现代操作系统原理与实践02:硬件结构
目录
1 冯.诺依曼结构
1.1 中央处理单元
1.2 存储器
1.3 输入输出
2 CPU与指令集架构
2.1 指令集架构概述
2.2 ARMv8体系结构概述
2.2.1 ARMv8 SoC基本结构
2.2.2 指令集
2.2.3 特权级
2.2.4 寄存器
3 物理内存与CPU缓存
3.1 存储结构
3.2 缓存组成
3.3 缓存结构与寻址
4 设备与中断
4.1 CPU访问设备的方式
4.1.1 MMIO(Memory-Mapped IO)
4.1.2 PIO(Port IO)
4.2 CPU与设备交互的方式
4.3 AArch64中的异常与中断
4.3.1 通用概念
4.3.2 不同体系结构术语
4.4 AArch64异常分类
4.5 中断控制器演变
4.5.1 中断控制器要考虑的问题
4.5.2 SoC厂商实现
4.5.3 向量中断控制器VIC
4.5.4 通用中断控制器GIC
1 冯.诺依曼结构
从宏观上看,现在主流的计算机依然采用冯.诺依曼结构

1.1 中央处理单元
1. 中央处理单元(Central Processing Unit,CPU)主要负责运算和逻辑控制
2. CPU中包括处理单元和控制单元
1.2 存储器
1. 存储器(memory unit)负责存储程序指令和数据,以及保存程序执行的中间结果和最终结果
2. 在现代计算机中,存储器通常包括寄存器、CPU缓存、内存等存储层次
1.3 输入输出
输入输出(Input and Output,I/O)负责与外界进行交互,从外界获得输入,将结果向外界输出
说明1:冯.诺依曼结构工作原理
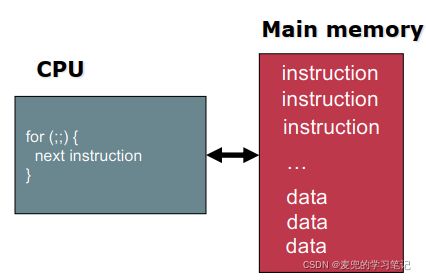
① 指令和数据均存储在内存中
② CPU逐条指令取指并执行
说明2:冯.诺依曼结构的局限
① CPU与内存交互引起的内存墙问题,即内存性能严重限制CPU性能发挥
② 数据与指令不区分,存在数据等指令或指令等数据问题
③ 串行数据处理,缺乏数据并行能力
这些冯.诺伊曼结构的局限,也是后续计算机体系结构改进的原因,例如
① 引入Cache以及存算一体化就是为了解决内存墙问题
② 在Cache层面,区分D-Cache和I-Cache,从而区分数据和指令
③ 引入SIMD指令,实现数据的并行处理
2 CPU与指令集架构
2.1 指令集架构概述
1. 指令集架构(Instruction Set Architecture,ISA)是CPU和软件之间的桥梁
2. ISA包括指令集、特权级、寄存器、执行模式、安全扩展、性能加速扩展等诸多方面
3. 指令集是ISA的重要组成部分,通常包含一系列不同功能的指令,用于数据搬移、计算、内存访问和过程调用等
说明:ARMv8体系结构有AArch64和AArch32两种执行状态,本课程中仅使用AArch64执行状态
2.2 ARMv8体系结构概述
本课程选择ARMv8体系结构作为实现平台,关于ARMv8体系结构的相关内容可参考如下笔记
ARMv8体系结构基础01:ARMv8体系结构简介_麦小兜的博客-CSDN博客
2.2.1 ARMv8 SoC基本结构
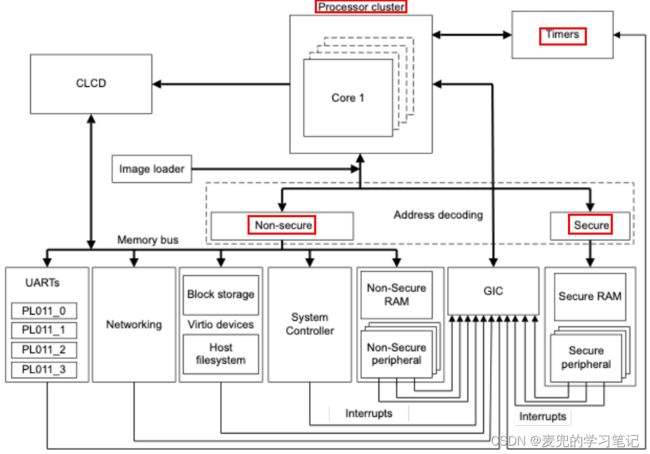
说明1:为何要将CPU组织为cluster
① 在SoC中,会根据功耗和性能的需求,将不同的性能的核放在不同的cluster,从而实现性能与功耗的平衡。在ARMv8体系结构中称作big.LITTLE技术,例如使用Cortex-A53(LITTLE cluster)和Cortex-A57(big cluster)构成2个cluster

② 在后续的SoC结构中,还引入了Big,Medim,Little结构
说明2:图中的Timers是CPU核心的arch timer(区别于外设timer),arch timer可用于调度和高精度定时
说明3:在Soc中,secure和non-secure部分有独立的资源,其中的secure部分就是trust zone
说明4:图中的GIC(Generic Interrupt Controller,通用中断控制器)对中断进行管理与路由
2.2.2 指令集
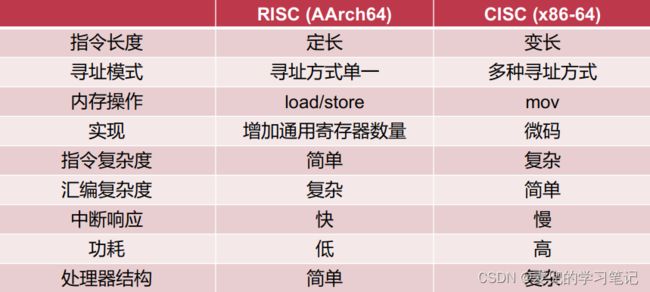
ARMv8体系结构属于RISC,其使用的指令集具有如下特点,
1. 固定长度指令格式
2. 更多的通用寄存器
3. load / store结构
4. 简化寻址方式
说明1:与X86-64体系结构的指令集对比
X86-64体系结构属于CISC,两种结构指令集对比如下
说明2:RISC & CISC指令集讨论
① 一个技术刚出现时,会有明显的界限。但是随着技术的发展,不同的技术路线会开始融合
② X86-64指令集是CISC的实现方式,但是在译码时会通过微码转换为RISC
③ RISC也会扩展自己的指令集,比如SIME、NEON和乘加指令,用于加速信号处理
2.2.3 特权级
2.2.3.1 特权级概念
AArch64中的特权级被称作异常等级(Exception Level,EL),共有4个异常等级

1. EL0:最低的特权级,应用程序运行通常运行在该特权级,因此也称作用户态
2. EL1:操作系统通常运行在该特权级,因此也称作内核态
3. EL2:在虚拟化场景下需要,虚拟机监控器(Virtual Machine Monitor,VMM,也称作Hypervisor)通常运行在该特权级
4. EL3:最高的特权级,和安全特性TrustZone相关,负责普通世界(normal world)和安全世界(secure world)之间的切换
说明1:关于TrustZone
① TrustZone从ARMv6体系结构开始引入
② TrustZone从逻辑上将整个系统分为安全世界和普通世界,计算资源可以被划分到这2个世界中
③ 安全世界可以不受限制地访问所有计算资源,而普通世界只能访问自己的资源
说明2:与X86-64体系结构的特权级对比
① X86-64体系结构为了支持虚拟化,引入了Root和Non-root两种模式,而每种模式中又分别具有Ring0 ~ Ring3的特权级
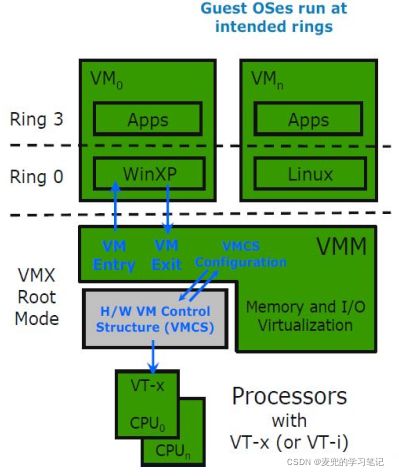
② 在Non-root模式下
Ring3运行Guest app,Ring0运行Guest OS
③ 在Root模式下
Ring3运行app,Ring0运行Hypervisor
2.2.3.2 特权级切换场景示例
CPU提供了4种特权级,也提供了在特权级之间切换的方法,此处以从EL0(应用程序)切换到EL1(操作系统内核)为例加以说明
从EL0切换到EL1,有如下3种场景
1. 应用程序调用系统调用
此时应用程序会通过SVC(supervisor call)指令从EL0切换到EL1
2. 应用程序触发异常(exception)
e.g. 应用程序运行时触发缺页异常,从而切换到内核态处理
3. 应用程序在执行过程中,CPU接收到来自外设的中断
说明:同步切换与异步切换
① 前2种场景称为同步特权级切换,因为这些切换都是由CPU正在执行的命令导致的
② 第3种场景称为异步特权级切换,因为这些切换与CPU正在执行的命令无关
2.2.3.3 特权级切换流程
下面以EL0和EL1之间的切换为例说明特权级切换流程,该流程由CPU和操作系统内核协同完成
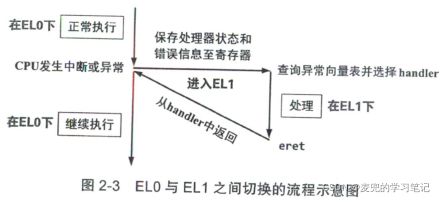
2.2.3.3.1 异常处理概述
1. 进入中断或异常时
① 保存处理器状态,以便之后恢复执行
② 准备好在高特权级下进行执行的环境(e.g. 异常等级切换、栈的切换)
③ 选择合适的异常处理代码进行执行
④ 确保用户态和内核态之间的隔离
2. 处理时
获取关于异常的信息,e.g. 系统调用参数、错误原因、导致缺页异常的地址等
3. 返回时
恢复处理器状态,返回低特权级,继续之前的执行流
说明:在AArch64中,中断和异常使用同一套机制处理
2.2.3.3.2 异常发生时保存信息
异常或中断发生时,CPU会将错误码和部分上下文信息存储在寄存器中
1. 处理器状态PSTATE保存在Saved Program Status Register(SPSR_EL1)中
2. 当前指令地址PC保存在Exception Link Register(ELR_EL1)中
3. 如果是Serror或异常,会将错误原因保存在Exception Syndrome Register(ESR_EL1)中
4. 如果是中断,则需要读取GIC中的寄存器,以确定触发中断的设备
说明1:根据不同的异常原因,CPU还会保存一些其他信息,供异常处理程序使用。例如对于缺页异常,会将导致异常的地址保存在FAR_EL1(Fault Address Register,错误地址寄存器)寄存器中
说明2:这里说明的都是CPU硬件保存的内容,所以是部分上下文信息。软件可以做进一步的信息保存,一般在操作系统的异常处理函数中进行
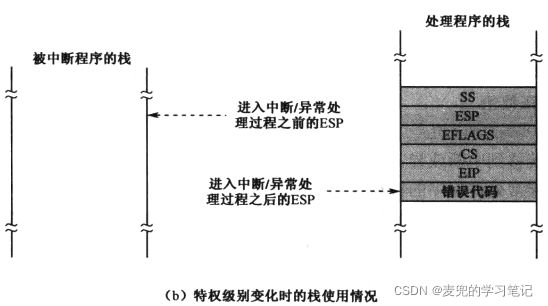
说明3:与X86-64体系结构相比,AArch64在异常处理时更少使用到栈,而是都保存在寄存器中,因此处理异常的速度更快
在X86-64体系中,如果处理中断时发生特权级切换,则会将之前使用的栈、EFLAGS、返回地址和错误代码都压入栈中
2.2.3.3.3 进入异常切换EL
1. 硬件会适当修改处理器状态PSTAE,从而进入EL1异常等级
2. 进入EL1异常等级后,栈指针SP会自动切换使用SP_EL1
3. 如需在EL1异常等级中使用SP_EL0作为栈指针,可配置SPSel寄存器实现
说明:在EL1异常等级中需要使用SP_EL0的原因
① 在有些场景中,在从EL0进入EL1时,有些状态保存在SP_EL0指向的栈中。在进入EL1之后,如果需要访问这些参数,则需要切换使用SP_EL0
② 联想一下X86体系结构中的调用门(call gate),可以在调用门描述符指定要拷贝的参数个数,当因为调用门导致特权级切换(从而导致栈切换)时,处理器会自动将原先栈中的参数拷贝到当前栈中
相关内容可参考如下笔记的chapter 2
X86汇编语言从实模式到保护模式16:特权级和特权级保护_麦小兜的博客-CSDN博客
2.2.3.3.4 寻找handler代码
1. 寻找handler代码需要使用异常向量表(Exception Vector Table),其中的每个表项是异常向量,是处理异常或跳转到异常处理handler的一小段汇编代码
2. AArch64中,除EL0之外的每个异常等级都有自己独立的异常向量表,而其首地址记录在VBAR_ELn寄存器中
说明1:AArch64中异常向量的选择由如下3个方面决定
① 异常类型(Synchronous、IRQ、FIQ、SError)
② 异常发生时CPU所处的异常等级
③ 异常发生时处理器的状态(使用的栈指针、处理器执行状态)
下图为EL1的异常向量表,
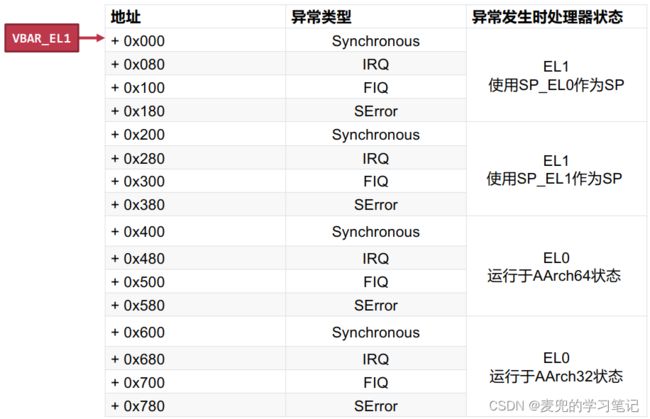
说明2:从异常向量表中可见,每个异常向量可以使用128(0x80)B的内存,因此和ARMv7相比,每个异常向量中可以处理更多的内容(ARMv7中每个异常向量只有4B内存,因此只能部署一条跳转指令)
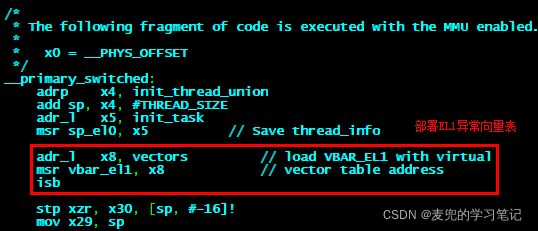
说明3:AArch64异常向量表实例
我们来看一下Linux 4.14内核中为AArch64实际部署的异常向量表
文件路径:arch/arm64/kernel/head.S
文件路径:arch/arm64/kernel/entry.S

我们以其中的Synchronous 64-bit EL0为例,此时应用程序在EL0 + AArch64状态下运行,同时触发同步异常(e.g. 缺页异常)
文件路径:arch/arm64/kernel/entry.S
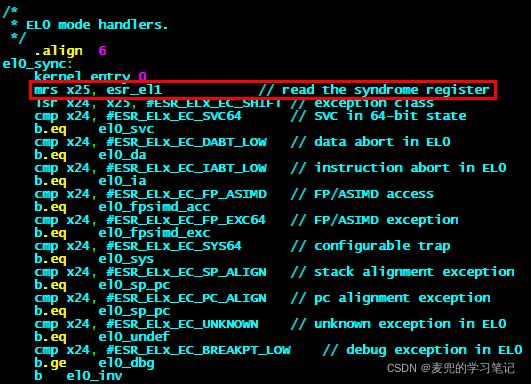
可见在el0_sync函数中,会根据ESR_EL1寄存器的状态,判断不同的异常原因,从而调用不同的处理函数
2.2.3.3.5 异常返回
通过eret(Exception Return)指令实现异常返回,在此过程中,
1. 将ELR_EL1恢复到PC,恢复PC的状态
2. 将SPSR_EL1恢复到PSTATE,恢复处理器状态
3. 异常等级降至EL0,CPU自动使用SP_EL0作为栈指针
之后便可恢复异常之前的执行流
2.2.4 寄存器
2.2.4.1 通用寄存器

AArch64提供31个通用寄存器,其中X29和X30有使用管理,
1. X29一般用于保存函数调用过程中栈顶的地址
2. X30一般用于保存bl指令的返回地址
说明:X86-64体系结构只有16个通用寄存器
2.2.4.2 特殊寄存器
AArch64提供的特殊寄存器如下,

说明:X86-64体系结构提供一个RIP(对应PC),一个RSP(对应SP_ELn)、一个EFLAGS(对应PSTATE)
2.2.4.3 系统寄存器
AArch64提供了众多系统寄存器,下面以EL1异常等级下的页表基地址寄存器(Translation Table Base Register,TTBR)为了加以说明
1. AAch64在EL1异常等级下共有2个TTBR寄存器,即TTBR0_EL1和TTBR1_EL1,他们负责翻译虚拟地址空间中不同的地址范围
2. 在操作系统的常见配置中,TTBR0_EL1负责翻译用户地址空间,虚拟地址范围为[0, 2^48);TTBR1_EL1负责翻译内核地址空间,虚拟地址范围为[2^48, 2^64),映射关系如下图所示
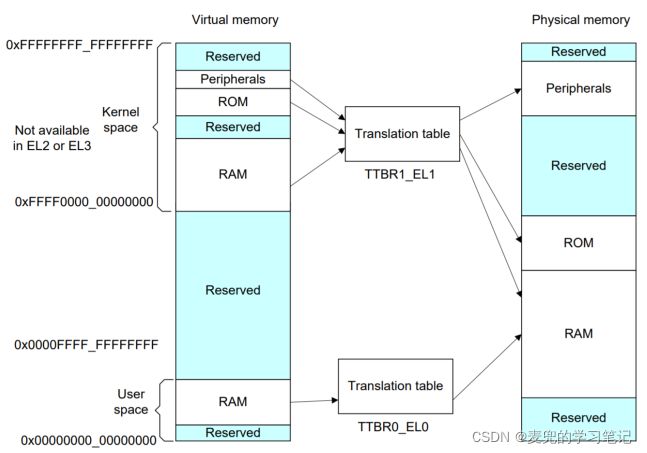
说明1:X86-64体系结构中只有一个页表基地址寄存器CR3
说明2:AArch64为何要在EL1异常等级设置2个TTBR寄存器
在操作系统中,内核态和用户态一般是在不同的虚拟地址空间的,如果只有一个TTBR,如果从用户态陷入内核态,就需要进行一次页表切换。随之而来的,TLB也会被刷新
如果不同特权级使用不同的TTBR,则无需这次页表切换,从而提升效率
说明3:在X86-64体系结构 + Linux内核的环境中,通过将内核页表映射到进程页表的高端地址部分,也避免了从用户态陷入内核态的页表切换
说明4:处理EL1异常等级,在EL2和EL3异常等级也有TTBR,这些TTBR构成的完整地址映射关系如下图所示
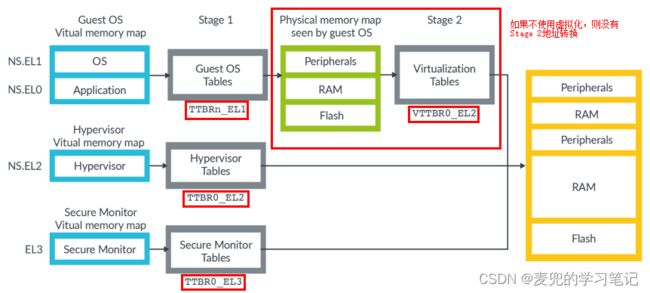
由于在EL2和EL3异常等级没有用户态和内核态区分的要求,所以只有一个TTBR寄存器、
3 物理内存与CPU缓存
3.1 存储结构
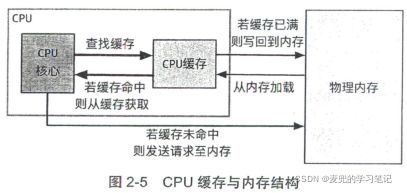
1. 从CPU的角度,可以将内存看作由字节组成的大数组,其中每个字节有一个物理地址
2. 为了降低CPU访问内存的开销,现在的CPU中都引入了缓存(cache),用于存放一部分物理内存中的数据
3. 当CPU需要写物理内存时,可以直接写在CPU缓存之中,之后在适当的时机再从缓存写入物理内存
4. 当CPU需要读物理内存时,可以先在CPU缓存中查找,如果找到,则可以很快获取数据;如果找不到,才访问物理内存,并且将获取的数据放入缓存中,以便下次读取时可以快速获取
5. CPU缓存的有效性基于局部性原理
说明:一条算术运算指令只需要一个或几个时钟周期即可完成,但是一次内存访问可能需要上百个时钟周期
3.2 缓存组成
1. 缓存由若干个缓存行(cache line)组成
2. 每个cache line包括,
① 一个有效位(valid bit),用于标识当前行是否有效
② 一个标记地址(tag address),用于标识当前cache line对应的物理地址
③ 一些其他状态信息
④ 实际存储数据的区域
3. CPU以cache line为单位,将物理内存中的数据读取到CPU缓存中;在将数据写回物理内存时,也是以cache line为单位
3.3 缓存结构与寻址
1. 首先需要注意的是,缓存寻址使用的是物理地址
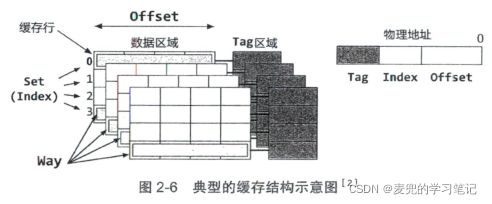
2. 缓存的寻址方式,是与缓存的组织方式有关的,上图中所述的缓存结构称为组相联模式,我们结合物理地址的划分进行说明
① 首先,物理地址被划分为Tag、Index(也称作Set)和Offset三段
② 物理地址的Index(Set)段表示的最大数目称为组
③ 同一组下,支持的最大Tag数称为路,即同一组下的cache line数目。上图中在Set相同的情况下,缓存最多支持4个Tag,也就是4路,所以该缓存结构称为4路组相联(4-Way Set Associative)
说明1:缓存寻址实例
以支持AArch64的Cortex-A57为例,该CPU的缓存参数如下,
① 物理地址的长度为44位
② 缓存大小为32KB,cache line大小为64B
③ 256组,2路组相联缓存
假设要访问的物理地址为0x2fbbc030

我们首先来分析一下这里物理地址的划分,
① 由于cache line为64B,所以Offset字段为6位,用于寻址这64B
② 由于cache为256组,所以Set字段为8位,用于寻址这256组
③ 其余的物理地址位均为Tag字段
接着我们来分析物理地址0x2fbbc030如何寻址cache
① Set字段为0,因此先索引到第0组
② 该组共有2路,因此通过Tag字段匹配,Tag字段为0xbeef,因此索引到相应的cache line
③ 该cache line的valid位为1,说明该cache line有效
④ Offset字段为48,因此从该cache line中获取偏移量为48的字节内容
说明2:操作系统和应用程序可以根据CPU缓存的特定对代码进行优化,从而更好地利用缓存提升性能
4 设备与中断
4.1 CPU访问设备的方式
4.1.1 MMIO(Memory-Mapped IO)
1. MMIO(Memory-Mapped IO)将设备内部的内存和寄存器和物理内存放在同一个地址空间,并为他们分配了物理地址
2. CPU通过设备内部内存和寄存器的物理地址访问和操作设备
3. CPU使用和访问物理内存一样的指令(ldr和str)访问设备
说明1:ARM体系结构中只支持MMIO方式访问设备
说明2:需要注意对MMIO访问的副作用
一般读内存不会改变内存中的数据,但是读MMIO可能会具有副作用,e.g.
① 对于读清的寄存器,读取MMIO会将其数据清零
② 对于某些外设的数据寄存器(e.g. 串口),读取数据后,数据寄存器中就是下一个待读取数据
4.1.2 PIO(Port IO)
1. IO设备具有独立的地址空间
2. 使用特殊的指令访问(e.g. X86体系结构中的in/out指令)
4.2 CPU与设备交互的方式
对于CPU如何获知设备有事件发生,有2种处理方式
1. 轮询(polling)
CPU不断通过MMIO访问设备的状态寄存器,判断事件是否发生
2. 中断(interrupt)
中断机制赋予设备通知CPU的能力,当设备发生事件时,通过中断打断CPU的执行,使得CPU去处理这个中断
说明1:中断机制除了使得设备能够主动通知CPU,还可以让一个CPU核去通知另一个CPU核,也就是核间中断
说明2:中断与轮询的使用场景
① 慢速设备使用中断较好,这样可以避免CPU在轮询过程中长时间处于忙等待状态。需要注意的是,这里的慢速是相对于CPU而言的,比如键盘、串口、显示器等
② 对于高速设备,比如万兆网卡,使用轮询更好,因为频繁的中断会导致操作系统大部分时间都在处理中断上下文的切换
因此在实际的网络设备驱动中,引入了NAPI框架,会议中断 + 轮询的方式实现CPU与网卡的通信
4.3 AArch64中的异常与中断
4.3.1 通用概念
1. 中断(interrupt)
① 外部硬件设备所产生的信号
② 与当前执行的指令异步
2. 异常(exception)
① 程序执行所产生的事件
② 与当前执行的指令同步
4.3.2 不同体系结构术语

4.3.2.1 AArch64异步异常
1. 重置(Reset)
① 最高级别的异常,用以执行代码初始化CPU核心
② 由系统首次上电或控制软件、Watchdog等触发
③ Reset异常向量并不在异常向量表中,而是存储在RVBAR_ELn寄存器中,其中n是芯片实现的最高异常等级
2. 中断(Interrupt)
① 由CPU外部的信号触发,打断当前执行
② 异常向量在异常向量表中
4.3.2.2 AArch64同步异常
1. 终止(Abort)
① 失败的指令获取或数据访问
② 如访问不可读的内存地址等
2. 异常产生指令(Exception generating instructions)
① SVC:用户程序调用操作系统提供的服务
② HVC:客户操作系统调用虚拟机管理器提供的服务
③ SMC:从normal world切换到secure world
4.3.2.3 X86-64体系结构术语
1. 中断(设备异步产生)
① 可屏蔽中断:设备产生的信号,通过中断控制器与处理器相连,可被屏蔽
② 不可屏蔽中断:关键硬件的崩溃,e.g. 内存校验错误
2. 异常(软件同步产生)
① 错误(Fault):如缺页异常(可恢复)、段错误(不可恢复)
② 陷阱(Trap):无需恢复,如断点(int 3)、系统调用(int 0x80)
③ 中止(Abort):严重的错误,不可恢复
4.4 AArch64异常分类
1. IRQ
普通中断,优先级低,处理慢
2. FIQ
① 一次只能由一个FIQ
② 快速中断,优先级高,处理快
③ 常为可信的中断源预留
说明:IRQ和FIQ均由中断控制器管理
3. SError(System Error)
① 原因难以定位、较难处理的异常,多由异步终止导致
② 如将数据从cache line写回内存时发生的异常
4. Synchronous
① 同步异常
② 由软件执行指令时触发
4.5 中断控制器演变
4.5.1 中断控制器要考虑的问题
1. 如何汇集各种设备的中断
2. 如何指定不同中断的优先级(是否支持中断嵌套)
3. 将中断交给哪个CPU核处理
4. 如何与软件协同
4.5.2 SoC厂商实现
早期将中断路由给处理器的功能由SoC厂商实现

4.5.3 向量中断控制器VIC
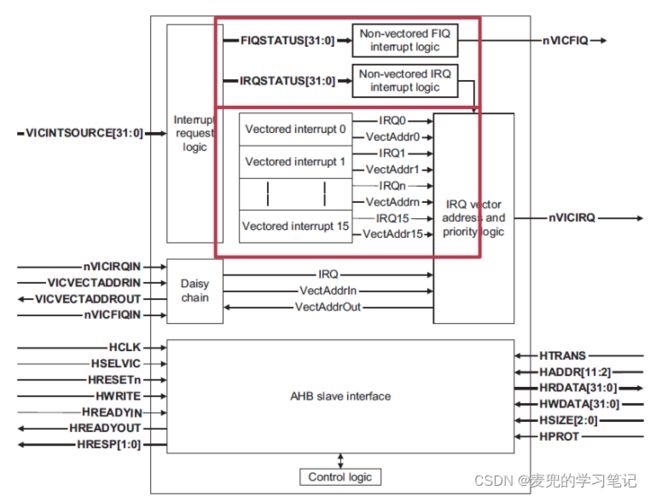
1. 向量中断控制器VIC(Vector Interrupt Controller)由ARM提出,与AMBA总线连接
2. 在早期配置中,提供32种非向量中断和16种向量中断
说明:非向量中断和向量中断
① 非向量中断:不同中断有相同的处理入口
② 向量中断:不同中断有不同的处理入口
4.5.4 通用中断控制器GIC
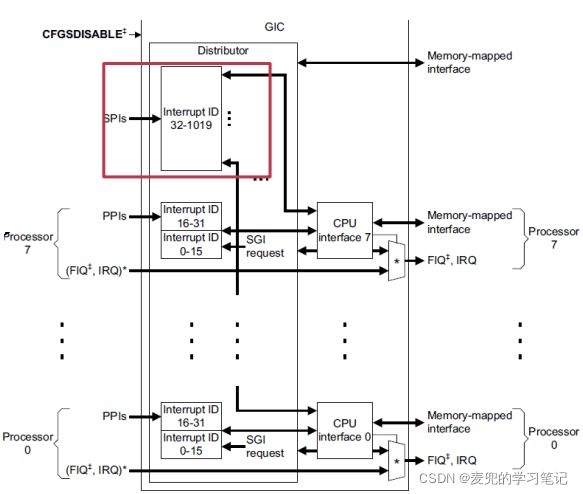
1. 引入GIC(Generic Interrupt Controller)是因为外设越来越多,CPU核也越来越多
2. GIC的主要功能
① 分发:管理所有中断、决定优先级、中断路由
② CPU接口:与每个CPU核有对应的接口
3. GIC中断来源
① SPI:共享外围中断
- 可以被路由到一个或多个CPU核处理
- 中断ID为32 ~ 1019
- 示例:UART中断
② PPI:私有外围中断
- 指定CPU核处理
- 中断ID:16 ~ 31
- PPI中断ID是私有的
③ SGI:软件产生中断
- 一般用于核间通信
- 中断ID:0 ~ 15