从从协方差的误差椭圆到PCA
参考博客:如何绘制协方差误差椭圆
PCA-特征提取
1.误差椭圆的介绍
误差椭圆是代表高斯分布的等值轮廓线,并允许可视化一个2D置信区间,下图正态分布样本数据为95%置信椭圆:

下面主要介绍椭圆的长轴,短轴,置信度以及椭圆的旋转角度的由来。
2.轴对齐的置信椭圆
先看一种特殊的误差椭圆,轴对齐的置信椭圆,即各个维度之间是独立的,协方差为0的误差椭圆。
协方差为:

误差椭圆为:
椭圆的方程式定义如下:
( x a ) 2 + ( y b ) 2 = 1 (\frac{x}{a})^2 + (\frac{y}{b})^2 = 1 (ax)2+(by)2=1
误差椭圆定义为
( x σ x ) 2 + ( y σ y ) 2 = s (\frac{x}{\sigma_x})^2 + (\frac{y}{\sigma_y})^2 = s (σxx)2+(σyy)2=s
σ x 与 σ y \sigma_x与\sigma_y σx与σy分别代表x和y的标准差,s与置信度有关。
95%的置信水平对应于s =5.991。(详情参考卡方分布表)
3.任意置信椭圆
数据之间存在相关的情况下存在写放擦汗,所产生的误差椭圆不会是轴对齐的。椭圆以x轴为基准,发生逆时针旋转,旋转的角度定义为 α \alpha α

我们这里可以直观的感觉到,误差椭圆的长短轴方向应该是协方差的特征向量的方向,大小等于特征值。
因为我们知道特征向量之间是正交的,而且特征值的大小表示在对应特征向量上的能量大小,感兴趣可以参考花了10分钟,终于弄懂了特征值和特征向量到底有什么意义
所以误差椭圆定义为
( x λ 1 ) 2 + ( y λ 2 ) 2 = s (\frac{x}{\lambda_1})^2 + (\frac{y}{\lambda_2})^2 = s (λ1x)2+(λ2y)2=s
95%的置信水平对应于s =5.991。那旋转角都怎么算呢?
为了获得椭圆的方向,我们简单地计算最大特征向量的角度

可以参考
向量能不能相除?
4.PCA的介绍
PCA即主成分分析(principal component analysis)
1.线性变换,变换到原来空间的子空间;
2.应用特征向量,选取正交特征,去相关。
我们知道高维数据意味着更多的参数,更复杂的模型,很容易过度拟合,所以应该选择我们需要的特征保留,舍弃不需要的特征。
5 PCA-从去相关到降维
通常数据都是相关的,也就是数据的各个维度并不独立,导致各维度之间有或强或弱的相关性。直接删除一个维度,舍弃此维度的特征往往不可取,因为它隐含消去了其他维度的分量。我们可以去相关。
考虑下面二维特征空间的例子:
x1N(0,1)和x2N(0,1),x1,x2相互独立
{ x = x 1 + x 2 y = x 2 − x 1 \begin{cases} x = x_1 + x_2\\ y = x_2 - x_1\\ \end{cases} {x=x1+x2y=x2−x1
协方差
∑ = [ 2 2 2 2 ] \sum= \begin{bmatrix} {2}&{2}\\ {2}&{2}\\ \end{bmatrix} ∑=[2222]
s=时的误差椭圆的长轴与短轴,
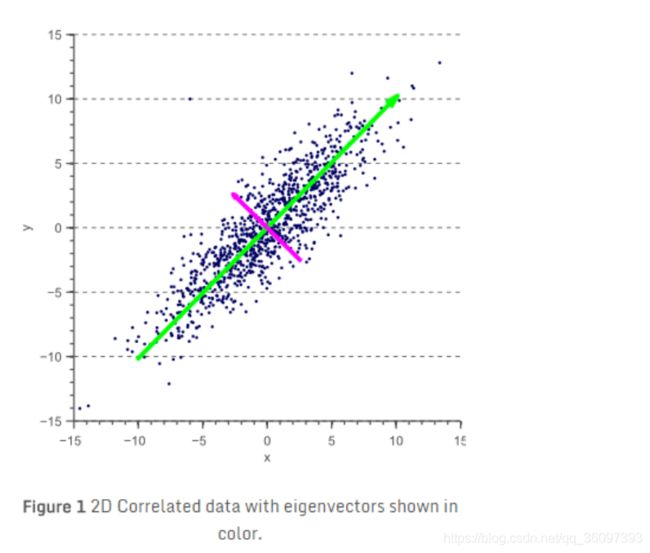
借助代码,我们算一下特征向量和特征值
import numpy as np
#A = np.array([[16.7,14.94],[14.94,17.27]])
#A = np.array([[3,-1],[-1,3]])
A = np.array([[2,2],[2,2]])
print('打印A:\n{}'.format(A))
a,b = np.linalg.eig(A)
print('打印特征值a:\n{}'.format(a))
print('打印特征向量b:\n{}'.format(b))结果

特征值从大到小排列,则由特征向量组成的特征矩阵为:(每列表示一个特征向量)
V = [ 0.7071 − 0.7071 0.7071 0.7071 ] V= \begin{bmatrix} {0.7071}&{-0.7071}\\ {0.7071}&{0.7071}\\ \end{bmatrix} V=[0.70710.7071−0.70710.7071]
V是旋转矩阵, t a n ( α ) = 0.7071 / 0.7071 = 1 tan(\alpha) = 0.7071/0.7071 =1 tan(α)=0.7071/0.7071=1,坐标系逆时针旋转45度得到新的坐标系x’ 和 有 y’,


特征向量空间下的特征是正交的,未知的,换言之是不相关的,这时候想要降低维度只需按照需求删除x’或者y’.
在上述例子中,我们以一个二维问题开始。如果我们想降低维数,问题仍然是是否消除x1(x’)或y1(y’)。尽管这样的选择可能取决于许多因素,如分类问题的数据可分性,但是PCA简单地假定最有趣的特征具有最大方差。这种假设是基于信息论的角度,由于最大方差的维对应于最大熵的维,编码了大部分信息。最小的特征向量将简单地表示噪声成分,而最大的特征向量往往对应于定义数据的主要成分。
由主成分分析降低维数,然后投影数据到协方差矩阵的最大特征向量上。对于上面的例子,所得到的一维特征空间如图3所示:

显然,上面的例子很容易推广到更高维的特征空间。例如,在三维情况下,我们既可以将数据投影到两个最大特征向量定义的平面来获得2D特征空间,也可以将其投影到最大特征向量来获得1D特征空间。结果示于图4:

Figure 4. 3D data projected onto a 2D or 1D linear subspace by means of Principal Component Analysis.
一般情况下,主成分分析使我们获得原始N维数据的一个线性M维子空间,其中M小于等于N。此外,如果未知,不相关的成分满足高斯分布,则PCA实际上充当了独立成分分析的角色,因为不相关的高斯变量在统计上是独立的。但是,如果底层成分不是正态分布,PCA仅仅产生去相关的变量,这些变量不一定是独立的。在这种情况下,非线性降维算法可能是一个更好的选择。
参考为什么随机变量X和Y不相关却不一定独立?
6. PCA-正交回归方法
在上述的讨论中,我们以获得独立成分(如果数据不是正态分布,至少是不相关成分)为目标来减少特征空间的维数。我们发现,这些所谓的“主成分”是由我们数据协方差矩阵的特征值分解获得的。然后将数据投影到最大特征向量从而降低维数。
现在,我们不考虑找不相关成分。相反,我们现在尝试通过找到原始特征空间上的一个线性子空间来实现降维数,我们可以将我们的数据映射的这个子空间上使得映射误差最小化。在二维情况下,这意味着我们试图找到一个向量,映射到这个向量上的数据对应于一个映射误差,而这个误差比任何其他可能向量所映射数据的映射误差低。接下来的问题是如何找到这个最佳向量。
考虑图5所示的例子。三种不同的映射向量,以及所得到的一维数据。在接下来的段落中,我们将讨论如何确定哪些映射向量最小化映射误差。在寻找这个向量之前,我们必须定义这个误差函数。
 这部分参考 PCA-正交回归方法与PCA实际应用:特征脸,PCA配方,PCA陷阱
这部分参考 PCA-正交回归方法与PCA实际应用:特征脸,PCA配方,PCA陷阱