckhardt, 2014] 来定义在分布式系统中实现的共享对象(例如,读/写寄存器、计数器、设置、队列、等等)。对于每个复制的数据类型,可以通过某个函数 F 指定预期返回值的集合(F函数认为等同于符合某种仲裁(arbitration)约束的操作x最新的读取的写操作)
基于异步操作的一致性模型
假设这类一致性模型中的共享变量都是非同步共享变量(asynchronization variable),即共享变量的各个备份之间不使用同步操作进行信息同步。客户端各个进程的对于这个变量的读写操作也不是同步操作。
操作数据一致性模型由强到弱有多个种类针对不同的场景:
1. 严格一致性(Strict consistency)
描述:所有进程都必须可以立即读到任何进程对共享变量的写入。严格一致性能保证所有的读写操作都按照全局物理实时时钟下的顺序执行。例如:任一进程在实时的时间点t,对共享变量执行 x ≔ 1 并且这是最新的写操作,然后在统一时钟下的时刻 t‘且t ′> t,每个尝试读取 x 的进程都将能得到值 1
符合严格一致性写操作以及读操作记录示例如下:
(write,a, x, value1, t1, t1) start time=end time
(write,b, x, value2, t1, t1)
(read,c, x, list(value1,value2), t3, t3)
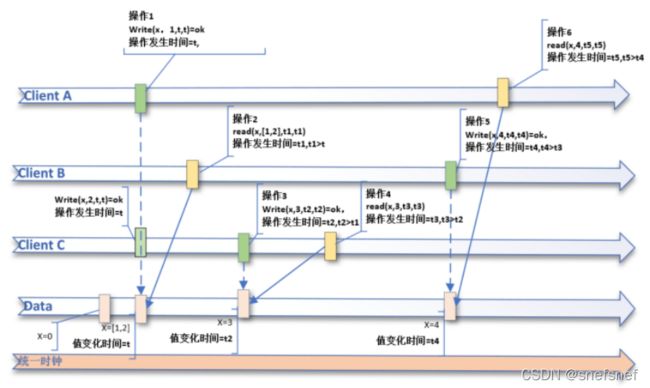
图4 严格一致性
模型限制条件:
1)整个系统的log遵循同一个高精度的统一的时钟(保证每个进程对于这个系统中的所有数据项的读写都是全序的基础)。
2)startTime=endTime,读写操作不花费时间,读写都是原子操作,
3)假设对于两个写操作并操作时,read操作可返回所有的读操作的列表list(value1,value2) (不定义仲裁(arbitration))。
4)信息传输,交换和更新时间不做考虑
5)共享变量多个副本默认可以认为严格的同时更新,假设所以操作所需时间为0,严格的一致性是对于共享变量的复制完全透明,可以认为共享变量就是单个copy无副本。
6)对于传输延迟等也均不做考虑。
我们可以将古老的无副本的单变量单处理器系统,可以作为一个符合这些假设的类似系统。这个模型是一个概念模型,不能给与多进程同时操作同一个变量要如何处理的解决方式。以上种种理想化的限制注定严格一致性只能是一个理论模型。
2. 线性一致性(Linearizability Consistency)
描述:严格一致性的定义要求太高了,通过对于严格一致性限制的某些方面进行有限度的妥协,提出了相对弱一些的线性一致性模型(Linearizability),线性一致性要求任何操作逻辑进程一个读操作必须得到最新的写的操作的结果,这和严格一致性相同,但基于对于执行时间方面进行了约束放宽。
线性一致性
模型限制条件:
1)系统基于统一时钟来确定对于某个共享变量的单个操作先后顺序,这个统一时钟可以基于逻辑时钟 。
2)消息传输的时间为实时传输,传输时间的延迟忽略不计。
3)对于这个系统的一个共享变量x,一个或多个进程可以并行执行读写操作,每一个读写操作都是原子的。对于系统会将共享变量的一系列读写操作以及操作发生的时间的记录下来作为这个变量的操作历史记录。
4)假设并发造成的写重叠会出现,软件开发者需要对于随机组合情况进行处理。
符合严格一致性写操作以及读操作记录示例如下:
(write,a, x, value1, t0, t1) 假设:变化发生在时间s, t0>t1
(write,b, x, value2, t2, t3) 假设:变化发生在时间s, t2>t3, t2>t0 and t1>t3
(read,c, x, list(value1,value2), t4, t5) 假设:变化发生在时间s1, t1>t4 and t5>t1
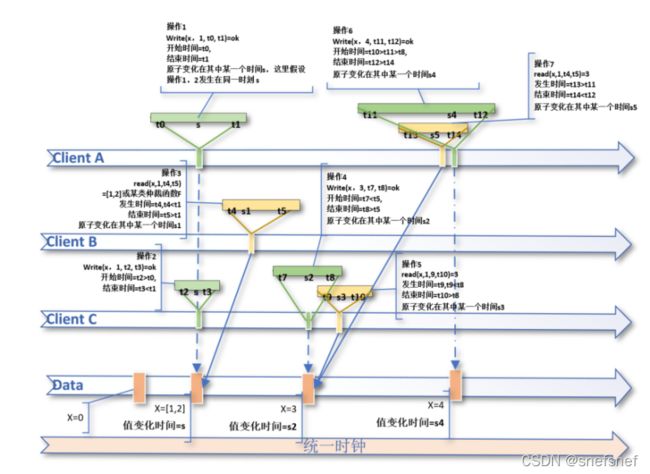 图5 线性一致性
图5 线性一致性
当这个系统中的任意多个逻辑进程clinetA,clientB,ClienC,ClienD 都基于统一的时钟对于对于同一个共享变量X进行了一系列顺序操作,由于是对于同一个共享变量X进行了一系列顺序,我们可以将所有对共享变量X的操作以及结果都基于统一时钟的timestamp 记录下来,如果将每个进程的自己对于共享变量x操作记录和所有进程对于共享变量x的操作记录组合起来,便能得到这个符合单一全序(基于时间timestamp)的顺序记录。此外,需要注意的地方是由于只需要任意进程在任何时间点的读操作的到结果都等于对于共享变量X这个读操作之前的最新的写操作的结果即符合线性一致性的要求,所以线性一致性的顺序记录可以不止一种(仲裁(arbitration)基于各个进程操作发生的时间点的唯一组合有随机性),线性一致性的定义仅排除重新排序使读写操作的响应出现于读写操作调用之前的情况;如果原初的读写操作调用顺序保证只包含读写操作调用之前没有读写操作响应的情况,则开发人员可以根据需要对顺序进行重新排序,前提是原始历史确实是线性一致性的。上图中的,Data上的历史记录可以由两种顺序(ClientA write,ClientC write,Client B read,ClientC write, ClientC read,ClientA read,ClientA write )或((或ClientC write,ClientA write ,Client B read,ClientC write, ClientC read,ClientA read,ClientA write)
3.顺序一致性 Sequential consistency
描述:顺序一致性模型也是由Lamport于1979年提出的。Lamport在这篇著名论文对于 顺序一致性定义为“如果任意执行的结果都与所有处理器的操作以某种顺序执行相同,并且每个单独处理器的操作的排序按照其程序指定的顺序进行。”则可以认为符合顺序一致性。可以将顺序一致性模型看作生活中常见的洗牌动作。假设人们在洗两幅牌的之前,左右手各持一副牌,此时每一副牌有自己顺序,(这个顺序就如同一个进程本地代码在处理器上的执行顺序)。当开始洗牌,两幅牌开始相互交织,(这就如同两个进程之间本地执行顺序相互交织的过程),当洗牌结束便得到一个统一的包含两副牌的顺序。这个顺序中左右两幅牌的顺序只是交织,对于单独一副牌来说它的顺序没有被破坏(进程来对于说本地代码执行顺序并没有被破坏),只是它的各个步骤当中插入了另外一个进程的本地代码步骤。洗牌可以多次,每一次洗牌相互交织组成的统一的顺序可以是不同的,但是对于每一副牌仍旧保持了自己的本地顺序也就是顺序一致性。同时对于所有参与牌局的人来说,洗牌完成后形成的顺序都是一致的,即所有的人看到的都是唯一的相同的交织的顺序。这个模型在顺序上的限制比线性一致性要弱(没有时间上的约束)。

图6 洗牌和顺序一致性
模型限制条件:
1)在顺序一致性定义中进程不必立即看到其他进程对变量的写入。
2)顺序一致性需要所有进程必须以相同的顺序看到不同进程对变量的写入,这就需要维持每个进程内的程序顺序和进程之间的操作一个统一顺序。为了维持进程之间的执行顺序,所有操作都必须相对于每个其他进程显的能够立即完成或原子地执行(洗牌的动作就是立即原子的完成)。在实际系统中发送信息不可能立即完成,所以这些操作只需要显得能够即刻完成即可。如果不能保证这一点,会破坏传输顺序的正确性,这样就不能保证各个进程接收到的本地代码执行顺序的正确, 从而破坏以此为基础的统一的顺序的正确性以及一致性。
例如,在一个使用单一全局共享总线的SOA系统中,一旦一条总线上发布了信息,就可以保证所有进程都会在同一时刻看到该信息。因此,将信息传递到总线就意味着对所有进程来说这个本地执行步骤已经完成了,或者看起来已经被执行了。如果某些进程所在的服务器包含缓存并没有把消息直接传送给相应的进程,从而导致这些进程和其他各个进程看到的某一个进程本地执行顺序并不相同,从而破坏了顺序一致性。
3)顺序一致性也不包含两个操作同时对一个数据进行操作的情况的定义(或者说(仲裁(arbitration)的逻辑处理留给了分布式软件开发者自行进行处理)),因此顺序一致性会产生不确定的结果,即在重复运行相同的分布式程序,各个进程之间的顺序操作的组合顺序会随着执行的次数出现随机不同。但是,每一次执行都会产生统一的对于所有参与这次顺序组合的进程来说是唯一的也是相同的组合顺序log。分布式软件开发者需要考虑这类情况并做出处理。
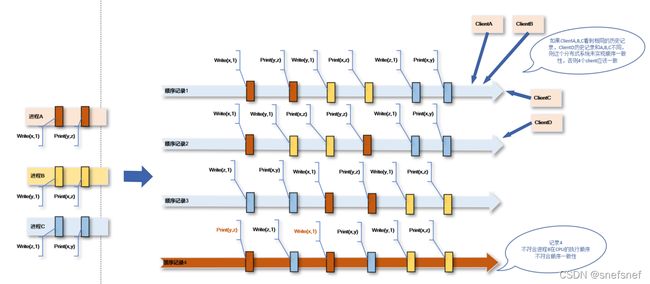
图7 顺序一致性有多种可能的组合
顺序一致性和线性一致性的比较:
两者都试图让分布式系统每一个进程如同单个处理器执行一样得到一个整个分布式系统层面的统一的全序。
两者都保证了程序的本地执行顺序不会被打乱。
线性一致性的全序基于整体系统的绝对统一实时时间的先后顺序,而顺序一致性没有基于实时时间的统一先后顺序,只有基于同一个进程发出的操作的实时时间进行排序的顺序被保存了下来,因此线性一致性可以看作顺序一致性的一个特例。
满足线性一致性的执行过程,肯定都满足顺序一致性;当对于操作顺序基于shi'j进行实时性约束,即当一个操作 OP1(x) 的发生时间t1小于另外一个操作 OP2(y)的发生时间 t2,则认为 OP1(x)必须在 OP2(y) 之前完成,那么就得到了线性一致性。
4.因果类一致性(causal consistency)
因果关系:因果关系记录基于Lamport对发生前关系(happens-before relation)的定义,因果关系蕴含了先后顺序。通过将某次操作与发生在前的操作按在同一过程内顺序进行(同一进程内操作a发生的时间startTime小于操作b的开始时间startTime,则认为依据发生前关系happens-before relation a操作在b之前发生)以及在其他过程发生的操作与这些进程之间的信息交换产生(不同进程之间的发生前关系happens-before relation)的影响进行关联得到相应的因果关系。简单来说,所谓因果相关可以认为假设一个分布式系统中某一个进程a对于某个共享变量X进行了写入操作,如果程序的定义了执行的这次写入操作之前需要读取进程a或其他进程(两次写入可以由同一个进程或不同的进程完成系)进行的最近的一次操作的写入操作写入的值,也就是说如果某一个进程对共享变量的一次写入依赖于对变量X的最近一次写入的值(需要认定发生前关系(happens-before relation)),则可以认为这两次写入可能成互为因果相关(等同于这几个操作在单个进程上进行)。
因果一致性(causal consistency)
描述:因果一致性定义了只有因果相关的写操作需要被所有进程以相同的顺序得到,即所有有因果关系的读写操作有一个统一的记录,而对于没有因果关系的各个操作,各个进程所得到顺序可以不同,即没有一个统一的各个进程之间都一致的顺序(全序)。除此以外,这种因果关系是可以传递的,即如果操作A和操作B有因果关系,而操作B和操作C有因果关系,则可以认为操作A和操作C也有因果关系。
符合因果关系的条件如下:
(1) 操作o1和操作o2属于同一个进程,且操作o1在操作o2前面执行(同进程内happen-before)。
(2) 操作o1是个写操作,操作o2是个读操作,且操作o2读到的值是由操作o1写入的(进程之间happen-before)。
(3) 存在一个操作o’满足o1→o’→o2(传递)。
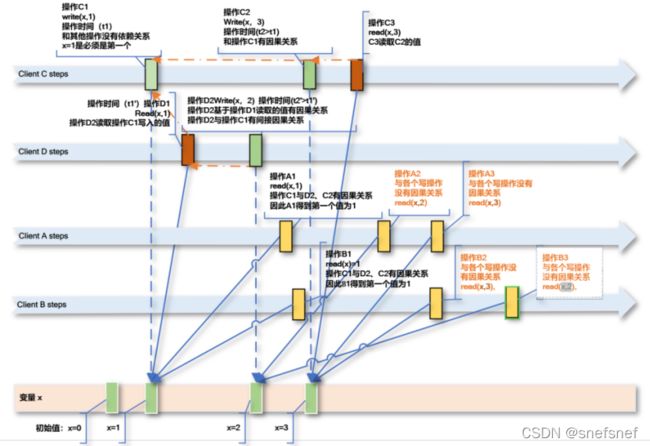
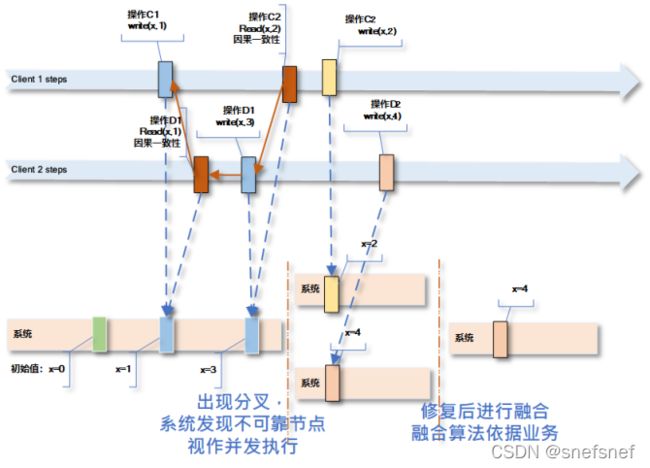
图8 A1读操作发生时,由于操作C1刚刚执行完毕,所以A1,B1操作只能读到相同的值x=1,其后的读操作A2 A3 与B2 B3 其他操作没有任何因果关系(A1、A2、A3之间没有写操作,ClineB同理),所以这些读操作得到结果可能有多种值组合。
模型限制条件:
1) 操作之间的因果关系基于操作之间的可见性 (visibility) ,符合happen-before关系是这类可见性 (visibility) 的子集。
2)任一进程的读操作需要反应最近的(包含并发)其他或自身进程写操作的内容即两者之间有因果相关,即如果写操作a将值写入后,最近发生的读取操作b得到了操作a写入的值则,认为a对b有因果关系。
3)对于没有因果关系的各个操作,由于没有全序因此会发生多种可能性。例如:图8中两个写操作(C2,D2),对于clientA和clientB来说会看到完全不同的结果,这是因为两者的参照系不同,因此观察者对于不同事件的先后顺序,可能产生不同的看法。实际上,分别站在clientA和clientB视角上,它们看到的都没有什么矛盾。而从系统本身总体则会发现顺序无法收敛。如果图8中的对于两个写操作(C2,D2)同时对于同一个共享变量进行写入操作(写重叠)的情景给出一个仲裁(arbitration)来裁定如何解决并发冲突,则产生了几类更强的因果关系,例如(实时因果一致性 (Real-time causal consistency,causal+)
实时因果一致性 (Real-time causal consistency)
描述:实时因果一致性在有因果关系的操作维持因果一致性基础上对于各个进程没有因果关系的操作之间的先后次序在时间维度增加了限制使各个操作的顺序成为全序顺序。通过增加系统唯一时钟,从而不允许各个操作的先后次序出现时间回溯,即任意两个操作之间,如果操作a的结束时间小于操作b的开始时间,则认为操作b不可能在操作a之前发生。
模型限制条件:
实时因果一致性 假设有一个绝对的global时间来保证时间无法回溯,不实时重叠的因果并发写入操作必须根据它们的实时顺序,同时实时因果一致性也不解决并发写冲突,而是通过一个读取操作得到多个值来回避冲突处理。
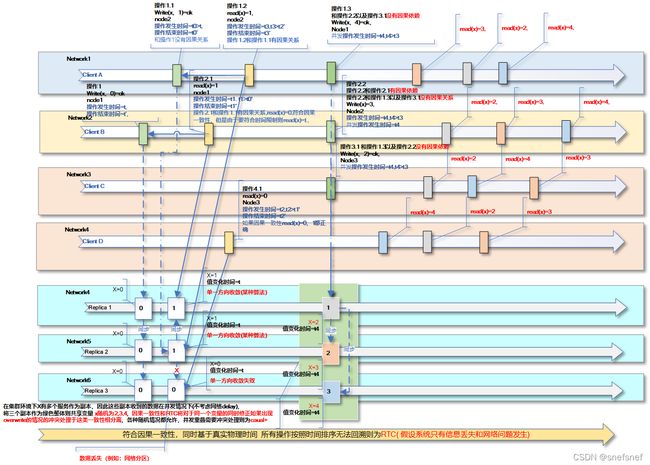 图9 各个网络中的各个client的除了有因果关系的操作按照因果一致性排序之外,其他操作顺序按照时间排序,操作4.1如果按照因果一致性则值可0或1,如果按照实时因果一致性则为0。当出现写入并发操作的情况,图中的写入操作1.3、2.2与3.1是并发写操作,由于实时因果一致性不包含仲裁,因此后续的读操作得到结果可能有多种值组合。
图9 各个网络中的各个client的除了有因果关系的操作按照因果一致性排序之外,其他操作顺序按照时间排序,操作4.1如果按照因果一致性则值可0或1,如果按照实时因果一致性则为0。当出现写入并发操作的情况,图中的写入操作1.3、2.2与3.1是并发写操作,由于实时因果一致性不包含仲裁,因此后续的读操作得到结果可能有多种值组合。
因果plus一致性(causal+ or convergent causal)
描述:因果plus一致性指在有因果关系的操作维持因果一致性的基础上,在集群环境中对于同时存在于多个数据副本的同一个变量进行更新时产生的冲突的进行强行收敛,即所有的副本都必须独立的最终同意某一个冲突解决方式。收敛冲突处理要求在所有副本上使用处理函数 h 以相同方式独立处理所有冲突。这个处理函数 h 必须符合结合律和交换律(一个副本h(a, h(b, c)) 等同于另外一个副本的 h(c, h(b, a)) )。一个常见的收敛方式最后 last-writer-wins。如此各个副本才能在得到冲突的写入操作次序的时候使用此函数将不同的次序种类进行收敛。
5.管道一致性FIFO (Pipelined RAM) 一致性
描述:FIFO (PRAM) 一致性由Lipton 以及 Sandberg 于1988提出,这个一致性需要保证的是各个进程观察得到的对于同一个进程对于同一个共享变量的多次操作的组成先后顺序一致,而对于不同进程对于的同一个共享变量的多次操作观察得到的先后顺序可以不同。
模型限制条件:
1) PRAM一致性和时间无关,也无需一个整体的包含所有进程操作的顺序。
2)这种一致性和因果一致性相比限制更低,性能也更好。其相关性只基于同一个进程操作之内,可以将每一个进程实例范围内的所有操作集合看作一个管道或一次会话,所以在这个管道或会话上的操作都必须有前后顺序。
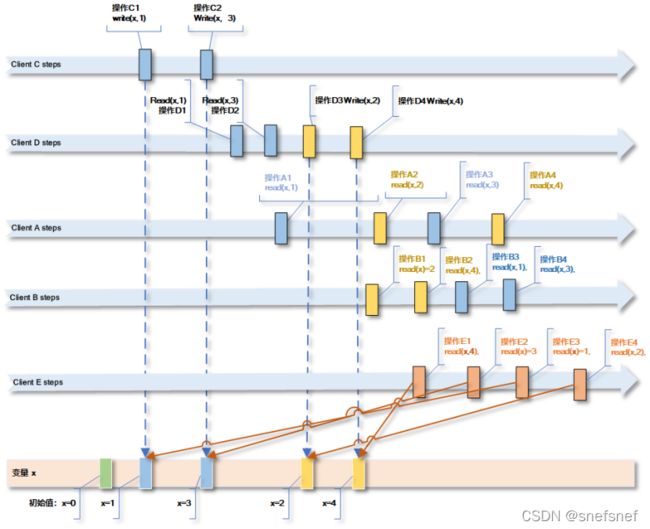
图10 图中clientE的不符合PRAM,读操作E1与E4的次序与ClintC,ClientD的写入次序矛盾
基于同步共享变量的一致性模型
同步变量:是用于协调基于异步事件的进程执行的同步原语,在分布式中其用在需要更新共享数据存储的所有副本的情景。
当一个同步变量被分配后,其可充当一个或多个进程可以阻塞的点,并对相关的进程进行阻塞,直到事件发生。于此同时,它也可以在需要的时候释放一个或所有进程。
每个同步变量上次获取它的进程都是它当前所有者。所有者有如下属性:
所有者可以重复进入和退出临界区,而无需通过网络发送任何消息。
当前不拥有同步变量但希望获取该变量的进程必须向当前所有者发送一条消息,用来寻求获取与该同步变量关联的数据的所有权和当前值。
多个进程也可以在非独占模式下同时拥有一个同步变量,这意味着它们可以读取但不能更新相关的共享数据存储。
由于,这类一致性模型中的共享变量都是同步变量(synchronization variable),基于同步变量的一致性也可以看作是分布式系统下面的多个进程(线程)之间的竞争-间接制约关系的协调。
基于同步变量的一致性由泛化到特化分为弱排序一致性(Weak Order Consistency)释放一致性 Release Consistency,进入一致性 Entry Consistency。
1.2弱排序一致性(Weak Order Consistency)
描述:本质上,弱排序一致性的同步变量在某种程度上等同于一个内存barrier或者fence,弱排序一致性不在乎其他进程是否立即知道每一个操作的读取和写入,而在乎所有进程是否知道的这一系列同步操作完成后造成的结果(即:在同步操作过程中,是不保证一致性的,只有对同步变量的同步操作完成之后,共享存储数据才可能保持一致性)。当同步完成后,其他进程读到数据后,它可以认为它得到是这个读取操作之前最近完成的写操作。因此,这个一致性不要求所有进程能够立即查看每一个读/写操作(visibility 要求低),更不用说都以相同的顺序查看它们了。弱排序一致性可说是顺序一致性(Sequential consistency) 的缩小范围到同步变量的简易弱化版本从而以提高系统的整体效率,其主要用于处理分布式系统的各个临界区。
模型属性:
1. 在一个进程完成所有先前针对各个共享存储数据(变量)的读/写入操作之前,不允许其他进程从该同步变量得到访问权限并执行任何操作。(即,其他进程同步等待所有对共享存储数据的正在进行的访问完成)
2. 在某一个进程(客户端)能够得到对同步变量的访问权限之前,不允许其对各个共享存储数据执行读取或写入操作,且能够得到先决条件是没有任何其他持有这个共享存储数据(变量)。(即,对共享存储数据所有新访问必须等待同步执行)
3. 与所有共享存储数据关联的同步共享变量的访问必须符合顺序一致性。
4. 整个系统在同步的时候“暂停”(需要顺序一致性)。
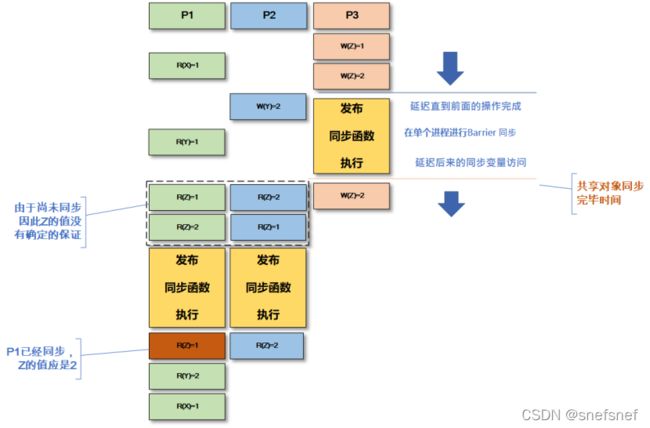
图11 弱排序一致性只在需要时进行同步
2. 释放一致性 Release Consistency
描述:由于采用弱排序一致性的系统的系统需要等待前面的操作都完成后,才进行对于同步变量的读/写操作,而只有这些同步操作都完成后,共享存储数据才可能保持一致性,因此效率较差。如果数据存储能够确定是读同步操作还是写同步操作,则可以依据对于共享数据对象读、写操作的特点,将同步步骤优化为两个同步变量获取acquire(读)和释放release(写)来分别实现,从而提高相应的执行效率,释放一致性模型也是基于此而来的。 释放一致性不要求顺序一致性,对于同步变量的访问仅需要PRAM,由于不需要维持顺序一致性,整个系统也就不用“暂停”了。
获取acquire:释放一致性模型中,当进程执行获取acquire时,在临界区的共享数据存储将确保与之相关的所有本地副本中受保护数据已经是更新完毕的最新的,同时在需要时可以与远程副本保持一致。
释放release:而释放release完成后,已更改的受保护的在临界区的数据将完整更新到数据存储的所有本地副本。(也就是说,“锁定”对其保护所有的共享存储数据的访问,并且直到对这些共享存储数据的所有访问都完成后,才会完成释放。)
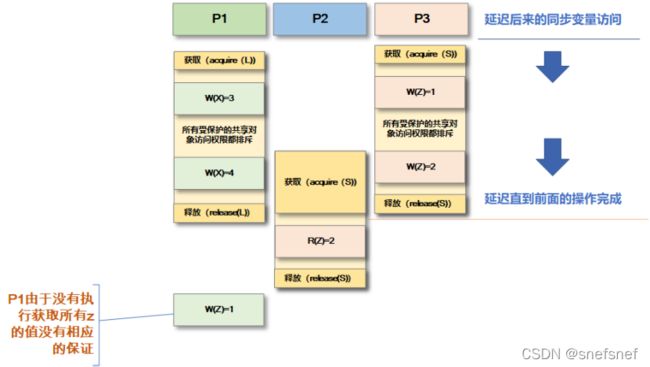
图12 进程需要保证中所有的受保护的共享变量的PRAM一致性
懒释放一致性 Lazy release consistency
由于释放release完成后,保证已更改的受保护的在临界区的数据都机械的无差别的更新到数据存储的所有本地副本的成本很高,而且有的时候本地副本未必需要更新(例如:更新的值和原来的值没有区别)。因此,在释放阶段对于释放一致性进行优化,对于更新进行所谓的lazy处理,即数据的更新只在另一个副本真正需要更新时发生,如有必要,进行数据更新的进程仍会向已修改和更新数据的副本发送消息。数据的时间戳是确定数据是否已过时或是否符合最新更新的最常用手段之一。
3. 进入一致性 (Entry Consistency)
描述:为了进一步提升系统效率,在释放一致性 Release Consistency进一步优化的基础上对acquire(读)和释放release(写)进行进一步优化,满足以下条件:
1)acquire(读)和释放release(写)与单个数据项相关联,而不是与整个共享存储数据相关联。(acquire(读)和释放release(写)可以看作锁。在(acquire(读)时,所有的远程进程的对于受保护单个数据项变化都必须更新到最新。
2)每个单个共享存储数据项都有一个隐式同步变量进(acquire(读)和释放release(写))行保护,可以获取该同步变量以防止并发访问共享存储数据项。
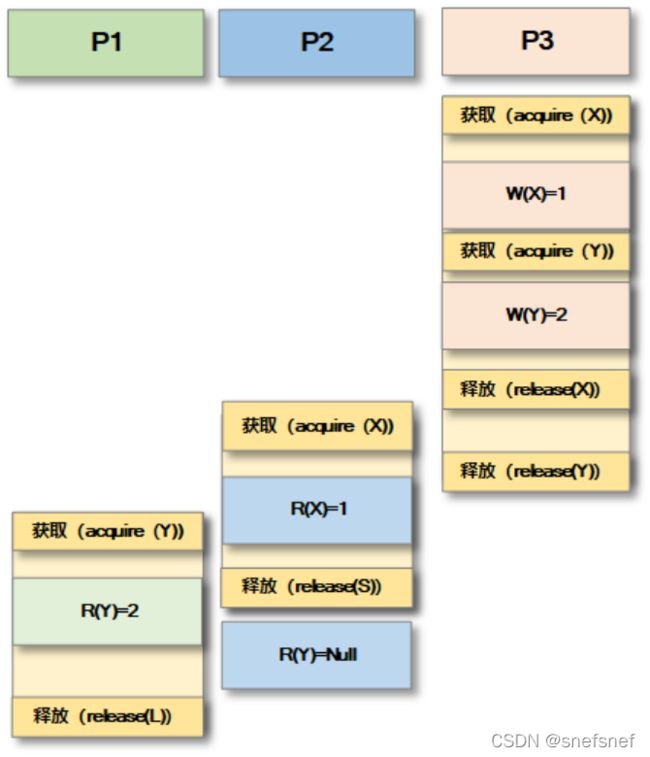
图13 P3释放后 P2和P1才行获取
客户端为中心的一致性模型(Client-Centric Consistency Models)
以数据为中心的一致性意味着,数据存储系统总是能够立即给出全局的符合某种一致性模型的结果给所有的客户端的读/写操作,无论是不是并发。然后,受限于现实的工程实现难度,成本等各种客观因素数据存储系统往往不能立即(或者说足够短的时间内)给出这样的结果。由此,我们需要对于现实生活中的分布式系统的客户端的本身操作特点进行分析,设计相应的一致性模型,从而给出以基于客户端为中心的一致性模型。在这个模型当中,其对于系统的假设是系统中各个进程的大部分的操作是非并发性的,因此系统中的共享存储数据的更新过程显得相对容易。这种模型以的方较小的代价忽略大部分的系统的不一致情景,因为每一个进程和其所需要的数据可信程度是各不相同的。例如:一个读操作大于写操作的系统,由于大多数进程都只是读取数据,几乎不执行副本上的更新,和大量的读操作相比只有少数进程执行更新也就是写操作。这里,重点会更多地放在为当前在数据存储上运行的单个客户端进程维护一致的视图上。在此基础上,必须具体分析的唯一情况是当一个进程想要更新更新一个共享存储数据项的时候,而另一个进程想要同时读取同一个数据项这种情景要如何依据读进程所需要的数据可信程度进行处理以保证客户端得到数据的一致性。
操作可以是严格操作,也可以是非严格操作。严格的操作要求它们在获得响应后立即保持稳定,而非严格操作可能会在之后重新排序。如果操作之前的前缀操作符合最终的总顺序,则称该操作是稳定的。
1. 弱一致性(weak Consistency)
描述:弱一致性是限制最少的一致性,当然它能保证的一致性也是最弱的。弱一致性只能保证各个进程的读操作可以得到一个结果,但是它不能保证进程的读操作从共享数据存储中得到值都是离这个读操作发生时间最近的写操作写入的值,也就是说得到值可能是过时的数据。即使如此,由于毕竟返回了结果,某些(随机的)需求仍能得到满足。弱一致性也不需要保证各个操作的顺序,因此没有对于同步以及时序的需要。乍一看,这个模型的可用性似乎很有限,但实际上很多现实需求都通过网络实现同步协议成本太高且没有必要,毕竟有的需求只需要数据存储系统的副本之间的偶然信息交换就足够了。例如,常见百度网页快照,web浏览器的本地缓存,各类CDN系统等待。 [Vogels, 2008; Bermbach and Kuhlenkamp, 2013]
2. 最终一致性(Eventual consistency)
最终一致性(Eventual consistency)比弱一致性稍微强一点。最终一致性假设系统并发更新的几率较小,绝大多数操作都是读操作。此模型的更新是通过类似于懒释放一致性 Lazy release consistency模型的延迟方式进行的(即数据的更新只在另一个副本真正需要更新时发生)。同时,当时数据在某个副本被某个进程更新完毕后,共享数据存储系统会容忍一段时间的高度不一致。如果后续长时间后没有新的数据更新,系统或副本将逐渐变得一致(即:副本会通过某些方式例如:通过乐观复制,或称延迟复制等收敛到相同的状态(仲裁)),并最终都能获取已更新的数据。因此,采用最终一致性的系统如果没有针对特定数据的新更新,则他们将从最近的数据访问位置接收更新,并读取最新更新。做一个不算恰当的比喻,这种过程类似于养鱼时候给底部有沉淀的鱼缸换水。当你开始换水,底部一部分沉淀物受到抽取脏水以及污物,加新水的影响会逐渐泛起,同时水也会变浑浊。而当你换水完毕,这些沉淀物又会逐渐沉淀在鱼缸底部,鱼缸的水质又回归稳定。这种概念最初始于移动应用,后来在各类分布式系统中也有广泛的应用,很多系统例如,像Casandra[72]、Google Big Table[73]和Amazon Dynamo这样的存储系统在提供大规模服务方面是有保证的。Amazon Dynamoch基于最终一致性,它的副本中的每个数据项是逐渐同步的,从而减少同步开销。
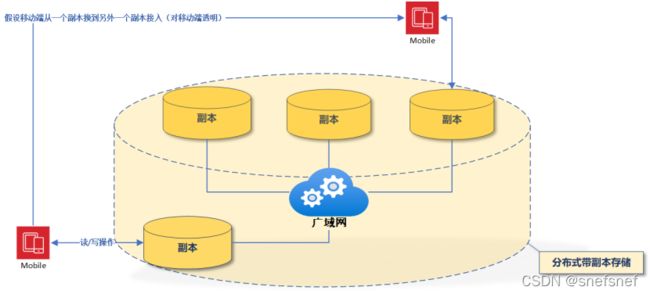
图14 最终一致性
如果以特定进程实例为单位的一系列顺序操作,可以将这个客户端进程实例在一次执行期间的读写操作序列抽象为一次session会话,由此可以得出会话保证(Session guarantees)概念 Terry et al. [1994]。最终一致性(Eventual consistency)等同于会话为单元的一致性的保证。 [Tanenbaum and van Steen, 2007]。对于客户端来说,符合最终一致性(Eventual consistency)的会话由于参与的读写操作组合不同而产生了以下几类一致性:
3. 读跟随写(Reads Follow Writes)一致性
描述:对于实现读跟随写的系统来说,它需要保证如果一个进程在对某一个共享数据x执行读取操作之前由这同一个进程已经进行的对共享数据x的写入操作必须已经全部完成。如果这个系统是一个多副本分布式数据存储系统,则这个进程的读取操作执行之前其所有的写入操作在所有副本上都要执行完毕。
模型限制条件:
由于其因果关系只局限于单个进程或者会话的范围,这种一致性和因果一致性相比限制更低也就更弱。
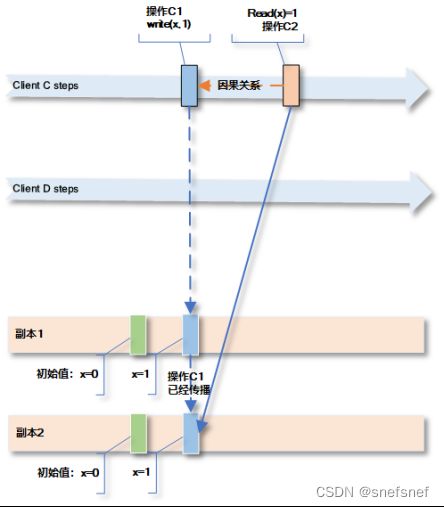
图15 只保证单个会话或进程中读操作C2在写操作C1之后并且操作C1在所有部分都已经执行完毕。
4. 写跟随读(Writes Follow Reads)一致性
描述:写跟随读(Writes Follow Reads)一致性又称为会话因果一致性(session causality),当一个进程a进行读操作x读取了某一个共享变量v,这个变量v的值x是由之前的某一个进程b的写操作y写入的,而后当这个进程a进行写操作z写入值w,则写操作z必须对所有的进行观察的进程来说发生在写入操作y发生之后发生。即写操作z不能改变读操作z之前发生的结果。这个一致性与读跟随写一致性的要求相反,也是一种系统实现的常见的一致性,例如:发帖与跟帖。
模型限制条件:
和因果关系一致性相比,由于其和顺序关系排序相关的3个操作中后面发生的两个局限于单个进程实例范围内读写操作之间,因此这种一致性是限制更低的一类因果一致性。由于其不是所有的操作都局限在单个进程实例范围内,因此写跟随读(Writes Follow Reads)一致性也不同于管道一致性FIFO。
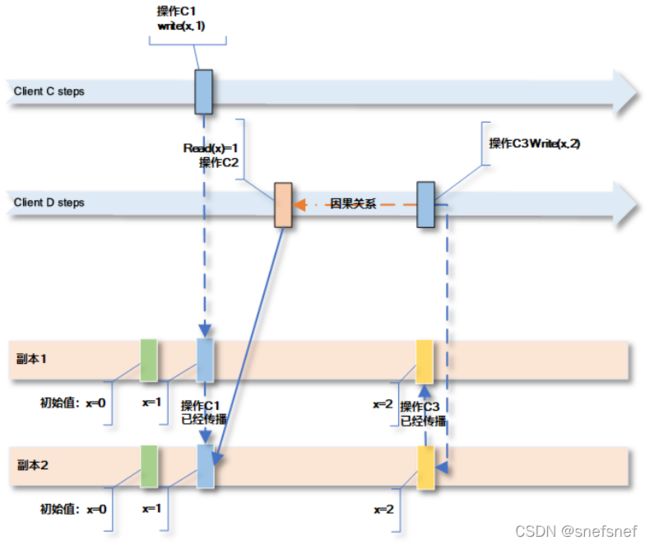
图16 只保证单个会话或进程中读操作C2在写操作C1之后并且写操作C3在写操作C1之后。
5. 单调读取(Monotonic Reads)一致性
描述:
单调读取(Monotonic reads)保证当一个进程(在一个会话范围内)先执行了读操作r1,然后执行了读操作r2,则读操作r2不能观察到在r1操作读取到的由写操作x写入值发生之前的由任意其他写操作的值。
模型限制条件:
单调读取(Monotonic reads)仅保证一个进程(在一个会话范围内)的读操作,而不保证多个进程之间的读操作。
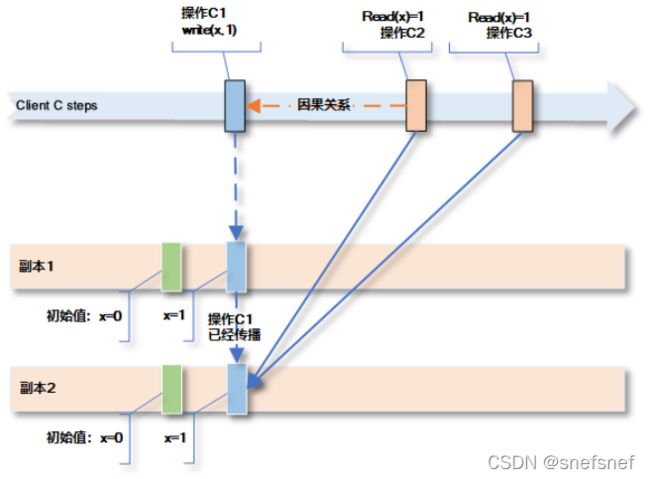
图17 为了保证单调读取,所有clientC的写操作在副本1,2之间都要传播完毕
6. 单调写入(Monotonic Writes)一致性
描述:单调写入(Monotonic Writes)保证当一个进程实例(在一个会话范围内)先执行了写操作w1,然后执行了写操作w2,则所有其他进程对于这两个写入操作的顺序观察是w1发生在w2之前
模型限制条件:
单调写入(Monotonic Writes)仅保证一个进程实例(在一个会话范围内)的写操作,而不保证多个进程之间的写操作。
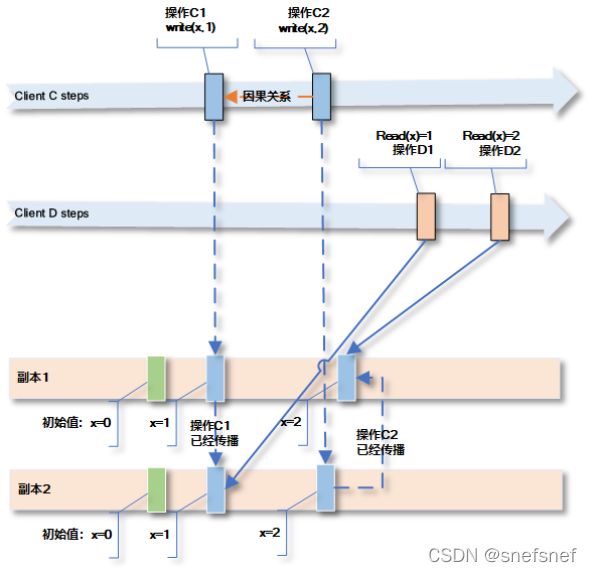
图18 对于clientD来说要保证其观察到操作C1和C2顺序和在clientC上面是一致的
复合一致性
由于经典的强一致性对于数据存储系统系统实际实现有较高的要求,同时在执行效率上是有较大的影响。而客户端为中心的一致性往往基于客户端系统的需求有较大的弹性并由较高的可用性需求,为了弥合较强一致性的需求和分布式系统实际实现以及系统整体执行效率需求之间的差异。人们根据性能需求和一致性需求从实际出发,对于所设计的系统从时间,数据,操作顺序维护,数据错误等多个方面,加以权衡以及妥协,从而提出了一系列复合一致性以及可调的一致性语义,是开发者可以依据系统的需求以及使用场景以自适应方式使用不同类型的一致性。
基于过期信息模式下的一致性模型(Staleness-based models)
如果某些需求能接受类似最终一致性(Eventual consistency)的情景,即需求允许系统容忍一段时间的状态不一致后,同时系统能保证后续长时间后没有新的数据更新,系统或副本的状态将逐渐变得一致。但是系统或副本的状态恢复到一致性状态之前这段时间应该如何定义呢?而且如果在这段期间内,为了保证系统的可用性,此时允许系统返回已经陈旧结果,这类情况是否又能与其他一致性结合来满足一致性需求和执行效率的平衡呢?由此,提出了一类基于过期信息模式下的一致性模型来处理这一类情况。它们提供了比最终一致更强大的语义保证,但和线性一致性这类一致性相比又限制足够弱,从而获得了更高的系统执行效率。一般来说,业界使用两种常见的指标来衡量数据是否过时:(实时)时间和数据(对象)版本。
delta 一致性(delta consistency)、定时一致性模型(timed consistency)以及有界过期一致性(bounded staleness)
这三个一致性的思想本质上都是一致的,主要差异在于实现细节层面,这些差异由发明这些模型的不同背景和实际目的造成的。这类一致性如果使用在一个有副本的共享系统,则需要这个时间间隔内各个副本的状态要同步完毕并符合需求无误。这类模型常用在保证服务级别协议以及帮助设计实现分布式系统操作的时候在实现一致性与系统可用性(可访问性)两者之间的进行明确的划分。
1.delta 一致性(delta consistency)
描述:第一次明确的形式化定义了基于时间的过期内容的一致性(Singla et al. [1997] )的一致性是delta 一致性。delta 一致性规定某个进程对于某个共享变量的写操作在t + delta (time units)时间单元后必须为所有进程可见(visibility)。delta 一致性没有定义对应所有进程的写操作的全局统一的排序,它仅要求由同一个进程写入给定对象必须给所有进程以相同的顺序观察。delta 一致性没有对于时间长短delta 值进行具体定义。
2.定时一致性模型(timed consistency)
描述:由Torres-Rojas(Torres-Rojas[1999])等人提出了定时一致性模型(timed consistency)一种数据为中心的一致性模式,对于这个写操作后流逝时间的长短与返回值之间的关系进行了定义(即,哪些值可见(visibility)),即通过自先前写操作后的流逝的时间的长短来限制读操作返回值的集合。具体而言,在定时序列化(timed serialization)中,所有读取都即时发生。也就是说,当在超过∆个时间单位(∆是操作执行的一个参数即操作时间的具体长短)时后有更多最近的值可用时,读取不会返回过时的值。换句话说,与delta一致性类似,如果在时间t执行了一次写操作,则该操作写入的值必须在时间t + ∆ 对所有进程可见。
3.有界过期一致性(bounded staleness)
描述:(Mahajan et al. [2010]),也提出了类似的语义,不同之处在于,其将delta时间的长短定义为一个固定值,通过每一个进程与其他进程之间通过定期消息(信标)交换以保证信息的更新以及检查更新丢失。
与基于过期信息模式相关的复合一致性
属于基于过期信息模型下的各类一致性(如:定时一致性模型等)也可以与前面提过某些较强的一致性相结合形成一类复合一致性,从而实现执行效率和正确性之间的某种平衡。
1.定时因果一致性(Timed causal consistency)
描述:定时因果一致性(Timed causal consistency)既满足了一般因果一致性所需要因果顺序要求,并且加上了基于时间的对于操作顺序可见性的限制要求,即当系统在时间T已经有操作e1发生以及和e1有因果关系的e2发生,则在时间T+δ时刻之后整个系统内所有的进程能够观察并得到操作顺序和因果一致性保证的顺序一致。由于增加了基于时间的可见性限制要求,定时因果一致性比因果一致性要强。
2.定时顺序(序列)一致性(Timed sequential( serial ) consistency)
描述:定时顺序(序列)一致性(Timed sequential( serial ) consistency)在整个系统中使用统一的时间作为标准来保证系统内各个读/写操作的实时执行顺序。假设在系统的时间t的有操作e1发生和时间t+δ这一时刻有操作e2执行,则整个这个系统内所有的节点或进程观察得到操作顺序和这两个操作基于发生时间发生的前后顺序一致。即有某个并发进程的的读取操作从共享变量x读取所得到信息,要么是其他进程在t时间写入的值,要么是在t+δ写入的值。Golab et al. [2011] [Torres-Rojas and Meneses,2005]
3.定时线性一致性(TIMEDLINEARIZABILITY)
描述:定时线性一致性是一种将δ看作一个“偏差”( “deviation”)时间的线性一致性模型[Golab et al., 2014],即将在δ时间作为某个操作的所需的执行的时间(实际执行时间=δ)与具有相同操作结果的可线性操作执行的时间(线性一致性假设理想化执行时间实时)之间的"偏差",而这种有相对固定”偏差“限制的线性一致性便是定时线性一致性(TIMEDLINEARIZABILITY)。当将定时顺序(序列)一致性的δ与线性一致性的区别是它设定了一个偏差时间限制。
4.前缀顺序一致性(Prefix sequential consistency)、前缀线性一致性(prefix linearizable consistency)、
描述:在某些分布式系统所需实现的需求中,保证所有进程都能够保证观察到各个进程对一个共享变量的统一写入操作的顺序比保证所有进程的读操作一定能读到最新的写入值要更重要。在当这个分布式系统中的共享变量有多个副本情况下要符合前缀顺序一致性,则需要某个进程的读操作获得的值是所有副本都同意的之前的各个进程以某种统一的写入顺序(单个进程在一个session中的写入顺序会得到保证,参考单调写入)进行写入的结果(通过仲裁进行收敛)。即使由于收敛需要时间,这个写入的结果有可能已经过期,系统仍会接受这个结果。基于前面描述过的顺序一致性和线性一致的关系,如果对于写入操作加入时间上面的限制,则我们可以得到前缀线性一致性(prefix linearizable consistency)。
5.K线性一致性(K-linearizability(K的由需求定义))以及概率有界过期一致性模型(PBS(PBS
描述:那么当系统可以容忍某些过期结果,要如何定义容忍基于版本的有限过时性呢?一种是通过选择读取非重叠并发写入的最新 K个版本的值之一并结合前缀线性一致性得到K-linearizability(K基于需求),另一类是将得到的过期值的限制以一个概率模型代替从而得到概率有界一致性模型(PBS k-staleness)或某个写入操作应该多久被其他进程可见的时间范围也以概率模型进行限制(PBS t-visibility),也可以将这两者结合从而可以从返回值的过时概率范围,以及写入变得为所有进程可见之前的时间概率范围两方面给出相应的限制,从而定义出概率有界过期一致性模型(PBS
操作相关的混合一致性(hybrid consistency)
描述:为了分布式系统的运行性能着想,这类一致性模型将系统中的所有操作分为强操作( strong operations)和弱操作(weak operations)。强操作保证的执行顺序能被所有的进程可见,即强操作对于所有进程保证顺序一致性,而弱操作则只保证最终状态为所有进程可见(和最终一致性类似)。当弱操作和强操作相互交织情景下,弱操作的最终顺序必须根据其与强操作的交错顺序来进行排序,即如果两个操作属于同一会话,其中一个是强操作,一个是弱操作,则所有进程都会看到一个统一的两个操作之间关联的调用顺序。
1.最终线性一致性(Eventual linearizability consistency)
描述:这种一致性保证强操作会立即线性化,但弱操作则只能保证最终才会线性化。实际上,弱操作可以被设计为在某些条件下(例如:故障)终止执行,而当终止的条件消除(故障消除)后,弱操作最终会完成并形成相应的执行顺序。因此,最终线性一致性可能在有限的时间内违反线性化。从本质上讲,最终线性一致性还是要达到线性一致性,因此这种一致性模型最终还是必须根据各个操作实时操作时间行排序。但是由于弱操作的存在,只能保证在特定时间 t 之后调用的操作记录符合这一要求。因此,比特定时间 t更早的时候发生的各个进程的读操作可能观察到不一致的历史记录,并且这些记录可以以任意临时的方式进行排序。但是最终,实现最终线性一致性的系统中的操作会提供一份实现满足各个操作实时行约束的总的操作排序。
2.红蓝一致性(RedBlue consistency)
描述:红蓝一致性和最终线性一致性十分类似,可以看作最终线性一致性一类扩展,其主要使用在个多个副本的分布式环境中。当分布式系统中多个主从副本的数据复制速度这一性能的要求比维护系统数据较强的一致性(例如:线性一致性)更重要的时候,这种一致性显得十分有用。红蓝一致性将操作分为红 、蓝两类。这种一致性模型以下几个部分组成:
1.符合系统的一个总的红、蓝顺序其指定了一个所有的操作的偏序。其中,红色操作是全序(与总的红、蓝顺序这个偏序兼容),而蓝色操作是偏序。(即:蓝色操作的执行顺序从一个副本到另一个副本可以不同,而红色操作的执行顺序则在所以副本上应相同)
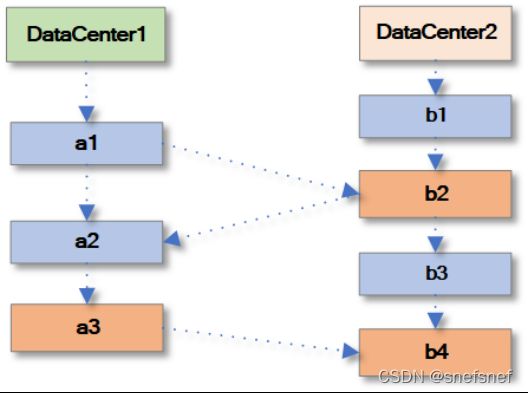
图19 红蓝操作的总顺序
2.在使用蓝红一致性的多副本存储的分布式系统中,每个副本的本地的序列化(Causal serialization)操作顺序由一组由各个副本彼此之间具有因果关系的操作组成的。它定义了某个应用操作特定于某个副本的所有操作的全序。这些副本的本地的操作顺序一起组成了整个分布式系统的符合红蓝一致性的所有操作的全序。
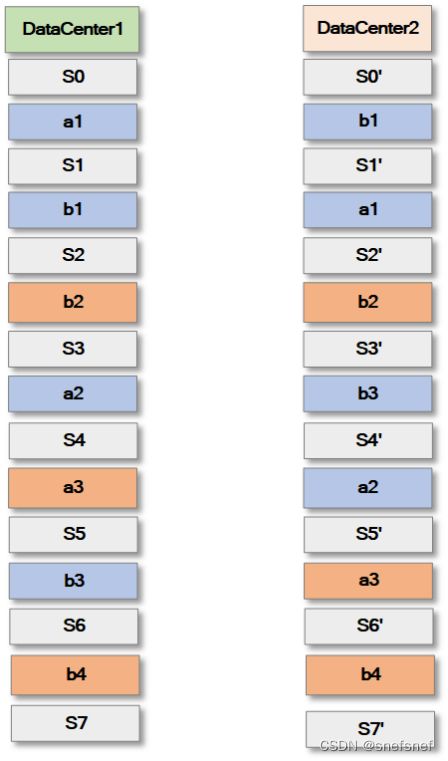
图20 S表示的是状态的所写,由于蓝色是偏序操作符合各自本地的因果一致性,因此各个数据中心的蓝色操作顺序可以不同,但红色操作顺序必须一致。
3.由于红蓝一致性中每个副本的本地的序列化(Causal serialization)操作的顺序是不同的,而且当系统中有的操作本身是不支持交换律的时候,会造成各个副本的状态各异,使各个副本的状态无法收敛到一个单一相同状态,从而影响系统的整体的正确性。
例如系统要进行如下操作:
float total=100, price=10, discount=0.1,
func addItemCalTotal( int itemNumber ):
total = total + (itemNumber*price);
func removeItemCalTotal( int itemNumber ):
if ( total - (itemNumber*price) >= 0 ) then:
total = total - (itemNumber*price);
else print "failure";
func accrueTotalPrice ():
float totaldiscount= total× discount;
total = total- totaldiscount;如下的例子当中总价计算与增减产品数量操作本身都不是可交换的。由于不同的顺序会造成总价的数量不同,这不符合业务的正确性。
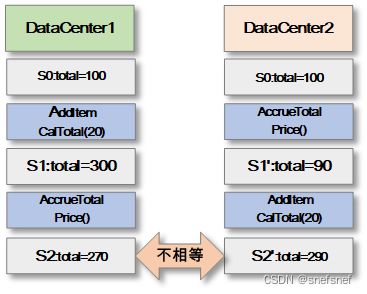
图21 当操作不符合交换律的时候造成不同的数据中心的数据记录状态在多个操作执行完毕后出现了不一致
4. 为保证分布式系统的整体的准确性,理论上为了达成这个目标的充分条件是所有的蓝色操作都支持交换律,也就是说所有的蓝色操作与其他操作无论红色还是蓝色操作都能交换次序,且交换后系统的各个阶段的状态没有变化。当所有的蓝色操作都支持交换律就可以保证符合红蓝一致性的分布式系统的各个副本的状态全部收敛到同一个正确的状态。现实中很多操作本身不支持交换律,但是可以通过使这些操作造成的变化后的状态符合交换律来达到相同的目的。为了达到这个目的,需要将这个系统中的每一个操作(无论红/蓝)分为两个部分:一类是没有复制副作用(Replicating side effects)的所谓生成器操作(generator operation),它仅在主副本(primary)针对某些系统状态 执行,一类是基于生成器操作生成的在每个副本(包括主副本)都会执行的影子操作 ( shadow operations),影子操作可以多于一个。影子操作存在使所有的操作都能符合交换律成为可能,只要我们能够识别出这下函数的潜在的阿贝尔群(阿贝尔群也称为交换群或可交换群,它是满足其元素的运算不依赖于它们的次序的群。)。
例如:将计算折扣操作拆分成一个没有任何复制副作用的生成器操作accrueTotalPrice(),以及它相应的影子操作 accrueTotalPrice(90)‘。这个影子操作将在所有的副本上执行,需要注意的是无论这个操作在各个的主/副本的执行顺序如何,这个影子操作的输入参数的值与其所属的生成器操作当初执行时的输入参数的值(即原始状态)一致,执行后的结果(状态)也一致。
系统操作对应影子操作 (shadow operations):
func addItemCalTotal’ ( int itemNumber ):
total = total + (itemNumber*price);
func removeItemCalTotalAck’ ( int itemNumber ):
total = total - (itemNumber*price);
func removeItemCalTotalFail’ ():
/* no-op */
func accrueTotalPrice’ ( float totaldiscount ):
total = total - totaldiscount;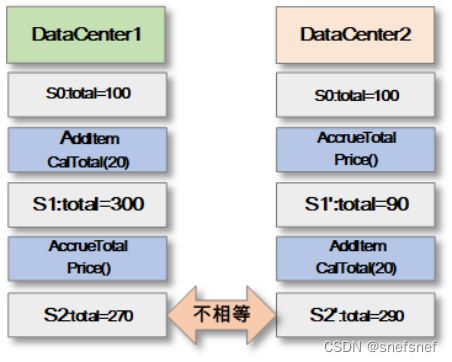
图22 蓝色的影子操作 ( shadow operations)
5.除此以外,由于分布式系统所需满足的需求也会有相应的业务约束,因此仅仅保证所有的蓝色操作都支持交换律只能保证系统的副本状态收敛到某一个状态,但是并不能保证这个状态一定符合系统的业务需求。因此,需要蓝色操作的影子操作都符合业务约束的要求。
例子:连续两次减少货品函数的使购物车出现了负数,在这个业务场景下的业务规则要求是不允许出现负数,因此收敛到负数的运行结果是错误的。
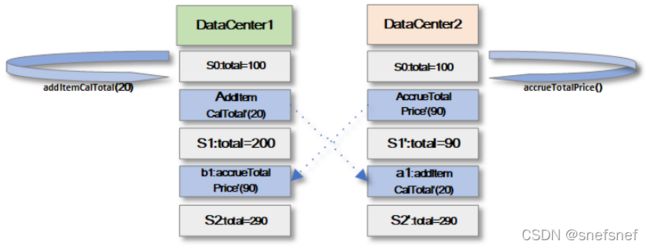
图23 系统的状态S4不符合系统的业务需求约束
将上面的情况结合起来,可以看到如果所有的影子操作都正确执行,所有蓝色操作的影子操作都符合业务的规则并且是全部符合交换律的,则可以认为这个分布式系统符合红蓝一致性,所有的副本的状态都符合业务需求的约束。
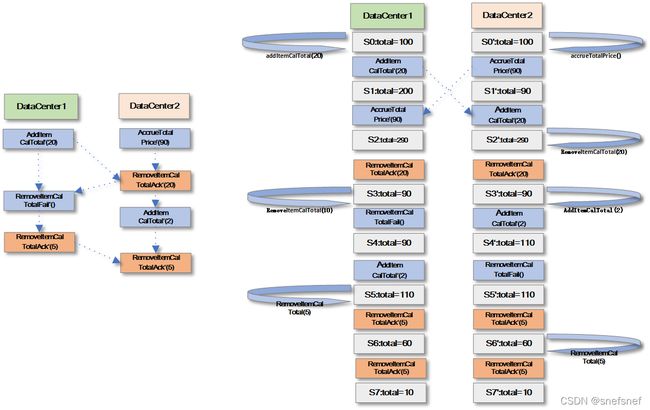
图24 系统通过红色的影子操作和蓝色的影子操作结合使系统状态符合业务约束
至于哪些操作选择为蓝色操作,哪些为红色操作这个问题,从上面的描述可以看到,可以依据以下条件筛选:
1.如果任何影子操作的执行会造成违反业务规则的结果则这个操作可以认定为红色操作。
2.任何成对的不符合交换律的影子操作可以认定为红色操作。
3.除此以外的所有非红影子操作可以看做蓝色操作
连续或可调类一致性(continues or tunable consistency)
随着云存储以及云计算等技术成为业界的主流技术,由于高可用/性能/伸缩性等需要变得越来越重要,这些设计目标和系统所需达到的一致性需求向着一种相互妥协相互平衡的方向发展,从而产生了一类比复合类一致性灵活性更高的连续类一致性。通过对于业务需求,QoS 、SLA模型以及其他因素(例如:系统的实现、运维成本)来分析并确认客户端对于分布式的一致性需求,系统架构师可以基于这些需求进行分析权衡,选择相应的能提供相关强一致性或弱一致性语义的连续类一致性的来设计分布式系统。
由于连续类一致性是可以基于一致性语义相关的可调参数进行动态一致性调整的,因此提出了一致性程度的概念(degree of consistency)。架构师可以以此为基础,建立相应的可调的参数化连续类一致性框架来满足分布式系统的多种一致性需求。
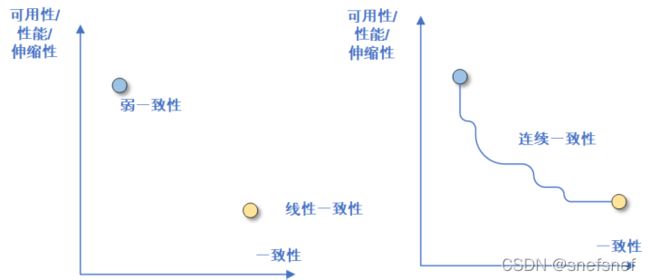
图25 相比于两分的一致性,系统可以更好的利用连续一致性的一致性参数
1.自适应或配给一致性(Adaptable Consistency)
描述:自适应或配给一致性是一种可以动态调整的复合一致性,符合这种一致性的分布式系统的各个操作的执行的一致性强弱程度与系统内保存的业务数据重要性成正比。
例如,某在线购物网站,需要存储用户个人信息在不同类型的数据项上并在维护成本以及网站执行效率等多个方面上取得平衡,就可以使用这种一致性模型,
假设我们有A, B, C三类信息。其中A信息是信用卡的账户号或身份证号,B信息是用户的生日,C信息是昵称。
A信息的重要性最高这是不言而喻的,因此需要保证线性一致性。C信息重要性较低可以使用最终一致性。B信息则基于信息不一致后会造成的损失大小而采用不同的一致性。如果采用某种一致性造成的损失(例如:使用最终一致性,但是发现姓名信息在各个副本存储的结果不一致造成给用户的错误显示造成的某些和用户的生日相关的促销或其他服务产生错误)大于由于可用性与性能造成的损失(例如:用户流失),则会自行调整为采用线性一致性。当在云环境等分布式系统使用时,这种自适应性的一致性模型可以使云服务依据ServiceLevel Agreement (SLA) 在提供的最大过期读取速率与符合某种一致性所需要的成本之间得到动态平衡。
2.多维度一致性(Multi-dimensional consistency)
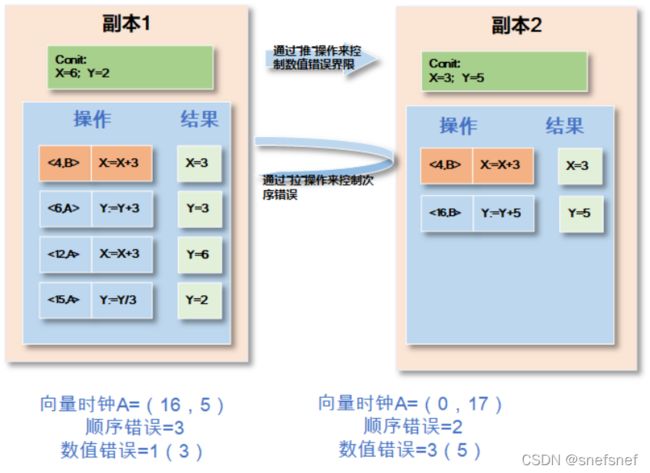
描述:多维一致性[88]是一种以数据为中心的一致性,和自适应或配给一致性相比它具有更完整的一致性程度的概念。这个模型通过三维向量过时、顺序错误和数字错误描述一致性程度。具有这三维向量数据单元或数据项的称为“conit”的数据单元,一般为不能有矛盾的信息(例如:银行账户数据,身份证信息等)。这个基于数据单元可以度量当前系统能够的提供的一致性与理想线性一致性之间差距。实现这个模型的系统在处理一致性时,应用程序应只面对语义级别(简化来说即业务级别)的一致性。在这个模型中没有数据项级别的一致性的设计,而是通过每个数据副本基于其所拥有的“conit” 维持一个独立一致性级别来实现。
数值错误(Numerical error):系统所有的副本都应该执行,但由于各种原因未传播到特定对象的某个给定副本的写入操作总次数的上限,即具有不同数据的副本的上限。这个维度用来说明系统能容忍的未能完全收敛的数据程度。另外,由于数值错误是通过消息推送的方法进行限制,因此当副本太忙而无法进行传出通信操作即进行消息推送,则提交给系统的写入操作将被延迟。
顺序错误(Order error):任何副本上要重新排序的临时写入操作的次数上限。主要通过消息拉取来进行核对并进行限制。
过时(staleness):写入操作在复制副本之间的传播延迟的实时性限制。为了限制副本的数据的过时性,每个服务器都需要维护一个实时向量(real time vector)。向量在这个系统中的每一个副本上面有一个记录。如果在副本A的实时向量记录与B副本的记录一致都是时间t,则副本A能够观察到B在实时t之前接受的所有的写记录。 为了将系统信息的过时限制在某个限制L以内,假设系统内的副本当前时间为T,系统内的副本需要检查实时向量中的每个记录是否符合T-t 多维度一致性可以在单个副本上定义,每个副本都可以有自己独立的conit一致性级别,而不是强制实施系统范围的统一的一致性级别。假设此分布式通过推送进行副本数据同步更新,如果放松某一个副本的数值错误,这意味着其他副本可以不那么频繁地向该副本推送写入,从而减少需要从其他副本传入的消息。需要注意的是这个副本的传出通信量保持不变,因为这取决于其他副本的一致性级别。类似的,通过放松对于某个副本的顺序错误与过期两个指标,也可以减少各个副本进行的通信次数。 下面是一个示例:假设有两个数据副本A,B的分布式系统,每个数据副本有中的两个数据项x,y,所有副本基于各自独立的“conit”进行数据更新 ,整个系统基于逻辑向量时钟。当在A副本有一个写操作提交成功,即变成永久变化无法回滚。副本B对副本A发送了操作(4,B) X+=3 (操作记录的次序为4,在副本B和副本A都进行了这个写操作)。 顺序错误:但在这个写操作成功的同时,在副本A还同时有其他3个没有执行并提交的操作(假设副本A是顺序执行且(5,B) X+=3 第一个执行),这些操作需要重新排序,所以需要重新排序的操作有3个即顺序错误为3。同样的,在副本B也有2个还没有执行并提交的写操作,写操作次数由副本B独立决定和副本A无关,所以需要重新排序的操作有2个即顺序错误为2。 数值误差:是应用于本地副本未观察到的所有副本的基于“conit” 的所有写操作的次数。副本 A 没有观察到一个写操作(16,B):Y+=5(假设副本2没有向副本1推送,副本中可以容忍的上限为3),而副本 B 没有观察到三个更新(假设副本1没有向副本2推送,假设副本中可以容忍的上限为 5)(6,A):Y+=3,(12,A):X+=3,(15,A):Y=Y/3。 图26 副本2 向 副本1 发送操作 [4,B: x := x + 3]; 3.VFC3 (Versatile Framework for Consistency in Cloud Computing) 描述:VFC3的设计思想与多维一致性等类似,是一种专门设计用于满足需要在几个地理分布上分散的超大规模和动态分布式系统环境的数据中心(例如,云计算中心)之间同步大量数据(无论是应用程序运行需要的信息交换或存储数据)并同时保持对外提供服务的质量和所提供服务的数据质量的一致性框架库,它的设计初始目标是运行于NoSQL高性能数据库之上。VFC3框架库还包括一个分布式事务缓存,并且它的一致性水平可以根据统计信息自动调整。人们系统通过VFC3能够改进 QoS,合理化资源使用(尤其是带宽),并提供更高的性能。 VFC3 框架库基于3个维度的向量以提升在数据中心的数据备份的一致性水平。 时间维度:表示某副本在具有了最新值之后无法进行更新的最长时间。 序列维度:表示对某一个对象进行更新操作且不用考虑数据在其他副本进行备份的频次上限。 值维度:表示各个副本已经保存某一个数据项的数据内容与系统层面定义的某一个常量之间(例如:某个最大值)差异的最大比例(例如:通过百分比表示)。 图27 VFC3示意图 ref Quality-of-Service for Consistency of Data Geo-Replication in Cloud Computing? 拜占庭(Byzantine faults)系统下的一致性模型 分布式系统当中大部分属于良性故障,例如:遗漏性故障,时间故障等,此类故障不存在恶意攻击的场景,即系统虽然会发生故障,但是系统中所有的部分都是可以信任的,不会出现无法预测的恶意故障。当系统环境中出现了内部信任限制,例如:某些副本可能被人植入了恶意软件,则需要将此分布式系统归入存在拜占庭故障系统,而拜占庭故障属于所有故障中最糟糕的故障,各个部分都可能出现无法预测的恶意故障。所以, 需要对通信部分的可靠性做出保证,并以此为基础设计出适用于无法保证各个部分过程行为的系统的共识问题解决方案,才能完成满足某些一致性需求的存在拜占庭式故障的分布式系统的设计。 通信模式: 由于(FLP)定理,在纯粹基于异步的通信的分布式系统中,对于即使像崩溃停止(crash stop)这样的良性的简单故障,没有任何解决方案能使系统中的各个节点达成共识,在存在进程故障的情况下只有基于消息传递模型的同步分布式系统有可能达成共识并满足某些一致性需求。因此,本文中的存在拜占庭故障系统的分布式系统的通信都假设采用同步通信模式并在此基础上符合口头通信模型(Oral Communication)的所有要求,要求如下: 1)计算速度具有已知的下限, 2)通道延迟具有已知的上限, 3)因此可以使用超时来检测消息的缺失,即使消息可能会丢失,但可以检测到消息的缺失。 4)消息在传输过程中不会损坏。 5)当收到消息(或检测到消息缺失)时,接收方知道发送方的身份。 拜占庭(Byzantine faults)系统节点的角色交互式一致性标准: 正如Lamport 在拜占庭问题描述中将一般节点分为指挥官与中尉两种角色那样。每个一般节点在广播时扮演指挥官的角色,当他接到另一位将军的命令时扮演中尉的角色。有些一般节点可能是叛徒。当忠诚的指挥官将他的命令广播给 中尉,每个忠诚的中尉都会收到相同的命令。当有的反叛一般节点做指挥官,收到相同的命令便不能保证,反叛一般节点可以同时发出攻击与撤退指令给其他中尉。因此,为了满足存在拜占庭故障系统的分布式系统的能有一致性,指挥官与其中尉之间的通信需要满足以下两个交互式一致性标准定义: 1:每个忠诚的中尉都会从指挥官那里得到同样的命令。 2:如果指挥官是忠诚的,那么每个忠诚的中尉都会收到指挥官发出的命令。 在确定了系统的通信模式及其相应的交互式一致性标准之后,对于存在拜占庭故障系统的分布式系统如何满足一致性本质上就变成了如何制定一种策略,通过该策略,无论系统中任何错误节点的行为如何,系统中的每个正确的通信节点最终都会同意同样的合约即达到共识。一般的一致性需求的定义不考虑系统的网络的具体情况,而在拜占庭故障存在的分布式系统中需要分别考虑,因为分布式系统中不同的网络分区模式(即所有节点之间都能相互通信,还是会将各个节点区分为不同组各个组之间不通信或各个节点之间不通信)会对于系统的一致性的限制有很大的影响。 首先,我们需要知道在这样的假设的分布式系统之下,是不是仍旧有类似FLP的不可能达到的结果呢。由于是基于共识达成一致性目标,当叛徒出现,则每个中尉只从自己指挥官那里收取数据是不够的,因为每一个中尉并不知道自己的指挥官是不是叛徒,为了检查可能的不一致之处,忠诚(和明智)的中尉也需要从其他中尉那里知道信息并通过少数服从多数原则来分析收到的哪些消息是正确的消息。 拜占庭(Byzantine faults)系统达成共识的限制 即使符合上述条件,由于系统要获得共识必然采用少数少数服从多数原则,在拜占庭(Byzantine faults)系统中在某些情况下仍旧无法达成共识。 由下图可知,当只有三个节点的时候,只要由一个节点是叛徒,无论其是指挥官还是中尉,系统中的各个节点无论如何都无法基于少数服从多数原则得到共识。 图28 a)将军是忠诚的,红色为叛徒 b)将军为叛徒,士兵没有叛徒 实际上人们已经证明,如果使用口头通信模型具有拜占庭将军故障的分布式系统的节点数量为3m或更少的时候,只要其中有m(m>0)个一般节点为叛徒,系统无论如何都不存在基于少数服从多数原则的解决方案使系统得到共识,即,为了在具有m个叛徒节点的系统中达成共识,系统的总结点数量需要为 n ≥3m + 1个。 分叉类一致性(Fork consistency) 分叉类一致性(Fork consistency)(Mazieres and Shasha [2002])适合于某一类分布式系统,这种分布式系统由可能为不可靠的存储节点及其彼此之间没有直接联系的可靠的客户端节点组成。分叉一致性增加了对分布式系统中共享数据的操作的并发性,并引入了分叉类一致性来保护客户端节点信息免受恶意存储节点的侵害。这个系统中的客户端节点彼此互相观察对方的操作都是通过某些存储节点的操作记录 。 分叉线性一致性(Fork Linearize Consistency (FLC)) 描述:分叉线性一致性也是一种复合型一致性,当节点是可靠得,一致性模型保证了所有客户端操作在服务器节点上操作的原子性。实现分叉线性一致性的系统可以保证,当多个客户端节点通过某个存储节点观察到同一个操作时,所有客户端以一致和统一的方式查看其他客户的操作,这些客户端节点对于这个操作以前执行的操作进行观察而得到的历史记录都是相同的。如果任何一个不可靠的存储节点导致两个进程的可见的历史记录不同,即使这个节点只对一个操作发生这样的情况,(假设客户端节之间可以使用任何可用通信协议进行相互通信,从而很容易地发现各个客户端节点彼此所观察到的log记录中的任何差异。例如,gossip协议等),则各个客户端节点便再也不能通过这个已经被确认为不可靠的存储节点进行观察并得到彼此对于某个共享变量的写入结果,即出现了记录的分叉(fork)。当分叉后,各个客户端基于得到不同写入结果分出不同得群。分叉线性一致性一旦分叉无法再次连接(join)。当某个存储节点是可靠节点时,该一致性要求这个存储节点应该实现线性一致性,如果这个存储节点不可靠,则通过分叉一致性来保证一致性。如果将线性一致性部分的时间限制去除,如同线性一致性部分则转变成为顺序一致性一样,从而得到分叉顺序一致性(Fork sequential Consistency (FSC)),在FSC中,并不能保证所有客户端的操作都是原子的。分叉顺序一致性和分叉线性一致性一致一旦分叉无法再次连接(join),也没有任何冲突处理。 图29 分叉线性一致性 不同的客户端client1,2最终得到操作记录版本会不同。客户端确信当不可靠的存储节点的故障被发现后系统会分叉,各个客户端直接会永久分区。造成不同版本的唯一原因是分叉,而不是由拜占庭错误引起(即服务器没有恶意行为)。 Fork*一致性(Fork*Consistency) 描述:Fork*一致性放松了对于分叉类一致性分叉后已经分组的各个进程不允许再次看到同一个进程的公共操作的限制。Fork*一致性允许由于分叉而被分组的各个客户端节点可以再次都观察到由某个正确进程发出的最多一个公共操作(join一次)。Fork*一致性可以提供更好的性能以及存活性(Liveness)。 分叉连接因果一致性(Fork-join causal consistency) 描述:在分叉连接因果一致性(Fork-join causal consistency)的因果一致存储系统中。FJC保证各个可靠进程的操作之间的因果一致,即如果一个可靠进程发出的某个写操作op1依赖于它之前的任何进程发出的写操作op0,那么对每个可靠的进程来说,写操作op0在写操作op1之前变得可见。此外,因为不可靠的进程(假设系统含有拜占庭错误)而产生分叉写入操作被视为由多个虚拟进程发生的并发写入,所以当不可靠的节点被发现并给修正,因为分叉而被分区的进程可以再次连接(join),如何融合则基于各个系统各自特殊需求所需的合并策略来定义(例如: git的merge)。 图30 分叉后做为并发操作处理 总结 感谢读者有耐心完成这一冗长的一致性介绍之旅。本文涉及的一致性种类繁多,主要从系统需要实现的目标的角度,给开发者在确立系统的设计目标有一个相应的参考与了解,并介绍了先进主要的一致性分类以及相互之间的关系。 一致性是系统实现“正确性”的基础,是系统需要协调的根本原因之一。实现这些一致性目标并不容易,追求系统的“正确性”同时实现系统其他设计目标,例如执行效率等是一个复杂的权衡与设计过程,虽然现在有了不少中间件产品可以使用,但是对于一致性的基本信息的了解也是十分重要的,对于开发者也是一个巨大的挑战,希望本文能给予大家一定的帮助。 参考资料: Paolo Viotti, Marko Vukolic Consistency in Non-Transactional Distributed Storage Systems Consistency models in distributed systems: A survey on definitions, disciplines, challenges and applications Werner Vogels, "Eventually Consistent", 2008. MAURICE P. HERLIHY and JEANNETTE M. WING,Linearizability: A Correctness Condition for Concurrent Objects Strong consistency models (aphyr.com) Haifeng Yu,Amin Vahdat, Design and evaluation of a conit-based continuous consistency model for replicated services https://doi.org/10.1145/566340.566342 Cheng Li†, Daniel Porto∗†, Allen Clement†, Johannes Gehrke‡, Nuno Preguic¸a∗, Rodrigo Rodrigues,Making Geo-Replicated Systems Fast as Possible, Consistent when Necessary S´ergio Esteves · Jo˜ao Silva · and · Lu´ıs Veiga,Quality-of-Service for Consistency of Data Geo-Replication in Cloud Computing? Lamport, Leslie (Sep 1979). "How to make a multiprocessor computer that correctly executes multiprocess programs". Fork Join Causal Consistency (FJC) Yu and Vahdat (2002) Design and Evaluation of a Conit-Based Continuous Consistency Model for Replicated Services lamport,Time, Clocks, and the Ordering of Events in a Distributed System Don't Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS (cmu.edu) Distributed Systems: Replication and Consistency Causal Consistency Prince Mahajan, Lorenzo Alvisi, and Mike Dahlin, Consistency, Availability, and Convergence amazon-dynamo Martin Kleppmann,A Critique of the CAP Theorem Session Guarantees for Weakly Consistent Replicated Data (cornell.edu) Distributed shared memory Michael Fischer,Nancy Lynch, Mike Paterson, Impossibility of distributed consensus withone faulty process (1985) 全序与偏序关系_Algorigoat的博客-CSDN博客_全序和偏序 条分缕析分布式:因果一致性和相对论时空