弱监督目标检测算法论文阅读(二)Rethinking the Route Towards Weakly Supervised Object Localization
个人阅读文章的一点理解,有其他不同理解的同学问欢迎评论交流。
这是南京大学一篇CVPR2020的文章,论文提出了一个伪监督目标定位的方法,生成伪grountruth 进行训练。文章分析了现有的目标检测方法的弊病,联合优化定位与分类并不能两者达到最优。文章创造性的提出了把分类任务和定位任务分开,单独进行训练,取得了很好的效果。

Abstract
弱监督对象定位(WSOL)旨在仅使用图像级标签来定位对象。 先前的方法经常尝试利用特征图和分类权重来间接使用图像级注释来定位对象。 在本文中,我们证明了弱监督的对象定位应该分为两部分:与类无关的对象定位和对象分类。 对于与类无关的对象定位,我们使用与类无关的方法生成有偏差的伪标注(noisy pseudo annotations),然后在没有类标签的情况下对它们执行边界框回归。 我们提出了伪监督对象定位(PSOL)方法作为解决WSOL的新方法。 我们的PSOL模型在不同数据集之间具有良好的可传递性,而无需进行微调。 使用生成的伪边界框,我们在ImageNet上实现了58.00%的定位精度,在CUB-200上达到了74.97%的定位精度,这比以前的模型有很大进步。
Introduction
首先了解什么是DDT (deep descriptor transformation):
链接: https://www.cnblogs.com/walter-xh/p/11011571.html
简单的来说DDT就是从很多张包含同一类的图片中,定位到每张图片中这个物体。是一种无监督定位的方法。
在本文中,通过消融研究和实验,我们证明了WSOL的定位部分应与类别无关,与分类标签无联系。 基于这些观察,我们提倡一种模式转换,它将WSOL分为两个独立的子任务:与类无关的对象定位和对象分类。 我们的方法的总体流程如图1所示。我们将此新颖的流程命名为“伪监督对象定位”(PSOL)。 我们首先根据类不可知方法深度描述符变换(DDT)生成伪groundtruth边界框。 通过对这些生成的边界框执行边界框回归,我们的方法消除了对大多数WSOL模型的限制,包括仅允许一个完全连接的层作为分类权重的限制以及分类和定位之间的困境。
 我们结合了这两个独立子任务的结果,在ImageNet-1k和CUB-200上实现了最高的性能,与以前的WSOL模型(尤其是在CUB-200上)相比,取得了很大的优势。 根据最新的EfficientNet模型的分类结果,我们在ImageNet-1k上实现了58.00%的Top-1定位精度,这大大优于以前的方法。
我们结合了这两个独立子任务的结果,在ImageNet-1k和CUB-200上实现了最高的性能,与以前的WSOL模型(尤其是在CUB-200上)相比,取得了很大的优势。 根据最新的EfficientNet模型的分类结果,我们在ImageNet-1k上实现了58.00%的Top-1定位精度,这大大优于以前的方法。
主要贡献有以下几点:
1、弱监督的对象定位应该分为两个独立的子任务:与类无关的对象定位和对象分类。 我们提出PSOL来解决以前WSOL方法中的缺点和问题。
2、尽管生成的边界框有误差,但我们在不使用类标签的情况下直接对其进行优化。 通过提出的PSOL,我们在ImageNet-1k上实现了58.00%的Top-1定位精度,在CUB-200上实现了74.97%的Top-1定位精度,这远远超出了SOTA。
3、我们的PSOL方法在不同数据集之间具有良好的定位转移能力,而无需进行任何微调,这比以前的WSOL模型要好得多。
Related Works
Fully Supervised Methods
在AlexNet 成功之后,研究人员试图采用CNN进行对象定位和检测。 开拓性的工作OverFeat 尝试使用滑动窗口和多尺度技术在单个网络中进行分类,定位和检测。 VGGNet 添加了集成了基于类的回归,以增强定位的预测结果。
目标检测是另一个可以同时生成边界框和标签的任务。 R-CNN和Fast-RCNN 使用选择性搜索生成候选区域,然后使用CNN对其进行分类。 Faster-RCNN 提出了一个两阶段的网络:用于产生感兴趣区域(ROI)的区域提议网络(RPN),然后是R-CNN模块对它们进行分类并在该区域中定位对象。 这些流行的两级检测器广泛用于检测任务。 YOLO 和SSD是具有精心设计的网络结构和锚点的one-stage检测器。 最近,有人提出了一些无锚点 (anchor-free)检测器来减轻诸如CornerNet 和CenterNet 等常见检测器中的锚点问题。
但是,所有这些方法都需要大量,详细和准确的注释。 实际任务中的注释非常昂贵,有时甚至难以获取。 因此,我们需要其他一些方法来执行对象定位任务,而不需要许多确切的标签。
Weakly Supervised Methods
弱监督对象定位(WSOL)学习仅使用图像级标签来定位对象。 它更具吸引力,因为与对象级标签相比,图像级标签更容易获得且更便宜。 当训练图像仅具有图像级标签时,弱监督检测(WSOD)会尝试同时给出对象的位置和类别。
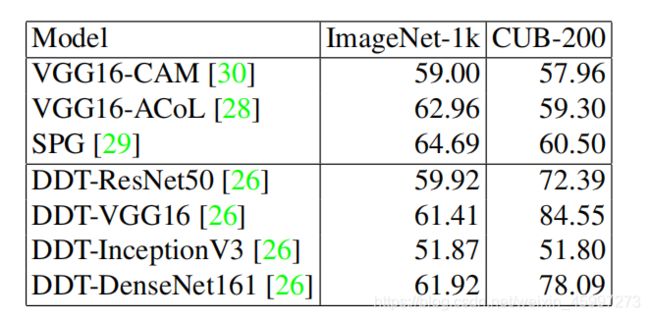
WSOL假设整个图像中只有一个特定类别的对象。基于此假设,提出了许多方法来提高WSOL的限制。 【30】首先用全局平均池化层和最终的全连接层(分类器的权重)生成类激活图。 Grad-CAM使用梯度而不是输出特征来生成更准确的类类激活图。除了这些专注于改进类激活图的方法外,其他一些方法还试图使分类模型更适合于定位任务。 HaS [19]试图随机擦除输入图像中的某些区域,以强制网络对WSOL保持细致。 ACoL [28]使用两个并行分类器进行动态擦除和对抗学习,以更有效地发现互补的目标区域。 SPG [29]生成自产掩码以定位整个对象。
WSOD没有一个类只有一个物体的限制。 但是,WSOD通常需要一些方法来生成区域proposal,例如选择性搜索(SS)[24]和边框(EB)[32],这将花费大量的计算资源和时间。 此外,当前的WSOD检测器使用高分辨率输入来输出边界框,从而导致沉重的计算负担。 因此,大多数WSOD方法
难以应用于大规模数据集。
Methodology
A paradigm shift from WSOL to PSOL
当前的WSOL网络可以生成具有给定类标签的边界框。 但是,已发现此方法的严重缺陷。
1、学习目标是间接的,这会损害模型在定位任务上的性能。 HaS [19]和ADL [2]表明,当只有一个CNN模型时,定位与分类不兼容。 定位尝试对整个对象进行定位,而分类尝试对对象进行分类。 分类模型通常尝试仅定位图像中对象的最有区别的部分。
2、CAM [30]具有阈值参数,需要存储三维特征图以进行进一步计算。 该阈值是棘手的并且难以确定。
受选择性搜索和Faster-RCNN中产生感兴趣区域(ROI)的类无关过程的鼓励,我们将WSOL分为两个子任务:类无关对象的定位和对象分类。 基于这两个子任务,我们提出了PSOL方法。 PSOL在显式生成的伪ground-truth边界框上直接优化定位模型。 因此,它消除了以前WSOL方法中说明的限制和缺点,并且是WSOL的模式转变。
The PSOL Method
Bounding Box Generation
 WSOL和我们的PSOL之间的关键区别是生成用于训练图像的伪边界框。 检测是完成此任务的自然选择,因为检测模型可以直接提供边界框和类。 但是,检测中最大的数据集只有80个类别[10],它无法为具有许多类别的数据集(例如ImageNet-1k)提供通用的对象定位。 此外,像Faster-RCNN [14]这样的检测器需要大量的计算资源和较大的输入图像大小(例如,测试时短边= 600)。 这些问题使检测模型无法应用于大规模数据集上的边界框。
WSOL和我们的PSOL之间的关键区别是生成用于训练图像的伪边界框。 检测是完成此任务的自然选择,因为检测模型可以直接提供边界框和类。 但是,检测中最大的数据集只有80个类别[10],它无法为具有许多类别的数据集(例如ImageNet-1k)提供通用的对象定位。 此外,像Faster-RCNN [14]这样的检测器需要大量的计算资源和较大的输入图像大小(例如,测试时短边= 600)。 这些问题使检测模型无法应用于大规模数据集上的边界框。
如果没有检测模型,我们可以尝试一些定位方法来输出边界框,以直接训练图像。 一些弱联合监督的方法可能会产生有偏差的边界框,我们将对其进行简要介绍。
WSOL methods
现有的WSOL方法通常遵循此 pipeline来生成图像的边界框。 首先将图像 I输入网络 F,然后生成最终特征图(通常是最后卷积层的输出)G:
![]() 其中 h,w,d 是最终特征图的高度,宽度和深度。 然后,在全局平均池和最终的完连接层之后,将生成标签 Lpred 。根据预测标签 Lpred 或 地面真实标签 Lgt ,我们可以在最终的全连接层中获得类特定的权重
其中 h,w,d 是最终特征图的高度,宽度和深度。 然后,在全局平均池和最终的完连接层之后,将生成标签 Lpred 。根据预测标签 Lpred 或 地面真实标签 Lgt ,我们可以在最终的全连接层中获得类特定的权重
![]() 然后,按通道权重对 G 的每个空间位置进行加权和求和,以获得特定类别的最终热图 H:
然后,按通道权重对 G 的每个空间位置进行加权和求和,以获得特定类别的最终热图 H:
![]() 最后,将 H 上采样到原始输入大小,并应用阈值生成最终边界框。
最后,将 H 上采样到原始输入大小,并应用阈值生成最终边界框。
DDT recap
一些协同监督的方法在定位任务上也可以表现良好。 在这些协同监督方法中,DDT具有良好的性能,并且对计算资源的需求很少。 因此,我们以DDT [26]为例。
给定具有n张图像的一组图像包S,其中每个图像 I∈S 具有相同的标签,或在图像中包含相同的对象。使用预先训练的模型 F ,还会生成最终特征图:
![]() 然后将这些特征图收集到一个大型特征图集中:
然后将这些特征图收集到一个大型特征图集中:
![]() 沿深度方向应用主成分分析(PCA)[12]。 经过PCA处理,我们可以得到特征值最大的特征向量 P 。 然后,对 G 的每个空间位置进行逐通道加权并求和,以获得最终的热图H:
沿深度方向应用主成分分析(PCA)[12]。 经过PCA处理,我们可以得到特征值最大的特征向量 P 。 然后,对 G 的每个空间位置进行逐通道加权并求和,以获得最终的热图H:
![]() 然后将H上采样至原始输入大小。 零阈值和最大连接的分量分析将应用于生成最终边界框。
然后将H上采样至原始输入大小。 零阈值和最大连接的分量分析将应用于生成最终边界框。
我们将使用WSOL方法和DDT方法生成伪边界框,并评估其适用性
Localization Methods
生成边界框后,每个训练图像都有(伪)边界框注释。 然后自然要用这些生成框执行对象定位。 如前所示,检测模型太繁重,无法处理此任务。 因此,执行bounding box回归是很自然的。 以前的全受监督的工作提出了两种边界框回归方法:单类回归(SCR)和 每类回归(PCR)。 PCR与类别标签密切相关。 由于我们主张定位是与类无关的,而不是与类有关的任务,因此我们为所有实验选择SCR。
我们按照先前的工作进行bounding box回归。 假设边界框采用x,y,w,h格式,其中x,y是边界框的左上角坐标,而w,h分别是边界框的宽度和高度。我们首先将x,y,w,h 转换为 x*,y*,w* ,h* 。
![]() h* = h / hi
h* = h / hi
wi和hi分别是输入图像的宽度和高度。
我们使用具有两个全连接的层和相应的ReLU层的子网进行回归。 最后,输出输入到sigmoid激活函数。 对于回归任务,我们使用均方误差损失(l2损失”)。
组合算法1中的步骤2和步骤3,即 Fcls 和 Floc 可以集成到一个模型中,该模型与分类标签和生成的边界框一起进行训练。 但是,我们将凭经验表明定位和分类模型应该分开。
Experiments