推荐系统:基础知识总结
itemCF的召回实践及其在信息流推荐中的应用
- 1.1 推荐系统中的召回基本范式?
- 1.2 为何要进行召回?
- 1.3 召回传统方式有哪些?
-
-
- 2. itemCF类召回
- 2.1 从哪几个方向理解item CF
-
- 2.2 通用建模方式还有哪些?
- 3.ItemCF实践
- 3.1 在信息流中如何抽取数据?
- 3.2 item CF代码实践(python)
-
- 3.4具体内容
-
- 1. 通用范式内容有哪些?
-
- i2i
- u2i
- u2i2i
- u2u2i
- u2tag2i
- u2***2i
- 2. 传统的基于热门和CB的召回方式有哪些,如何实现?
-
- 基于**CB**:
- 基于**CF**:
-
- 3. item CF有哪几种实现方式?
- 4. 不同的实现方式的时间复杂度如何
- 5. 在信息流推荐中如何利用实践item CF
- 6. Scala+spark实现item CF的多种方式
1.1 推荐系统中的召回基本范式?
一般来说业务的推荐系统的常用的基本召回算法有两个范式,相似度索引范式(如I2I),EBR范式(如DeepMatch)。I2I范式缺点在于对共现少的pair难以泛化,难以建模U2I部分,从而模型缺乏准确和个性化。EBR范式虽建模了U2I部分,将用户的兴趣整合成了一个向量。但却无法建模用户每一个行为和打分item之间的关系(类似于Target Attention),从而召回即缺乏多样性。
1.2 为何要进行召回?

召回不同于评价指标中的召回率,召回本质上与精排、粗排、重排都属于排序,之所以需要进行召回,主要原因有两个:
1.基于工程上的考虑,在精排阶段,一般会使用复杂的模型与特征,比如模型会使用深度神经网络,特征空间非常大,如果精排对上百万的候选数据进行排序,时间成本是非常大的,因此加入了召回层,利用少量的特征与简单的模型或规则对候选集进行快速筛选(一般筛选到1000个左右),这样就可以大大的减少精排阶段的时间消耗。
2.基于业务上的考虑,排序阶段主要考虑单一目标,比如ctr(click through rate),而有时候我们需要给用户多展现热点新闻、时效性数据、热点新闻等,这样我们可以采取多路召回的方式。
1.3 召回传统方式有哪些?
UserCF,矩阵分解,热度召回,LBS,用户标签(兴趣标签、地理标签、偏好标签)召回,ItemCF,频繁模式挖掘,二部图挖掘等。
2. itemCF类召回
2.1 从哪几个方向理解item CF
1.个性化程度:itemCF推荐结果着重于用户的历史兴趣,推荐更加个性化,反映了用户自己的兴趣传承,可以用于长尾物品丰富的领域。
2.可解释行:itemCF可以利用用户的历史行为给推荐结果提供推荐解释。
3.相似度矩阵:itemCF要计算物品的相似度矩阵,适用于物品的个数远少于用户个数的场景,互联网中物品的相似度对于用户的兴趣一般比较稳定。
4.用户冷启动:itemCF对用户冷启动不敏感,对于新加入的用户,一旦新用户对该物品产生行为,itemCF可以给新用户推荐和该物品相似的物品,而UserCF无法很好的给新加入的用户产生推荐。
5.应用场景:itemCF更适用于兴趣变化较为稳定的应用,比如Amazon的电商场景中,用户在一个时间段内更倾向于需找一类商品,这时利用物品相似度为其推荐相关物品是契合用户动机的。在Netfix的视频推荐场景中,用户观看电影,电视剧的兴趣往往比较稳定,因此利用itemCF推荐风格、类型相似的视频是更合理的选择。
2.2 通用建模方式还有哪些?
ItemCF
由于UserCF工程和效果上的缺陷,大多数互联网企业都选择ItemCF。ItemCF是基于物品相似度进行推荐的协同过滤算法。具体讲,通过计算Item之间的相似度,得到Item相似度矩阵,然后找到用户历史正反馈物品的相似物品进行排序和推荐,ItemCF的步骤总结如下:
(1)构建共现矩阵。根据用户的行为,构建以用户为行坐标,物品为纵坐标的共现矩阵。
(2)构建物品相似度矩阵。根据共现矩阵计算两两物品之间的相似度,得到物品相似度矩阵。
(3)获取Top n相似物品。根据用户历史正反馈物品,找出最相似的 n 个物品。
(4)计算用户对Top n 物品的喜好度。用户对物品的喜好度定义为:当前物品和用户历史物品评分的加权和,加权系数是前面计算的物品相似度。
(5)按喜好度生成排序结果。
UserCF
矩阵分解
协同过滤具有简单、可解释性强的优点,在推荐系统早期广泛应用。但是协同过滤也有泛化能力弱、热门物品头部效应强的弱点。为了解决上述问题,后来矩阵分解技术被提出来。矩阵分解的过程如图所示。
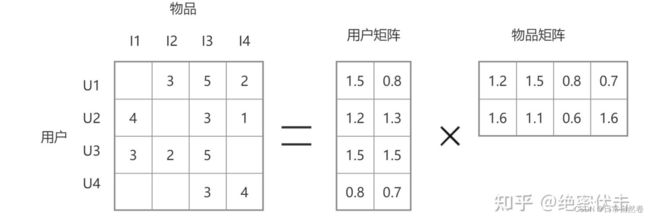
矩阵分解在推荐系统中的应用得益于2006年Netflix举办的推荐系统算法竞赛Netflix Prize Challenge,当时Netflix提出能在现有推荐系统基础上误差降低10%的人可以瓜分100万美元奖金,吸引了很多人参加。Netflix的比赛数据正是用户的评分数据,这次竞赛推动了无数推荐算法的产生,其中就包含了一系列矩阵分解模型,而最著名的便是SVD算法及其变种。

3.ItemCF实践
3.1 在信息流中如何抽取数据?

3.2 item CF代码实践(python)
#!/usr/sbin/env python
# -*- coding:utf-8 -*-
import math
# ItemCF算法
def ItemSimilarity(train):
# 物品-物品的共同矩阵
C = dict()
# 物品被多少个不同用户购买
N = dict()
for u, items in train.items():
for i in items.keys():
N.setdefault(i, 0)
N[i] += 1
C.setdefault(i, {})
for j in items.keys():
if i == j:
continue
C[i].setdefault(j, 0)
C[i][j] += 1
# 计算相似度矩阵
W = dict()
for i, related_items in C.items():
W.setdefault(i, {})
for j, cij in related_items.items():
W[i][j] = cij / math.sqrt(N[i] * N[j])
return W
# 推荐前K个用户
def Recommend(train, user_id, W, K):
rank = dict()
action_item = train[user_id]
for item, score in action_item.items():
for j, wj in sorted(W[item].items(), key=lambda x:x[1], reverse=True)[0:K]:
if j in action_item.keys():
continue
rank.setdefault(j, 0)
rank[j] += score * wj
print rank.items()
return sorted(rank.items(), key=lambda x:x[1], reverse=True)
train = dict()
for line in open('requests.txt', 'r'):
user, item, score = line.strip().split(",")
train.setdefault(user, {})
train[user][item] = float(score)
W = ItemSimilarity(train)
result = Recommend(train, '5', W, 3)
print result
3.4具体内容
1. 通用范式内容有哪些?
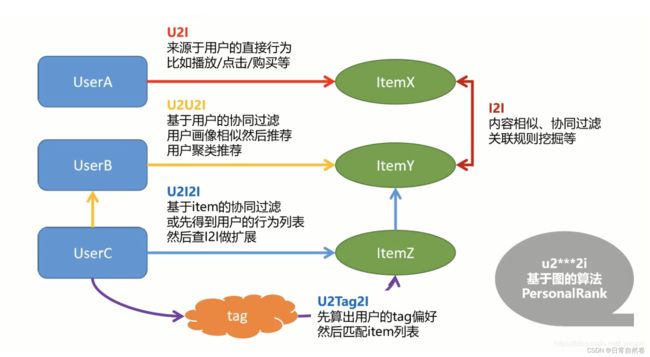
i2i
i2i:指从一个物品到达另外一个物品,item 到 item
应用:头条,在下方列出相似的、相关的文章;
算法:
内容相似,eg:文章的相似,取标题的关键字,内容相似
协同过滤
关联规则挖掘等
两个物品被同时看的可能性很大,当一个物品被查看,就给他推荐另一个物品
u2i
u2i:指从一个用户到达一个物品,user 到item
一般指用户的直接行为,比如播放、点击、购买等;
用户查看了一个物品,就会再次给它推荐这个物品
结合i2i一起使用,就是用户查看以合物品,就会给他推荐另一个相似的物品,就是u2i2i路径;
u2i2i
u2i2i:从一个用户,通过一个物品,到达另一个物品
用户查看了一个耳机(u2i),找出和这个耳机相似或者相关的产品(i2i)并推荐给用户
对路径的使用,已经从一条线变成两条线
方法:就是把两种算法结合起来,先得到u2i的数据,再利用i2i的数据进行扩展,就可以从第一个节点,越过一个节点,到达第三个节点,实现推荐
中间的桥梁是item
u2u2i
u2u2i:从一个用户,到达另一个用户,到达一个物品
先计算u2u:两种方法
一是:取用户的性别、年龄、职业等人工属性的信息,计算相似性,得到u2u;
一是:从行为数据中进行挖掘,比如看的内容和视频大部分很相似,就可以看作一类人;
也可以使用聚类的方法进行u2u计算
u2u一般用在社交里,比如微博、Facebook,推荐感兴趣的人
userB和UserC相似,如果userB查看了某个商品,就把这个商品推荐给userC;
中间的桥梁是user
u2tag2i
u2tag2i:中间节点是Tag标签,而不是 u 或者 i
京东,豆瓣,物品的标签非常丰富、非常详细;比如统计一个用户历史查看过的书籍,就可以计算标签偏好的向量:标签+喜欢的强度。
用户就达到了tag的节点,而商品本身带有标签,这就可以互通,进行推荐
先算出用户的tag偏好,然后匹配item列表
这种方法的泛化性能比较好(推荐的内容不那么狭窄,比如喜欢科幻,那么会推荐科幻的所有内容)
今日头条就大量使用标签推荐
u2***2i
基于图的算法:u2***2i
起始于U,结束于I,中间跨越很多的U、很多的I,可以在图中不停的游走
例如:PersonalRank,不限制一条还是两条线,在图中到处的游走,游走带着概率,可以达到很多的item;但是相比前面一条、两条边的路径,性能不是很好
2. 传统的基于热门和CB的召回方式有哪些,如何实现?
基于CB:
1、首先聊的是最简单的规则,“捆绑”,电商场景,乒乓球拍配乒乓球,游戏机配游戏卡,手机配手机壳,这都是一些用户可能高频出发的高关联项,这个其实可以通过关联规则之类的挖掘出来,例如“啤酒和尿布”的经典例子。
2、然后就是“用户画像”,用户在对一些行为后,通过分析用户点击的物料的规律,可以发现一些可以参考的标签喜好,例如恐怖小说看得多,那我们其实可以给用户推恐怖小说,玩射击类游戏多,那就可以继续推射击类游戏,看体育新闻多那就可以推体育新闻。
3、对于一些冷启动或者比较低频的用户,可以通过人群画像来进行召回,例如北京人喜欢看相声,那新来一个北京用户,就可以尝试和给他推相声,当然人群的划分方式很多,可以根据实际场景和标签来圈取人群推荐。这个虽然不是一个千人千面,但也算是一些千人百面的情况,能提升冷启用户的体验,让用户向活跃用户转化。
基于CF:
UserCF
.1.搜集用户和物品的历史信息,形成共现矩阵(m*n, m表示m个用户数,n表示物品数)。
.2.计算用户u和其他用户的相似度(上述相似度方式等),找到和目标用户u兴趣相似的Topk个用户,生成相似用户集合S。
.3.对相似用户集S中的用户有关联(他们喜欢的或者点击过的)的物品,生成一个物品集P
.4.预测并计算u用户对物品集P中每个物品p的喜好值,最后进行去重,排序
.5.最终取出步骤3的TopN个推荐物品推荐给用户u
ItemCF
.1.搜集用户和物品的历史信息,形成共现矩阵(m*n, m表示m个用户数,n表示物品数)。
.2.用户u历史喜欢的物品形成向量(列向量),和其他物品的列向量计算物品之间的相似度,找到TopK个相似物品,生成相似物品集合H。
.3.预测并计算用户u对物品集H中每个物品h的喜好值,最后进行去重,排序
.4.最终取出步骤3的TopN个推荐物品推荐给用户u
3. item CF有哪几种实现方式?
4. 不同的实现方式的时间复杂度如何
5. 在信息流推荐中如何利用实践item CF
6. Scala+spark实现item CF的多种方式
1.推荐系统是由数据驱动的,在实际企业工作中,用户行为数据存储在数据仓库中。假设数据仓库上有一张用户行为日志表:t_user_interaction,它的DDL如下:
CREATE TABLE t_user_interaction(
`user_id` string COMMENT 'User ID',
`item_id` string COMMENT 'Item Id',
`action_time` bigint COMMENT '动作发生的时间')
PARTITIONED BY (
dt bigint)
通过Spark的SQL引擎很容易获取我们需要的数据:
下面展示一些 内联代码片。
val sql =
s"""
|select
|user_id,
|item_id
|from t_user_interaction
|where dt>=${param.startDt} and dt<=${param.endDt}
""".stripMargin
val interactions = spark.sql(sql)
.rdd
.map(r => {
val userId = r.getAs[String]("user_id")
val itemId = r.getAs[String]("item_id")
(userId, itemId)
})
这里我们设置了两个参数:startDt,endDt,即一个滑动时间窗的开始时间和结束时间。实际生产环境,用户的行为日志在连续不断的产生,线上会不间断的收集这些行为日志,然后按一定时间窗,比如一个小时,保存一次。ItemCF的计算任务也需要按一定时间滑动窗口周期运行,因为会不断有新的物品出现,系统需要尽可能快地计算出新物品的相似物品,才能在用户对新物品产生新的行为后尽快做出响应。
相似度计算
物品的相似度计算有很多公式,这里我们以最常用的余弦相似度为例:

公式中 xi 表示第 i个用户对物品 x的评分, yi同理。
在实际生产中用户的显式评分数据很少,大多是一些隐式反馈(implicit feedback)数据,比如点击或者购买,所以我们用0或者1来表示用户对物品的偏好程度。以新闻推荐为例,1可以是用户点击了一篇文章,0表示给曝光了某篇文章但是用户没点击,或者用户根本没见过这篇文章。上面的公式可以拆解成分子和分母两部分:分子可以理解成是同时点击了文章 x和文章 y的用户数。分母包含点击了文章 x的用户数和点击了文章 y的用户数。
首先,我们计算好每个文章的点击数备用。
// 统计每个文章的点击用户数
val itemClickCnt = interactions.map {
case (_, itemId) => (itemId, 1)
}.reduceByKey((a, b) => a + b)
接着计算每两篇文章同时被点击的次数。假设总共有 N 篇文章,两两的组合数有 N*(N-1)/2。直接的思路是拿到每个物品的点击用户列表,然后两两组合,求出两个点击用户列表的交集。这个思路比较容易理解,但是面临计算量太大任务可能无法完成的问题。比如 N=100000 ,就需要至少数十亿量级的计算。在生产环境,文章的数量常常不止十万的量级,某些业务场景下,物品的数量可能有百万级甚至更多。实际上并非所有文章组合都有共现发生(文章A和文章B都被用户X点击了称为一次A和B的一次共现),即有些文章组合没有被同一个用户点击过,这些文章组合的相似度为0,对后续的推荐没有作用,可以去掉。因此,我们可以只计算至少被一个用户同时点击过的文章组合。共现的基础是一个用户点了多篇文章,类似用Map-Reduce思想实现Word-Counter的方法,先收集每个用户的点击文章列表,然后罗列出两两文章的组合,再统计这些组合出现的次数。
// 统计每两个Item被一个用户同时点击出现的次数
val coClickNumRdd = interactions.groupByKey
.filter {
case (_, items) =>
items.size > 1 && items.size < param.maxClick // 去掉点击数特别多用户,可能是异常用户
}
.flatMap {
case (_, items) =>
(for {x <- items; y <- items} yield ((x, y), 1))
}
.reduceByKey((a, b) => a + b)
.filter(_._2 >= param.minCoClick) // 限制最小的共现次数
注意把点击次数特别多的用户过滤掉,这些用户可能是网络的一些爬虫,会污染数据。同时,这个操作也解决了数据倾斜导致计算耗时太长或无法完成的问题。(数据倾斜是Spark计算任务常见的问题,可以理解为由于数据分布的不均匀,某些子任务计算耗时太长或一直无法完成,导致整个任务耗时太长或无法完成。)另外,还需要限制文章最小的共现次数,如果A和B两篇文章只是被一个用户同时点击了,不管计算出来的相似分数多高都不足以作为相似的理由,很有可能只是偶然发生的。一般来说,被更多用户同时点击,相似的分数会更加置信。
通过上面两步的操作,我们就完成了分子分母所需元素的计算。下面将他们合起来就可以计算相似度了。
val similarities = coClickNumRdd.map {
case ((x, y), clicks) =>
(x, (y, clicks))
}.join(itemClickNumRdd)
.map {
case (x, ((y, clicks), xClickCnt)) =>
(y, (clicks, x, xClickCnt))
}.join(itemClickNumRdd)
.map {
case (y, ((clicks, x, xClickCnt), yClickCnt)) =>
val cosine = clicks / math.sqrt(xClickCnt * yClickCnt)
(x, y, cosine)
}
得到物品之间的相似度后做一个简单的排序,截取最相似的 [公式] 个物品,来作为线上的推荐的数据。 到这里相似物品的计算过程就完成了,完整的代码可以在GitHub上找到。GitHub链接:https://github.com/Play-With-AI/recommender-system