BEVFormer论文解析
1、背景
跟基于雷达的相比,纯视觉的方案成本低,而且具有RGB和纹理信息,可以用于检测像交通信号灯、车道线等道路要素。
自动驾驶的感知本意是要从多个摄像头给出的2D信息来预测3D bbox(检测)或者semantic map(分割),最直接的方案是基于单目的框架或者加入跨相机的后处理,这种方案的缺点是单独去处理不同的视图,而且不能捕获那些跨视图的信息,因此效果差。
相比于单目框架,更加统一的方案是从多相机图像中提取整体的表示,BEV是一种通用的表示,因为BEV可以清楚地显示物体的位置和尺寸,适用于各种自动驾驶的任务,不仅是感知还有规划。这种方案的缺点是精确的3D目标检测结果对BEV特征的质量要求高,但是目前从2D平面来生成BEV很不稳定。目前主流的生成BEV特征的框架是基于深度信息的,对深度值或者深度分布的准确程度很敏感,这样一来就导致了基于BEV的检测方法受到复合误差影响大,导致后续的检测结果也很差。
因此作者想提出一种不依赖深度信息,能够自适应的融合有价值的特征而不强依赖于3D先验(深度信息)来生成BEV特征的方法,因此想到了Transformer。
BEV的第二个优点是BEV可以用于连接时间和空间信息。对自动驾驶而言,时间信息也是很重要的(用于判断运动状态和遮挡),不是单单定位物体然后分类进行检测就完事了。
本文三个贡献:
- 提出了BEVFormer,一个时空transformer编码器。也就是又利用时间信息,又利用空间信息的一个基于transformer的编码器,注意只是编码器没有解码器。可以将多相机的图像和时间戳信息投影到BEV表示,然后借助这种统一的BEV表示,可以在(BEV特征)上面进行3D检测和语义分割等各种自动驾驶的感知任务。
- 设置了可学习的BEV query以及空间交叉注意力层和时间自注意力层,实现了从跨摄像机(对应空间)和历史BEV(对应时间)中查询(transformer中query的抽象操作)空间特征和时间特征,然后把他们统一聚合成BEV特征
- 实验结果balabala……具体来说,在自动驾驶3D检测和地图分割任务都达到了SOTA(证明了生成的bev feature真的很厉害)
2、相关工作
2.1 基于Transformer的2D感知
近年一个新的趋势是利用Transformer来制定新的检测和分割任务处理范式,比如detr。但是detr训练太慢了。Deformable DETR通过可变形的注意力改善了这个缺点,在BEVFormer中,作者把Deformable DETR扩展到3D感知任务中,来有效地聚合空间和时间信息。
2.2 基于相机的3D感知
早期的3D检测方案一般类似2D的检测,直接基于2D的bbox来预测3D的bbox。另一种方案是把2D的图像特征转化为BEV feature然后在BEV中预测3D bbox。这种方案的核心是2D到BEV的转化方法,一般是利用深度估计或深度分布来实现。
在地图分割任务里,2D到BEV的转化研究工作更多。比如用逆透视映射(IPM)将透视图转换为BEV,还有著名的LSS基于深度分布生成BEV特征,还有用MLP来学习从透视图到BEV的变换。也有用transformer将前视单目图转化为BEV,但是这种方法用全局注意力,不适合拓展到多摄像机的情况,计算成本太高。此外,也有考虑空间信息的,但是之前的工作固定地堆叠多个时间戳的BEV特征,计算成本太高。本文BEVFormer综合考虑时间和空间信息生成当前时间的BEV,并且通过RNN的方法从之前的BEV中获取
3、 BEVFormer算法解析
3.1 整体框架

整个pipeline为:
首先把6个摄像机的图片全都经过backbone+neck进行2D特征提取,这个没什么好说的,重点是中间部分,也就是真正的BEVFormer部分:
这是一个编码器encoder,总共有6层,这个6遵循vanilla transformer,跟摄像机个数无关。结构也完全遵循原本的transformer,除了三块内容有变动,一个是新设计的BEV queries,一个是spatial cross-attention, 一个是temporal self-attention。
- 首先BEV queries是网格形状的可学习参数,目的是用来通过注意力机制去从不同相机视图里查询BEV特征;
- spatial cross-attention也就是空间交叉注意力层用于根据BEV query来查找多相机图像里的空间信息;
- temporal self-attention也就是时间自注意力层用于根据BEV query聚合历史BEV的时间特征。
在infer阶段,首先把当前帧的多摄像机图像送入backbone进行特征提取,然后网络实际上会保留前一阵的BEV特征,在每个encoder layer(total=6),会先用BEV queries通过时间自注意力查询时间信息,然后再用BEV queries通过空间交叉注意力从多相机特征中查询空间信息,最后经过ffn输出细化的BEV feature送入下一层encoder layer,堆叠6层最后生成当前帧的统一BEV feature,送入下游任务头(检测头/分割头)
3.2 BEV query
这个BEV query有点类似feature map,实际上是一个[H, W, C]的tensor,但是划分成了[H, W]大小的一个网格,那么网格上坐标为(x, y)的每一块[1, C],实际上就对应着BEV平面中的一块区域。
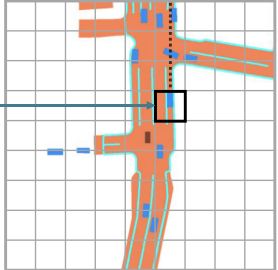
BEV平面的每一块区域实际含义就是真实场景鸟瞰图下s平米的一块区域。注意BEV的中心一般都是车辆自身的区域。
跟常规的transformer一样,这个BEV query里也有可学习的位置嵌入(positional embedding)
3.3 Spatial Cross-Attention
因为多摄像机输入规模大(图多,size一般也大),因此用基于可变形注意力的空间交叉注意力而不是普通的多头注意力。为了适配3D感知,把原本BEV平面上的每个query都lift到柱状的一个query(多了z),然后从这个柱状的query里采样N个点,再把这N个点投影到2D视图上,每个点对应可能只能投影到部分视图,而在其他摄像机里没有拍到这个点的内容,因此这就是一种空间注意力操作,最后把能投影到的2D点从对应所在的视图里进行特征的采样,然后加权求和最终成为空间交叉注意力的输出。
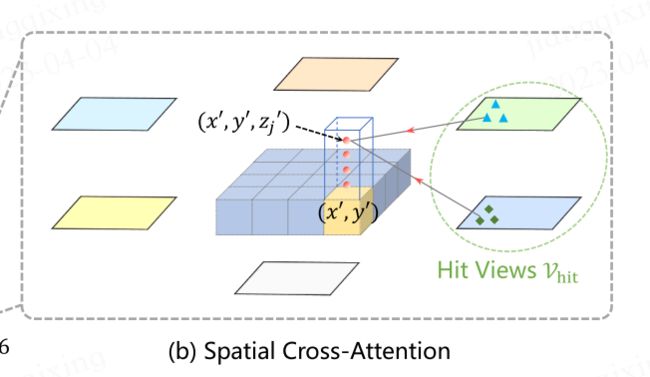

SCA代表spatial cross-attention
那么具体怎么进行3D query采样的点投影到2D视图上的呢?
首先对于BEV平面上(x,y)位置的一个query,我们可以计算出它在真实世界中的(x',y')二维坐标:
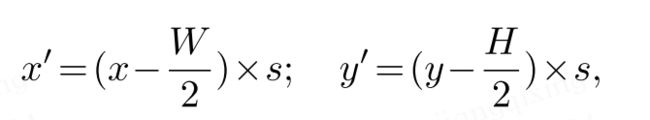
W,H是BEV queries的尺寸,s就是BEV网格的分辨率。(x',y')的实际含义就是以车本身为原点的3D坐标系里的位置,因为3D坐标系里的每个位置还应该有z',因此预定义一系列离散的z'点,那么每个点都有自己的z'_i,即自己的一个高度。最后利用相机投影矩阵(内外参)T(3*4矩阵)把3D参考点j(x', y', z'_j)投影成第i张图里的点P(x,y)
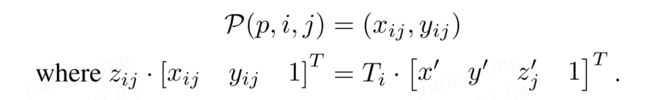
注:作者在附录中提到,这里原本是可以用全局注意力,即让每个bev query都跟所有相机的feature 进行交互,但是这样做的计算成本实在是太高了,所以才转而考虑利用每个相机的内外参,使用可变形注意力来得到每个BEV query对应的某些“值得”做交互的相机视图,而不是所有相机视图。这样做的缺点就是导致精度跟内外参也就是相机标定有关联,用全局的鲁棒性肯定是更高的,因为无视相机内外参,但是实在是没办法承受全局注意力的计算成本。
3.4 Temporal Self-Attention
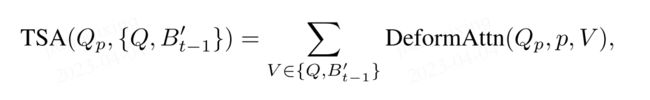
Q_p代表着位置为(x,y)的BEV query,这个Q_p会跟当前帧的BEV query Q concat 历史的BEV feature B'_t-1的结果进行“自注意力操作”,通过这种变式,相当于从B'_t-1中带入了时间信息。其中t跟t-1的差值△t是由TSA预测的,因此能实现自适应的注意力操作,而不是无脑堆叠多个BEV特征来融合。
实际代码实现中,先把BEV query、BEV position embedding等参数送入Temporal Self-Attention中,输出BEV query,然后再把BEV query送入Spatial Cross-Attention得到bev_embedding即BEV特征