数据流图例子_探索数据流架构模型的潜力

众所周知,当代通用处理器(CPU)的设计重点早已从加速数据计算单元(ALU)架构转移到full-time指令驱动方向上。换句话说,冯诺依曼计算体系当中,最核心的之一便是指令驱动运算。如何能够满足主频运行条件下,指令一直在驱动执行而不受到间断(stall),便是高性能处理器一直以来发展的方向。基于此背景,许多研究人员在此做了很多工作,如超标量,超长指令字,动态调度算法,指令预取等等。这些技术对于当代处理器有着很大的性能开销。总结起来,主要由两个方面的原因:1、动态分析数据之间的依赖关系 2、维持正确的状态运行 (思考tomasulo算法结构)。众所周知,曾经在20世纪80年代左右提出的数据流架构能很好地解决以上问题,但是经过数十年的发展,数据流架构仍然没有受到主流的关注。其原因在于两个原因,其一是如何进行有效地数据控制猜测,另一个是显式数据交流上的延迟开销。值得思考的是,这些问题只对于某一部分代码存在以上问题。一个自然的思路便是能否在通用处理器上同时存在两种执行架构,既可以兼顾通用型乱序发射处理器的优点,也可以运算数据流处理器。对于这个方向,在UW-Madison大学提出了显示数据流架构(SEED),这篇文章,主要探讨一下对于这个架构的优势分析。
首先介绍一下传统的冯诺依曼架构(也可以称为“控制流”)当中,有哪些种提升能效的方法。主流的方案有两种方法,其一是在部分代码区采用低功耗的简单序列化硬件去实现低功耗来提升能效,比如(bigLITTLE方案和Compsoite方案)。另外一种是采取循环执行技术,比如(Revolver技术)。上述技术和方案都是控制流方案中经典的设计方案。他们当中有着加速效果不明显(前者)或者实现硬件成本高昂(后者)的劣势。那么显式数据流架构便应运而生,例如其中早期的架构比如标记令牌数据流,以及最近的TRIPS,WaveScalar,Tartan架构。但是数据流架构一直没有称为常规的考虑方案实际上也存在不少原因,数据流架构方案一直对于高层次指令之间的并行没有提供合理的方案,以及对于非常规的代码,他们的高性能低功耗仍然无法实现。那么如何将冯诺依曼架构与数据流架构结合起来,便是一种新的思考方案。本文提出得SEED架构是探究显式数据流与冯诺依曼架构之间得结合探索。从TOP来看,它的架构如下:
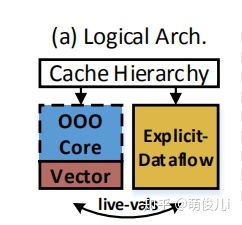
看到这里,很多小伙伴们已经迫不及待地想具体地看一下图A架构的具体实现方案了。不过在正式给出方案架构之前,我们再次考虑以下三个问题,用以确保开发一个冯诺依曼架构和数据流架构结合的目标或者说方向是有意义的:
- 设计方案是否满足高能效与低功耗?
- 是否能够满足通常情况下的工作负载?
- 两个部分的通信成本如何?
接下来带着这三个问题,我们一起探索SEED( Specialization Engine for Explicit-Dataflflow)架构设计。
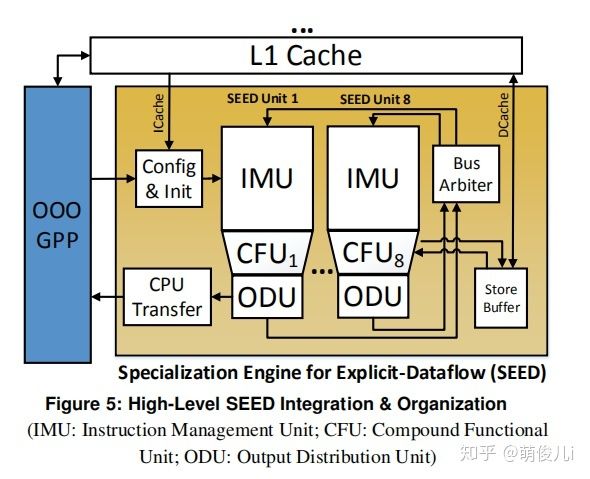
看到这里,是不是感觉很迷糊?接下来,我们分别探讨微架构的组成部分,最后,我们用一个例子来完成程序在微架构中的数据流向。这个架构实现了指令的高度并行和简化的分布式计算单元。总体设计有8个SEED组成,每个SEED单位周围配置一个CFU单元,SEED单元通过网络进行通信。
- 复合功能单元CFU(Compound Functional Unit )内部架构如下:
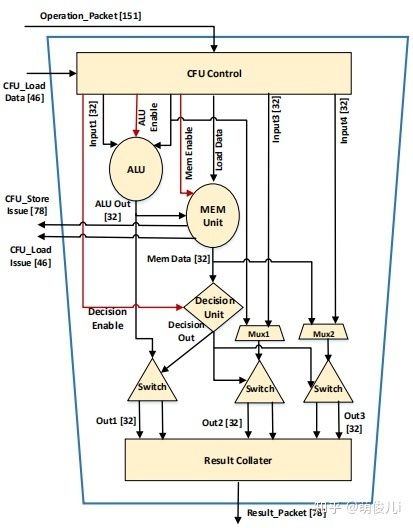
整体上来看,CFU基本上由FU的固定网络组成(加法器,乘法器,逻辑单元,开关单元等),CFU将程序中未使用的模块进行旁路停用。这样的做法可以缓冲长等待时间的指令(例如负载),CFU将支持现在已有的方案中的2-5个操作。我们目前设计嵌入整数硬件,但浮点(FP)单元可以通过实例化新硬件或通过SIMD单元进行运算。在CFU中设置了内存管理单元(Mem_Unit),该单元的功能是向主机的内存管理单元发出load 和store指令请求,用于保证使用SEED时处于活动(active)状态。
- 指令管理单元Instruction Management Unit (IMU)的内部架构如下:

从图中可以看出IMU的五个核心模块为指令存储单元ISU,目的存储单元DSU,操作存储单元OSU,指令就绪逻辑IRL,指令选择逻辑ISL,上述模块共同完成了三个IMU的核心功能:
1.存储指令,操作数和目标地址:IMU具有32个复合指令的存储位置,每个操作数最多包含四个操作数,并且我们为四个并发循环迭代保留操作数存储空间。这样可以存储2600字节的数据。八个SEED单元中的所有IMU总共具有约20KB的存储空间。静态指令存储量大约等于1024条非复合指令的最大值。
2.触发指令(Firing Instruction):IRL单元监视操作数存储单元,并选择一条最早的就绪指令(当所有操作数可用)进行发射,然后,复合指令及其操作数和目的地将发送到CFU。
3.定向输入值:输入控件从网络提取值并根据指令的标签存到适当的位置。
IMU的主要独特功能是它允许“展开”操作数存储循环的四个迭代。这个操作使得指令直接与从属指令进行通讯,而无需使用耗电的标签匹配CAM每个执行节点的结构。
在图A中,还有一个结构是ODU(Output Distribution Unit)输出分配单元。 该单元的主要功能是负责分配输出值和目标数据包(SEED单元+指令位置+迭代偏移),到总线网络,并在总线冲突期间对其进行缓冲。
那么以上三个部分的整体SEED的架构设计图为:

看到这里,相信大多数同学的想法和我一样,这个架构的基本组成已经理解了,可是对于某一程序,数据的流动方向与硬件的交互应该是如何进行呢?程序是如何和这个SEED架构结合起来的呢?接下来将以一个例子为读者介绍SEED的运行方案。
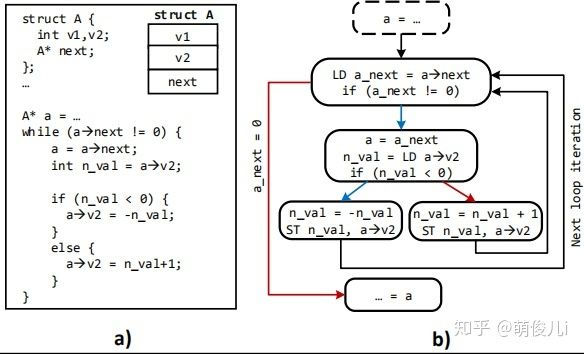
左图A是一个链表遍历的C程序的核心部分,相信能读到这里的同学们都应该会理解。右侧是图A对应的控制流图(也就是高中常遇到的程序流图)。上述程序在SEED中数据流架构的执行方式为:

SEED的运算规则同样遵循数据流的“点火规则”,指令在操作数就绪时候执行。为了初始计算的开始,发送一个初始的值意味着开始执行,在数据流的执行期间,无论是在同一个迭代还是在后续的迭代中,运行每条指令将其的输出转发至相关的指令。控制流策略指令之间的控制依赖关系转换为数据依赖关系。SEED使用切换指令(switch节点)根据输入控制信号将控制或数据值转发到两个可能的目标之一。在该示例中,根据n_val与0的大小比较结果,将v2转发到if或else分支。该策略使控制等效同时产生的区域。
这里还有一个之前提到过的“复合指令”,这个复合指令在图C中便可以体现出来。为了减轻通信开销,编译器(编译器设计这部分省略,如有兴趣,欢迎参考原文)将原始指令分组(例如添加,移动,切换等)构成子图并执行。这里我们可以看出,每个子图所含有的硬件资源是相同的(画圈的部分SubGraph),这就意味着可以将其mapping至相同功能得FPU上,所以这里一共使用了两个FPU就可以完成四个子图得操作。这是依靠FPU的单元完成的运算。
直到这里,SEED的核心架构设计部分就基本上完成了。但是有一个重要的问题,程序运行的时候,何时利用SEED运行,何时利用通用处理器进行运算呢?这两者之间的交互是如何进行的呢?答案是:编译器进行。编译器通过对于SEED部分运行的代码设置SEED_CONFIG的开始准备标志,该指令指示SEED单元开始配置阶段。第二条添加的指令SEED_BEGIN是一种条件分支,将控制转移到SEED(如果有)预计运行足够长的时间以减轻开销。这个指令从GPP寄存器发出实时值传输信号。配置阶段此阶段填充指令和特定区域的目标存储单元,以及初始化操作数存储区中的所有循环不变常量单元。通过指令缓存读取配置数据,并流到每个IMU。配置存储后,可以发送“实时”数据包以启动数据流计算。运行的时间是通过编译器的算法(平均时间)进行预测的。
- SEED编译器
这个部分有些复杂,编译器的主要任务是确定将程序中的哪些区域(完全内联的嵌套循环区域(利用循环嵌套树自顶向上遍历(我的知识盲区-.-求编译大佬)))专门用于SEED架构进行运算处理并调度处理指令到FPU。指令调度部分是如何形成复合指令,这部分直接影响FPU运算的效果。
- 效果评估
为了验证SEED+VONM的架构是高效的,选择的基准是来自SPECint和Mediabench ,代表各种控制和记忆异常,以及一些常规基准。
自然,根据实验得到的效果图,运行了当下较为主流的测试程序,他的运行结果是这样的:
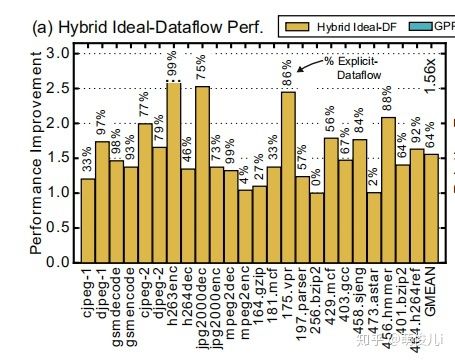
从图中可以看出结果,大约占据了65%的时间。证明还是具有非常高的占用比。
- 面积:
做计算机体系结构的经常忽略面积这重要的一项,好在本文的作者并没有忽视。在Verilog中实现了SEED体系结构,并使用32nm的设计进行了综合Synopsys设计编译器提供了标准单元库。CACTI 用于估计SRAM面积。结果表明,每个SEED单元都占据了合理的面积,SEED的所有八个单元和总线仲裁器一起占据一个区域0.93平方毫米

总结:
本文通过探索数据流架构方案设计与传统冯诺依曼结构的结合对于核心的运行的影响。总体而言,在数据流研究的背景下,该工作已经显示了传统的Von Neumann OOO和显式数据流体系结构如何支持不同的工作负载属性,并且与单独的两种执行模型相比,细粒度的交错可以提供显着且可实现的收益。这种新型的方案架构设计能给我们今后的设计带来一定的新思路。
Reference:
Tony Nowatzki, "Exploring the Potential of Heterogeneous Von Neumann/Dataflflow Execution Models" , ISCA ’15, June 13 - 17, 2015, Portland, OR, USA